情感语音合成方法、装置、电子设备和计算机存储介质与流程
本发明涉及语音合成,特别是涉及一种情感语音合成方法、一种情感语音合成装置、一种电子设备和一种计算机可读存储介质。
背景技术:
1、目前的语音合成多采用大规模预训练与微调训练的方式,由于大量样本训练好的基础模型已经能够表述目标模型的大部分特征,所以只需要在基础模型上继续叠加训练就能拟合小样本数据又不缺失小样本数据不包含的大量特征。
2、但是目前的语音合成主要聚焦于对少量录音的发音人进行声音复刻,并没有针对情感特征进行小样本训练,从而造成在面向情感语音合成的效果方面略有欠缺。
技术实现思路
1、鉴于上述问题,提出了本发明实施例以便提供一种克服上述问题或者至少部分地解决上述问题的一种情感语音合成方法、一种情感语音合成装置、一种电子设备和一种计算机可读存储介质。
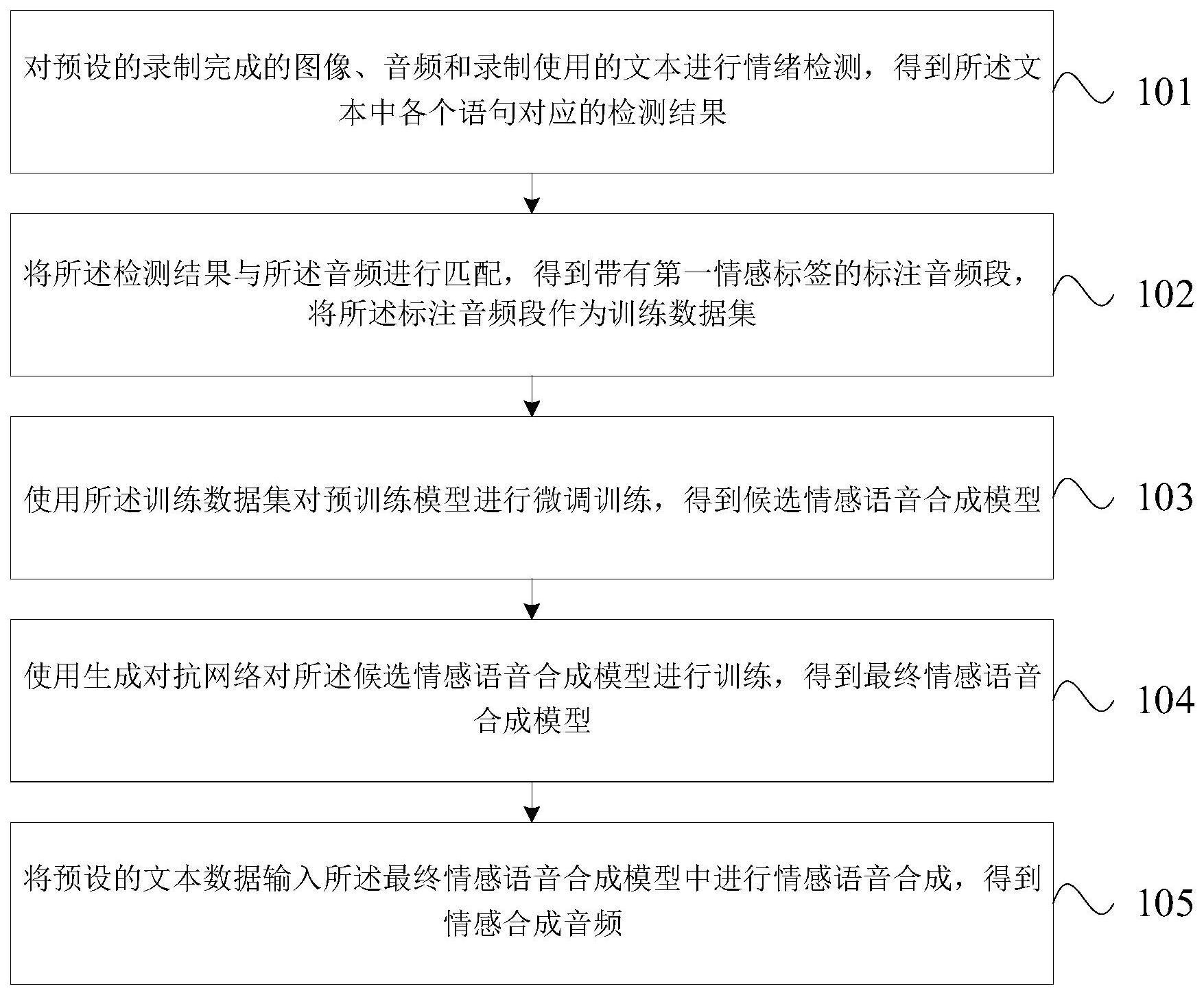
2、为了解决上述问题,本发明实施例公开了一种情感语音合成的方法,所述方法包括:
3、对预设的录制完成的图像、音频和录制使用的文本进行情绪检测,得到所述文本中各个语句对应的检测结果;
4、将所述检测结果与所述音频进行匹配,得到带有第一情感标签的标注音频段,将所述标注音频段作为训练数据集;
5、使用所述训练数据集对预训练模型进行微调训练,得到候选情感语音合成模型;
6、使用生成对抗网络对所述候选情感语音合成模型进行训练,得到最终情感语音合成模型;
7、将预设的文本数据输入所述最终情感语音合成模型中进行情感语音合成,得到情感合成音频。
8、在一个或多个实施例中,所述对预设的录制完成的图像、音频和录制使用的文本进行情绪检测,包括:
9、对所述图像进行图像特征提取,得到所述图像的图像特征;
10、对所述音频进行音频特征提取,得到所述音频的音频特征;
11、对所述录制使用的文本进行文本特征提取,得到所述文本的文本特征;
12、将所述图像特征、所述音频特征和所述文本特征进行特征融合,得到最终特征;
13、对所述最终特征进行情绪检测。
14、在一个或多个实施例中,所述将所述检测结果与所述音频进行匹配,包括:
15、获取所述音频中与各个语句对应的音频段;
16、将各个语句对应的检测结果与各个音频段进行一一匹配,得到带有第一情感标签的各个标注音频段。
17、在一个或多个实施例中,所述预设的预训练模型通过如下方式生成:
18、使用预设的带有第二情感标签的语音标注数据对原始的语音合成模型进行训练,所述第二情感标签通过情感特征分类的方式进行标注。
19、在一个或多个实施例中,所述使用生成对抗网络对所述候选情感语音合成模型进行训练,得到最终情感语音合成模型,包括:
20、s1、将候选情感语音合成模型作为第一生成器,输入预设的带有第三情感标签的文本,生成第一情感合成音频;
21、s2、将第一音频情绪检测模块作为第一鉴别器,输入所述第一情感合成音频,按照所述第三情感标签进行判断,计算所述第一生成器的损失函数和所述第一鉴别器的损失函数;
22、s3、采用所述第一生成器的损失函数和所述第一鉴别器的损失函数对所述第一生成器和所述第一鉴别器进行更新,得到更新后的第二生成器和第二鉴别器;
23、s4、重复s1至s3,直至更新次数满足预设的更新次数的最大值,得到最终生成器和最终鉴别器,所述最终生成器为最终情感语音合成模型。
24、相应的,本发明实施例公开了一种情感语音合成的装置,所述装置包括:
25、多模态情绪检测模块,用于对预设的录制完成的图像、音频和录制使用的文本进行情绪检测,得到所述文本中各个语句对应的检测结果;
26、匹配模块,用于将所述检测结果与所述音频进行匹配,得到带有第一情感标签的标注音频段,将所述标注音频段作为训练数据集;
27、微调训练模块,用于使用所述训练数据集对预训练模型进行微调训练,得到候选情感语音合成模型;
28、对抗网络训练模块,用于使用生成对抗网络对所述候选情感语音合成模型进行训练,得到最终情感语音合成模型;
29、生成模块,用于将预设的文本数据输入所述最终情感语音合成模型中进行情感语音合成,得到情感合成音频。
30、在一个或多个实施例中,所述多模态情绪检测模块,用于对预设的录制完成的图像、音频和录制使用的文本进行情绪检测,得到所述文本中各个语句对应的检测结果;
31、所述装置还包括:
32、多模态情绪检测子模块,用于对所述图像进行图像特征提取,得到所述图像的图像特征;
33、对所述音频进行音频特征提取,得到所述音频的音频特征;
34、对所述录制使用的文本进行文本特征提取,得到所述文本的文本特征;
35、将所述图像特征、所述音频特征和所述文本特征进行特征融合,得到最终特征;
36、对所述最终特征进行情绪检测。
37、在一个或多个实施例中,所述匹配模块,用于将所述检测结果与所述音频进行匹配,得到带有第一情感标签的标注音频段,将所述标注音频段作为训练数据集;
38、所述装置还包括:
39、匹配子模块,用于获取所述音频中与各个语句对应的音频段;
40、将各个语句对应的检测结果与各个音频段进行一一匹配,得到带有第一情感标签的各个标注音频段。
41、在一个或多个实施例中,所述微调训练模块,用于使用所述训练数据集对预训练模型进行微调训练,得到候选情感语音合成模型;
42、所述装置还包括:
43、预训练模型生成子模块,用于使用预设的带有第二情感标签的语音标注数据对原始的语音合成模型进行训练,所述第二情感标签通过情感特征分类的方式进行标注,得到预训练模型。
44、在一个或多个实施例中,所述对抗网络训练模块,用于使用生成对抗网络对所述候选情感语音合成模型进行训练,得到最终情感语音合成模型;
45、所述装置还包括:
46、合成音频生成子模块:用于将候选情感语音合成模型作为第一生成器,输入预设的带有第三情感标签的文本,生成第一情感合成音频;
47、损失函数计算子模块:用于将第一音频情绪检测模块作为第一鉴别器,输入所述第一情感合成音频,按照所述第三情感标签进行判断,计算所述第一生成器的损失函数和所述第一鉴别器的损失函数;
48、更新子模块:用于采用所述第一生成器的损失函数和所述第一鉴别器的损失函数对所述第一生成器和所述第一鉴别器进行更新,得到更新后的第二生成器和第二鉴别器;
49、重复子模块:用于重复调用所述合成音频生成子模块、所述损失函数计算子模块和所述更新子模块,直至更新次数满足预设的更新次数的最大值,得到最终生成器和最终鉴别器,所述最终生成器为最终情感语音合成模型。
50、相应的,本发明实施例公开了一种电子设备,包括:处理器、存储器及存储在所述存储器上并能够在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现上述情感语音合成方法实施例的各个步骤。
51、相应的,本发明实施例公开了一种计算机可读存储介质,所述计算机可读存储介质上存储计算机程序,所述计算机程序被处理器执行时实现上述情感语音合成方法实施例的各个步骤。
52、本发明实施例包括以下优点:
53、本发明实施例的情感语音合成方法,先对预设的录制完成的图像、音频和录制使用的文本进行情绪检测,得到所述文本中各个语句对应的检测结果,然后将所述检测结果与所述音频进行匹配,得到带有第一情感标签的标注音频段,将所述标注音频段作为训练数据集,再使用所述训练数据集对预训练模型进行微调训练,得到候选情感语音合成模型,再使用生成对抗网络对所述候选情感语音合成模型进行训练,得到最终情感语音合成模型,最后将预设的文本数据输入所述最终情感语音合成模型中进行情感语音合成,就能得到情感合成音频。通过上述方式,对录音人在整个录音过程中的视频、音频、文本进行综合性的情感分析,从而获得了更加精准的情感标注结果;在预训练模型使用训练数据集作为小样本进行训练的过程中,加入情感标注的特征维度,从而提升了小样本语音合成模型所生成出的音频的情感表达效果;结合生成对抗网络gan,针对模型生成音频的情感进行博弈调优,从而进一步优化了合成音频的情感表达效果。
- 还没有人留言评论。精彩留言会获得点赞!