基于人工智能的语音识别纠错方法及系统与流程
本发明涉及语音识别,尤其涉及一种基于人工智能的语音识别纠错方法及系统。
背景技术:
1、随着人工智能技术的不断发展,语音识别系统在各领域的应用变得越来越普遍。然而,现有的语音识别系统在处理多人语音重叠分离以及方言和口音时存在一定的限制。多人语音情况下,识别系统容易混淆多个说话者的话语,导致误识别。另外,方言和口音也经常导致识别错误,降低了系统的可用性。
技术实现思路
1、基于此,有必要提供一种基于人工智能的语音识别纠错方法及系统,以解决至少一个上述技术问题。
2、为实现上述目的,一种基于人工智能的语音识别纠错方法及系统,所述方法包括以下步骤:
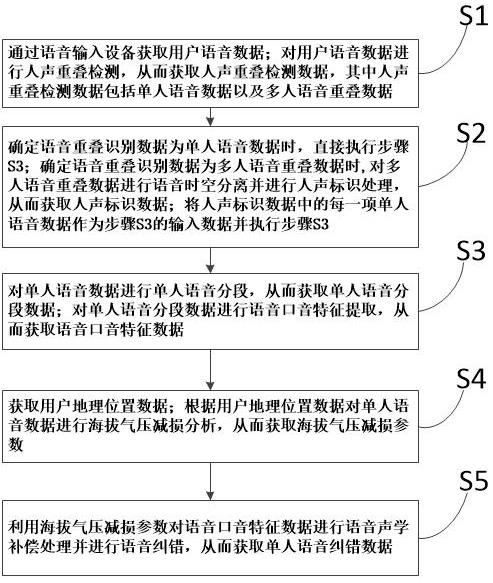
3、步骤s1:通过语音输入设备获取用户语音数据;对用户语音数据进行人声重叠检测,从而获取人声重叠检测数据,其中人声重叠检测数据包括单人语音数据以及多人语音重叠数据;
4、步骤s2:确定语音重叠识别数据为单人语音数据时,直接执行步骤s3;确定语音重叠识别数据为多人语音重叠数据时,对多人语音重叠数据进行语音时空分离并进行人声标识处理,从而获取人声标识数据;将人声标识数据中的每一项单人语音数据作为步骤s3的输入数据并执行步骤s3;
5、步骤s3:对单人语音数据进行单人语音分段,从而获取单人语音分段数据;对单人语音分段数据进行语音口音特征提取,从而获取语音口音特征数据;
6、步骤s4:获取用户地理位置数据;根据用户地理位置数据对单人语音数据进行海拔气压减损分析,从而获取海拔气压减损参数;
7、步骤s5:利用海拔气压减损参数对语音口音特征数据进行语音声学补偿处理并进行语音纠错,从而获取单人语音纠错数据。
8、本发明通过从多种语音源中采集数据,使得系统能够处理不同说话者的语音,同时,检测人声重叠数据有助于区分单人语音和多人语音重叠数据,为后续处理提供基础;通过根据语音重叠情况,系统能够有效地区分处理方式,以准备进行相应的后续处理,当识别数据为单人语音时,无需进行多人语音分离,从而减少计算负担,提高系统效率;将单人语音数据分成小段,有助于后续精细的口音特征提取和声学补偿处理,提取语音口音特征数据,以了解发音和口音的特点,为后续纠错提供重要信息;利用用户的地理位置信息,系统可以更好地适应不同地理区域的气压变化,从而提高声音质量,通过海拔气压减损分析,校准语音信号,降低海拔对声音信号的影响,从而改善语音质量;通过声学补偿处理,系统可以更准确地识别和纠正发音错误,从而提高语音识别的准确性,基于用户的地理位置信息,系统可以进行个性化的声学适应,提供更符合用户的语音纠错。因此,本发明提供了一种基于人工智能的语音识别纠错方法及系统,通过海拔气压减损分析以及多人语音重叠数据的语音时空分离处理,提高了不同海拔高度的多人语音情况下语音识别准确性以及应对方言和口音的适应性。
9、优选地,步骤s1包括以下步骤:
10、步骤s11:通过语音输入设备获取用户语音数据;
11、步骤s12:对用户语音数据进行语音环境降噪,从而获取用户语音环境降噪;
12、步骤s13:对用户语音环境降噪进行语音信号分帧,从而获取用户语音帧数据;
13、步骤s14:对用户语音帧数据进行连续帧分析,从而获取语音连续帧数据;
14、步骤s15:利用预设的人声重叠检测模型对语音连续帧数据进行人声重叠检测,从而获取人声重叠检测数据。
15、本发明通过语音输入设备,如麦克风或手机麦克风,获取用户的语音数据,这是语音识别和纠错的起始点,这一步骤确保了用户的语音信号可以被记录和用于后续处理;通过语音环境降噪计算公式对用户语音数据进行语音环境降噪计算,用于去除来自环境噪声的干扰,使语音信号更加清晰,有助于提高后续语音处理的准确性;将降噪后的语音信号分成短时间帧,通常为20毫秒到50毫秒的持续时间,有助于语音信号的分析和处理,分帧后的数据可用于进行各种语音特征提取和分析,如音频频谱分析;对分帧后的语音数据进行连续帧分析,通过计算相邻帧之间的音频特征,如频谱包络、能量、频率,来捕捉语音信号的动态特性;利用事先构建的人声重叠检测模型,对连续帧数据进行分析,以检测是否存在多人语音重叠,有助于区分单人语音和多人语音,为后续的语音分离和纠错提供了关键信息。
16、优选地,步骤s12中语音环境降噪计算公式进行计算,其中语音环境降噪计算公式具体为:
17、;
18、式中,表示用户语音环境降噪后的输出信号,用户语音数据的输入信号,表示用户语音数据的频率分量的序号,表示用户语音数据的第个频率分量的幅度,表示用户语音数据的第个频率分量的相位,表示用户语音数据的音频方向角,表示用户语音数据的音频倾斜角,表示用户语音数据的信噪比,表示用户语音数据的音频能量,表示用户语音数据的音频峰值,表示语音环境降噪误差修复量。
19、本发明构造了一种语音环境降噪计算公式,用于对用户语音数据进行语音环境降噪;公式中部分涉及对用户语音数据的频率分量幅度和相位的对数比,计算频率分量的幅度和相位比的对数可以有助于突出主要声音成分,因为人类语音通常由一系列频率分量组成,有助于提取语音信号中的有用信息;部分涉及用户语音数据的音频方向角和音频倾斜角,这部分有助于识别声音来源的方向和倾斜度,从而有助于降低噪声,尤其是来自不同方向的噪声;部分包括用户语音数据的信噪比和音频能量以及音频峰值,计算信噪比的平方根与音频能量和音频峰值之和的平方根的比例,这可以用来调整信噪比,使具有较高信噪比的部分得到保留,而具有较低信噪比的部分得到抑制,从而改善降噪效果;项用于对降噪后的信号进行额外的校正和修复,以确保声音质量和清晰度。
20、优选地,步骤s2包括以下步骤:
21、步骤s21:确定语音重叠识别数据为单人语音数据时,直接执行步骤s3;
22、步骤s22:确定语音重叠识别数据为多人语音重叠数据时,对多人语音重叠数据进行语音时空分离,从而获取独立语言流数据;
23、步骤s23:对独立语言流数据进行人声标识处理,从而获取人声标识数据;
24、步骤s24:将人声标识数据中的每一项单人语音数据作为步骤s3的输入数据并执行步骤s3。
25、本发明通过对多人语音重叠数据进行语音时空分离,有助于识别和处理多人语音,提供了更多的分析和纠错材料,通过时空分离,可以减少多人语音中的交叉干扰,提高独立语音流数据的准确性和纯净度;人声标识处理有助于识别和区分不同的说话者,从而确定每个独立语音流数据的来源。这对于后续的纠错和标记非常重要,通过识别说话者,系统可以为每个说话者应用个性化的纠错和改进策略,以更好地满足他们的需求;通过将每个单人语音数据与其关联的人声标识数据一一对应,可以根据每个说话者的特点进行个性化的纠错和改进,提高了语音识别的适应性和准确性;通过将分离出的单人语音数据分别处理,系统可以更有效地应对多人语音重叠情况,减少混叠和错误,从而提高了多人语音的处理能力。
26、优选地,步骤s22包括以下步骤:
27、步骤s221:确定语音重叠识别数据为多人语音重叠数据时,对多人语音重叠数据进行声源多波束构建,从而获取声源多波束数据;
28、步骤s222:对声源多波束数据进行空间谱估计,从而获取声源空间谱数据;
29、步骤s223:对多人语音重叠数据进行混合矩阵估计,从而获取声源混合矩阵数据;
30、步骤s224:对声源混合矩阵数据进行矩阵逆调整以及进行声源分离,从而获取声源分离结果数据;
31、步骤s225:基于声源空间谱数据以及声源分离结果数据进行时间-频域分析,从获取时间-频域分析数据;
32、步骤s226:对时间-频域分析数据进行时间序列定位处理,时间序列定位数据;
33、步骤s227:基于声源空间谱数据以及声源分离结果数据进行三维空间位置分析,从而获取三维空间位置数据;
34、步骤s228:对声源分离结果数据、时间序列定位数据以及三维空间位置数据进行语音流重建,从而获取独立语音流数据。
35、本发明通过构建声源多波束,可以增强特定方向上的声音源信号,同时抑制其他方向上的噪声和混叠语音,有助于提高多人语音重叠数据的清晰度和可分辨性;通过进行空间谱估计,系统可以更准确地了解声源在多麦克风阵列中的分布情况,以便更好地分离语音信号,有助于提高声音源的空间定位和声音源信号的质量;估计混合矩阵有助于了解多个说话者的语音信号是如何混合在一起的,这个信息对后续的声源分离过程至关重要,因为它提供了分离算法所需的关键信息;通过调整混合矩阵并进行矩阵逆操作,系统能够有效地分离混叠的语音信号,从而提供单独的语音流,有助于提高多人语音重叠数据的可理解性和可操作性;时间-频域分析有助于了解语音信号在不同时间和频率上的变化,包括说话者切换、语音段落和音频特性,有助于提高语音纠错的准确性和针对性;时间序列定位处理允许系统更好地理解多人语音中不同说话者的时间序列,有助于更准确地区分说话者和理解他们的发言时刻,这对于语音分离和纠错非常重要;通过三维空间位置分析,系统能够确定每个声源的具体三维位置,有助于实现更高级的声音源定位和空间分离,这对于多人语音分离和纠错的准确性非常关键;语音流重建允许系统将分离出的语音信号重新组合为单独的语音流,这使得后续的语音识别和纠错工作更容易实施,提高了语音处理的质量和可用性。
36、优选地,步骤s3包括以下步骤:
37、步骤s31:确定语音重叠识别数据为单人语音数据时,对单人语音数据进行能量门限检测,从而获取语音段数据;
38、步骤s32:利用语音活动检测算法对语音段数据进行语音活动检测,从而获取语音活动数据;
39、步骤s33:对语音活动数据进行定位切割点,从而获取定位切割点数据;
40、步骤s34:跟定位切割点数据进行语音定点切割,从而获取单人语音分段数据;
41、步骤s35:对单人语音分段数据进行声音频谱分析,从而获取声音频谱数据;
42、步骤s36:对单人语音分段数据进行共振峰参数提取,从而获取共振峰参数;
43、步骤s37:利用共振峰参数对声音频谱数据进行峰值匹配,从而获取声音频谱峰值数据;
44、步骤s38:对单人语音分段数据进行单人声纹特征提取,从而获取单人声纹特征数据;
45、步骤s39:对单人语音分段数据进行单人音素分析,从而获取单人音素特征数据;
46、步骤s310:根据声音频谱峰值数据对单人声纹特征数据以及单人音素特征数据进行语音口音特征融合,从而获取语音口音特征数据。
47、本发明通过检测语音数据的能量门限,确定语音段数据的开始和结束,从而准确提取语音段,有助于排除背景噪音或沉默段,使后续的分析更加准确和高效;语音活动检测算法用于确定语音段中的活动和非活动部分,即声音是否存在,有助于确定语音段的实际语音活动部分,从而避免处理无声或非语音区域,提高了分析的精确性;定位切割点数据的获取有助于确定语音段的分界点,即语音活动的开始和结束,使得进一步的语音分割变得更加精确,为后续的分析和特征提取提供了准确的语音段;语音定点切割是根据定位切割点数据对语音段进行准确的切分,以获取单人语音分段数据,有助于将不同的语音活动分离开,为后续的声学分析和声纹特征提取提供了清晰的语音数据;声音频谱分析用于提取语音段的频谱特征,包括声音频谱的幅度和频率信息,有助于了解语音的声音质量和语音内容,为后续的特征提取和分析提供了基础数据;共振峰参数提取是声学分析的一部分,用于提取语音段中的共振峰信息,这些峰值与声音的声学特性相关,有助于区分不同语音的声音特征,为声音识别提供了重要信息;峰值匹配过程用于根据共振峰参数对声音频谱数据进行匹配,以确定语音的声学特征,有助于识别和区分不同的语音,提高语音识别的准确性;单人声纹特征提取用于捕捉语音中的声纹特征,这些特征是与说话者个体相关的,有助于对不同说话者进行区分,可以用于声纹识别和说话者识别;单人音素分析有助于将语音分段拆分成音素级别的语音单位,这对于语音识别和语音理解非常重要,提供了语音的更细粒度特征,有助于精确的语音处理;语音口音特征融合是将声音频谱峰值数据与单人声纹特征和单人音素特征相结合,以获得更全面和准确的语音口音特征数据,有助于改善方言、口音和发音错误的识别和纠正,提高了语音识别系统的性能。
48、优选地,步骤s4包括以下步骤:
49、步骤s41:获取用户地理位置数据;利用gis对用户地理位置数据进行三维空间局部构建,从而获取地理空间局部数据;
50、步骤s42:对地理空间局部数据进行用户地理海拔标注,从而获取用户地理海拔数据;
51、步骤s43:根据用户地理海拔数据进行气压数据获取,从而获取海拔气压数据;
52、步骤s44:基于海拔气压数据进行气压-海拔关系模型构建,从而获取气压-海拔关系模型;
53、步骤s45:利用气压-海拔关系模型对海拔气压数据进行模型拟合,从而获取气压-海拔关系模型拟合参数;
54、步骤s46:基于气压-海拔关系模型拟合参数进行海拔气压减损参数提取,从而获取海拔气压减损参数。
55、本发明通过获取用户的地理位置数据有助于将环境变量引入到语音处理中,这意味着语音识别系统可以更好地适应不同地理区域的环境条件,提高了系统的环境适应性;标注用户的地理海拔信息可以帮助系统更准确地了解语音信号产生时的海拔高度,对于声学环境的建模非常重要,因为海拔高度会影响声音的传播速度和声音的频谱特性;获取气压数据是为了获取与地理位置相关的气象数据,气压与海拔高度之间存在紧密的关系,因此能够提供声音传播中的重要环境信息;建立气压-海拔关系模型允许系统根据气压数据来推断海拔高度,这一模型是基于气象学原理构建的,可以提供精确的海拔高度估计;模型拟合可以进一步改进海拔高度的估计精度,模型能够更好地捕捉气压和海拔之间的关系,从而提供更准确的数据;提取海拔气压减损参数是为了对多人语音数据进行声学补偿,准确的减损参数允许语音处理系统更好地理解声音在不同海拔高度和气压条件下的传播特性,从而提高语音识别的准确性。
56、优选地,步骤s46包括以下步骤:
57、步骤s461:基于气压-海拔关系模型拟合参数进行气压减损参数计算,从而获取气压减损参数数据;
58、步骤s462:根据气压减损参数数据进行声音传播速度变化分析,从而获取声音传播速度变化数据;
59、步骤s463:根据气压减损参数数据进行声音波长变化分析,从而获取声音波长变化数据;
60、步骤s464:基于声音传播速度变化数据以及声音波长变化数据进行语音信号影响效应分析,从而获取语音信号影响效应数据;
61、步骤s465:对语音信号影响效应数据进行语音信号调整,从而获取海拔气压减损参数。
62、本发明通过气压-海拔关系模型,可计算出与海拔高度相关的气压减损参数,有助于纠正多人语音中受海拔高度影响的语音信号,提高语音识别的准确性;通过声音传播速度变化数据,可以了解语音信号在不同海拔高度下的传播速度差异,有助于校正语音信号的时间特性,确保语音识别过程中的时序关系准确;声音波长变化数据揭示了语音信号在不同海拔高度下的波长变化情况,有助于更好地理解语音信号的频谱特性,从而提高语音识别的频谱建模准确性;语音信号影响效应数据反映了海拔高度对语音信号的影响,包括时间特性和频谱特性,这些数据有助于更精确地理解语音信号的变化,从而更好地进行校正和纠正;通过语音信号调整,可以根据获取的语音信号影响效应数据,对语音信号进行纠正和调整,以适应不同海拔高度下的语音信号特性,有助于提高语音识别系统的鲁棒性和准确性,无论用户所在的海拔高度如何。
63、优选地,步骤s461中气压减损参数计算公式进行计算,其中气压减损参数计算公式具体为:
64、;
65、式中,表示气压减损参数,表示一个离散的海拔高度分段的总数,表示海拔高度分段的索引值,表示在海拔高度分段上的气压变化,表示海平面上的标准大气压力,表示与海拔高度分段相关的角度参数,表示与海拔高度分段相关的斜率参数,表示气压减损参数计算偏差纠正值。
66、本发明构造了一种气压减损参数计算公式,用于基于气压-海拔关系模型拟合参数进行气压减损参数计算;公式中表示了在不同海拔高度分段上的气压减损程度,它是计算气压减损的核心参数,对于纠正语音数据中的气压效应非常重要;表示将海拔高度分段为多少个小区间,用于离散化海拔高度,使气压减损参数的计算更精确,增加n的数量可以提高计算的精度;表示在特定海拔高度分段k上的气压变化量,反映了海拔高度对气压的影响,可以帮助确定气压减损的程度;作为一个常数,表示海平面上的标准大气压力,提供了一个基准值,用于计算气压变化相对于海平面的影响;这个角度参数可能用于考虑不同海拔高度分段之间的斜率或倾斜度,以更准确地表示气压减损效应;这个参数可能用于调整计算的斜率,以更好地匹配海拔高度分段的数据;这是一个纠正值,用于调整整体计算结果,以消除可能的系统偏差。
67、10.优选地,本发明还提供了一种基于人工智能的语音识别纠错系统,包括:
68、用户语音检测模块,用于通过语音输入设备获取用户语音数据;对用户语音数据进行人声重叠检测,从而获取人声重叠检测数据,其中人声重叠检测数据包括单人语音数据以及多人语音重叠数据;
69、语音重叠识别数据判断模块,用于确定语音重叠识别数据为单人语音数据时,直接执行步骤s3;确定语音重叠识别数据为多人语音重叠数据时,对多人语音重叠数据进行语音时空分离并进行人声标识处理,从而获取人声标识数据;将人声标识数据中的每一项单人语音数据作为步骤s3的输入数据并执行步骤s3;
70、单人语言特征提取模块,用于对单人语音数据进行单人语音分段,从而获取单人语音分段数据;对单人语音分段数据进行语音口音特征提取,从而获取语音口音特征数据;
71、海拔气压减损分析模块,用于获取用户地理位置数据;根据用户地理位置数据对单人语音数据进行海拔气压减损分析,从而获取海拔气压减损参数;
72、语音声学纠错模块,用于利用海拔气压减损参数对语音口音特征数据进行语音声学补偿处理并进行语音纠错,从而获取单人语音纠错数据。
73、本发明通过从多种语音源中采集数据,使得系统能够处理不同说话者的语音,同时,检测人声重叠数据有助于区分单人语音和多人语音重叠数据,为后续处理提供基础;通过根据语音重叠情况,系统能够有效地区分处理方式,以准备进行相应的后续处理,当识别数据为单人语音时,无需进行多人语音分离,从而减少计算负担,提高系统效率;将单人语音数据分成小段,有助于后续精细的口音特征提取和声学补偿处理,提取语音口音特征数据,以了解发音和口音的特点,为后续纠错提供重要信息;利用用户的地理位置信息,系统可以更好地适应不同地理区域的气压变化,从而提高声音质量,通过海拔气压减损分析,校准语音信号,降低海拔对声音信号的影响,从而改善语音质量;通过声学补偿处理,系统可以更准确地识别和纠正发音错误,从而提高语音识别的准确性,基于用户的地理位置信息,系统可以进行个性化的声学适应,提供更符合用户的语音纠错。因此,本发明提供了一种基于人工智能的语音识别纠错方法及系统,通过海拔气压减损分析以及多人语音重叠数据的语音时空分离处理,提高了不同海拔高度的多人语音情况下语音识别准确性以及应对方言和口音的适应性。
- 还没有人留言评论。精彩留言会获得点赞!