一种多语种语音识别系统及方法与流程
本发明属于智能语音交互,特别涉及一种多语种语音识别系统及方法。
背景技术:
1、随着社会和电子信息技术的发展,人工智能产品成为了人民生活当中不可或缺的必需品,如智能音箱、智能汽车、智能电视、智能空调等。其它很多设备以及应用也都快速的朝着智能化的方向发展。同时,用户对人工智能产品的功能需求也是丰富多样,要求满足基础功能之外,还兼具影音娱乐、生活服务、互连等需求。
2、随着智能应用的丰富和ai技术的发展,消费者对智能产品的认识也不断的升级,对产品体验也从单一功能向更多的智能场景进行转变,由此,对产品的诸多功能需要重新定义,与此同时,人工智能、5g、人机交互设备与操作系统等技术的大幅度进步推动着智能应用的快速发展,以满足用户不断上升的认识和需求。
3、在现代的人机对话系统中,语音识别是一个基础的能力。随着越来越多的提供语音交互的设备,用户的发话的语种也存在多样性。用户可能使用多个语种与智能设备进行交互,这就要求智能设备具备自动的识别使用多个语种的发话的能力。多语种的自动识别给用户提供一个更加自然、简单的交互方式。
4、如果按传统技术构建多个用于各自独立语种及混合语种的模型,然后对多语种发话分别进行识别,会增加模型的数量,并且难于优化和维护。
5、现有技术中已有的支持多语种发话的两个主流的做法为:
6、(1)对建模单元进行统一:将不同语种的建模单元映射成同一套建模单元,构建一个语种无关的语音识别系统。具体可参考“huwenxuan,et.al.,multi-lingual speechrecognition researchbasedon end-to-endmodel[j].journalof signalprocessing,2021,37(10):1816-1824.doi:10.16798/j.issn.1003-0530.2021.10.004”。
7、(2)构建多语种网络模型:不同的语种可以共享部分参数,通过对参数进行共享,可以发掘多语种的共同表征。具体可参考“alec radford,et.al.,robustspeechrecognitionvia large-scale weak supervision arxiv:2212.04356v1,2022.”。
8、上述第(1)种方法不能有效的对特定语种进行独立优化,一般效果较第2种方法较差一些,但对于很多没有大量训练数据的小语种来说,第(1)种方法也能取到很好的效果。第(2)种方法一般是先独立训练各自的语种网络模型作为预训练的语种子网络,然后添加多语种共享的连接各语种的子网络结构,在这个基础上使用各语种的混合数据进行训练。
9、现有技术中的多语种识别系统面临如下问题:
10、(1)需要提供多个模型,用于识别不同的混合语种的组合。如中英模型、中文模型、粤语模型、普粤模型等,这会占用大量的存储空间。
11、(2)在性能优化阶段,需要对各模型中的指定成份进行优化。如优化中文性能时,需要对中英模型、中文模型、普粤模型进行优化。
技术实现思路
1、本发明提出一种系统及方法,首先构建多语种的独立声学模型和语言模型,然后将各声学模型的建模单元线性投影至一个通用的混合建模单元输出,独立构建的各语种语言模型与该统一的建模单元进行结合,构建各语种的语音识别系统解码所需要的网络(如wfst网络),然后对语种网络进行并行解码。本发明通过构建统一建模声学单元与语种独立语言模型进行结合的方式,完成多语种语音识别系统。
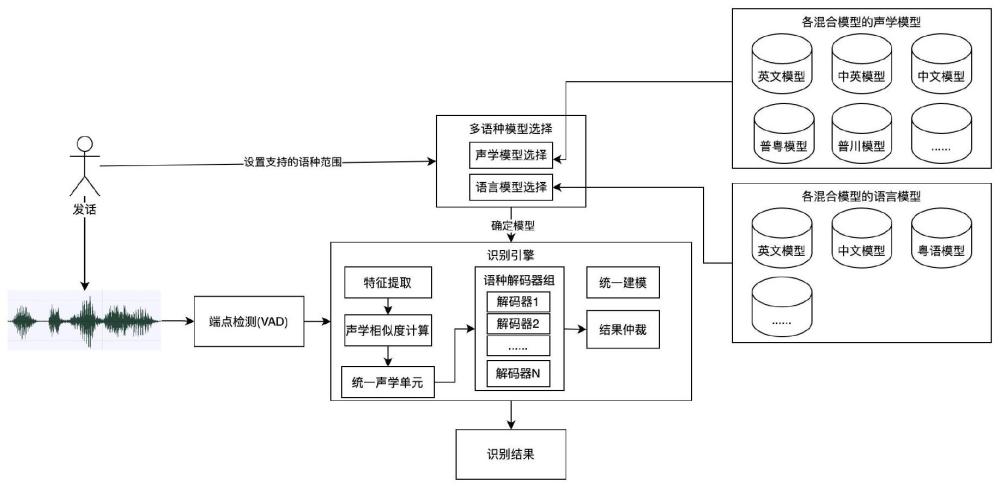
2、本发明提供一种多语种识别系统,包括多语种模型选择模块、声学模型库、语言模型库、端点检测装置、识别引擎、以及输出单元;其中,
3、所述多语种模型选择模块,用于根据用户输入的语种范围,在所述声学模型库中选择对应语种的一个声学模型,并在所述语言模型库中选择对应语种的一个或多个语言模型;
4、所述端点检测装置用于在用户发话后,找到用户发话的开始和结束的位置,并将探测到的用户发话传送给所述识别引擎;
5、所述识别引擎包括特征提取单元、声学相似度计算单元、统一声学模型单元、语种解码器组、以及结果仲裁单元;
6、所述特征提取单元用于对所述探测到的用户发话进行特征提取;
7、所述统一声学模型单元用于构建并存储所述统一声学模型;
8、所述声学相似度计算单元用于使用已选择的所述声学模型对所述提取单元提取的所述特征进行声学相似度计算;并将所述声学相似度计算结果,根据所述声学模型与所述统一声学模型的对应关系,投影到所述统一声学模型上;
9、所述语种解码器组用于基于所述统一声学模型,采用与多个所述语言模型对应的多个解码器进行解码,并解码出各自的识别结果;
10、所述结果仲裁单元,用于基于所述语种解码器组中针对多个所述语言模型的多个所述识别结果,综合选择最终的结果。
11、进一步地,构建所述统一声学模型时,通过线性投影的方式将所述声学模型库中的各所述声学模型投影到所述统一声学模型上。
12、本发明提供一种多语种识别方法,其特征在于,
13、根据用户输入的语种范围,在声学模型库中选择一个声学模型;
14、根据用户输入的所述语种范围,在语言模型库中选择一个或多个语言模型;
15、对端点检测装置探测到的用户发话进行特征提取,然后使用所述声学模型对提取的所述特征进行声学相似度计算;
16、将所述声学相似度计算结果投影到统一声学模型与所述声学模型对应的区域上;
17、基于所述统一声学模型,利用与所述语言模型对应的语种解码器解码,获得各语种的识别结果;
18、对各语种的所述识别结果进行结果仲裁,获得最优结果。
19、进一步地,构建所述统一声学模型时,通过线性投影的方式将所述声学模型库中的各所述声学模型投影到所述统一声学模型上。
20、本发明还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现本发明所述方法的步骤。
21、本发明还提供一种电子设备,包括:
22、一个或多个处理器;以及
23、与所述一个或多个处理器关联的存储器,所述存储器用于存储程序指令,所述程序指令在被所述一个或多个处理器读取执行时,执行本发明所述方法的步骤。
24、采用本发明所述的系统和方法,可以有效地解决多语种识别系统的资源占用问题以及多模型的资源管理问题。
25、以四个语种(普通话、英文、粤语、四川话)、单个语种模型为400m为例,用户可以说支持范围内的任意语种。按各语种组合方法,现有技术中系统的存储空间需要400m×4+800m×6+1200m×4+1600m=12800m,最大使用内存为1600m;按照本发明提供的系统和方法,需要存储空间为400m×4=1600m,最大内存为400m×4=1600m。通过比较得知,本发明所述的方法可以大大减小资源占用空间。
- 还没有人留言评论。精彩留言会获得点赞!