一种数字人音视频生成系统的制作方法
本技术实施例涉及数字人技术,涉及但不限于一种数字人音视频生成系统。
背景技术:
1、数字人技术是一种利用人工智能、自然语言处理等技术,模拟人的外貌、声音、行为和语言等,创建高度逼真、可交互的虚拟人物或数字化形象的技术。目前,数字人技术在视频创作领域得到越来越广泛的应用,例如,为了提升用户科普类视频的制作效率,可以采用数字人技术快速生成与用户形象、声音等匹配的数字人形象的科普视频,节省用户录制视频的时间。
2、然而,现有技术在采用数字人技术在创作视频时,由于在合成视频的过程中,数字人形象的嘴型变化会导致合成视频中人脸画质下降,如分辨率下降、脸部纹理丢失、脸部颜色不一致等,使得视频质量和逼真度不够,从而降低了用户的观看体验。
技术实现思路
1、有鉴于此,本技术实施例提供一种数字人音视频生成系统,本技术实施例提供的一种数字人音视频生成系统是这样实现的:
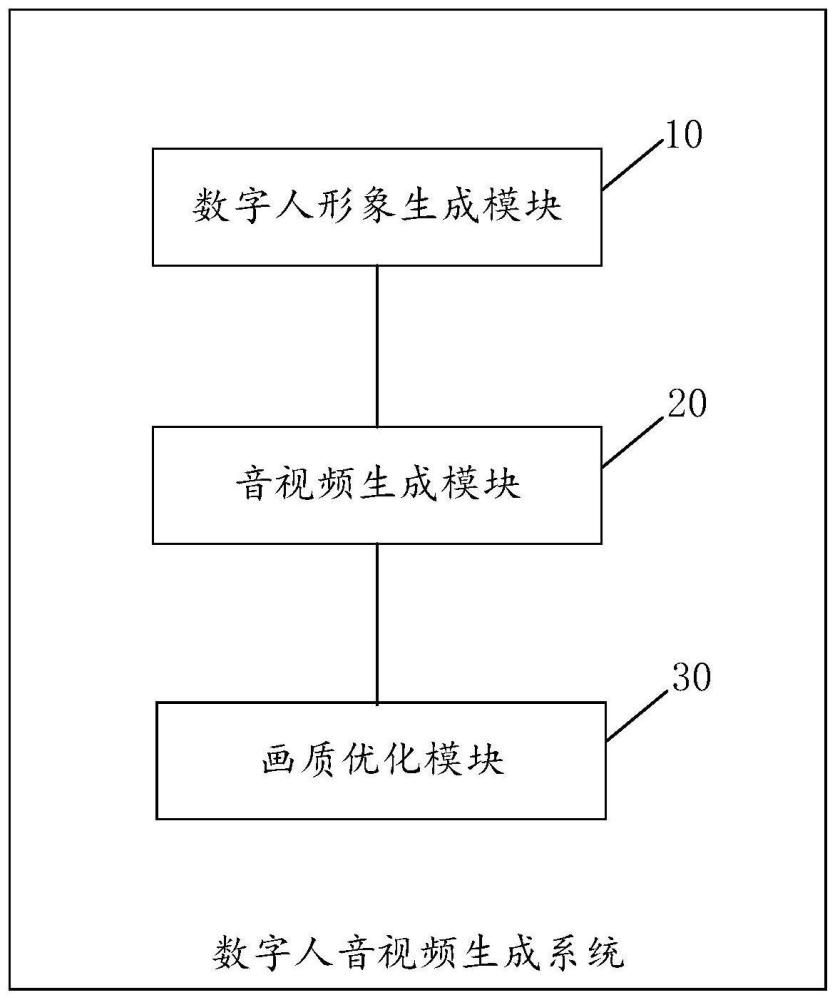
2、本技术实施例提供的一种数字人音视频生成系统,所述系统包括数字人形象生成模块、音视频生成模块以及画质优化模块,其中:
3、所述数字人形象生成模块,用于获取初始音视频,所述初始音视频为包括目标用户形象和语音的音视频,以及,根据所述初始音视频创建得到与所述目标用户形象和语音对应的目标数字人形象的音视频;
4、所述音视频生成模块,用于获取录制文本数据,以及,根据所述录制文本数据以及所述目标数字人形象的音视频,生成初始数字人音视频,所述目标数字人形象的嘴型变化与所述录制文本数据对应;
5、所述画质优化模块,用于对所述初始数字人音视频进行人脸修复处理,生成目标数字人音视频,所述人脸修复处理是针对所述目标数字人形象的嘴型变化引起的画质降低的修复处理。
6、本技术实施例中,用户利用该系统不仅可以自动生成数字人音视频,还提高了音视频质量、画质,从而提高了用户的观看体验,解决了现有技术中视频质量和逼真度不够的问题。
7、在一些实施例中,所述音视频生成模块包括语音合成单元以及嘴型合成单元,其中:
8、所述语音合成单元,用于将所述录制文本数据以及所述目标数字人形象的音视频输入到预存的目标语音合成模型,得到目标合成音频,所述目标语音合成模型是根据目标用户的语音合成训练数据对预设语音合成模型进行训练得到的,每个用户对应唯一的语音合成模型;
9、所述嘴型合成单元,用于将所述目标数字人形象的音视频以及所述目标合成音频输入到预存的目标嘴型合成模型,得到所述初始数字人音视频,所述目标嘴型合成模型是根据嘴型合成训练数据对预设嘴型合成模型进行训练得到的。
10、该实施例中,利用语音合成模型和嘴型合成模型可以快速生成数字人音视频,提高了音视频制作效率,节省了用户录制和剪辑音视频的时间成本。
11、在一些实施例中,所述画质优化模块包括人脸修复输入单元以及人脸修复处理单元,其中:
12、所述人脸修复输入单元,用于获取并将所述初始数字人音视频输入到所述人脸修复处理单元;
13、所述人脸修复处理单元,用于接收所述初始数字人音视频,并根据预存的目标人脸修复模型对所述初始数字人音视频进行处理,得到所述目标数字人音视频,所述目标人脸修复模型是根据人脸修复训练数据对预设人脸修复模型进行训练得到的。
14、该实施例中,利用人脸修复模型可以快速、准确的对生成的初始数字人音视频进行画质优化及修复,有效避免了因数字人形象的嘴型变化引起的画质降低的问题,提高了用户的观看体验。
15、在一些实施例中,所述系统还包括语音合成训练模块、嘴型合成训练模块以及人脸修复训练模块,其中:
16、所述语音合成训练模块,用于根据所述目标用户的语音合成训练数据对所述预设语音合成模型进行训练,得到所述目标语音合成模型;
17、所述嘴型合成训练模块,用于根据所述嘴型合成训练数据对所述预设嘴型合成模型进行训练,得到所述目标嘴型合成模型;
18、所述人脸修复训练模块,用于根据所述人脸修复训练数据对所述预设人脸修复模型进行训练,得到所述目标人脸修复模型。
19、该实施例中,利用多种训练数据分别对模型进行训练,可以帮助模型学习数据中的模式、关联和特征,从而提高模型生成数字人音视频的准确性,以及提高生成的数字人音视频的视频质量和逼真度。
20、在一些实施例中,所述语音合成训练模块包括第一音频获取单元、音频预处理单元以及语音合成训练单元,包括:
21、所述第一音频获取单元,用于获取所述目标用户的语音合成训练数据,所述目标用户的语音合成训练数据包括初始音频以及与所述初始音频对应的文本数据,所述初始音频为包括目标用户语音的音频;
22、所述音频预处理单元,用于对所述初始音频进行预处理,得到目标韵律以及目标音素时长,所述预处理至少包括音频切片、韵律标注以及音素时长标注;
23、所述语音合成训练单元,用于将所述文本数据输入到所述预设语音合成模型,得到预设合成音频,以及,提取所述预设合成音频对应的韵律以及音素时长,以及,将所述预设合成音频对应的韵律以及音素时长与所述目标韵律以及所述目标音素时长分别进行对比,得到语音合成损失参数,以及,在所述语音合成损失参数符合预设语音合成神经网络参数的情况下,得到所述目标语音合成模型。
24、该实施例中,对初始音频进行预处理能够从不同维度提高模型训练效率和训练效果;此外,通过对比语音合成损失参数以及预设语音合成神经网络参数,有助于提高模型在语音合成时的准确率,并生成更加自然的合成语音。
25、在一些实施例中,所述嘴型合成训练模块包括第二音频获取单元、音频图像配对单元、音视频生成单元以及音频口型同步判别单元,所述预设嘴型合成模型包括音视频生成器以及音频口型同步判别器,其中:
26、所述第二音频获取单元,用于获取所述嘴型合成训练数据,所述嘴型合成训练数据包括至少一个用户的音频以及与所述至少一个用户对应的人脸图像,所述音频包括所述至少一个用户的初始音频和/或合成音频;
27、所述音频图像配对单元,用于对所述至少一个用户的音频进行特征提取,得到音频特征,以及,将所述音频特征与所述人脸图像进行配对,得到音频图像对;
28、所述音视频生成单元,用于将所述音频图像对输入到所述音视频生成器,生成预设数字人音视频,所述预设数字人音视频中数字人形象的嘴型变化与所述至少一个用户的音频的内容对应;
29、所述音频口型同步判别单元,用于将所述预设数字人音视频输入到所述音频口型同步判别器进行判别,得到判别结果,以及,在所述判别结果指示所述预设数字人音视频中数字人形象的嘴型变化与所述至少一个用户的音频的内容同步的情况下,得到所述目标嘴型合成模型。
30、该实施例中,音频图像对可以帮助模型学习在嘴型合成时如何根据音频特征生成与之匹配的嘴型变化,通过判别器可以确保数字人嘴型变化与预设的录制文本同步,从而提高了模型生成的数字人音视频中数字人嘴型变化的一致性和真实性。
31、在一些实施例中,所述人脸修复训练模块包括人脸图像获取单元以及人脸修复训练单元,其中:
32、所述人脸图像获取单元,用于获取所述人脸修复训练数据,所述人脸修复训练数据包括低清人脸图像以及与所述低清人脸图像对应的高清人脸图像;
33、所述人脸修复训练单元,用于将所述低清人脸图像输入到所述预设人脸修复模型进行修复,得到修复后的人脸图像,以及,计算所述修复后的人脸图像与所述高清人脸图像的重建误差,在所述重建误差满足预设人脸修复神经网络参数的情况下,得到所述目标人脸修复模型。
34、该实施例中,可以客观地评估模型的修复效果,帮助模型学习在人脸修复时得到更高画质的人脸图像,从而提高了模型生成的数字人音视频的画质和人脸逼真度。
35、在一些实施例中,所述系统还包括数字人形象存储模块,其中:
36、所述数字人形象存储模块,用于将所述数字人形象生成模块创建的数字人形象的音视频存储在数字人形象库中,所述数字人形象库包括至少一个用户的数字人形象的音视频,所述至少一个用户的数字人形象的音视频包括所述目标数字人形象的音视频。
37、该实施例中,支持用户在系统中预先创建与用户形象对应的数字人形象,方便用户后续制作数字人音视频时选择需要的数字人形象。
38、在一些实施例中,所述音视频生成模块,还用于在所述根据所述录制文本数据以及所述目标数字人形象的音视频,生成初始数字人音视频之前,从所述数字人形象库中获取所述目标数字人形象的音视频。
39、该实施例中,当用户在创建数字人形象的音视频时,可以快速从数字人形象库中获取数字人形象,提高了数字人音视频制作的效率以及操作便捷性。
40、在一些实施例中,所述系统还包括素材存储模块,其中:
41、所述素材存储模块,用于获取文本素材、背景素材以及封面素材,并将所述文本素材、所述背景素材以及所述封面素材存储在素材库中,所述文本素材包括所述录制文本数据;
42、所述音视频生成模块,还用于从所述素材库或文本内容输入框中获取所述录制文本数据,所述文本内容输入框用于根据用户的输入操作获取所述录制文本数据,以及,从所述素材库中获取目标背景和目标封面,并根据所述录制文本数据、所述目标背景、所述目标封面以及所述目标数字人形象的音视频,生成所述初始数字人音视频。
43、该实施例中,当用户在创建数字人形象的音视频时,可以选择背景素材以及封面素材,提高了音视频制作的趣味和数字人形象的丰富度,还提高了数字人音视频的呈现效果。
- 还没有人留言评论。精彩留言会获得点赞!