语音识别方法、装置、设备及存储介质与流程
本技术涉及语音识别,更具体的说,是涉及一种语音识别方法、装置、设备及存储介质。
背景技术:
1、自基于注意力机制的端到端机器翻译框架提出以来,端到端建模思路已成为机器翻译、手写识别、语音识别等序列建模任务中的研究热点。在语音识别任务中,端到端建模方法具有声学和语言联合建模的优点,理论上的潜力很大。
2、大语言模型llm,是一种人工智能模型,旨在理解和生成人类语言。通过在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。llm的特点是规模庞大,包含数十亿甚至更多的参数,帮助模型学习语言数据中的复杂模式。大语言模型涌现的能力包括上下文学习、指令遵循和循序渐进的推理能力,随着chatgpt的发布,llm相关的研究和应用逐渐爆发,比如google的palm模型、meta的llama模型等。
3、目前将大语言模型与端到端的语音识别模型相结合的方案较少,仅有的结合方案一般是采用级联方案,具体是使用llm能力对语音识别模型输出的nbest结果(语音识别模型对输入语音会解码出多条候选语音识别结果,该多条候选语音识别结果称之为nbest结果)进行重打分,根据llm的打分结果对nbest结果进行重排序,得到最优的识别结果。
4、上述采用级联方案将语音识别模型和llm进行结合的方式,仅仅是浅层次的融合,llm并不能影响语音识别模型的识别结果,其仅仅是对语音识别模型输出的多条识别结果进行打分,无法充分利用llm的强大建模能力,对语音识别效果提升有限。
技术实现思路
1、鉴于上述问题,提出了本技术以便提供一种语音识别方法、装置、设备及存储介质,以实现将llm与语音识别模型的深层次结合,借助llm来提升语音识别效果。具体方案如下:
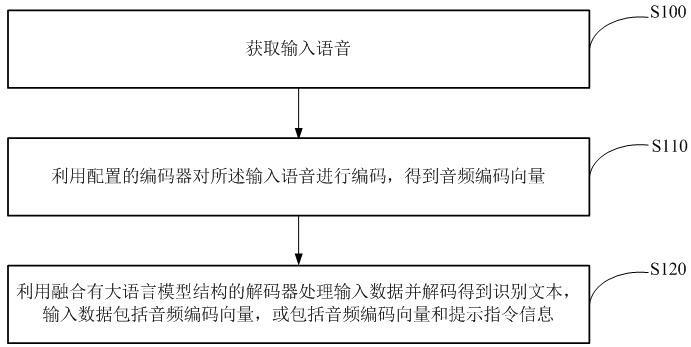
2、第一方面,提供了一种语音识别方法,包括:
3、获取输入语音;
4、利用配置的编码器对所述输入语音进行编码,得到音频编码向量;
5、利用配置的解码器处理输入数据并解码得到所述输入语音对应的识别文本,所述输入数据包括所述音频编码向量,或所述输入数据包括所述音频编码向量和提示指令信息,所述提示指令信息包括用于辅助对输入语音进行识别的辅助信息;其中,所述解码器融合有大语言模型结构,以利用所述大语言模型结构对所述输入数据进行处理。
6、优选地,所述解码器包括:大语言模型llm模块和原始解码模块,所述llm模块共有n层,所述原始解码模块共有m层;
7、所述输入数据具体包括所述音频编码向量和提示指令信息。
8、优选地,所述llm模块与所述原始解码模块按照自下而上依次连接;
9、所述llm模块用于对所述输入数据中的所述提示指令信息进行编码,并将提示指令的编码向量传递给所述原始解码模块;
10、所述原始解码模块用于接收所述提示指令的编码向量,以及接收所述编码器传递的所述音频编码向量,基于所述提示指令的编码向量和所述音频编码向量进行解码,得到所述识别文本。
11、优选地,p层所述llm模块及m层所述原始解码模块按照自下而上依次连接,每一层所述原始解码模块内部包含自下而上依次连接的原始解码层及1层所述llm模块,p层所述llm模块的输出还通过残差连接传递到每一层所述原始解码模块内的所述llm模块,n=p+m;
12、p层所述llm模块用于对所述输入数据中的所述提示指令信息进行编码,并将提示指令的编码向量传递给所述原始解码模块;
13、所述原始解码模块用于接收所述提示指令的编码向量,以及接收所述编码器传递的所述音频编码向量,基于所述提示指令的编码向量和所述音频编码向量进行解码,得到所述识别文本。
14、优选地,所述解码器采用大语言模型llm模块作为主体结构;所述输入数据具体包括所述音频编码向量;
15、则所述利用解码器处理输入数据并解码得到所述输入语音对应的识别文本的过程,包括:
16、将所述音频编码向量输入所述llm模块,由所述llm模块将所述音频编码向量作为隐式的提示指令信息,通过自回归解码方式得到所述输入语音对应的识别文本。
17、优选地,所述提示指令信息包括:
18、所述输入语音所属的领域信息、说话人信息、语种信息、主题信息中的任意一项或多项。
19、优选地,所述提示指令信息还包括上下文信息;
20、在所述语音识别方法应用于听写场景时,所述上下文信息包括机器历史回复文本和/或用户的历史输入语音的识别文本;
21、在所述语音识别方法应用于转写场景时,所述上下文信息包括用户的历史输入语音的识别文本。
22、优选地,所述编码器和所述解码器的训练过程,包括:有监督训练过程;
23、所述有监督训练过程包括:
24、获取训练语音及其标注文本,以及,获取提示指令信息;
25、将所述标注文本及所述提示指令信息组合为训练文本;
26、利用编码器对所述训练语音进行编码,得到音频编码向量;
27、利用解码器处理所述训练语音的音频编码向量及所述训练文本,并解码得到所述训练语音对应的识别文本;
28、基于所述解码器解码得到的识别文本及所述训练语音的标注文本计算损失函数,并按照所述损失函数更新所述编码器和所述解码器的参数。
29、优选地,在所述有监督训练过程之前,还包括:无监督训练解码器过程,该过程包括:
30、获取无监督文本及基于所述无监督文本生成的提示指令信息;
31、将所述无监督文本及所述提示指令信息组合为训练文本;
32、利用所述训练文本采用无监督训练方式,训练所述解码器。
33、优选地,所述编码器和作为所述解码器的llm模块的训练过程,包括:
34、获取训练语音及其标注文本;
35、利用预训练后的编码器对所述训练语音进行编码,得到音频编码向量并输入所述llm模块;
36、获取所述标注文本的嵌入向量,并输入所述llm模块;
37、利用所述llm模块联合所述训练语音的音频编码向量和所述标注文本的嵌入向量,通过自回归解码方式得到所述训练语音对应的识别文本;
38、基于所述llm模块解码得到的识别文本及所述训练语音的标注文本计算损失函数,并按照所述损失函数更新所述编码器和所述llm模块的参数。
39、优选地,所述编码器的预训练过程,包括:
40、采用所述训练语音及其标注文本训练一个初始语音识别模型,所述初始语音识别模型包括编码器和解码器,将训练后的初始语音识别模型中的编码器作为所述预训练后的编码器。
41、第二方面,提供了一种语音识别装置,包括:
42、语音获取单元,用于获取输入语音;
43、语音编码单元,用于利用配置的编码器对所述输入语音进行编码,得到音频编码向量;
44、解码单元,用于利用配置的解码器处理输入数据并解码得到所述输入语音对应的识别文本,所述输入数据包括所述音频编码向量,或所述输入数据包括所述音频编码向量和提示指令信息,所述提示指令信息包括用于辅助对输入语音进行识别的辅助信息;其中,所述解码器融合有大语言模型结构,以利用所述大语言模型结构对所述输入数据进行处理。
45、第三方面,提供了一种语音识别设备,包括:存储器和处理器;
46、所述存储器,用于存储程序;
47、所述处理器,用于执行所述程序,实现上述的语音识别方法的各个步骤。
48、第四方面,提供了一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现上述的语音识别方法的各个步骤。
49、借由上述技术方案,本技术提供了一种在语音识别模型的解码器中融合大语言模型的网络结构,从而实现将大语言模型与语音识别模型的深度结合,借助大语言模型的建模能力提升语音识别模型中解码器的解码能力,进而提升语音识别效果。在应用本技术提供的融合有大语言模型的语音识别模型对输入语音进行识别时,首先通过编码器对输入语音进行编码,得到音频编码向量,进一步利用融合有大语言模型的解码器处理输入数据并解码得到识别文本。这里,输入数据可以包括音频编码向量,则通过解码器可以解码得到识别文本。除此之外,输入数据还可以包括音频编码向量和提示指令信息,该提示指令信息包括用于辅助对输入语音进行识别的辅助信息,示例如可以是说话人信息、上下文信息等。也即,在解码器解码得到识别文本时,除了可以参考输入语音的音频编码向量之外,还可以进一步考虑其它提示指令信息,从而为解码器提供更加丰富的参考信息,辅助进一步提升语音识别效果。
- 还没有人留言评论。精彩留言会获得点赞!