基于转换系统的视频语音同步方法、装置、电子设备与流程
本技术涉及金融科技,尤其涉及一种基于转换系统的视频语音同步方法、装置、电子设备及存储介质。
背景技术:
1、随着科学技术的发展,语音翻译系统已经非常成熟,从早期的移动手持翻译器,到目前集成在讲座和视频会议中的同声传译系统,这些系统和工具在实际生活和商业操作中起着重要作用,例如,可以应用于保险展业系统、银行培训系统、订单交易系统等等。在保险展业的应用场景下,进行连续翻译对话内容的过程中,首先语音识别出每个句子内容,然后翻译成对应文本,最后将翻译成的目标语言进行语音合成,以向客户介绍相关理财产品的购买过程、理财收益等等。相比之下,演讲、电影和视频会议的同声传译通常是采用字幕的方法。然而,在制作电影或离线视频录音时,字幕会产生干扰。因此,电影通常邀请配音人员进行视频翻译和配音,使用翻译出来的目标语言来代替视频中的原声音,它的成本高昂,需要大量的人力物力,而且容易出现原始视频和目标声音不匹配的情况,并且在配音演员和合成语音的输出过程中,仍然存在原始视频中说话人的嘴唇运动和声音不匹配的问题,从而降低客户再保险展业过程中的体验感。
技术实现思路
1、本技术实施例的主要目的在于提出一种基于转换系统的视频语音同步方法、装置、电子设备及存储介质,能够生成包含翻译的音频和经过调整的嘴唇动作的视频,实现视频中说话人的嘴唇和声音相匹配。
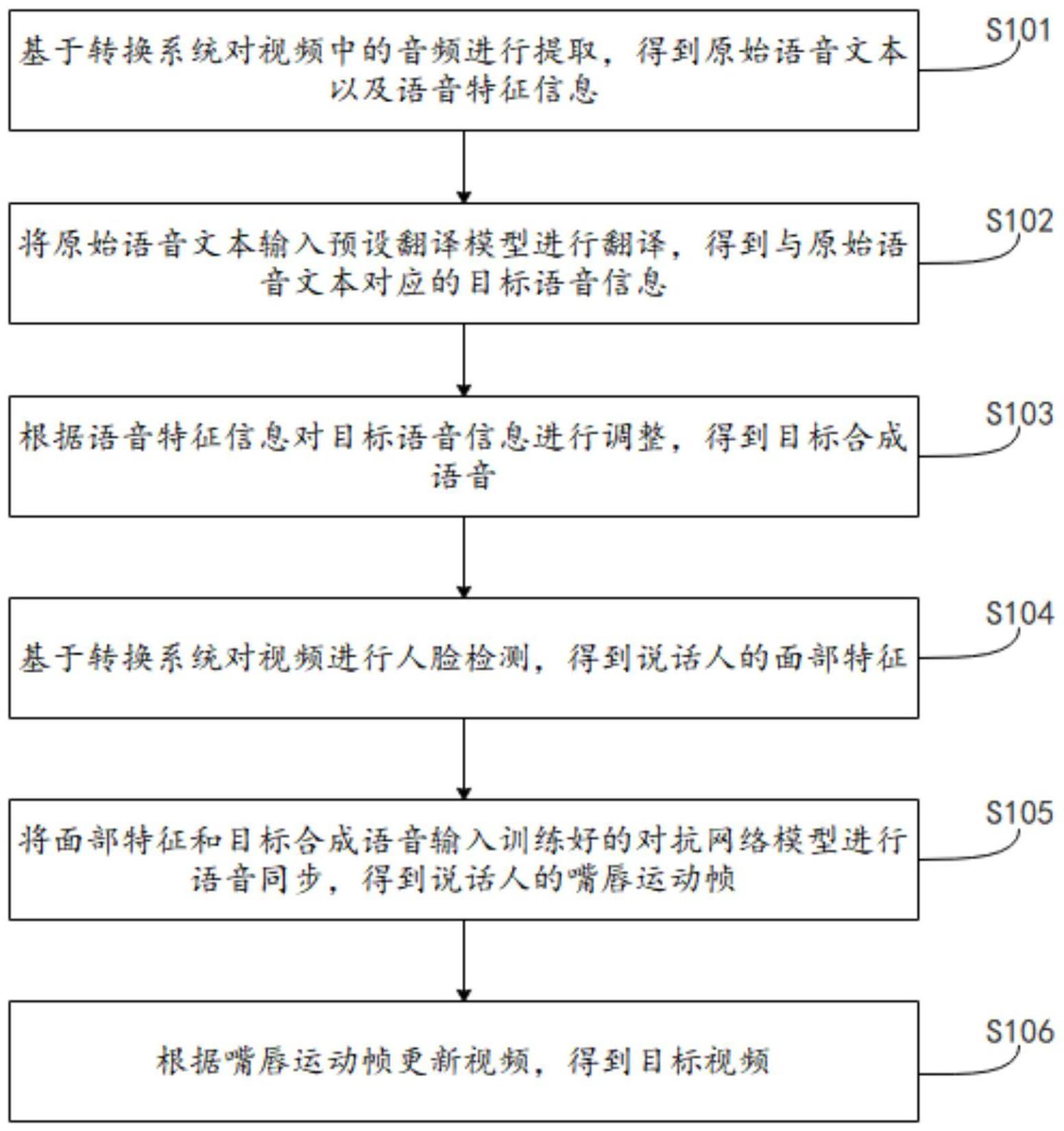
2、为实现上述目的,本技术实施例的第一方面提出了一种基于转换系统的视频语音同步方法,所述方法包括:
3、基于所述转换系统对视频中的音频进行提取,得到原始语音文本以及语音特征信息;
4、将所述原始语音文本输入预设翻译模型进行翻译,得到与所述原始语音文本对应的目标语音信息;
5、根据所述语音特征信息对所述目标语音信息进行调整,得到目标合成语音;
6、基于所述转换系统对所述视频进行人脸检测,得到说话人的面部特征;
7、将所述面部特征和所述目标合成语音输入训练好的对抗网络模型进行语音同步,得到所述说话人的嘴唇运动帧;
8、根据所述嘴唇运动帧更新所述视频,得到目标视频。
9、在一些实施例,所述转换系统包括自动语音识别模型;所述基于所述转换系统对视频中的音频进行提取,得到原始语音文本以及语音特征信息,包括:
10、基于所述自动语音识别模型对视频中的音频进行重音检测,得到携带重音信息的原始语音文本;
11、对所述原始语音文本进行特征提取,得到说话人的音色信息、韵律信息以及音调信息;
12、根据所述音色信息、所述韵律信息以及所述音调信息生成语音特征信息。
13、在一些实施例,所述将所述原始语音文本输入预设翻译模型进行翻译,得到与所述原始语音文本对应的目标语音信息,包括:
14、将所述原始语音文本输入预设翻译模型,使得所述预设翻译模型根据所述重音信息对所述原始语音文本进行翻译,得到所述目标语音信息。
15、在一些实施例,所述转换系统包括语音合成模型和语音转换模型;所述根据所述语音特征信息对所述目标语音信息进行调整,得到目标合成语音,包括:
16、将所述语音特征信息输入所述语音转换模型进行语音转换,得到转换序列;
17、将所述转换序列以及所述目标语音信息输入所述语音合成模型,使得所述语音合成模型根据所述重音信息将所述目标语音信息映射至所述转换序列,得到所述目标合成语音。
18、在一些实施例,所述语音转换模型包括音高编码器、韵律编码器和音色编码器;所述将所述语音特征信息输入所述语音转换模型进行语音转换,得到转换序列,包括:
19、将所述音色信息输入所述音色编码器进行音色转换,得到音色序列;
20、将所述韵律信息输入所述韵律编码器进行语音嵌入,得到韵律序列;
21、将所述音调信息输入所述音高编码器进行音调预测,得到音调序列;
22、根据所述音色序列、所述韵律序列和所述音调序列生成所述转换序列。
23、在一些实施例,所述基于所述转换系统对所述视频进行人脸检测,得到说话人的面部特征,包括:
24、基于所述转换系统对所述视频进行分割,得到所述视频的视频帧;
25、对所述视频帧进行检测,得到说话人的面部信息;
26、对所述面部信息进行特征分割,得到所述说话人的唇部区域、眼部区域以及鼻部区域;
27、根据所述唇部区域、所述眼部区域和所述鼻部区域生成所述面部特征。
28、在一些实施例,所述对抗网络模型包括唇生成模型;所述将所述面部特征和所述目标合成语音输入训练好的对抗网络模型进行语音同步,得到所述说话人的嘴唇运动帧,包括:
29、将所述面部特征输入所述唇生成模型,使得所述唇生成模型对所述唇部区域进行特征提取,得到唇形特征;
30、根据所述目标合成语音生成目标唇形帧;
31、根据所述目标唇形帧对所述唇形特征进行语音同步,生成所述说话人的嘴唇运动帧。
32、为实现上述目的,本技术实施例的第二方面提出了一种基于转换系统的视频语音同步装置,所述装置包括:
33、音频提取模块,用于基于所述转换系统对视频中的音频进行提取,得到原始语音文本以及语音特征信息;
34、语音翻译模块,用于将所述原始语音文本输入预设翻译模型进行翻译,得到与所述原始语音文本对应的目标语音信息;
35、语音合成模块,用于根据所述语音特征信息对所述目标语音信息进行调整,得到目标合成语音;
36、特征检测散模块,用于基于所述转换系统对所述视频进行人脸检测,得到说话人的面部特征;
37、语音同步模块,用于将所述面部特征和所述目标合成语音输入训练好的对抗网络模型进行语音同步,得到所述说话人的嘴唇运动帧;
38、目标确定模块,用于根据所述嘴唇运动帧更新所述面部特征,得到目标视频。
39、为实现上述目的,本技术实施例的第三方面提出了一种电子设备,一种电子设备,所述电子设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现如第一方面所述的基于转换系统的视频语音同步方法。
40、为实现上述目的,本技术实施例的第四方面提出了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的基于转换系统的视频语音同步方法。
41、本技术提出的基于转换系统的视频语音同步方法和装置、电子设备及存储介质,首先,基于转换系统对视频中的音频进行提取,从而得到原始语音文本以及视频中的语音特征信息,再将原始语音文本输入预设翻译模型进行翻译,得到与原始语音文本对应的目标语音信息,从而能够将原始语音文本翻译成对应的语言,实现对特定语言的翻译,之后,根据语音特征信息对目标语音信息进行调整,得到目标合成语音,从而使得翻译后的语音更加流畅,再基于转换系统对视频进行人脸检测,得到说话人的面部特征,便于后续对视频中的人脸进行调节,最后将面部特征和目标合成语音输入训练好的对抗网络模型进行语音同步,生成与目标合成语音对应的嘴唇运动帧,并根据嘴唇运动帧对视频进行更新,从而得到目标视频,实现视频中说话人的嘴唇和声音相匹配,增加视频中说话人嘴型与配音的匹配度,提高客户在保险展业过程中的体验感。
- 还没有人留言评论。精彩留言会获得点赞!