声学模型训练方法、音色融合方法、装置、设备及介质与流程
本发明涉及音色融合,特别涉及一种声学模型训练方法、音色融合方法、装置、设备及介质。
背景技术:
1、目前的语音合成系统在合成语音的过程中,需要指定发音人或者根据参考语音合成特定发音人的语音,这种情况下,发音人的音色选择有很大的限制,同时针对一些个性化的音色需求无法即时进行满足。
2、为此,如何解决发音人的音色选择的限制,同时产生任意多个融合音色,是本领域亟待解决的问题。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种声学模型训练方法、音色融合方法、装置、设备及介质,能够解决发音人的音色选择的限制,同时产生任意多个融合音色,其具体方案如下:
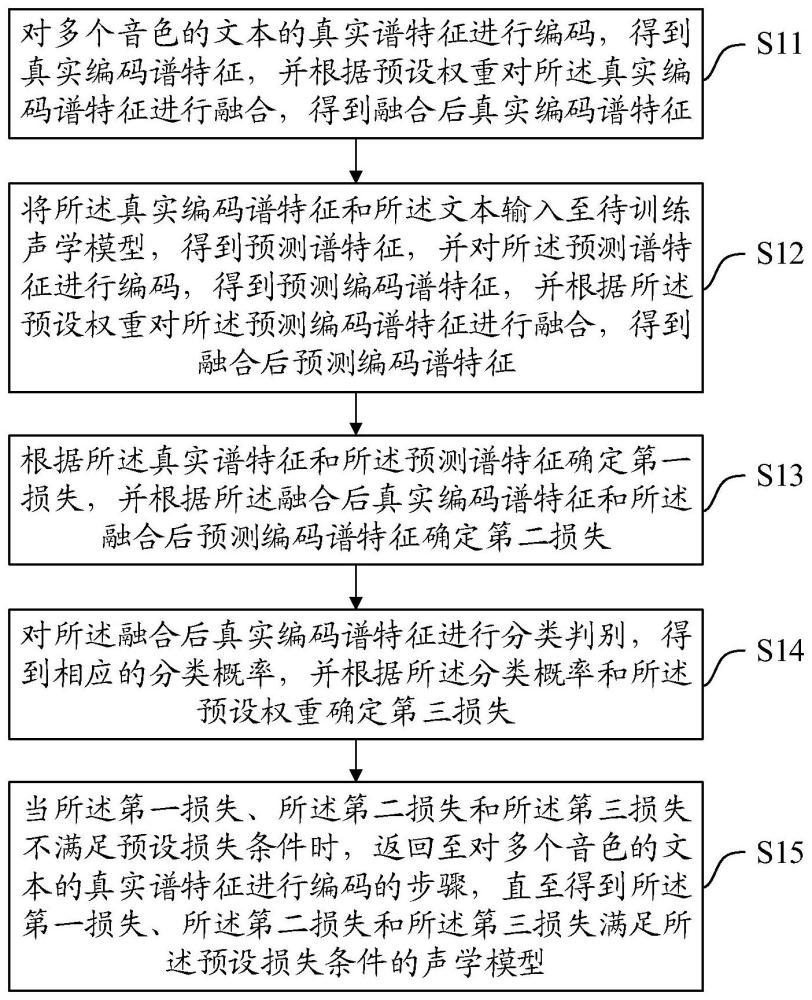
2、第一方面,本技术公开了一种声学模型训练方法,包括:
3、对多个音色的文本的真实谱特征进行编码,得到真实编码谱特征,并根据预设权重对所述真实编码谱特征进行融合,得到融合后真实编码谱特征;
4、将所述真实编码谱特征和所述文本输入至待训练声学模型,得到预测谱特征,并对所述预测谱特征进行编码,得到预测编码谱特征,并根据所述预设权重对所述预测编码谱特征进行融合,得到融合后预测编码谱特征;
5、根据所述真实谱特征和所述预测谱特征确定第一损失,并根据所述融合后真实编码谱特征和所述融合后预测编码谱特征确定第二损失;
6、对所述融合后真实编码谱特征进行分类判别,得到相应的分类概率,并根据所述分类概率和所述预设权重确定第三损失;
7、当所述第一损失、所述第二损失和所述第三损失不满足预设损失条件时,返回至对多个音色的文本的真实谱特征进行编码的步骤,直至得到所述第一损失、所述第二损失和所述第三损失满足所述预设损失条件的声学模型。
8、可选的,所述对多个音色的文本的真实谱特征进行编码,得到真实编码谱特征,包括:
9、利用语音编码器对多个音色的所述文本的所述真实谱特征进行编码,得到多个所述真实编码谱特征;
10、相应的,所述对所述预测谱特征进行编码,得到预测编码谱特征,包括:
11、利用所述语音编码器对所述预测谱特征进行编码,得到多个所述预测编码谱特征。
12、可选的,所述根据预设权重对所述真实编码谱特征进行融合,得到融合后真实编码谱特征,包括:
13、确定多个所述预设权重;
14、根据多个所述预设权重对多个所述真实编码谱特征进行融合,得到所述融合后真实编码谱特征;
15、相应的,所述根据所述预设权重对所述预测编码谱特征进行融合,得到融合后预测编码谱特征,包括:
16、根据多个所述预设权重对多个所述预测编码谱特征进行融合,得到所述融合后预测编码谱特征。
17、可选的,所述确定多个所述预设权重,包括:
18、从多个所述文本中随机采样得到多个所述预设权重;
19、或,指定多个所述预设权重。
20、可选的,所述对所述融合后真实编码谱特征进行分类判别,得到相应的分类概率,包括:
21、利用预设分类器对所述融合后真实编码谱特征进行分类判别,得到相应的所述分类概率;其中,所述分类概率为所述真实编码谱特征中各个音色所占概率。
22、第二方面,本技术公开了一种音色融合方法,包括:
23、获取多个音色的真实谱特征,并对所述真实谱特征进行编码,得到真实编码谱特征;
24、根据预设权重对所述真实编码谱特征进行融合,得到融合后真实编码谱特征;
25、将所述融合后真实编码谱特征和待合成文本输入至利用如前述所述的声学模型训练方法得到的声学模型,得到预测谱特征;
26、根据所述预测谱特征实现针对所述待合成文本的音色融合。
27、第三方面,本技术公开了一种声学模型训练装置,包括:
28、真实编码谱特征融合模块,用于对多个音色的文本的真实谱特征进行编码,得到真实编码谱特征,并根据预设权重对所述真实编码谱特征进行融合,得到融合后真实编码谱特征;
29、预测编码谱特征融合模块,用于将所述真实编码谱特征和所述文本输入至待训练声学模型,得到预测谱特征,并对所述预测谱特征进行编码,得到预测编码谱特征,并根据所述预设权重对所述预测编码谱特征进行融合,得到融合后预测编码谱特征;
30、第一损失和第二损失确定模块,用于根据所述真实谱特征和所述预测谱特征确定第一损失,并根据所述融合后真实编码谱特征和所述融合后预测编码谱特征确定第二损失;
31、第三损失确定模块,用于对所述融合后真实编码谱特征进行分类判别,得到相应的分类概率,并根据所述分类概率和所述预设权重确定第三损失;
32、声学模型生成模块,用于当所述第一损失、所述第二损失和所述第三损失不满足预设损失条件时,返回至对多个音色的文本的真实谱特征进行编码的步骤,直至得到所述第一损失、所述第二损失和所述第三损失满足所述预设损失条件的声学模型。
33、第四方面,本技术公开了一种音色融合装置,包括:
34、真实编码谱特征确定模块,用于获取多个音色的真实谱特征,并对所述真实谱特征进行编码,得到真实编码谱特征;
35、融合后真实编码谱特征确定模块,用于根据预设权重对所述真实编码谱特征进行融合,得到融合后真实编码谱特征;
36、预测谱特征确定模块,用于将所述融合后真实编码谱特征和待合成文本输入至利用如前述所述的声学模型训练方法得到的声学模型,得到预测谱特征;
37、音色融合模块,用于根据所述预测谱特征实现针对所述待合成文本的音色融合。
38、第五方面,本技术公开了一种电子设备,包括:
39、存储器,用于保存计算机程序;
40、处理器,用于执行所述计算机程序,以实现前述公开的方法。
41、第六方面,本技术公开了一种计算机可读存储介质,用于保存计算机程序;其中,所述计算机程序被处理器执行时实现前述公开的方法。
42、可见,本技术提出一种声学模型训练方法,包括:对多个音色的文本的真实谱特征进行编码,得到真实编码谱特征,并根据预设权重对所述真实编码谱特征进行融合,得到融合后真实编码谱特征;将所述真实编码谱特征和所述文本输入至待训练声学模型,得到预测谱特征,并对所述预测谱特征进行编码,得到预测编码谱特征,并根据所述预设权重对所述预测编码谱特征进行融合,得到融合后预测编码谱特征;根据所述真实谱特征和所述预测谱特征确定第一损失,并根据所述融合后真实编码谱特征和所述融合后预测编码谱特征确定第二损失;对所述融合后真实编码谱特征进行分类判别,得到相应的分类概率,并根据所述分类概率和所述预设权重确定第三损失;当所述第一损失、所述第二损失和所述第三损失不满足预设损失条件时,返回至对多个音色的文本的真实谱特征进行编码的步骤,直至得到所述第一损失、所述第二损失和所述第三损失满足所述预设损失条件的声学模型。综上可见,本技术通过对真实谱特征和预测谱特征进行编码,实现了以无监督的方式来训练声学模型,从而无需额外的标注每个音色的文本的说话人信息。其次,本技术在训练的过程中将融合后真实编码谱特征加入到声学模型中,这样一来,提升了声学模型在音色融合阶段的合成稳定性。最后,本技术根据预设权重对真实编码谱特征和预测编码谱特征分别进行融合,从而保证了融合后真实编码谱特征和融合后预测编码谱特征中包含多个被融合音色的信息及其占比,提升了音色融合阶段中融合音色的可控性。
- 还没有人留言评论。精彩留言会获得点赞!