一种通话场景说话人识别方法
本发明涉及语音识别领域,具体涉及一种通话场景说话人识别方法。
背景技术:
1、说话人识别是生物特征识别的重要手段之一,在刑侦、金融、安全等领域极具应用价值。其中,对通话语音进行说话人识别是一个极具挑战性的现实场景。该类语音具有采样率低、背景噪声复杂和实时性要求高这三大特征。现有方法往往基于深度学习技术,在高质量语音数据下表现良好,但在低采样率和嘈杂的通话环境中效果不佳。此外,现有方法倾向于使用复杂的网络结构优化精度,难以满足实时性需求。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的一种通话场景说话人识别方法解决了现有方法在低采样率和嘈杂的通话环境中效果不佳、难以满足实时性需求的问题。
2、为了达到上述发明目的,本发明采用的技术方案为:
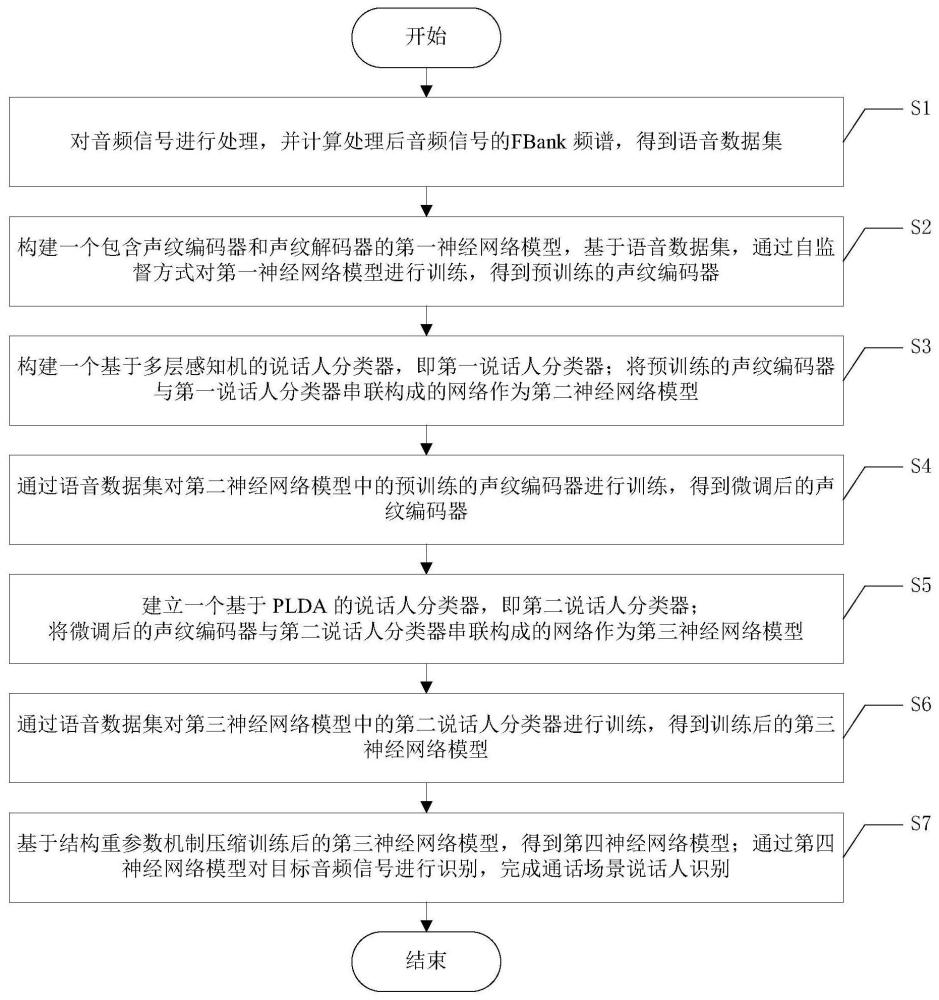
3、提供一种通话场景说话人识别方法,其包括以下步骤:
4、s1、对音频信号进行处理,并计算处理后音频信号的fbank频谱,得到语音数据集;
5、s2、构建一个包含声纹编码器和声纹解码器的第一神经网络模型,基于语音数据集,通过自监督方式对第一神经网络模型进行训练,得到预训练的声纹编码器;
6、s3、构建一个基于多层感知机的说话人分类器,即第一说话人分类器;将预训练的声纹编码器与第一说话人分类器串联构成的网络作为第二神经网络模型;
7、s4、通过语音数据集对第二神经网络模型中的预训练的声纹编码器进行训练,得到微调后的声纹编码器;
8、s5、建立一个基于plda的说话人分类器,即第二说话人分类器;将微调后的声纹编码器与第二说话人分类器串联构成的网络作为第三神经网络模型;
9、s6、通过语音数据集对第三神经网络模型中的第二说话人分类器进行训练,得到训练后的第三神经网络模型;
10、s7、基于结构重参数机制压缩训练后的第三神经网络模型,得到第四神经网络模型;通过第四神经网络模型对目标音频信号进行识别,完成通话场景说话人识别。
11、进一步地,步骤s1的具体方法为:
12、对音频信号进行分帧、加窗和梅尔滤波后计算fbank频谱,结合音频信号的说话人标签,得到语音数据集。
13、进一步地,声纹编码器包括至少28个串联的多尺度卷积块、一个注意力统计池化模块和一个全连接层;其中:
14、第一个多尺度卷积块,用于将fbank频谱作为输入,并输出对应的特征;
15、第l个多尺度卷积块,用于将第l-1个多尺度卷积块输出的特征作为输入,并输出对应的特征;其中l大于等于2;最后一个多尺度卷积块的输出为帧级特征;
16、注意力统计池化模块和全连接层,用于将最后一个多尺度卷积块输出的帧级特征作为输入,并将对应的输出作为说话人的深层特征。
17、进一步地,单个多尺度卷积块对输入数据的具体处理过程包括以下子步骤:
18、a1、将输入数据分别输入1×1卷积层和3×3卷积层,得到两种不同尺度的特征图;
19、a2、对输入数据和两种不同尺度的特征图分别进行输入批量归一化,并将三个批量归一化的输出对应输入三个dropblock正则化层,得到三种经归一正则化的特征;
20、a3、将步骤a2得到的三种经归一正则化输入特征相加层进行特征相加后输入se模块,并通过leaky relu函数激活,即得到输出。
21、进一步地,将帧级特征作为输入,并将对应的输出作为说话人的深层特征的具体方法包括以下子步骤:
22、b1、根据公式:
23、ut=f(wht+b)
24、将帧级特征中的每一帧通过全连接层映射到低维子空间;其中ht表示帧级特征中的第t帧;w表示线性映射;b为偏置;f(.)表示激活函数;ut为映射后的低维帧;
25、b2、根据公式:
26、
27、获取帧级特征中每一帧的注意力权重;其中αt为帧级特征中第t帧的注意力权重;exp表示以自然常数e为底的指数;t为帧级特征的总帧数,也即fbank频谱的总帧数;表示ut的转置;k为偏置;
28、b3、根据公式:
29、
30、
31、得到帧级特征的加权平均数和加权标准差其中⊙表示按元素相乘;
32、b4、根据公式:
33、
34、得到说话人的深层特征r;其中conc[.]为拼接函数。
35、进一步地,声纹解码器包括依次连接的全连接层、1d卷积层、变形模块和多尺度转置卷积网络;其中:
36、全连接层,用于将声纹编码器的输出映射到高维子空间,得到高维特征向量;
37、1d卷积层,用于增加高维特征向量的通道数并保持高维特征向量的特征维数,得到多通道高维特征向量;
38、变形模块,用于将多通道高维特征向量中各通道向量的同维分量变形为二维特征图,得到多通道特征图;
39、多尺度转置卷积网络,用于将多通道特征图还原为fbank频谱,即得到第一神经网络模型的输出。
40、进一步地,多尺度转置卷积网络包括依次串联的15个多尺度转置卷积模块、1个2d转置卷积层、5个多尺度转置卷积模块、1个2d转置卷积层、3个多尺度转置卷积模块、2个2d转置卷积层、1个多尺度转置卷积模块和1个2d转置卷积层;其中单个多尺度转置卷积块对输入的具体处理过程包括以下子步骤:
41、c1、将输入数据分别输入1×1转置卷积层和3×3转置卷积层,得到两种不同尺度的多通道特征图;
42、c2、将原始输入数据和步骤c1得到的两种不同尺度的多通道特征图分别进行批量归一化和dropblock正则化,得到三种经归一正则化的特征;
43、c3、将步骤c2得到的三种经归一正则化的特征相加后输入se模块,并通过leakyrelu函数激活,得到该多尺度转置卷积块的输出。
44、进一步地,步骤s2中通过自监督方式对第一神经网络模型中的声纹编码器进行训练时的损失函数表达式为:
45、
46、其中loss1表示损失值;n表示训练样本批量大小;d表示fbank频谱中包含的分量总数;t表示fbank频谱的总帧数;表示第i个音频信号的fbank频谱的j个分量;表示第一神经网络模型输出的第i个音频信号的fbank频谱的j个分量;为l2正则项。
47、进一步地,步骤s4中对第二神经网络模型中的预训练的声纹编码器进行训练过程中的损失函数表达式为:
48、
49、
50、其中loss2表示损失值;n表示训练样本批量大小;e表示说话人数量;yij为取值函数,取值为1或0,当yij取值为1时表示第i个样本属于第j个说话人,当yij取值为0时表示第i个样本不属于第j个说话人;pij表示第i个样本属于第j个说话人的概率;log(.)表示以10为底的对数;e为自然常数;zij表示第i个样本属于第j个说话人的置信度;zik表示第i个样本属于第k个说话人的置信度。
51、进一步地,步骤s7中基于结构重参数机制压缩训练后的第三神经网络模型的具体方法包括以下子步骤:
52、s7-1、对于训练后的第三神经网络模型中声纹编码器中的每个多尺度卷积块,将特征相加之前的三路结构分别转换为等效的3×3卷积层,得到3个3×3卷积核;
53、s7-2、将步骤s7-1中得到的3个3×3卷积核相加得到单个3×3卷积核;
54、s7-3、将步骤s7-2中得到的单个3×3卷积核对应的卷积层替换多尺度卷积块中se模块之前的结构,完成对训练后的第三神经网络模型的基于结构重参数机制压缩。
55、本发明的有益效果为:本方法使用音频信号的fbank频谱作为说话人的浅层特征表示,通过声纹编码器增强浅层说话人特征表示中的各种局部模式,生成说话人特征的深度表示;然后使用这些深度表示训练plda分类器;最后使用结构重参数机制合并声纹编码器中冗余的网络层,并使用声纹编码器和plda分类器预测不同语音信号属于同一说话人的概率,不仅可以进行有效的说话人识别,还可以加快识别速度,解决了现有技术在低采样率和嘈杂的通话环境中效果不佳、难以满足实时性要求的问题。
- 还没有人留言评论。精彩留言会获得点赞!