语音合成方法、语音合成装置、电子设备及存储介质与流程
本技术涉及金融科技,尤其涉及一种语音合成方法、语音合成装置、电子设备及存储介质。
背景技术:
1、语音合成中语音转换的目的是改变源说话人的声音,使其听起来像目标说话人。例如,在银行、保险公司或其他金融机构中,往往由智能客服通过语音引导用户办理相应的业务。在对用户进行语音引导时,为了提高引导效果或基于用户定制化需求,往往需要更换语音中的源说话人为目标说话人。当前,随着声学模型和高质量的神经网络声码器的快速发展,语音合成中的说话人转换取得了显著的进步。在具有说话人的大量高质量录音数据的条件下,现有的语音合成模型很容易实现多说话人之间的语音转换。但新说话人的高质量录音数据难以获取,导致针对新说话人的语音转换定制服务难以实现。因此,如何提供一种语音合成方法,能够保证语音合成的质量,且能够针对任意说话人进行语音转换,成为了亟待解决的技术问题。
技术实现思路
1、本技术实施例的主要目的在于提出语音合成方法、语音合成装置、电子设备及存储介质,能够保证语音合成的质量,且能够针对任意说话人进行语音转换。
2、为实现上述目的,本技术实施例的第一方面提出了一种语音合成方法,所述方法包括:
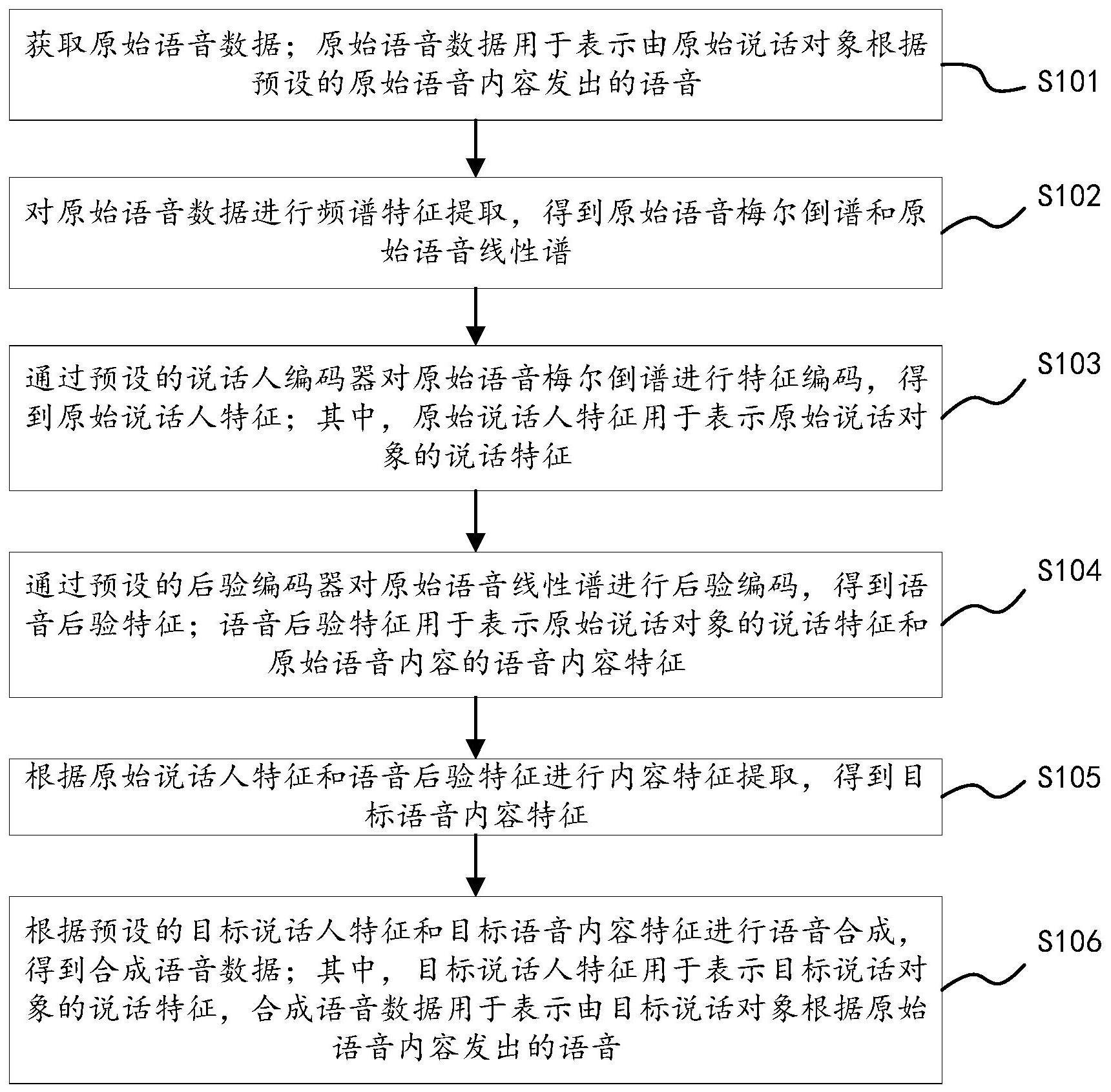
3、获取原始语音数据;所述原始语音数据用于表示由原始说话对象根据预设的原始语音内容发出的语音;
4、对所述原始语音数据进行频谱特征提取,得到原始语音梅尔倒谱和原始语音线性谱;
5、通过预设的说话人编码器对所述原始语音梅尔倒谱进行特征编码,得到原始说话人特征;其中,所述原始说话人特征用于表示所述原始说话对象的说话特征;
6、通过预设的后验编码器对所述原始语音线性谱进行后验编码,得到语音后验特征;所述语音后验特征用于表示所述原始说话对象的说话特征和所述原始语音内容的语音内容特征;
7、根据所述原始说话人特征和所述语音后验特征进行内容特征提取,得到目标语音内容特征;
8、根据预设的目标说话人特征和所述目标语音内容特征进行语音合成,得到合成语音数据;其中,所述目标说话人特征用于表示目标说话对象的说话特征,所述合成语音数据用于表示由所述目标说话对象根据所述原始语音内容发出的语音。
9、在一些实施例,所述根据所述原始说话人特征和所述语音后验特征进行内容特征提取,得到目标语音内容特征,包括:
10、通过预设的内容特征提取模型对所述语音后验特征进行特征提取,得到映射内容特征;
11、根据所述原始说话人特征对所述映射内容特征进行调整,得到所述目标内容特征。
12、在一些实施例,在所述通过预设的内容特征提取模型对所述语音后验特征进行特征提取,得到映射内容特征之前,所述方法还包括:
13、训练所述内容特征提取模型,具体包括:
14、通过预设的原始特征提取模型对所述语音后验特征进行特征提取,得到初始语音内容特征;
15、根据所述原始说话人特征和所述初始语音内容特征进行语音合成,得到中间语音数据;
16、对所述中间语音数据进行频谱特征提取,得到中间语音线性谱;
17、根据所述中间语音线性谱和所述原始语音线性谱进行损失计算,得到第一损失数据;
18、根据所述第一损失数据对所述原始特征提取模型进行参数调整,得到所述内容特征提取模型。
19、在一些实施例,所述说话人编码器包括:第一卷积层、非线性神经网络,所述通过预设的说话人编码器对所述原始语音梅尔倒谱进行特征编码,得到原始说话人特征,包括:
20、通过所述第一卷积层对所述原始语音梅尔倒谱进行隐状态特征提取,得到第一隐状态说话人特征;
21、通过所述非线性神经网络对所述第一隐状态说话人特征进行时序长度处理,得到所述原始说话人特征。
22、在一些实施例,所述非线性神经网络包括:残差层、第二卷积层和非线性子网络,所述通过所述非线性神经网络对所述第一隐状态特征进行时序长度处理,得到所述原始说话人特征,包括:
23、通过所述残差层对所述第一隐状态说话人特征进行隐状态特征激活,得到目标激活说话人特征;
24、通过所述第二卷积层对所述目标激活说话人特征进行隐状态特征提取,得到第二隐状态说话人特征;
25、通过所述非线性子网络对所述第二隐状态说话人特征进行时序长度处理,得到所述原始说话人特征。
26、在一些实施例,所述残差层包括第一卷积核、第二卷积核、目标激活函数,所述通过所述残差层对所述第一隐状态说话人特征进行隐状态特征激活,得到目标激活说话人特征,包括:
27、通过所述第一卷积核对所述第一隐状态说话人特征进行特征提取,得到第一中间隐状态特征;
28、通过所述目标激活函数对所述第一隐状态说话人特征进行非线性变换处理,得到目标非线性隐状态特征;
29、通过所述第二卷积核对所述目标非线性隐状态特征进行特征提取,得到第二中间隐状态特征;
30、对所述第一中间隐状态特征和所述第二中间隐状态特征进行特征融合,得到所述目标激活说话人特征。
31、在一些实施例,所述目标激活函数包括第一激活函数和第二激活函数,所述通过所述目标激活函数对所述第一隐状态特征进行非线性变换处理,得到目标非线性隐状态特征,包括:
32、通过所述第一激活函数对所述第一隐状态特征进行非线性变换处理,得到第一非线性隐状态特征;
33、通过所述第二激活函数对所述第一隐状态特征进行非线性变换处理,得到第二非线性隐状态特征;
34、将所述第一非线性隐状态特征和所述第二非线性隐状态特征进行点乘处理,得到所述目标非线性隐状态特征。
35、为实现上述目的,本技术实施例的第二方面提出了一种语音合成装置,所述装置包括:
36、语音数据获取模块,用于获取原始语音数据;所述原始语音数据用于表示由原始说话对象根据预设的原始语音内容发出的语音;
37、频谱提取模块,用于对所述原始语音数据进行频谱特征提取,得到原始语音梅尔倒谱和原始语音线性谱;
38、说话人特征编码模块,用于通过预设的说话人编码器对所述原始语音梅尔倒谱进行特征编码,得到原始说话人特征;其中,所述原始说话人特征用于表示所述原始说话对象的说话特征;
39、后验特征编码模块,用于通过预设的后验编码器对所述原始语音线性谱进行后验编码,得到语音后验特征;所述语音后验特征用于表示所述原始说话对象的说话特征和所述原始语音内容的语音内容特征;
40、内容特征提取模块,用于根据所述原始说话人特征和所述语音后验特征进行内容特征提取,得到目标语音内容特征;
41、语音合成模块,用于根据预设的目标说话人特征和所述目标语音内容特征进行语音合成,得到合成语音数据;其中,所述目标说话人特征用于表示目标说话对象的说话特征,所述合成语音数据用于表示由所述目标说话对象根据所述原始语音内容发出的语音。
42、为实现上述目的,本技术实施例的第三方面提出了一种电子设备,所述电子设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述第一方面所述的语音合成方法。
43、为实现上述目的,本技术实施例的第四方面提出了一种存储介质,所述存储介质为计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面所述的语音合成方法。
44、本技术提出的语音合成方法、语音合成装置、电子设备及存储介质,该方法包括:对原始语音数据进行频谱特征提取,得到原始语音梅尔倒谱和原始语音线性谱。通过说话人编码器对原始语音梅尔倒谱进行特征编码,可得到原始说话人特征。通过后验特征编码器对原始语音线性谱进行特征编码,可得到语音后验特征。通过原始说话人特征和语音后验特征进行内容特征提取,可得到与说话人特征无关的目标语音内容特征。最后根据目标说话人特征与目标语音内容特征进行语音合成,得到合成语音数据。综上所述,本技术实施例能够实现语音合成,且能够针对任意说话人进行语音转换。
- 还没有人留言评论。精彩留言会获得点赞!