一种基于Transformer全局特征的音素识别方法
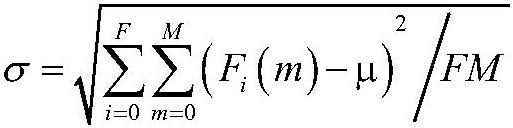
本发明涉及一种基于transformer全局特征的音素识别方法,属于语音识别。
背景技术:
1、音素识别属于语音识别领域,语音识别的模型大多能应用于音素识别。音素识别将语音转换为一段发音序列,这段发音序列可以应用于语音中敏感词、违禁词、污秽词的检测,对于信息化时代具有重要意义。音素识别一般采用的语音学特征主要有梅尔倒谱系数(mel-frequency cepstral coefficients,mfcc)、感知线性预测系数(perceptrallinearprediction coefficients,plpc)、伽马通滤波器倒谱系数(gammatone filtercepstralcoefficients,gfcc)、fbank特征等,上述特征在音素任务中表现较好的为fbank特征。音素识别常用的模型有gmm-hmm、dnn-hmm、ctc端到端模型等,但是上述模型对于全局特征的关注性不够。为了提高音素识别的识别率,需要对这些模型加以改进,基于transformer全局特征的音素识别方法应运而生。
技术实现思路
1、本发明提供了一种基于transformer全局特征的音素识别方法,用于解决音素识别模型对全局特征关注度不够的问题。
2、本发明的技术方案:一种基于transformer全局特征的音素识别方法,首先在前端对原语音信号进行预加重、分帧、加窗操作,接着对每一帧信号进行快速傅里叶变换、取模得到幅度谱,然后通过等高mel滤波器组进行滤波、取对数得到静态fbank特征参数,并使其标准化,再经过帧数的一、二阶差分得到动态特征。最后将fbank总特征通过transformer编码器,提取更为抽象的全局特征输入cnn-rnn-ctc端到端音素识别系统进行验证,得到识别结果。
3、具体步骤为:
4、step1:对语音信号进行预处理操作,具体操作包括预加重、分帧、加窗。
5、原始的语音信号为x(n),n=0,1,2,…,t,t为总采样点数,预加重处理为:
6、x′(n)=x(n)-αx(n-1 )(1)
7、式中x′(n)为预加重后的信号,α一般取0.97。预加重是为了补偿声音在传播到人耳过程中的快速衰减的高频。
8、分帧是为了将非平稳的长语音信号切分成平稳的短语音信号,帧长一般取10ms~30ms。接着为了每帧信号之间能够平滑过度,还设置了帧移,帧移重叠部分取帧长的1/3~1/2,但本发明中不进行帧移操作。大量实验表明,增加帧移和去除帧移的识别率结果相差无几,去除帧移后,还能大幅度提高运算效率。所以分帧之后的帧长为n,帧移为0ms,帧数为f,第i帧信号为xi′(n),0≤i≤f。
9、加窗的目的是为了减少语音信号分帧之后产生的频谱泄露问题,加窗的类型为汉明窗(hamming),hamming窗的表达式为:
10、
11、(2)式中的n代表窗的长度,第i帧信号xi′(n)加窗之后得到yi(n),yi(n)的表达式为:
12、yi(n)=xi′(n)×w(n),n=0,1,…,n (3)
13、step2:将预处理的信号进行快速傅里叶变换,取模得到幅度谱。
14、对yi(n)进行快速傅里叶变换(fft),将时域信号yi(n)转为频域信号xi(k),k=0,1,…,k,更利于捕捉语音中的信息分量。变换后每一帧的点数为k,k=n,表达式为:
15、xi(k)=fft[yi(n)],0≤i≤f (4)
16、傅里叶变换后的数值具有实数和虚数,所以接着对频域信号xi(k)进行取模操作得到|xi(k)|。
17、step3:得到幅度谱|xi(k)|后,将其输入到等高mel滤波器组(mel filter banks)进行滤波,该滤波器组模仿人耳听觉特性而设计,可以较好地突出语音中的共振峰,共振峰对于语音识别和音素识别来说具有重要的特征关系。
18、将|xi(k)|通过mel滤波器组滤波得到每一帧的谱线能量si(m),m=0,1,…,m,m为滤波器组的个数,f为分帧数,滤波表达式为:
19、
20、melm(k)代表mel滤波器组当中第m个滤波器的第k个值。
21、step4:滤波后,将信号进行常用对数运算得到静态fbank特征,并使其标准化。
22、对滤波之后的信号si(m)取常用对数得到静态fbank特征参数fi(m),表达式为:
23、fi(m)=ln(si(m)),0≤i≤f (6)
24、为了便于神经网络学习训练,需要对fi(m)进行标准化,使得数据分布的均值为0,标准差为1,表达式为:
25、
26、
27、fi(m)=(fi(m)-μ)/σ,m=0,1,…,m,0≤i≤f (9)
28、step5:对标准化后的特征进行一二阶差分得到动态特征。
29、静态特征不能很好地表达语音信息,需要融入语音变化的动态特征,对标准化后的fi(m)进行一二阶帧数差分得到动态特征fi′(m)、fi″(m),表达式为:
30、fi′(m)=fi+1(m)-fi(m),0≤i≤f-1 (10)
31、fi″(m)=f′i+1(m)-fi′(m)=fi+2(m)-2fi+1(m)+fi(m),0≤i≤f-2 (11)
32、将静态特征fi(m)和动态特征fi′(m)、fi″(m)进行拼接合并得到fbank总特征fj(m),表达式为:
33、fj(m)=[fi(m),fi′(m),fi″(m)],0≤m≤m,0≤j≤3f (12)
34、拼接以前,帧数维度为f,拼接以后,帧数维度为3f,m=0,1,…,m。
35、step6:将fbank总特征输入transformer编码器进行全局特征处理。
36、得到fbank总特征后,需要进行全局信息的处理,音素与字词需要考虑上下文的语境才能得到准确的表达意思。利用transformer模型中的编码器进行抽象特征的提取,fj(m)首先经过位置编码,表达式为:
37、
38、dmodel为位置编码的维度,一般dmodel=m,m设定为偶数,方便位置编码。pos为行的位置索引,i为列的位置索引。fj(m)经过transformer编码器编码后得到pj(m),其中m=0,1,…,m,0≤j≤3f。
39、fj(m)的矩阵维度大小为3f×m,经过自注意力网络后得到aj(m),维度大小为3f×m,运算表达式为:
40、q=fj(m)×wq (14)
41、k=fj(m)×wk (15)
42、v=fj(m)×wv (16)
43、
44、wq、wk、wv为参数学习矩阵,维度为m×m。q为查询矩阵,维度3f×m,k为键矩阵,维度3f×m,v为值矩阵,维度3f×m,dn为q、k、v矩阵的列维度,dn=m。
45、接着通过残差连接,表达式为:
46、cj(m)=fj(m)+r(fj(m)) (18)
47、在公式中,输入为fj(m),残差连接输出是r(fj(m))。其中每一个残差单元包括卷积层、批量归一化层、非线性激活函数和跳跃连接运算。残差连接以后得到cj(m),维度3f×m。
48、最后再次通过前馈网络和残差连接得到完整的一层编码器结构。
49、step7:将全局特征输入端到端网络进行音素序列识别,端到端模型采用cnn-rnn-ctc网络。
50、本发明的有益效果是:本发明提出的音素识别方法不仅在纯净语音下有效,在噪声环境下也提升了识别率。
- 还没有人留言评论。精彩留言会获得点赞!