一种基于生成式深度神经网络的多区域声场重建控制方法
本发明涉及多区域声场重建和汽车分区域声场控制领域,尤其涉及一种基于生成式深度神经网络的多区域声场重建控制方法。
背景技术:
1、在共享的空间内,不同的听者常需要不同的节目源,而不同节目源的相互串扰会显著影响听音体验,比如,在车内主驾驶位置通常需要听导航的声音,而其他座位的听众可能需要听歌曲、相声、有声书等娱乐性声音。个人声场多区域控制(personal sound zonecontrol,pszc)是解决这一问题的有效途径,其主要手段是设计一个用于扬声器阵列的数字滤波器,来优化扬声器阵列的激励信号,使阵列将不同节目源投影到声场不同区域。特定节目源对应的重放区域是亮区(听音区) ,而其余区域对应于此节目源都是暗区(静音区)。阵列优化的目标是使特定节目源在亮区的声重放性能符合预期,同时尽量减少对暗区的声辐射功率。
2、现有的pszc技术主要分为声学对比控制(acoustic contrast control,acc)、压力匹配(pressure matching,pm)、加权压力匹配(weight pressure matching,wpm)。其中,acc法试图在亮区最大化声能,在暗区衰减声能,通过最大化两个区域的声学对比度来设计扬声器阵列的滤波器。基于这一原理,提出了不同形式的acc,包括平均声能比、最大声能差等。这种对比控制方法与各个目标区域声场重建的误差无关,对声场相位没有约束,因此无法控制亮区重建的声场的空间方向。pm法主要是基于重建声场与期望声场的误差最小化,并采用最小二乘法减小声压误差,以获得扬声器阵列的滤波器。然而,它忽略了区域间的声学对比,在阵列工作中声能对比度表现不佳。pm法和acc法都只关注某一指标,是一种比较极端的方法,因此在一个指标上表现得特别好,而在其他指标上表现得很差。wpm是acc法和pm法的结合,通过调整权因子得到扬声器的驱动函数,在声场重建误差和声能对比度之间进行权衡,加权因子在0和1之间。
3、新的技术方案主要是基于上述三种技术原理进行研究和改进,例如,在时域、子带域、模态域进行阵列的滤波器设计,或者引入一些正则化方法,如l-曲线,tikhonov正则化等,以增强控制的鲁棒性。
4、马琮淦等人在中国发明专利申请“一种用于车内声场分区域的主动控制方法”(申请号为cn202210691382.1)中根据听音需求,确定明区和暗区;布置待选扬声器阵列;设置明区控制点、暗区控制点;采用单频信号响应法,获得待选扬声器阵列到明区和暗区控制点的传递函数矩阵;利用遗传算法选择扬声器阵列的最优扬声器数量和位置;利用双重迭代法确定最优控制模型参数值(即亮区,暗区权重)并用于生成实际扬声器阵列的频域驱动信号;通过快速傅里叶逆变换将频域驱动信号转换为时域驱动信号;输入到实际扬声器阵列中,驱动扬声器产生期望的声场。该方法本质上是声压匹配法(pm),使用一种迭代求解的方法,即双重迭代法解决这个优化问题。双重迭代法可能受到初始猜测值的选择和收敛性的影响,需要进行适当的调整和验证。同时,传递函数矩阵是预先测量好的,但是车内的声学混响通常较大,因为车内空间较小且由硬表面构成,这些硬表面会反射声音,导致声音在车内产生多次反射和干涉,从而增加混响效应,并且车内的驾驶员和乘客的活动、移动,也会导致声学传递函数的变化。
5、赵翔宇等人在中国发明专利申请“车内声学系统的音频控制方法、装置、存储介质及设备” (申请号为cn202211470705.0)中根据音频控制指令确定车内声场空间的明区与暗区;根据明区与暗区,确定明区对应的第一控制信号与暗区对应的第二控制信号;控制明区对应的扬声器根据第一控制信号进行音频播放,以及控制暗区对应的扬声器根据第二控制信号进行音频抑制,以在明区与暗区分别播放不同的音频内容,和/或在明区与暗区分别播放不同的音频音量,达到个性化的空间声场的效果。该方法是加权声压匹配法(wpm),用优化算法求解,存在局部最优解的情况。
6、李辉等人在中国发明专利申请“一种车内声场分区调控方法、系统及车辆”(申请号为cn202310428487.2)中根据需要播放声音a(t)得到车内扬声器系统的时域驱动信号;将需要播放声音a(t)作为主动控制的参考信号,将实时采集的车内各声场区域的车内声信号作为主动控制的误差信号;根据误差信号和参考信号生成扬声器系统的时域补偿信号;最后将扬声器系统的时域驱动信号与时域补偿信号进行信号叠加,加载给各个扬声器发声,在需要播放声音的明区生成期望的声音,在不需要播放声音的暗区生成零信号。该方法是一种声能对比度(acc)算法,存在矩阵求逆的问题。虽然结合主动控制的方法,但是,没有明确说明主动控制的详细控制策略。而且,在车内四个乘客区域布置声传感器并不能真的测量四个乘客区域的声音信号,只能测量到区域的部分点,并不能完全表征区域信号,这样的主动控制,可能导致测量点的效果很好,但是听音区域的其他点的效果下降。
7、上述方法都是在信号处理的领域进行改进,没有利用深度学习的方法,存在以下技术问题:
8、问题1:声对比度和重建误差是相互制衡的一对指标,声对比度提高,重建误差肯定也会变大,反之,亦然。尽管研究者们进行了各种优化求解,但是还是受到求解过程的限制,无法做到完全的分区控制。
9、问题2:这些方法均存在传递函数矩阵的测量问题。传递函数矩阵的测量会影响分区的性能。传递函数矩阵依赖测量点的位置、个数以及扬声器单元的位置和个数。如果车内环境发生变化,例如,乘坐人员位置移动、乘坐人员的衣物和身高等,都会影响传递函数的测量。而传递函数的测量是一个耗时耗力的人工过程,即使测量了大量的传递函数也无法覆盖所有的可能状况。
10、问题3: 这些方法均存在传递函数矩阵的求逆问题。矩阵求逆过程中,可能存在矩阵奇异、矩阵没办法求逆、矩阵求逆数值不稳定的情况。
11、因此,本领域的技术人员致力于开发一种新的多区域声场重建控制方法,借助深度学习来解决现有技术中存在的上述问题。
技术实现思路
1、有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是如何利用深度学习的方法来优化传递函数矩阵的测量、避免矩阵求逆并克服声对比度和重建误差之间的矛盾。
2、为实现上述目的,本发明提供了一种基于生成式深度神经网络的多区域声场重建控制方法,所述方法包括以下步骤:
3、步骤1、设置若干个多区域声场重建控制的目标区域,所述每个目标区域使用麦克风阵列,所述麦克风阵列最少包含一个麦克风;测量所述每个目标区域的传递函数矩阵,并通过插值和仿真操作来增加所述传递函数矩阵的数量,得到最终的所述传递函数矩阵;
4、步骤2、为所述每个目标区域设置通过扬声器阵列模拟出来的虚拟声源,并根据所述每个目标区域和所述虚拟声源的位置关系,得到所述每个目标区域的期望声场;
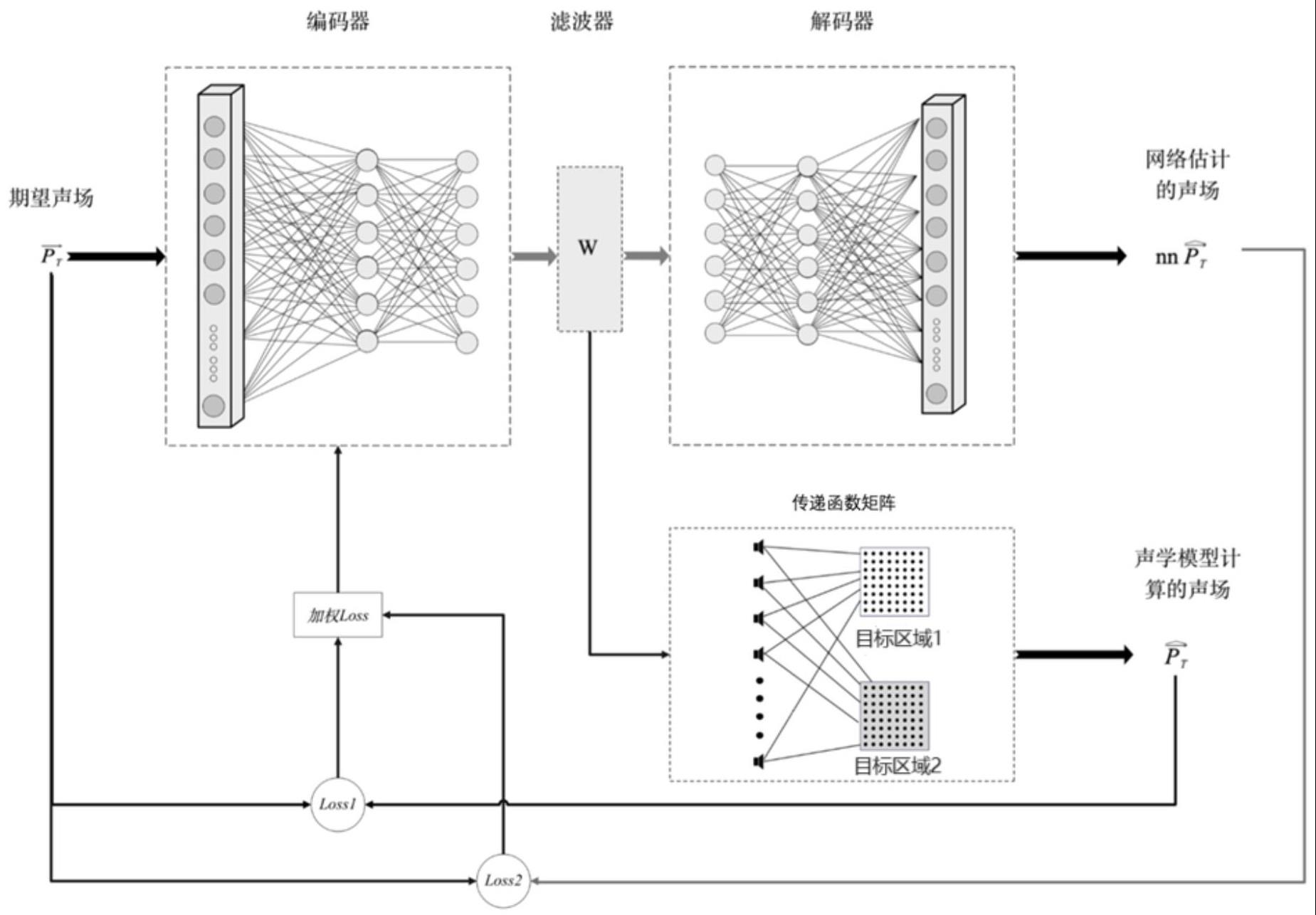
5、步骤3、设计包括编码器、解码器和隐向量层的生成式深度神经网络,其中,所述隐向量层位于所述编码器和所述解码器之间,通过控制所述隐向量层得到所述扬声器阵列的滤波器或者驱动信号,所述隐向量层也被称为滤波器层;所述编码器和所述解码器包括若干不同类型的神经网络层,所述神经网络层可以为全连接层、卷积层和池化层;
6、步骤4、将所述目标区域的所述期望声场作为输入,对所述生成式深度神经网络进行训练,得到网络估计的声场,即重建的声场数据,通过比较所述重建的声场数据和所述期望声场的数据之间的差异来计算损失函数,并根据所述损失函数的计算结果,使用反向传播算法更新所述生成式深度神经网络的参数,再经过若干轮的迭代训练,最后所述生成式深度神经网络收敛,完成训练;
7、步骤5、使用所述生成式深度神经网络生成所述扬声器阵列的所述滤波器或所述驱动信号。
8、进一步地,所述步骤1包括以下子步骤:
9、步骤1.1、设置若干个多区域声场重建控制的所述目标区域,所述目标区域的数量大于等于1;
10、步骤1.2、通过在所述每个目标区域中设置麦克风阵列来对所述每个目标区域进行空间采样,所述麦克风阵列至少包含一个麦克风,接收所述扬声器阵列中每一个阵元依次发出的扫频信号,得到所述每个目标区域的所述传递函数矩阵;
11、步骤1.3、通过插值和仿真操作来增加所述传递函数矩阵的数量,得到最终的所述传递函数矩阵。
12、进一步地,所述步骤1.2中测量所述传递函数矩阵包括以下子步骤:
13、步骤1.2.1、所述扬声器阵列发送一段频率连续变化的所述扫频信号,记为发送信号,所述发送信号的频率范围可根据实际需要进行选择;
14、步骤1.2.2、所述麦克风阵列接收所述发送信号,接收到的所述发送信号包含所述发送信号在传递过程中受到的影响,记为接收信号;
15、步骤1.2.3、对所述接收信号进行频域分析,得到在不同频率下的幅度和相位信息;
16、步骤1.2.4、将所述发送信号和所述接收信号的频域表示进行比较,得到所述每个目标区域的所述传递函数矩阵。
17、进一步地,所述步骤2包括以下子步骤:
18、步骤2.1、为所述每个目标区域设置通过所述扬声器阵列模拟出来的所述虚拟声源;
19、步骤2.2、所述每个目标区域包含若干个不同的所述虚拟声源的位置;
20、步骤2.3、根据所述每个目标区域和所述虚拟声源的位置关系,同时约束所述目标区域之间的声对比度acc,计算得到所述每个目标区域的所述期望声场,并记为,所述期望声场组成训练数据集;
21、步骤2.4、对所述训练数据集进行预处理,使得所有的所述目标区域的所述期望声场能够同时出现;
22、步骤2.5、为所述每个目标区域训练不同的深度神经网络模型。
23、进一步地,在所述步骤2.5中,也可以为所述训练数据集训练一个比较大的模型。
24、进一步地,所述步骤2.4需要考虑出现的不同情况:
25、a)只有一个所述目标区域,则所述训练数据集中的其他所述目标区域的所述期望声场被设置成零或者一个在听觉阈值以下的数值;
26、b)有两个所述目标区域,则所述训练数据集中的其他所述目标区域的所述期望声场被设置成零或者一个在听觉阈值以下的数值;
27、c)依次类推,直到所有的所述目标区域的所述期望声场能够同时出现。
28、进一步地,在所述步骤3中:
29、所述编码器以所述目标区域的所述期望声场作为输入,学习所述期望声场的空间特征和隐向量,其中,学习得到的所述隐向量位于所述隐向量层中;
30、所述解码器包括神经网络解码器和声学前向传播模型,其中,所述神经网络解码器将所述编码器的输出解码成所述网络估计的声场,所述声学前向传播模型根据所述传递函数矩阵计算得到声学模型计算的声场;
31、计算所述期望声场与所述声学模型计算的声场的误差,计算所述期望声场与所述网络估计的声场的误差,将和进行加权,得到加权;
32、将通过所述生成式深度神经网络的训练得到所述隐向量将作为所述扬声器阵列的所述滤波器或者所述驱动信号。
33、进一步地,所述步骤4包括以下子步骤:
34、步骤4.1、将所述目标区域的所述期望声场输入到所述编码器中,通过所述编码器得到所述隐向量,再将所述隐向量输入到所述解码器中,通过所述解码器得到所述重建的声场数据;
35、步骤4.2、比较所述重建的声场数据和原始输入的所述期望声场之间的差异,计算所述损失函数;
36、步骤4.3、根据所述损失函数的结果,计算梯度,并使用所述反向传播算法更新所述生成式深度神经网络的参数;
37、步骤4.4、重复所述步骤4.1~步骤4.3,直到达到预设的训练轮数或达到停止条件;
38、步骤4.5、对训练得到的所述生成式深度神经网络的性能进行评估,如果不满足要求,可以调整网络结构、调整超参数或增加训练数据来改进模型。
39、进一步地,所述步骤4.2中计算所述损失函数的方法包括均方误差、平均绝对误差或huber损失函数。
40、进一步地,所述步骤4.3中的所述反向传播算法包括梯度下降法、adam。
41、本发明提供的一种基于生成式深度神经网络的多区域声场重建控制方法至少具有以下技术效果:
42、1、本发明提供的技术方案借助深度学习强大的学习能力,通过测量的车内传递函数和仿真的传递函数以及虚拟声源,获得大量的多目标区域的期望声场的数据,通过声场数据进行训练,采用生成式深度神经网络,自动学习和提取声场特征,对复杂的声场进行更好的建模和表示,从而获得扬声器阵列的滤波器或者驱动信号;
43、2、本发明提供的深度学习模型具有很强的泛化能力,能够考虑到传递函数的变化特性,避免传递函数变化或者测量误差导致的性能下降,从而提高多区域声场的性能;
44、3、本发明提供的技术方案在训练过程中考虑不同的虚拟声源位置,能够在实现多区域声场控制的同时满足虚拟声的需求,在同一个声学环境下,使得听众感受到不同的听音位置;
45、4、本发明提供的技术方案避免传递函数矩阵的显式求逆,从而避免矩阵求逆的各种问题,提高多区域声场的性能;
46、5、本发明提供的技术方案结合声学传播模型和生成式深度学习模型,使得本发明的生成式神经网络模型从期望的声场直接生成扬声器阵列的滤波器或者驱动信号,从而增加模型的可用性和可解释性。
47、以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
- 还没有人留言评论。精彩留言会获得点赞!