一种嘈杂环境下的语义场景生成方法、设备及介质与流程
本技术涉及音频处理,具体涉及一种嘈杂环境下的语义场景生成方法、设备及介质。
背景技术:
1、在当前的语音识别和自然语言处理领域中,由于环境噪声、说话人口音、背景音乐等因素的影响,传统的语音识别和自然语言处理算法往往难以准确地识别和理解特定的语义场景。
2、目前,主要采用基于语音信号的特征提取和分类方法来实现对特定语义场景的识别和理解。例如,通过分析语音信号的频谱特征、声学特征、韵律特征等,可以对不同的说话人、口音、语速等进行区分和识别。同时,还可以利用机器学习算法对大量的训练数据进行分类和聚类,从而实现对特定语义场景的自动识别和理解。然而,这些方法在复杂的噪声环境中以及不同说话人的口音存在较大差异时,仍然存在一定弊端,并且,最终所识别到的语义场景是否基于上下文、是否具有对话前后逻辑很难得到保证,具有一定的局限性。
技术实现思路
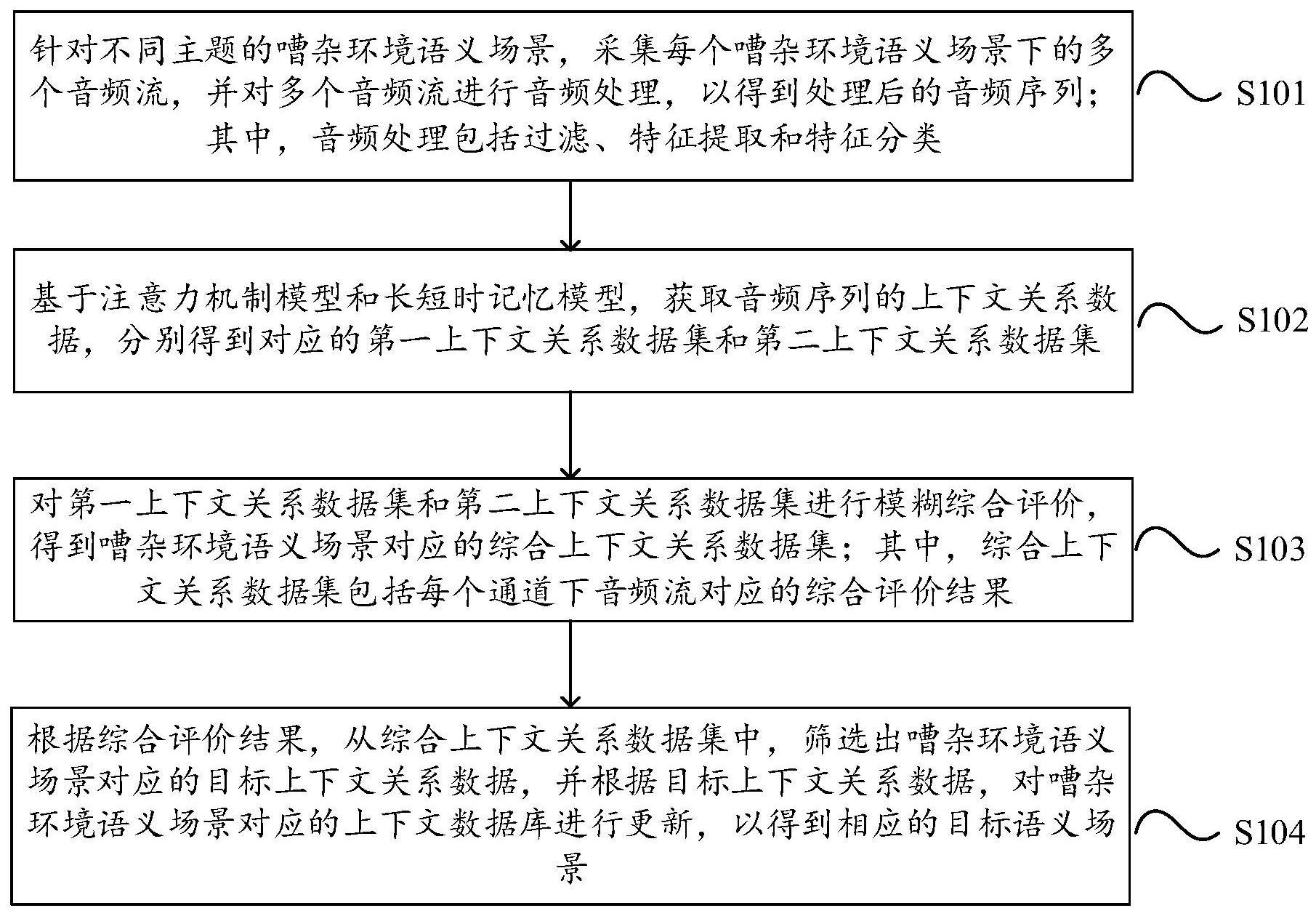
1、为了解决上述问题,本技术提出了一种嘈杂环境下的语义场景生成方法,包括:
2、针对不同主题的嘈杂环境语义场景,采集每个嘈杂环境语义场景下的多个音频流,并对所述多个音频流进行音频处理,以得到处理后的音频序列;其中,所述音频处理包括过滤、特征提取和特征分类;
3、基于注意力机制模型和长短时记忆模型,获取所述音频序列的上下文关系数据,分别得到对应的第一上下文关系数据集和第二上下文关系数据集;
4、对所述第一上下文关系数据集和所述第二上下文关系数据集进行模糊综合评价,得到所述嘈杂环境语义场景对应的综合上下文关系数据集;其中,所述综合上下文关系数据集包括每个通道下音频流对应的综合评价结果;
5、根据所述综合评价结果,从所述综合上下文关系数据集中,筛选出所述嘈杂环境语义场景对应的目标上下文关系数据,并根据所述目标上下文关系数据,对所述嘈杂环境语义场景对应的上下文数据库进行更新,以得到相应的目标语义场景。
6、在本技术的一种实现方式中,对所述第一上下文关系数据集和所述第二上下文关系数据集进行模糊综合评价,得到所述嘈杂环境语义场景对应的综合上下文关系数据集,具体包括:
7、分别获取所述第一上下文关系数据集和所述第二上下文关系数据集对应的评价指标集合,并确定所述评价指标集合中各评价指标分别对应的指标权重;
8、对所述评价指标和其对应的所述指标权重均进行归一化处理,并根据归一化后的所述评价指标和所述指标权重,分别确定所述第一上下文关系数据集对应的第一评价结果和所述第二上下文关系数据集对应的第二评价结果;
9、根据所述第一评价结果和所述第二评价结果,确定每个通道下音频流对应的综合评价结果,并整合所述综合评价结果,得到所述嘈杂环境语义场景对应的综合上下文关系数据集。
10、在本技术的一种实现方式中,基于注意力机制模型和长短时记忆模型,获取所述音频序列的上下文关系数据,分别得到对应的第一上下文关系数据集和第二上下文关系数据集,具体包括:
11、对所述音频序列进行向量化,得到对应的音频特征向量,并通过预设的编码器,对所述音频特征向量进行编码,以确定所述编码器在不同的第一时间步下对应的第一隐藏状态;
12、基于所述注意力机制模型,根据所述第一隐藏状态,确定所述音频序列对应的不同目标语义场景标签的第一概率分布,并根据所述第一概率分布,得到所述音频序列对应的第一上下文关系数据集;
13、对所述音频序列进行语音识别,得到对应的文本输入序列;其中,所述文本输入序列由不同的第二时间步下对应的音频特征向量组成;
14、将所述文本输入序列输入至所述长短时记忆模型,基于所述长短时记忆模型,确定所述文本输入序列在不同第二时间步下分别对应的第二隐藏状态;
15、根据所述第二隐藏状态,预测得到所述音频序列对应的不同目标语义场景标签的第二概率分布,并根据所述第二概率分布,得到所述音频序列对应的第二上下文关系数据集。
16、在本技术的一种实现方式中,根据所述第一隐藏状态,确定所述音频序列对应的不同目标语义场景标签的第一概率分布,具体包括:
17、针对每个第一时间步,将所述第一时间步的上一第一时间步对应的第一隐藏状态输入至预设的解码器中,以通过所述解码器,生成所述第一时间步对应的解码状态;
18、根据不同第一时间步分别对应的第一隐藏状态和所述第一时间步的上一第一时间步对应的解码状态,计算所述第一时间步对应的第一隐藏状态的重要度;
19、针对每个第一时间步,对所述第一时间步下的各所述第一隐藏状态对应的重要度进行加权求和,并将对应的加权求和结果和所述第一时间步对应的解码状态进行向量拼接,以得到所述音频序列对应的不同目标语义场景标签的第一概率分布。
20、在本技术的一种实现方式中,对所述多个音频流进行音频处理,以得到处理后的音频序列,具体包括:
21、将所述多个音频流输入至卷积神经网络中,通过所述卷积神经网络,对所述音频流进行卷积操作和下采样,并对经过所述下采样得到的池化结果进行平均处理,得到全局特征向量;
22、对所述全局特征向量进行全连接操作,得到分类结果,根据所述分类结果,从所述多个音频流中,剔除所述嘈杂环境语义场景的指定音频信息;其中,所述指定音频信息至少包括环境音、杂音;
23、对剔除掉所述指定音频信息的音频流进行特征提取和特征分类,得到处理后的音频序列。
24、在本技术的一种实现方式中,对剔除掉所述指定音频信息的音频流进行特征提取和特征分类,得到处理后的音频序列,具体包括:
25、对剔除掉所述指定音频信息的音频流进行短时傅里叶变换,得到所述音频流对应的时频信息,并对所述时频信息的幅值和相位进行分类处理,分别得到对应的幅值谱和相位谱;
26、将所述幅值谱输入至所述卷积神经网络中,输出所述音频流对应的语音识别结果,根据所述语音识别结果,确定所述音频流对应的音频序列。
27、在本技术的一种实现方式中,将所述幅值谱输入至所述卷积神经网络中,输出所述音频流对应的语音识别结果,根据所述语音识别结果,确定所述音频流对应的音频序列,具体包括:
28、将所述幅值谱输入至所述卷积神经网络中,通过所述卷积神经网络对所述幅值谱进行特征提取,提取出所述音频流对应的频域特征;
29、对所述频域特征进行特征分类,得到所述音频流对应的语音识别结果,并通过时间抑制算法,对所述语音识别结果进行平滑处理,得到处理后的音频序列。
30、在本技术的一种实现方式中,得到相应的目标语义场景之后,所述方法还包括:
31、采集嘈杂环境语义场景中的指定场景音频流,并对所述指定场景音频流进行音频处理,以得到处理后的指定音频序列;
32、通过所述注意力机制模型,对所述指定音频序列进行上下文识别,并确定识别出的第一上下文关系数据对应的第一正确率;
33、通过所述长短时记忆模型,对所述指定音频序列进行上下文识别,并确定识别出的第二上下文关系数据对应的第二正确率;
34、将所述第一正确率和第二正确率分别与其对应的正确率阈值进行对比,以从所述第一上下文关系数据和所述第二上下文关系数据中,筛选出对应正确率大于所述正确率阈值的目标上下文关系数据;
35、通过所述目标上下文关系数据,确定所述指定场景音频流对应的答案或反问槽值。
36、本技术实施例提供了一种嘈杂环境下的语义场景生成设备,所述设备包括:
37、至少一个处理器;
38、以及,与所述至少一个处理器通信连接的存储器;
39、其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行如上述的一种嘈杂环境下的语义场景生成方法。
40、本技术实施例提供了一种非易失性计算机存储介质,存储有计算机可执行指令,所述计算机可执行指令设置为:执行如上述的一种嘈杂环境下的语义场景生成方法。
41、通过本技术提出的一种嘈杂环境下的语义场景生成方法能够带来如下有益效果:
42、对嘈杂环境语义场景中采集到的音频流进行音频处理,能够处理嘈杂环境中的噪声、说话人的口音差异等干扰因素。通过注意力机制模型和长短时记忆模型,能够捕捉音频序列中的上下文信息,保证对话的前后逻辑,从而提高对特定语义场景的识别和理解能力。利用模糊综合评价得到嘈杂环境语义场景中的目标上下文关系数据,通过该目标上下文关系数据,能够让语音交互系统在新场景下更快地适应和学习,生成更为符合用户需求的目标语义场景。
- 还没有人留言评论。精彩留言会获得点赞!