一种基于音频同步渲染的点歌控制系统的制作方法
本发明涉及音频信号处理,特别涉及一种基于音频同步渲染的点歌控制系统。
背景技术:
1、随着模拟信号和数字信号处理技术的发展,ktv逐渐成为大众的娱乐潮流。ktv在被市场所接受和认可过程中,互动娱乐化的发展理念和专业舒适的听感体验,将成为ktv产业发展的新标杆。目前,一套完整的ktv系统由三个系统组成:点歌系统、音响系统、视频系统。点歌机是提供卡拉ok歌曲的音响系统的配合主要和房间面积、功能密切相关。主要设备包含:功放、音箱、效果器、话筒,当然有些功放会集成效果器的功能,也可以不单独选配效果器。近年来,互联网技术日益成熟,线上k歌迅速扩张,相比于传统的ktv,线上k歌适用人群广,不受空间地域限制且功能多样,满足人们在碎片化时代的唱歌需求。目前,k歌行业主打“唱歌+社交”的平台受到更多用户的欢迎。例如全民k歌进行唱歌、交友娱乐、学习唱歌、声乐教学等,这款软件具有系统计分、乐句重唱、专业音效、好友pk、互动交流及分享功能。
2、现有技术中的k歌/ktv系统都需要演唱者手动调音以得到较为满意的声音,由于大部分演唱者均非专业调音师,演唱者只能从多种场景中进行喜好的挑选,无法达到最佳的效果;并且有些修音软件会过度修音,虽然能提升歌声的表现效果,但容易失真,现有的渲染工具只能对唱歌的人实时唱出来的歌曲声纹信息进行调整,所以,不管如何调整,还是存在一定的瑕疵,无法达到最标准的地步。
技术实现思路
1、本发明提供一种基于音频同步渲染的点歌控制系统,用以避免由于过度修音使得声音失真的情况。
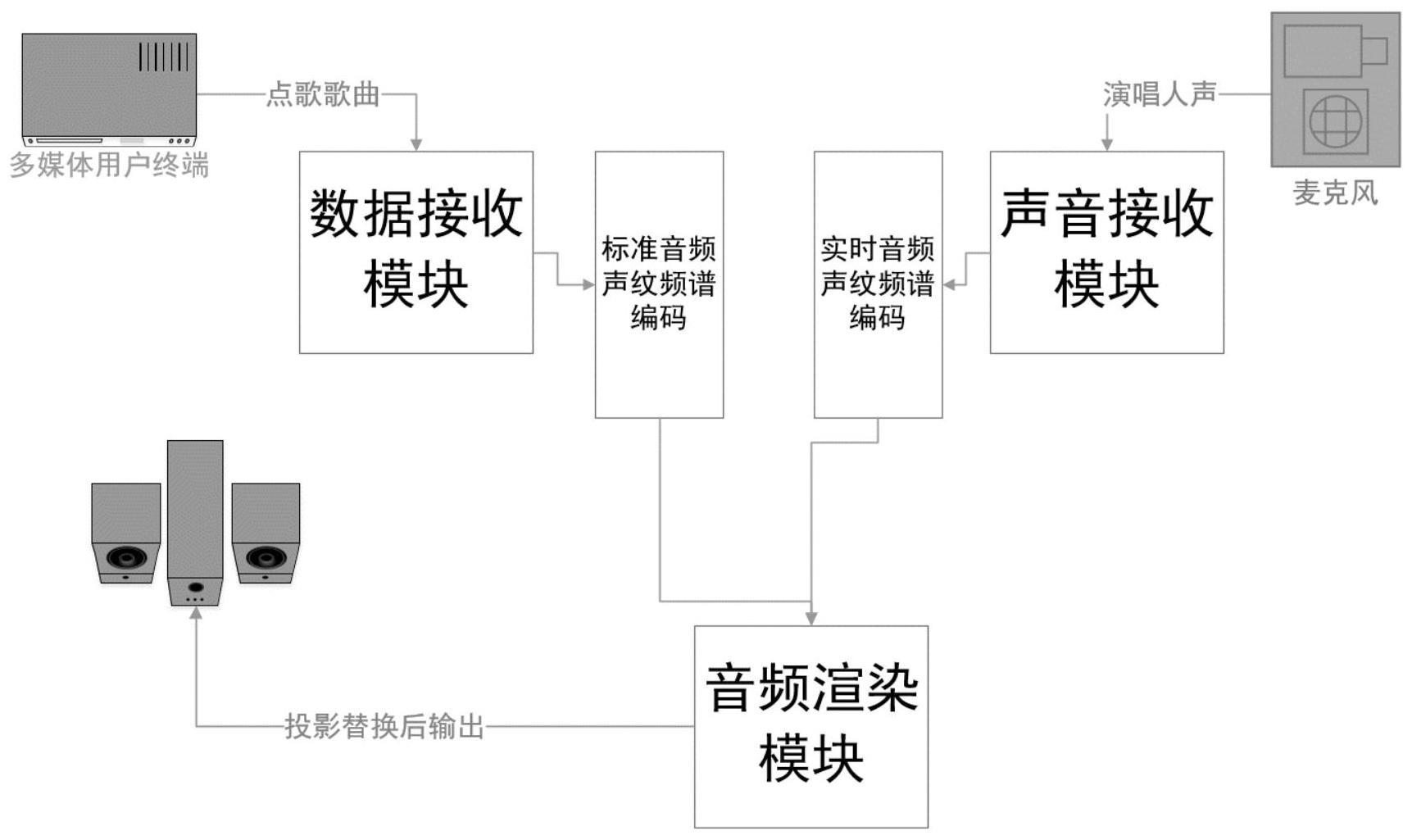
2、一种基于音频同步渲染的点歌控制系统,包括:
3、数据接收模块:用于接收用户的点歌歌曲,确定点歌歌曲的音频编码数据;其中,
4、音频编码数据为歌曲标准演唱下基于时间帧排布的标准音频声纹频谱编码;
5、声音接收模块:用于接收用户演唱点歌歌曲的用户实时声纹,生成用户的实时音频声纹频谱编码;
6、音频渲染模块:用于将实时声纹频谱编码按照时间帧投影至标准音频声纹频谱编码,并将相同音频声纹频谱编码部分进行投影替换,生成渲染后的目标音频声纹频谱编码,将目标音频声纹编码通过麦克风转换为用户人声进行播放。
7、优选的,所述声音接收模块还配有预处理单元:
8、预处理单元用于进行声音数字化处理,确定数字化声音信息,并基于预设的用户声纹特征,拾取数字化声音信息中的纯净人声;其中,
9、数字化声音信息包括人声信息和背景音信息。
10、优选的,所述音频渲染模块具体还包括:
11、对比子单元:用于提取音频编码数据的关键特征,并与用户实时声纹中的同类关键特征进行对比,判断基于关键特征的匹配度;其中,
12、关键特征为音色特征、音高特征和响度特征;
13、调整子单元:用于在当前时刻拾取的人声信息的关键特征的匹配度低于预设阈值时,对当前时刻拾取的人声信息的关键特征进行拟合化调整,得到渲染后的人声信息。
14、优选的,所述音频渲染模块还配置有可视化单元:
15、可视化单元用于绘制投影替换出折线对比图;其中,
16、折线对比图包括关键特征对比图和音频声纹频谱编码对比图。
17、优选的,所述折线对比图的绘制步骤包括:
18、根据音频编码数据和用户的实时音频声纹频谱编码,按照预设的图表类型构建相对应的多张第一折线图,并按照顺序展示,对各所述第一折线图进行动态配置;
19、构建第二折线图,并根据当前时刻人声信息中的关键特征数据实时更新所述第二折线图;
20、依次对动态配置后的第二折线图和各所述第一折线图在用户终端上进行滚动显示;其中,
21、第一折线图和第二折线图的在用户终端上的显示位置重合且显示颜色不同。
22、优选的,所述系统歌曲推荐模块,所述歌曲推荐模块被配置为:
23、获取用户选定的至少一个歌曲风格标签以及用户的歌曲播放记录;
24、根据歌曲风格标签和歌曲播放记录计算每个歌曲风格标签相对应的权重,并以第一向量的形式表示;
25、从歌曲库中查找与歌曲风格标签相同的歌曲,作为待推荐歌曲;
26、根据每个待推荐歌曲相对应的歌曲风格标签计算每个歌曲风格标签的权重,并以第二向量的形式表示;
27、计算第一向量与每个第二向量的相似度,并将相似度以从高到低的顺序对待推荐歌曲进行排序。
28、优选的,所述投影替换包括如下步骤:
29、预先设置基于填充的背景音矩阵;其中,
30、背景音矩阵为点歌歌曲的伴奏音频矩阵;
31、根据时间帧分别生成标准音频声纹频谱编码的第一输出链表和用户的实时音频声纹频谱编码的第二输出链表;
32、将第二输出链表投影值第一输出链表上,确定相同音频声纹频谱编码和第一输出链表上的差异音频声纹频谱编码;
33、并将相同音频声纹频谱编码和差异音频声纹频谱编码按照时间帧填充至背景音矩阵进行编码转换,生成投影替换后的目标音频声纹频谱编码;其中,
34、背景音矩阵上填充的相同音频声纹频谱编码在第二输出链表上提取;
35、背景音矩阵上填充的差异音频声纹频谱编码在第一输出链表上提取。
36、优选的,所述用户终端还用于显示用户所选曲目的演唱难度,并当演唱难度超出预设阈值时,以弹窗的形式告知用户并接收用户输入的是否需要修音的操作。
37、优选的,所述点歌歌曲还会进行演唱难度标记;其中,
38、演唱难度标记是通过训练好的分级模型确定,所述难度分级模型的构建步骤具体包括:
39、获取多个标记有难度标签的歌曲样本;
40、对歌曲样本进行频谱化处理,并将处理后的歌曲样本分为训练集和测试集;
41、提取训练集和测试集的特征值,特征值包括音域宽度、卡换声点、节奏快慢以及强弱长短音;
42、将训练集的特征值和与其相对应的难度标签输入至难度分级模型中进行训练,得到训练后的难度分级模型;
43、利用测试集的特征值确定难度分级模型的准确度,当准确度达到预设的准确值时,得到训练完成的难度分级模型。
44、优选的,所述数据接收模块还配置有音频编码单元;其中,
45、所述音频编码单元用于获取目标音频声纹频谱编码,并将目标音频声纹频谱编码作为当前用户的标准音频声纹频谱编码,并记录在当前用户的点歌信息中。
46、本发明有益效果在于:
47、通过本技术的方式对用户的声音进行渲染,在修音操作上,现有技术是对用户的声音进行调整,但是本技术是将用户的声音进行投影映射,所以对于可能存在修音的地方,直接进行了替换,而不是修改调整,修改调整存在偏差,但是替换是没有偏差,使得用户演唱的效果更好。
48、而且本技术的方式只有在系统在接收到用户的修音声音时,才会进行调音操作,不会主动调音,以充分满足不同用户的需求,实现音频同步的渲染操作。在实际的演唱过程中音频部分包括歌曲的人声和伴奏,本技术主要是对人声,即音频部分的关键特征为人声的音准和力度进行渲染,对于非专业的演唱者,因为难免会有跑调的情况。
49、当出现跑调时,即用户音准和/力度和当前歌曲所需的音准和/力度相差较大时,本系统的自动投影替换功能,相对于常规的渲方式,本技术的方式完全不会出现失真现象,渲染的效果更好也可以避免由于过度修音导致声音变形的情况。
50、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书以及附图中所特别指出的结构来实现和获得。
51、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!