音频诊断方法、装置、计算机设备和存储介质与流程
本技术涉及音频处理,特别是涉及一种音频诊断方法、装置、计算机设备、存储介质和计算机程序产品。
背景技术:
1、在金融业务场景中,有时候需要对金融系统的音频进行审核,比如贷款面签过程中的音频。为了保证音频内容的有效性,需要对音频进行诊断,避免音频被篡改伪造,影响音频审核结果。
2、传统技术中,对金融系统的音频进行诊断时,主要是通过单一维度对音频进行诊断,比如检测音频的声纹,判断音频是否伪造。但是,通过这种单一维度的音频诊断方法,容易存在误判或者错判,导致音频诊断准确率较低。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种能够音频诊断准确率的音频诊断方法、装置、计算机设备、计算机可读存储介质和计算机程序产品。
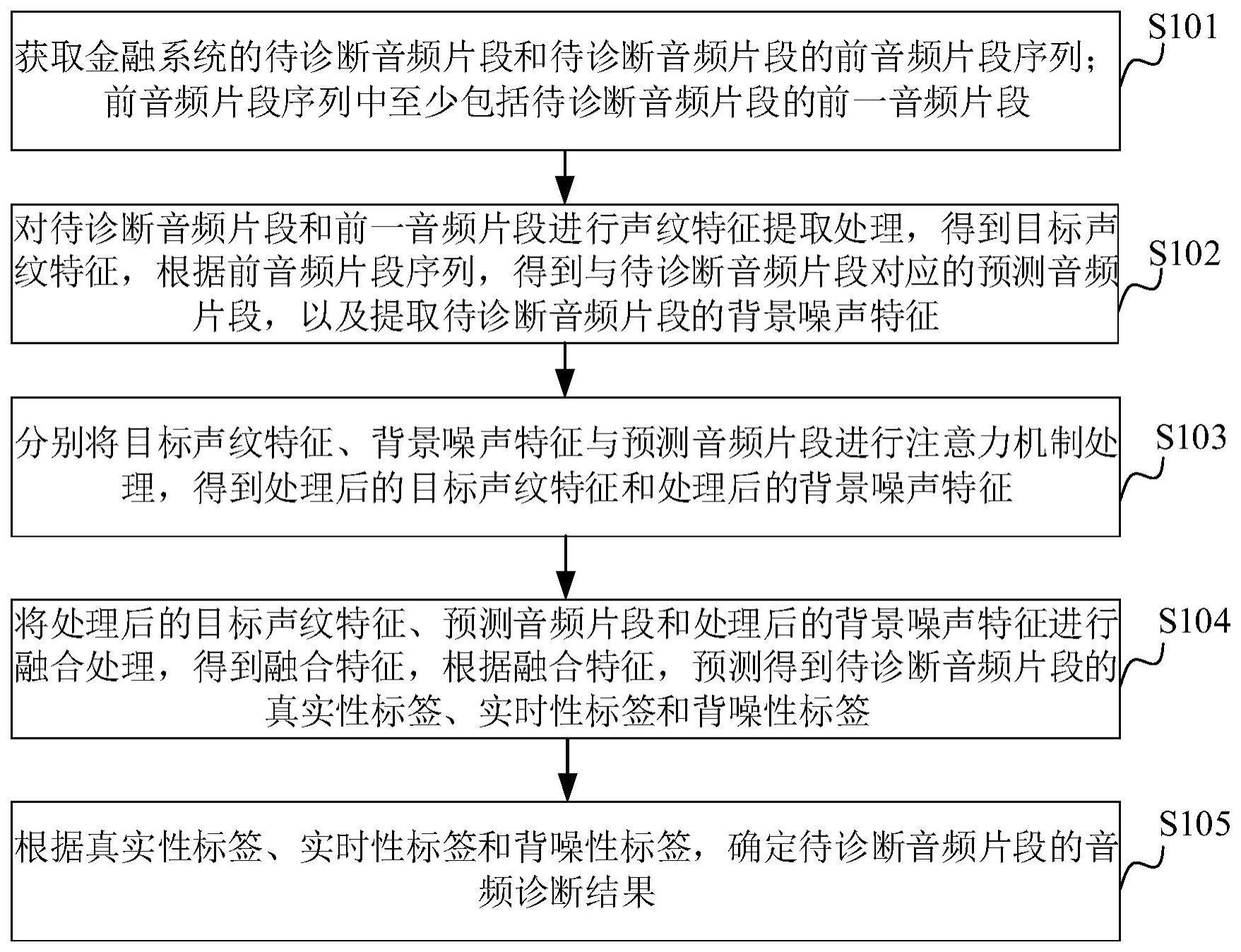
2、第一方面,本技术提供了一种音频诊断方法。所述方法包括:
3、获取金融系统的待诊断音频片段和所述待诊断音频片段的前音频片段序列;所述前音频片段序列中至少包括所述待诊断音频片段的前一音频片段;
4、对所述待诊断音频片段和所述前一音频片段进行声纹特征提取处理,得到目标声纹特征,根据所述前音频片段序列,得到与所述待诊断音频片段对应的预测音频片段,以及提取所述待诊断音频片段的背景噪声特征;所述目标声纹特征包括所述待诊断音频片段的第一声纹特征和所述前一音频片段的第二声纹特征;
5、分别将所述目标声纹特征、所述背景噪声特征与所述预测音频片段进行注意力机制处理,得到处理后的目标声纹特征和处理后的背景噪声特征;
6、将所述处理后的目标声纹特征、所述预测音频片段和所述处理后的背景噪声特征进行融合处理,得到融合特征,根据所述融合特征,预测得到所述待诊断音频片段的真实性标签、实时性标签和背噪性标签;
7、根据所述真实性标签、所述实时性标签和所述背噪性标签,确定所述待诊断音频片段的音频诊断结果。
8、在其中一个实施例中,所述对所述待诊断音频片段和所述前一音频片段进行声纹特征提取处理,得到目标声纹特征,根据所述前音频片段序列,得到与所述待诊断音频片段对应的预测音频片段,以及提取所述待诊断音频片段的背景噪声特征,包括:
9、将所述待诊断音频片段和所述前一音频片段,输入预先训练的音频诊断模型中的声纹特征提取网络,得到所述第一声纹特征和所述第二声纹特征,将所述第一声纹特征和所述第二声纹特征进行组合,得到目标声纹特征;
10、将所述前音频片段序列输入所述预先训练的音频诊断模型中的声音序列预测网络,得到与所述待诊断音频片段对应的预测音频片段;
11、将所述待诊断音频片段输入所述预先训练的音频诊断模型中的噪声特征提取网络和噪声水平建模网络,得到所述待诊断音频片段的背景噪声特征。
12、在其中一个实施例中,所述分别将所述目标声纹特征、所述背景噪声特征与所述预测音频片段进行注意力机制处理,得到处理后的目标声纹特征和处理后的背景噪声特征,包括:
13、将所述目标声纹特征与所述预测音频片段,输入所述预先训练的音频诊断模型中的第一注意力机制处理层,得到处理后的目标声纹特征;
14、将所述背景噪声特征与所述预测音频片段,输入所述预先训练的音频诊断模型中的第二注意力机制处理层,得到处理后的背景噪声特征;
15、所述将所述处理后的目标声纹特征、所述预测音频片段和所述处理后的背景噪声特征进行融合处理,得到融合特征,根据所述融合特征,预测得到所述待诊断音频片段的真实性标签、实时性标签和背噪性标签,包括:
16、将所述处理后的目标声纹特征、所述预测音频片段和所述处理后的背景噪声特征,输入所述预先训练的音频诊断模型中的拼接层进行拼接处理,得到拼接特征,作为所述融合特征;
17、将所述融合特征输入所述预先训练的音频诊断模型中的多标签预测层,得到所述待诊断音频片段的真实性标签、实时性标签和背噪性标签。
18、在其中一个实施例中,所述预先训练的音频诊断模型通过下述方式训练得到:
19、分别对待训练的音频诊断模型中的待训练声纹特征提取网络、待训练声音序列预测网络、待训练噪声特征提取网络和待训练噪声水平建模网络进行单独预训练,得到预训练声纹特征提取网络、预训练声音序列预测网络、预训练噪声特征提取网络和预训练噪声水平建模网络,并将所述预训练声音序列预测网络作为所述声音序列预测网络;
20、根据所述预训练声纹特征提取网络、所述声音序列预测网络、所述预训练噪声特征提取网络和所述预训练噪声水平建模网络,对所述待训练的音频诊断模型进行更新,得到预训练的音频诊断模型;
21、将样本音频片段、所述样本音频片段的前一样本音频片段和所述样本音频片段的前样本音频片段序列,输入所述预训练的音频诊断模型,得到所述样本音频片段的预测真实性标签、预测实时性标签和预测背噪性标签;
22、根据所述样本音频片段的预测真实性标签、预测实时性标签和预测背噪性标签,以及所述样本音频片段的实际真实性标签、实际实时性标签和实际背噪性标签,对所述预训练的音频诊断模型进行训练,得到训练完成的音频诊断模型,作为所述预先训练的音频诊断模型。
23、在其中一个实施例中,所述根据所述样本音频片段的预测真实性标签、预测实时性标签和预测背噪性标签,以及所述样本音频片段的实际真实性标签、实际实时性标签和实际背噪性标签,对所述预训练的音频诊断模型进行训练,得到训练完成的音频诊断模型,包括:
24、根据所述预测真实性标签和所述实际真实性标签之间的差异,得到第一损失值,根据所述预测实时性标签和所述实际实时性标签之间的差异,得到第二损失值,以及根据所述预测背噪性标签和所述实际背噪性标签之间的差异,得到第三损失值;
25、将所述第一损失值、所述第二损失值和所述第三损失值进行融合处理,得到目标损失值;
26、根据所述目标损失值,对所述预训练的音频诊断模型中除所述声音序列预测网络之外的网络对应的网络参数进行调整,并对调整后的音频诊断模型进行训练,直到达到训练结束条件;
27、将达到所述训练结束条件的训练后的音频诊断模型,作为训练完成的音频诊断模型。
28、在其中一个实施例中,所述根据所述真实性标签、所述实时性标签和所述背噪性标签,确定所述待诊断音频片段的音频诊断结果,包括:
29、获取所述真实性标签的第一权重、所述实时性标签的第二权重和所述背噪性标签的第三权重;
30、根据所述第一权重、所述第二权重和所述第三权重,对所述真实性标签对应的分数、所述实时性标签对应的分数和所述背噪性标签对应的分数进行融合处理,得到目标分数;
31、根据所述目标分数,确定所述待诊断音频片段的音频诊断结果。
32、在其中一个实施例中,所述根据所述真实性标签、所述实时性标签和所述背噪性标签,确定所述待诊断音频片段的音频诊断结果,还包括:
33、获取所述真实性标签对应的分数与第一预设分数之间的第一对比结果、所述实时性标签对应的分数与第二预设分数之间的第二对比结果、所述背噪性标签对应的分数与第三预设分数之间的第三对比结果;
34、根据所述第一对比结果、所述第二对比结果和所述第三对比结果,确定所述待诊断音频片段的音频诊断结果。
35、第二方面,本技术还提供了一种音频诊断装置。所述装置包括:
36、音频获取模块,用于获取金融系统的待诊断音频片段和所述待诊断音频片段的前音频片段序列;所述前音频片段序列中至少包括所述待诊断音频片段的前一音频片段;
37、特征提取模块,用于对所述待诊断音频片段和所述前一音频片段进行声纹特征提取处理,得到目标声纹特征,根据所述前音频片段序列,得到与所述待诊断音频片段对应的预测音频片段,以及提取所述待诊断音频片段的背景噪声特征;所述目标声纹特征包括所述待诊断音频片段的第一声纹特征和所述前一音频片段的第二声纹特征;
38、特征处理模块,用于分别将所述目标声纹特征、所述背景噪声特征与所述预测音频片段进行注意力机制处理,得到处理后的目标声纹特征和处理后的背景噪声特征;
39、标签确定模块,用于将所述处理后的目标声纹特征、所述预测音频片段和所述处理后的背景噪声特征进行融合处理,得到融合特征,根据所述融合特征,预测得到所述待诊断音频片段的真实性标签、实时性标签和背噪性标签;
40、结果确定模块,用于根据所述真实性标签、所述实时性标签和所述背噪性标签,确定所述待诊断音频片段的音频诊断结果。
41、第三方面,本技术还提供了一种计算机设备。所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
42、获取金融系统的待诊断音频片段和所述待诊断音频片段的前音频片段序列;所述前音频片段序列中至少包括所述待诊断音频片段的前一音频片段;
43、对所述待诊断音频片段和所述前一音频片段进行声纹特征提取处理,得到目标声纹特征,根据所述前音频片段序列,得到与所述待诊断音频片段对应的预测音频片段,以及提取所述待诊断音频片段的背景噪声特征;所述目标声纹特征包括所述待诊断音频片段的第一声纹特征和所述前一音频片段的第二声纹特征;
44、分别将所述目标声纹特征、所述背景噪声特征与所述预测音频片段进行注意力机制处理,得到处理后的目标声纹特征和处理后的背景噪声特征;
45、将所述处理后的目标声纹特征、所述预测音频片段和所述处理后的背景噪声特征进行融合处理,得到融合特征,根据所述融合特征,预测得到所述待诊断音频片段的真实性标签、实时性标签和背噪性标签;
46、根据所述真实性标签、所述实时性标签和所述背噪性标签,确定所述待诊断音频片段的音频诊断结果。
47、第四方面,本技术还提供了一种计算机可读存储介质。所述计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
48、获取金融系统的待诊断音频片段和所述待诊断音频片段的前音频片段序列;所述前音频片段序列中至少包括所述待诊断音频片段的前一音频片段;
49、对所述待诊断音频片段和所述前一音频片段进行声纹特征提取处理,得到目标声纹特征,根据所述前音频片段序列,得到与所述待诊断音频片段对应的预测音频片段,以及提取所述待诊断音频片段的背景噪声特征;所述目标声纹特征包括所述待诊断音频片段的第一声纹特征和所述前一音频片段的第二声纹特征;
50、分别将所述目标声纹特征、所述背景噪声特征与所述预测音频片段进行注意力机制处理,得到处理后的目标声纹特征和处理后的背景噪声特征;
51、将所述处理后的目标声纹特征、所述预测音频片段和所述处理后的背景噪声特征进行融合处理,得到融合特征,根据所述融合特征,预测得到所述待诊断音频片段的真实性标签、实时性标签和背噪性标签;
52、根据所述真实性标签、所述实时性标签和所述背噪性标签,确定所述待诊断音频片段的音频诊断结果。
53、第五方面,本技术还提供了一种计算机程序产品。所述计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现以下步骤:
54、获取金融系统的待诊断音频片段和所述待诊断音频片段的前音频片段序列;所述前音频片段序列中至少包括所述待诊断音频片段的前一音频片段;
55、对所述待诊断音频片段和所述前一音频片段进行声纹特征提取处理,得到目标声纹特征,根据所述前音频片段序列,得到与所述待诊断音频片段对应的预测音频片段,以及提取所述待诊断音频片段的背景噪声特征;所述目标声纹特征包括所述待诊断音频片段的第一声纹特征和所述前一音频片段的第二声纹特征;
56、分别将所述目标声纹特征、所述背景噪声特征与所述预测音频片段进行注意力机制处理,得到处理后的目标声纹特征和处理后的背景噪声特征;
57、将所述处理后的目标声纹特征、所述预测音频片段和所述处理后的背景噪声特征进行融合处理,得到融合特征,根据所述融合特征,预测得到所述待诊断音频片段的真实性标签、实时性标签和背噪性标签;
58、根据所述真实性标签、所述实时性标签和所述背噪性标签,确定所述待诊断音频片段的音频诊断结果。
59、上述音频诊断方法、装置、计算机设备、存储介质和计算机程序产品,通过获取金融系统的待诊断音频片段和待诊断音频片段的前音频片段序列;前音频片段序列中至少包括待诊断音频片段的前一音频片段;然后对待诊断音频片段和前一音频片段进行声纹特征提取处理,得到目标声纹特征,根据前音频片段序列,得到与待诊断音频片段对应的预测音频片段,以及提取待诊断音频片段的背景噪声特征;目标声纹特征包括待诊断音频片段的第一声纹特征和前一音频片段的第二声纹特征;接着分别将目标声纹特征、背景噪声特征与预测音频片段进行注意力机制处理,得到处理后的目标声纹特征和处理后的背景噪声特征;最后将处理后的目标声纹特征、预测音频片段和处理后的背景噪声特征进行融合处理,得到融合特征,根据融合特征,预测得到待诊断音频片段的真实性标签、实时性标签和背噪性标签;根据真实性标签、实时性标签和背噪性标签,确定待诊断音频片段的音频诊断结果。这样,通过对待诊断音频片段和待诊断音频片段的前音频片段序列进行一系列分析,得到待诊断音频片段的真实性标签、实时性标签和背噪性标签,有利于从多个音频诊断维度对音频进行诊断,使得最终得到的音频诊断结果更加准确,从而提高了音频诊断准确率;避免了从单一维度对音频进行诊断,容易存在误判或者错判,导致音频诊断准确率较低的缺陷。
- 还没有人留言评论。精彩留言会获得点赞!