一种基于中文分词优化的中文语音合成方法、电子设备及存储介质
本发明涉及中文语音合成,具体涉及一种基于中文分词优化的中文语音合成方法、电子设备及存储介质。
背景技术:
1、语音交互是人机交互的重要方式,通过语音合成模块使机器人向用户提供相应信息。以医疗服务机器人为例,由于交互过程中往往存在大量的专业术语,且没有明确的词汇边界,使得合成的音频中没有相应的停顿,容易导致医疗歧义信息问题。以疾病名“高铁血蛋白血症”为例,存在“高铁”、“白血症”(即白血病)等歧义信息,降低人机交互质量。
2、现有语音合成的输入是一串由其他模块(例如对话系统)输出的自然语言文本,对于中文领域来说,为了避免歧义或是多音字等问题,就需要将文本序列拆分成对应的词序列,即中文分词。中文分词作为中文自然语言处理中的一项基础任务,其任务的质量直接影响下游任务的性能,如问答系统,情感识别以及文本分类等。面向医疗文本的中文分词将大量包含医疗领域专业术语的字符串序列,切分为具有明确边界信息的词汇序列,减少文本中的歧义信息,为下游任务提供更准确的医疗语义。医疗文本往往包含大量的疾病名、手术名、药品名及医疗术语,这类专业术语相较通用语料大都是未登录(out-of-vocabulary,oov)词,oov词的识别性能直接影响模型的分词质量。成词信息(wordhood)对于中文文本建模十分重要,其本质是一种能够反映文本中字符之间共现概率的文本特征,能够提高模型对oov词的处理能力,但是现有整合成词信息的成词记忆网络在建模时并未考虑标签之间的依赖关系,(例如:标签s后面应该跟标签s或者标签b,而标签b后面应该跟标签m或者标签e),这导致模型的分词性能特别是对oov词的识别有所欠缺。
3、中文分词的相关研究可追溯到20世纪80年代,并在通用领域取得了丰硕的成果。而特定领域的中文分词研究由于存在大量的专业术语,导致在通用领域具有良好性能的模型和工具应用到专业领域时性能明显下降。ding等人提出一种利用领域通用知识来处理专业领域的分词模型,使用迁移学习将通用知识从高资源领域迁移到低资源领域,提高模型对于未登录词的处理能力,以解决面向专业领域分词任务。ye等人提出一种利用词嵌入的半监督跨领域中文分词模型,将从无监督专业领域语料中训练得到的词嵌入整合到模型的训练过程,利用词嵌入中的领域知识提高模型对专业领域术语的分词性能。李鹏等人提出一种解决特定领域未登录词识别质量较低问题的模型,通过筛选无监督语料中较高置信度的n-gram片段,利用n-gram片段中的先验知识辅助模型识别未登录词,在建筑领域中取得了分词性能提升。tian等人基于键-值网络和注意力机制提出一种利用文本成词信息的成词记忆网络,并且提出一种利用成词记忆网络的中文分词模型wmseg,取得了最前沿的中文分词性能,而且提高了模型对oov词的处理能力。
4、但这些方法主要存在两方面的不足:(1)但现有模型在建模语境特征和语义特征之间的高阶语义关联上有所不足;(2)目前研究未能将中文分词与医疗领域服务机器人联系起来,无法更进一步地利用模型。
技术实现思路
1、本发明的目的是为解决现有技术中存在的上述缺陷,提供一种基于中文分词优化的中文语音合成方法、电子设备及存储介质。
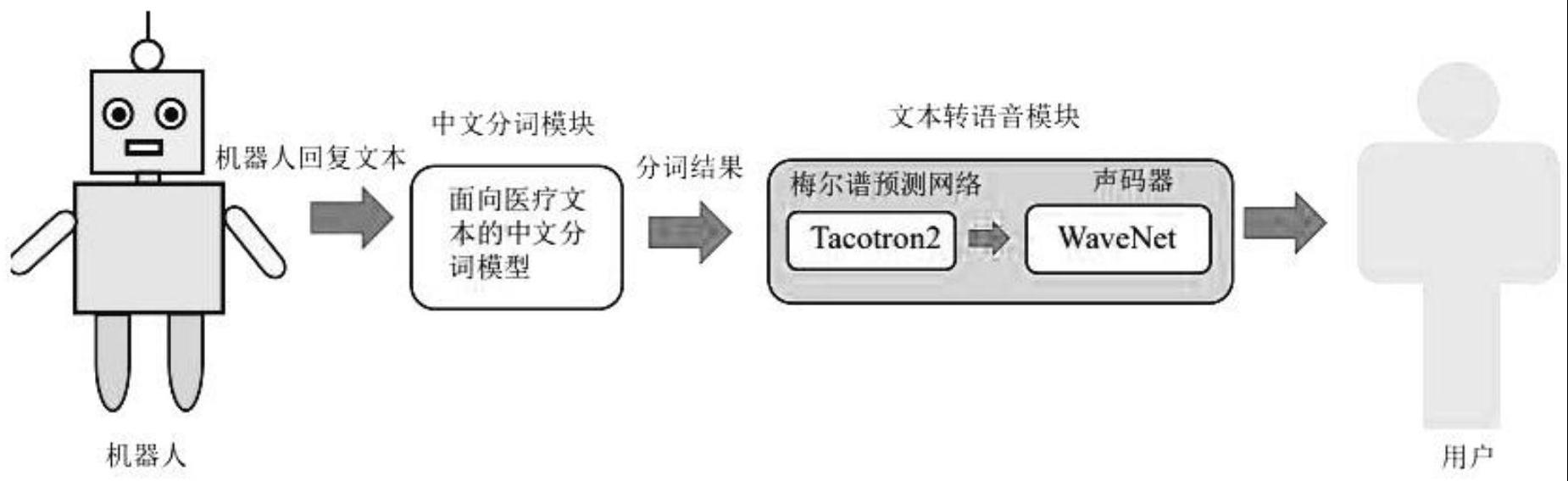
2、本发明为解决上述技术问题的不足,所采用的技术方案是:一种基于中文分词优化的中文语音合成方法:首先利用基于加权自蒸馏的中文分词模型cws-wsd将医疗服务机器人交互过程中产生的回复文本进行分词,明确文本中的词汇边界,然后根据分词结果插入相应的停顿标志符,最后将插入标识符后的文本送入tacotron2进行语音合成。
3、作为本发明一种基于中文分词优化的中文语音合成方法的进一步优化:中文分词具体为:
4、利用编码器将输入的文本序列分别进行语义编码和语境编码,生成包含文本语义信息的语义特征向量及包含成词信息的语境特征向量;
5、利用交互注意力机制将语境特征和语义特征之间的高阶语义关联引入到模型的训练过程,并且利用加权自蒸馏机制约束模型特征学习,指导模型学习文本中的语境特征;
6、将包含语境特征和语义特征之间的高阶语义关联的输出特征送入解码器进行分词标注。
7、作为本发明一种基于中文分词优化的中文语音合成方法的进一步优化:中文分词的方法具体包括以下步骤:
8、s1、构造词典n,用做筛选文本中包含相应字符的n-gram片段;
9、s2、给定文本序列x=[x1,…,xi,…,xx],其中x表示文本序列的长度,对于文本序列中每个字符xi,在词典n中遍历得到该文本序列中包含字符xi的所有n-gram片段,从而得到键列表ki=[ki,1,…,ki,j,…,ki,m]和值列表vi=[vi,1,…,vi,j,…,vi,m],m表示包含字符xi的n-gram片段的数量,用键嵌入表示ki,j以及值嵌入表示vi,j,其中i表示字符在文本序列x中的位置,j表示n-gram片段ki,j在键列表中的位置;
10、s3、将文本序列x输入到cws-wsd模型,通过编码器对序列中每个字符xi编码出一个包含文本语义信息的特征向量hi,公式如下:
11、encoder(x)=[h1,l,hi,l,h|x|],其中,encoder表示编码器,编码器具体为bert编码器;
12、s4、将语义特征向量hi、键嵌入及值嵌入进行计算得到包含成词信息的语境特征向量o,计算公式如下:
13、
14、
15、其中:hi表示编码器所生成的包含文本语义信息的特征向量;pi,j表示关于包含字符xi的n-gram片段ki,j的概率分布;oi表示成词记忆网络所生成的包含成词信息的语境特征向量;
16、s5、利用语境注意力机制建模两类特征相关性加权的包含语境特征的嵌入向量,利用语义注意力机制建模两类特征相关性加权的包含语义特征的嵌入向量,接着将两个加权之后嵌入向量进行拼接融合,然后将融合特征向量进行降维,以此将语境特征和语义特征之间的高阶语义关联整合到模型的训练过程,指导模型进行特征学习,最后得到交互注意力机制的输出特征;
17、s6、解码器根据交互注意力机制的输出特征预测文本的标签序列y=y1l yil y|x|,公式如下:
18、decoder(a′)=y
19、其中:decoder表示解码器,a′=a1l ail a|x|,以crf作为解码器,算法定义公式如下:
20、
21、其中:wc∈r|b|×|b|,bc∈r|b|,两者均为可训练参数;
22、s7、cws-wsd模型首先使用编码器将输入的文本序列进行语义编码,生成包含文本语义信息的特征向量,通过注意力机制和键-值记忆网络编码包含文本语境信息的特征向量,然后利用交互注意力机制将语境特征和语义特征之间的高阶语义关联引入到模型的训练过程,并且利用加权自蒸馏机制约束模型特征学习,指导模型学习文本中的语境特征,最后将包含语境特征和语义特征之间的高阶语义关联的输出特征送入解码器进行分词标注。
23、作为本发明一种基于中文分词优化的中文语音合成方法的进一步优化:所述词典n的构造采用无监督构词法,根据原始语料构造词典n,算法定义公式如下:
24、av(n)=min(l(n),r(n))
25、av表示邻接多样度,l(n)表示n-gram片段n左侧不同字符的数量,r(n)表示n-gram片段n右侧不同字符的数量。
26、作为本发明一种基于中文分词优化的中文语音合成方法的进一步优化:所述步骤s5中语境特征注意力机制的q矩阵为包含语义特征的嵌入向量,k和v为包含语境特征的嵌入向量,而语义特征注意力机制的q矩阵为语境特征的嵌入向量,k和v为语义特征的嵌入向量,以此实现语境特征和语义特征之间的高阶语义关联的建模和两个注意力机制模块之间的信息流交互。假设向量h为包含语义特征的嵌入特征,向量o为包含语境特征的嵌入特征,则语境注意力机制和语义注意力机制的计算过程如下所示:
27、o′=contextattention(h,o,o)
28、h′=semanticsattention(o,h,h)
29、contextattention(·)为语境注意力机制,semanticsattention(·)为语义注意力机制,o′为注意力加权之后的包含语境特征的嵌入向量,h′为注意力加权之后的包含语义特征的嵌入向量,在得到加权之后的两个嵌入向量之后,对两者进行特征拼接,然后将拼接之后的特征向量送入全连接层进行降维,最后得到交互注意力机制的输出特征,具体计算如下所示:
30、a′=wa′·([h′;o′])+ba′
31、其中,为模型的可学习参数,为模型的偏置参数,[h′;o′]表示将包含语境特征的嵌入向量和包含语义特征的嵌入向量按照某一维度进行特征拼接,da为包含语境特征和语义特征高阶语义关联的嵌入向量的维度。
32、作为本发明一种基于中文分词优化的中文语音合成方法的进一步优化:所述步骤s7中的加权自蒸馏机制具体为:
33、通过对教师模型和学生模型的预测输出进行打分,并且将两者的打分结果作为权重系数,对两者的信息流进行加权,指导模型学习文本中的语境特征,具体打分计算过程如下所示。
34、
35、
36、其中,numtrue表示给定文本序列对应标签序列中的标签数量,表示教师模型预测标签序列中标注正确的标签数量,表示学生模型预测标签序列中标注正确的标签数量,wt表示打分机制的教师模型打分,ws表示打分机制的学生模型打分,在得到两个权重系数后,对教师模型和学生模型的输出信息流进行加权,从而实现加权自蒸馏。
37、作为本发明一种基于中文分词优化的中文语音合成方法的进一步优化:所述cws-wsd模型的损失分为两部分:第一部分为自我训练过程的模型损失,将负对数似然函数作为该部分的损失函数。第二部分为自蒸馏过程中的模型损失,模型的第一部分损失、第二部分损失以及总损失函数如下所示:
38、
39、
40、lwsd(θwsd)=λl1+(1-λ)l2
41、其中,θwsd为cws-wsd的模型参数,在模型的训练过程中不断优化;l1(·)为模型的自我训练损失;l2(·)为加权自蒸馏损失;lwsd(·)是cws-wsd的总损失;logitst为教师模型输入解码器的信息流,logitss为学生模型输入解码器的信息流。λ为cws-wsd的超参数,设置目的是为了均衡两类损失。
42、一种电子设备,包括:
43、存储器和位于存储器上的至少一个计算机程序;
44、还包括至少一个处理器,用于处理所述存储器中的至少一个计算机程序,所述处理器执行所述计算机程序时,实现上述的中文语音合成方法的步骤。
45、一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,该计算机程序被处理器执行时实现上述的中文语音合成方法的步骤。
46、本发明具有以下有益效果:本发明通过在语音合成过程中事先对中文文本进行中文分词,来为文本加入词汇边界,进而在生成的语音中对应地加入停顿来缓解前述提到的歧义和交互质量的问题。在中文分词的过程中,本发明进一步提出了一种基于加权自蒸馏的中文分词模型lwseg对机器人将要语音合成的文本进行切分,明确其中的词汇边界,然后根据该边界信息插入相应的停顿标志符,通过文本转语音模型tacotron2进行语音合成,使合成的音频中插入停顿,缓解语音交互中歧义信息的影响,提升机器人语音交互的质量,为患者提供更准确的医疗信息,提高机器人服务质量。
- 还没有人留言评论。精彩留言会获得点赞!