一种基于智能感知的自适应语音调控方法及系统与流程
本发明涉及语音调控,尤其涉及一种基于智能感知的自适应语音调控方法及系统。
背景技术:
1、随着移动通信技术和语音处理技术的不断发展,人们越来越依赖语音通信来满足各种日常沟通需求。然而,现实生活中的通信环境多种多样,包括静音环境、嘈杂的街头、交通工具内等等。这些不同的环境条件会对语音通信的质量和清晰度产生显著影响。在传统的语音通信系统中,通常使用静态设置或预定义的参数来调整语音处理和增强算法,以适应不同的环境。这种方法存在一定的局限性,因为它无法灵活地适应环境的变化和用户的需求。
2、因此,如何根据实际使用环境和用户习惯来动态调整语音处理参数,以提供最佳的语音质量和清晰度,实现自适应调控,从而改善不同环境下的语音通信体验,并提供更好的语音通信体验是一个重要问题。
技术实现思路
1、本发明克服了现有技术的缺陷,提供了一种基于智能感知的自适应语音调控方法及系统,其重要目的在于改善语音通信体验并提高用户满意度。
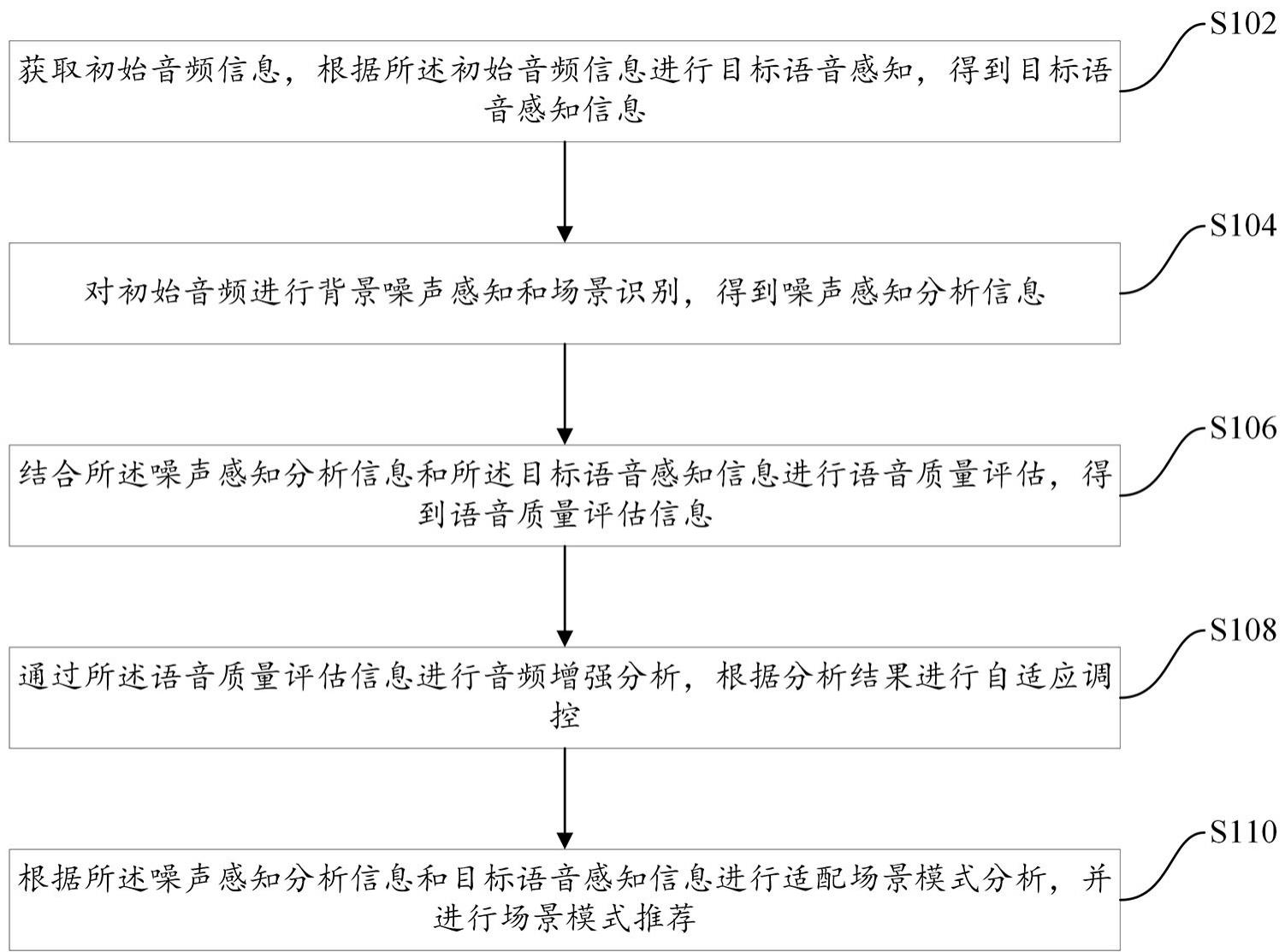
2、为实现上述目的本发明第一方面提供了一种基于智能感知的自适应语音调控方法,包括:
3、获取初始音频信息,根据所述初始音频信息进行目标语音感知,得到目标语音感知信息;
4、对初始音频进行背景噪声感知和场景识别,得到噪声感知分析信息;
5、结合所述噪声感知分析信息和所述目标语音感知信息进行语音质量评估,得到语音质量评估信息;
6、通过所述语音质量评估信息进行音频增强分析,根据分析结果进行自适应调控;
7、根据所述噪声感知分析信息和目标语音感知信息进行适配场景模式分析,并进行场景模式推荐。
8、本方案中,所述获取初始音频信息,根据所述初始音频信息进行目标语音感知,具体为:
9、获取初始音频信息,对所述初始音频信息进行预加重、分帧和加窗处理;
10、对初始音频信息进行短时傅里叶变换,得到变换音频信息,基于vad根据所述变换音频信息进行掩膜生成和帧分类;
11、计算每个音频帧的瞬时能量和短时能量,并计算短时能量的均值和方差,根据均值和方差设定分类阈值;
12、将各音频帧的瞬时能量与分类阈值进行判断,根据判断结果划分语音帧和噪声帧,并生成语音掩膜和噪声掩膜,得到第一音频信息;
13、对所述第一音频信息进行音素分割,对每个音素进行特征提取,提取各音素的mfcc特征并构建音素矩阵,得到音素特征信息;
14、基于cnn构建目标语音感知模型,将第一音频信息和音素特征信息输入至目标语音感知模型中进行目标语音识别和分离,得到目标语音感知信息。
15、本方案中,所述对初始音频进行背景噪声感知和场景识别,得到噪声感知分析信息,具体为:
16、基于大数据检索获取各种场景的噪声特征,通过聚类算法进行类别划分,随机提取各类别噪声场景k帧作为特征基向量,计算各向量的余弦距离,选取余弦距离最短的向量作为类别特征基准,构建噪声场景对比数据集;
17、获取第一音频信息,根据所述第一音频信息提取噪声帧的能量特征和mfcc特征,并对mfcc特征进行差分处理转换为动态特征,得到噪声特征信息;
18、将所述噪声特征信息与所述噪声场景对比数据集进行相似度计算,并于预设阈值进行判断,根据判断结果进行场景识别,得到场景识别信息;
19、对所述第一音频信息进行帧扩展处理,得到帧扩展音频信息,根据场景识别信息结合所述噪声场景对比数据集提取各场景下的背景噪声特征,得到多维噪声特征信息;
20、基于多头注意力机制结合多维噪声特征信息和帧扩展音频信息进行噪声特征预测,对所述帧扩展音频信息进行特征提取,获取当前场景下的音频特征;
21、计算当前场景下的音频特征与多维噪声特征信息的相似度,通过相似度进行选择和聚合噪声特征,得到噪声特征预测信息;
22、结合场景识别信息和噪声特征预测信息构成噪声感知分析信息。
23、本方案中,所述结合所述噪声感知分析信息和所述目标语音感知信息进行语音质量评估,具体包括:
24、获取噪声感知分析信息和目标语音感知信息,并进行特征提取,提取目标语音的频谱、时域和能量特征作为第一特征信息,提取背景噪声的频谱特征、噪声类型特征和能量强度特征作为第二特征信息;
25、基于大数据检索获取不同语音质量的音频特征信息,并通过聚类算法进行类别划分,得到音频质量类别信息;
26、根据所述音频质量类别信息设定评分标签,基于不同的语音质量设定不同的评估分数,并构建质量评分机制;
27、构建语音质量评估模型,基于音频质量类别信息和质量评分机制构建训练数据集,通过训练数据集对语音质量评估模型进行深度学习和训练;
28、将第一特征信息和第二特征信息输入至所述语音质量评估模型中进行语音质量评估,得到语音质量评估信息。
29、本方案中,所述通过所述语音质量评估信息进行音频增强分析,根据分析结果进行自适应调控,具体为:
30、获取语音质量评估信息、目标语音感知信息和噪声感知分析信息;
31、预设语音质量判断阈值,将所述语音质量评估信息与所述语音质量判断阈值进行判断,判断是否需要进行语音增强,得到语音增强判断信息;
32、构建语音增强模型,将所述目标语音感知信息和噪声感知分析信息输入至语音增强模型中进行增强,得到语音增强信息;
33、对增强后的语音信息进行语音质量评估,将语音增强信息输入至语音质量评估模型中进行评估,得到增强语音质量评估信息;
34、根据所述语音质量评估信息和增强语音质量评估信息进行增强效果分析,计算进行语音增强前后的差值,并与预设阈值进行判断,得到增强效果分析信息;
35、根据所述增强效果分析信息进行语音自适应调控。
36、本方案中,所述进行适配场景模式分析,并进行场景模式推荐,具体为:
37、获取噪声感知分析信息和目标语音感知信息,根据所述噪声感知分析信息得到场景识别信息,作为第一场景;
38、根据所述目标语音感知信息进行使用场景分析,对目标语音感知信息进行特征提取,得到目标语音特征信息;
39、构建使用场景分析模型,将所述目标语音特征信息输入至所述使用场景分析模型中进行分析,得到使用场景分析信息,作为第二场景;
40、获取历史使用信息,对所述历史使用信息进行特征提取,提取历史使用场景特征和历史使用模式特征,得到历史使用特征信息;
41、根据所述历史使用特征信息进行用户偏好分析,统计各场景下各种模式的使用频率并进行排序,并将排序结果与阈值进行判断,得到各场景用户偏好模式信息;
42、基于主成分分析法结合所述各场景用户偏好模式信息进行主成分分析,分析用户主要使用模式,得到主要使用模式信息;
43、根据各场景用户偏好模式信息获取各场景特征信息,与第一场景和第二场景进行场景匹配分析,分别计算第一场景和第二场景与各场景特征信息的欧式距离并取平均值,作为场景匹配度;
44、预设场景匹配判断阈值,将场景匹配度与所述场景匹配判断阈值进行判断,得到场景匹配分析信息;
45、根据所述场景匹配分析信息和各场景用户偏好模式信息得到候选场景模式信息,将所述主要使用模式信息作为权重,对候选场景模式信息进行加权计算;
46、根据加权计算结果选取最优场景模式,根据最优场景模式进行场景推荐和自适应模式调控。
47、本发明第二方面提供了一种基于智能感知的自适应语音调控系统,该系统包括:存储器、处理器,所述存储器中包含基于智能感知的自适应语音调控方法程序,所述基于智能感知的自适应语音调控方法程序被所述处理器执行时实现如下步骤:
48、获取初始音频信息,根据所述初始音频信息进行目标语音感知,得到目标语音感知信息;
49、对初始音频进行背景噪声感知和场景识别,得到噪声感知分析信息;
50、结合所述噪声感知分析信息和所述目标语音感知信息进行语音质量评估,得到语音质量评估信息;
51、通过所述语音质量评估信息进行音频增强分析,根据分析结果进行自适应调控;
52、根据所述噪声感知分析信息和目标语音感知信息进行适配场景模式分析,并进行场景模式推荐。
53、本发明公开了一种基于智能感知的自适应语音调控方法及系统,包括:获取初始音频信息,根据所述初始音频信息进行目标语音感知,得到目标语音感知信息;对初始音频进行背景噪声感知和场景识别,得到噪声感知分析信息;结合所述噪声感知分析信息和所述目标语音感知信息进行语音质量评估,得到语音质量评估信息;通过所述语音质量评估信息进行音频增强分析,根据分析结果进行自适应调控;根据所述噪声感知分析信息和目标语音感知信息进行适配场景模式分析,并进行场景模式推荐。提高语音通话的质量,并有效识别噪音和降低噪音,改善语音通信体验并提高用户满意度。
- 还没有人留言评论。精彩留言会获得点赞!