一种基于人工智能的教育信息监管方法
本发明涉及电数字数据处理,具体涉及一种基于人工智能的教育信息监管方法。
背景技术:
1、教育过程中,教师言论对于学生的价值观形成具备重要的引导作用,由于个体差异,每个教师的观点不同,因此,对于学生的教育存在正面和负面的作用,为了尽量减少负面作用,需要对教育信息进行监督,从而尽量的确保教育的正面引导作用。
2、对于教育信息进行监督,即实现对语言的监督,识别语言中是否包含敏感词汇或者敏感语义,从而提醒教育者从正面引导学生。
3、现有识别语言中是否包含敏感词汇或者敏感语义的方法,是采用语音识别语言模型对语音信号进行处理,从而得到对应的语义,现有语音识别语言模型常采用神经网络进行识别,但是现实环境中的语音信号存在较多噪声,直接采用神经网络进行识别,存在识别精度不高,造成监管不到位的问题。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的一种基于人工智能的教育信息监管方法解决了采用神经网络进行语音的语义识别存在识别精度不高,造成监管不到位的问题。
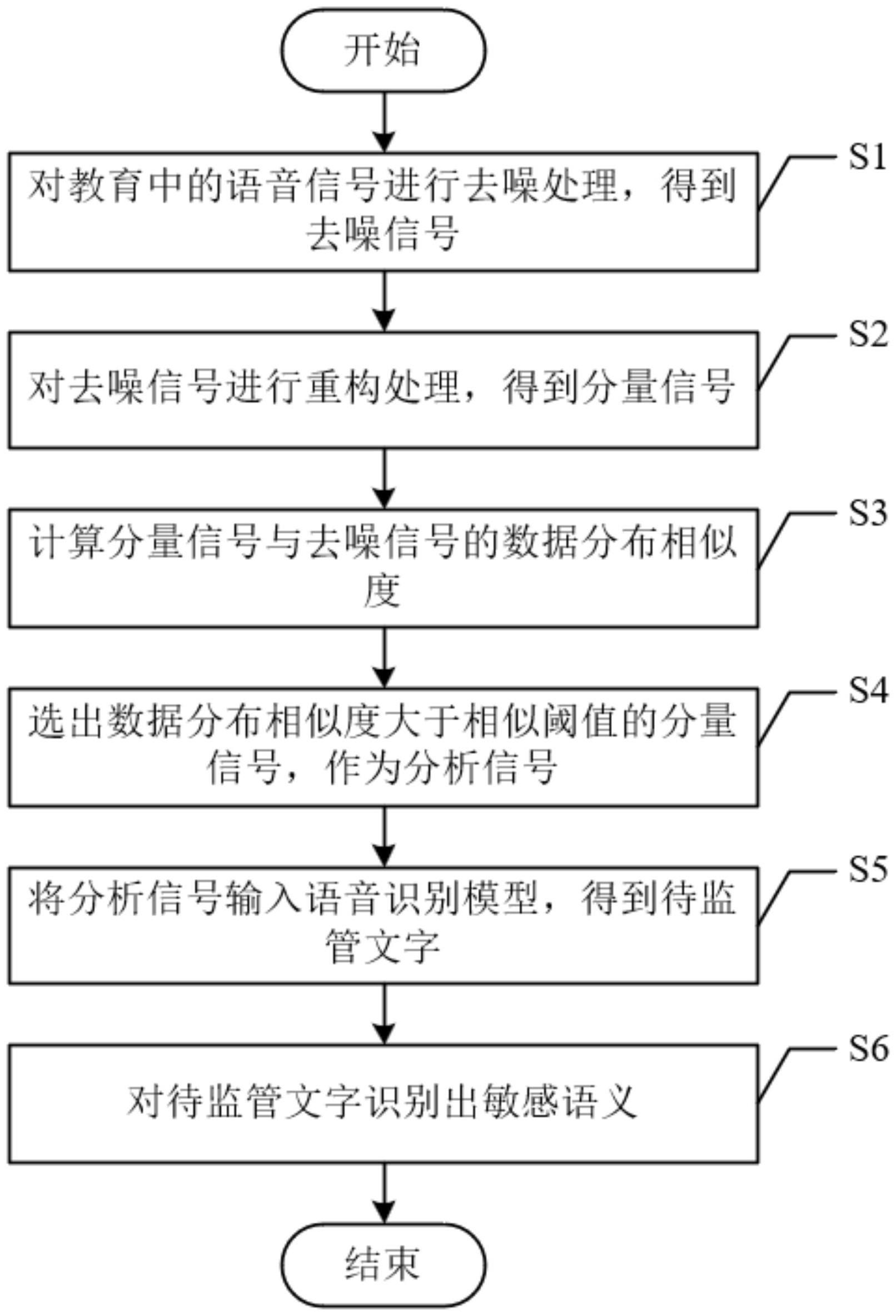
2、为了达到上述发明目的,本发明采用的技术方案为:一种基于人工智能的教育信息监管方法,包括以下步骤:
3、s1、对教育中的语音信号进行去噪处理,得到去噪信号;
4、s2、对去噪信号进行重构处理,得到分量信号;
5、s3、计算分量信号与去噪信号的数据分布相似度;
6、s4、选出数据分布相似度大于相似阈值的分量信号,作为分析信号;
7、s5、将分析信号输入语音识别模型,得到待监管文字;
8、s6、对待监管文字识别出敏感语义。
9、进一步地,所述s1包括以下分步骤:
10、s11、采用小波基函数和分解尺度对语音信号进行分解,得到小波分解系数;
11、s12、根据去噪函数对小波分解系数进行处理,得到估计小波系数;
12、s13、对估计小波系数进行小波逆变换,得到去噪信号。
13、进一步地,所述s12中去噪函数为:
14、,
15、,
16、其中,为估计小波系数,为去噪权重,为符号函数,为小波分解系数,为去噪阈值,| |为绝对值;
17、所述去噪阈值的公式为:
18、,
19、其中,为去噪阈值,为语音信号序列中的第个值,为语音信号序列的均值,为语音信号序列的长度,为自然常数,为分解尺度,为对数函数,为阈值系数。
20、上述进一步地方案的有益效果为:本发明设置了根据分解尺度和当前的语音信号自适应调节的去噪阈值,使得去噪阈值更好滤除噪声的小波分解系数,保留有用信号的小波分解系数。
21、进一步地,所述s2中重构处理的公式为:
22、,
23、其中,为去噪信号,为第个分量信号,为分量信号的数量,为剩余信号,为时间。
24、进一步地,所述s3中数据分布相似度的计算公式为:
25、,
26、其中,为数据分布相似度,为去噪信号,为第个分量信号,为去噪信号均值,为第个分量信号均值,为统计的时间段,为时间,| |为绝对值。
27、上述进一步地方案的有益效果为:本发明中对语音信号进行去噪处理,滤除了噪声信号,但为了进一步地提升语音识别模型的识别精度,将去噪信号进行重构处理,得到多个分量信号,计算每个分量信号与去噪信号的数据分布相似度,筛选出相似度高的分量信号,保障输入到语音识别模型中的信号均是有用信号,增强有用信号在语音识别模型中的表达,本发明通过信号与信号之间的数据值分布情况,计算相似度,找到数据值分布相似的分量信号,来表征原本的去噪信号。
28、进一步地,所述s5中语音识别模型包括:多个分析信号特征提取单元、特征融合单元、最大池化层、平均池化层、注意力单元、lstm单元、卷积层和分类单元;
29、每个所述分析信号特征提取单元用于输入一种分析信号,其输出端与特征融合单元的输入端连接;所述特征融合单元的输出端分别与最大池化层的输入端和平均池化层的输入端连接;所述注意力单元的输入端分别与最大池化层的输出端和平均池化层的输出端连接,其输出端与lstm单元的输入端连接;所述卷积层的输入端与lstm单元的输出端连接,其输出端与分类单元的输入端连接;所述分类单元的输出端作为语音识别模型的输出端。
30、上述进一步地方案的有益效果为:本发明中将相似度高的几个分量信号均输入至语音识别模型,通过每个分析信号特征提取单元提取出特征信号,在特征融合单元融合特征,再通过最大池化层提取显著特征,平均池化层提取全局特征,在注意力单元分别对最大池化层输出的特征和平均池化层输出的特征赋予不同注意力,便于提高有效特征的关注度。
31、进一步地,所述分析信号特征提取单元的公式为:
32、,
33、其中,为分析信号特征提取单元第时刻提取的特征,为激活函数,为分析信号特征提取单元的权重,为分析信号特征提取单元的偏置,为第时刻输入分析信号特征提取单元的分析信号,为自然常数。
34、上述进一步地方案的有益效果为:本发明先通过算出分析信号的比例系数,再通过指数函数增强分析信号,再通过筛选出有效的特征信息。
35、进一步地,所述特征融合单元的公式为:
36、,
37、其中,为特征融合单元第时刻输出的特征,为第1个分析信号特征提取单元第时刻提取的特征,为第个分析信号特征提取单元第时刻提取的特征,为第个分析信号特征提取单元第时刻提取的特征,为哈达玛积,为分析信号特征提取单元的数量;
38、所述注意力单元的公式为:
39、,
40、其中,为注意力单元第时刻输出的特征,为注意力单元的第一权重,为注意力单元的第二权重,为注意力单元的偏置,为第时刻最大池化层输入注意力单元的特征的数量,为最大池化层第时刻输出的第个特征,为第时刻平均池化层输入注意力单元的特征的数量,为平均池化层第时刻输出的第个特征,为第一分母系数,为第二分母系数。
41、上述进一步地方案的有益效果为:本发明中的特征融合单元将各个分析信号特征提取单元提取到的特征进行融合处理,使得各个分析信号特征提取单元提取到的特征融合在一起,避免后面提取特征时部分特征丢失;本发明中注意力单元中对最大池化层和平均池化层的特征赋予不同权重,提高有效特征的关注度。
42、进一步地,所述s6包括以下分步骤:
43、s61、对待监管文字进行分词处理,得到待监管词组;
44、s62、计算待监管文字对应的待监管词组与数据库中敏感语句的匹配度;
45、s63、在匹配度大于匹配阈值时,待监管文字中存在敏感语义。
46、进一步地,所述s62中计算匹配度的公式为:
47、,
48、,
49、,
50、,
51、其中,为匹配度;为第个待监管词组的匹配状态,在待监管文字中第个待监管词组出现在敏感语句中时为1,未出现在敏感语句中时为0;为第个待监管词组的同义词的匹配状态,在待监管文字中第个待监管词组的同义词出现在敏感语句中时为1,未出现在敏感语句中时为0;为第个待监管词组的近义词的匹配状态,为待监管文字中第个待监管词组的近义词出现在敏感语句中时为1,未出现在敏感语句中时为0;为第一指数系数,为第二指数系数,为第三指数系数,为待监管文字中待监管词组的数量。
52、上述进一步地方案的有益效果为:本发明中计算匹配度时,采用待监管词组、待监管词组同义词和待监管词组近义词三方面对语言之间的语义匹配度进行评价,同时,设置了指数系数,进一步增强各个语句的匹配度区分程度,在待监管词组本身、同义词或者近义词出现越多时,则匹配度越高,本发明中近义词的指数系数较低,待监管词组本身和同义词在匹配成功时,对匹配度的提升度更高,更容易确认出待监管文字中存在敏感语义。
53、综上,本发明的有益效果为:本发明中先对语音信号进行去噪处理,降低噪声信号的影响,再进行重构处理,将去噪信号进行拆分,得到分量信号,计算分量信号与去噪信号的数据分布相似度,取相似度大的分量信号替代去噪信号,进一步地削减噪声的影响,同时,还选出能够替代去噪信号的分量信号,将部分不太相似的信号筛选掉,从而达到精简数据和消除噪声的作用,再将分析信号输入到语音识别模型中,得到待监管文字,从待监管文字识别出敏感语义。本发明中通过去噪和重构两个过程滤除噪声,提高语音识别模型的识别精度,且精简后的数据更容易在语音识别模型中表达,进一步地提高语音识别模型的识别精度,在提取到准确的待监管文字的情况下,更便于对教育信息的监管,提高监管的准确率。
- 还没有人留言评论。精彩留言会获得点赞!