点读笔的语音识别方法与流程
本发明涉及语音识别,尤其涉及一种点读笔的语音识别方法。
背景技术:
1、点读笔的语音识别让用户能够用口语与设备互动,促进了更自然、更直接的交流方式。这种交互方式能激发兴趣,让学习变得更生动有趣。语音识别使点读笔能够适应不同用户的需求。它可以根据用户的口音、语速和语言习惯提供个性化的反馈和学习内容,更贴近个体需求。语音识别为点读笔增加了更多可能性,可以用于语音搜索、交互式教学、语音评估等教学应用,丰富了教学手段和体验。然而,现有的点读笔的语音识别方法由于仅通过语音内容进行分析,导致分析结果不够细节准确,使用者无法完全理解错误点。
技术实现思路
1、基于此,有必要提供一种点读笔的语音识别方法,以解决至少一个上述技术问题。
2、为实现上述目的,一种点读笔的语音识别方法,所述方法包括以下步骤:
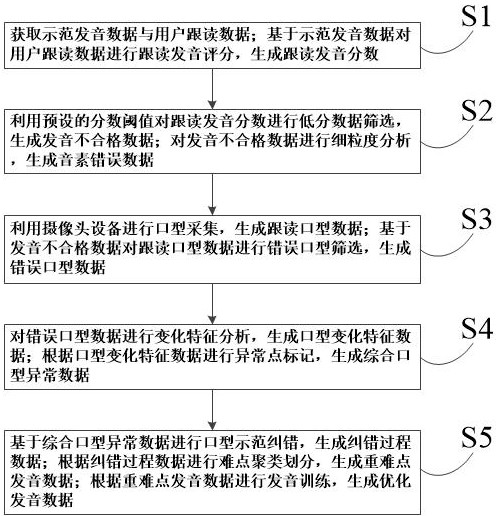
3、步骤s1:获取示范发音数据与用户跟读数据;基于示范发音数据对用户跟读数据进行跟读发音评分,生成跟读发音分数;
4、步骤s2:利用预设的分数阈值对跟读发音分数进行低分数据筛选,生成发音不合格数据;对发音不合格数据进行细粒度分析,生成音素错误数据;
5、步骤s3:利用摄像头设备进行口型采集,生成跟读口型数据;基于发音不合格数据对跟读口型数据进行错误口型筛选,生成错误口型数据;
6、步骤s4:对错误口型数据进行变化特征分析,生成口型变化特征数据;根据口型变化特征数据进行异常点标记,生成综合口型异常数据;
7、步骤s5:基于综合口型异常数据进行口型示范纠错,生成纠错过程数据;根据纠错过程数据进行难点聚类划分,生成重难点发音数据;根据重难点发音数据进行发音训练,生成优化发音数据。
8、本发明通过对比示范发音和用户跟读数据,可以量化用户的发音准确性,并生成跟读发音分数。为用户提供了明确的分数,帮助了解发音表现,激励改进口语。通过阈值筛选发音不合格数据,侧重于发音问题明显的数据,以便进一步分析。针对音素错误数据进行分析,识别具体的音素发音问题,为纠正提供具体方向。利用摄像头采集口型数据,用于发现口型不正确的情况。通过对口型数据进行错误筛选,能够更准确地定位到用户在发音过程中存在的口型问题。通过对口型数据的变化进行分析,发现口型问题的特定模式或规律。识别口型异常,进一步凸显口型方面的问题。基于口型异常数据进行示范纠错,以改善口型问题,提供更符合标准的口型示范。通过对难点发音数据的聚类划分,针对性地进行训练,强化用户在特定难点上的发音能力。因此,本发明的点读笔的语音识别方法通过细粒度分析以得到音素细节问题的同时,还对用户的跟读口型数据进行口型错误分析,从而综合评估用户的错误发音点,以提高纠错的准确性,改进用户发音习惯。
9、优选地,步骤s1包括以下步骤:
10、步骤s11:获取示范发音数据与用户跟读数据;基于示范发音数据进行特殊发音点标记,生成特殊发音要求数据;
11、步骤s12:对用户跟读数据进行短时能量与基频变化分析,生成语速语调数据;对语速语调数据进行节奏韵律分析,生成节奏韵律特征数据;
12、步骤s13:对用户跟读数据进行信号转换,生成跟读声谱图;基于跟读声谱图进行声纹特征分析,生成声纹特征数据;
13、步骤s14:利用节奏韵律特征数据对声纹特征数据进行特征偏差修正,生成跟读特征数据;
14、步骤s15:根据跟读特征数据进行综合跟读发音评分,生成综合评分因素数据;
15、步骤s16:根据特殊发音要求数据对节奏韵律特征数据进行特殊跟读发音评分,生成关键评分因素数据;
16、步骤s17:基于综合评分因素数据与关键评分因素数据进行发音总评分,生成跟读发音分数。
17、本发明通过标记示范发音中的特殊发音点,可能包括音调变化、特殊音素等,提供重点指导用户关注这些发音。短时能量和基频变化分析语速语调,而节奏韵律分析提供了语音的节奏、音调等信息。这些数据可以帮助用户了解自己的语音节奏和音调,有助于提高口语流畅度和自然度。基于节奏韵律和声纹特征数据,对跟读数据中的特征进行修正,以减少发音偏差和提高准确性。修正后的数据有助于提高用户的发音精准度,让他们更接近标准发音。结合跟读特征数据,综合考量语速、音调、声纹等多个因素,为用户的发音表现提供全面评价。综合评分因素数据提供了用户发音能力的多维度评估,有助于用户了解自己在不同方面的表现情况。根据特殊发音要求数据,对关键的发音点进行特殊评分,将重点放在发音需求特殊的部分。这些数据突出了用户在特定发音点上的表现,使得评分更加关注发音中的重点和需要改进的地方。基于综合评分因素数据和关键评分因素数据,生成最终的发音总评分,综合考虑了各方面的表现。最终的发音总评分提供了对用户整体发音能力的评估,为用户提供了全面的反馈,并指明改进的方向。
18、优选地,步骤s2包括以下步骤:
19、步骤s21:利用预设的分数阈值对跟读发音分数进行低分数据筛选,生成发音不合格数据;
20、步骤s22:根据综合评分因素数据对发音不合格数据的跟读特征数据进行误差片段切分,生成跟读误差特征数据;
21、步骤s23:基于特殊发音要求数据进行音素边界标记,生成音素边界划分数据;
22、步骤s24:利用音素边界划分数据对节奏韵律特征数据进行偏差音素提取,生成音素错误数据。
23、本发明通过分数阈值将低分数据筛选出来,定位发音不合格的具体数据,提供特定问题的定量信息。有助于后续更精准地进行错误分析和改进。根据综合评分因素数据切分发音不合格数据中的误差片段,帮助定位发音错误的具体部分。提供了针对性的错误片段,使得问题更具体、更可分析,为改进提供更明确的方向。根据特殊发音要求数据对音素进行边界标记,以便更精确地识别音素的具体位置。音素边界的划分有助于更准确地找出发音存在问题的具体音素,使得后续分析更加精确。利用音素边界划分数据,提取出节奏韵律特征数据中存在偏差的音素部分。提供了精确的发音问题位置,帮助更准确地识别发音的具体错误,并进行针对性的改进。
24、优选地,步骤s3包括以下步骤:
25、步骤s31:利用摄像头设备获取人脸图像数据;
26、步骤s32:利用摆放方位测算公式,并根据预采集的人脸正面图像数据与人脸图像数据进行设备摆放方位测算,生成预摆放位置数据;
27、步骤s33:根据预摆放位置数据对摄像头设备进行方位调整,并进行口型采集,生成跟读口型数据;
28、步骤s34:基于发音不合格数据对跟读口型数据进行口型数据筛选,生成错误口型数据。
29、本发明通过摄像头设备捕获人脸图像数据,用于后续口型信息的提取和分析。人脸图像数据有助于分析口型的形状、变化,为发音评估提供额外信息。利用预先采集的人脸正面图像数据和当前人脸图像数据,计算出设备的摆放位置,以确保更好的捕捉口型信息。通过设备位置的测算和调整,有助于提高口型采集的准确性和可靠性。在校准后的设备位置下,使用摄像头捕捉口型数据,记录用户的口型变化和发音过程。口型数据的收集有助于捕捉口形变化和发音过程中的动态信息。基于发音不合格数据对口型数据进行筛选,将与发音问题相关的口型数据提取出来。筛选出的错误口型数据有助于更精确地定位与发音不合格相关的口型问题,为后续改进提供方向。
30、优选地,步骤s32中的摆放方位测算公式如下所示:
31、;
32、;
33、式中,为预摆放位置数据,为点读笔位置的横坐标,为设备距离参数,为设备摆放方位角,为点读笔位置的纵坐标,为反正切函数,为鼻尖位置的纵坐标,为鼻尖位置的横坐标,为预采集的人脸正面图像的脸长最值,为人脸图像的脸长最值,为预采集的人脸正面图像的脸宽最值,为人脸图像的脸宽最值,为设备摆放方位的偏移角度,为修正角度。
34、本发明构建了一种摆放方位测算公式,用于根据预采集的人脸正面图像数据与人脸图像数据进行设备摆放方位测算,生成预摆放位置数据。该公式充分考虑了点读笔位置的横坐标,设备距离参数,设备摆放方位角,点读笔位置的纵坐标,反正切函数,鼻尖位置的纵坐标,鼻尖位置的横坐标,预采集的人脸正面图像的脸长最值,人脸图像的脸长最值,预采集的人脸正面图像的脸宽最值,人脸图像的脸宽最值,设备摆放方位的偏移角度,修正角度以及变量间的相互作用关系,构成以下函数关系式:
35、;
36、;
37、通过和决定了预摆放位置数据中设备的相对参考点。通过确定参照点的坐标,可以明确设备的摆放位置,并影响最终预摆放位置的确定。通过表示设备和参考物品之间的距离。通过调整距离参数,可以控制设备与参考物品之间的距离远近。较大的距离参数将使设备距离参考物品更远,而较小的距离参数将使设备更靠近参考物品。是设备的摆放方位角。通过计算点读笔与人脸位置之间的角度差,结合偏移角度,可以确定设备摆放的朝向角度。通过调整该角度,可以改变设备的朝向,使其朝向目标物品的不同方向。和是人脸图像数据中鼻尖位置的坐标。通过将点读笔位置与人脸的位置坐标进行比较,可以计算出设备的摆放方位角。这些坐标的变化将直接影响的计算结果。通过的计算,可以在计算设备摆放方位角时考虑到人脸相对尺寸的变化,进一步精确确定设备的摆放方位。其中较大的差异值表示高度变化相对于宽度变化更显著,角度值将更大;相反,较小的差异值表示高度和宽度变化趋势相似,角度值将更接近于零。通过获取的人脸图像数据的人脸中线位置与实际中线位置进行比较,可以得到设备摆放方位的偏移角度,从而校正设备摆放方位的偏移,以适应不同时间位置的用户使用情况。该函数关系式可以准确评估出设备与人脸位置之间的偏差程度,从而计算得出合理的设备摆放方位,以获取清晰的人脸图像数据,为后续的口型采集分析提供基础。并利用为修正角度对函数关系式进行调整修正,减少数据偏差或误差带来的影响,例如可以考虑光线较差时,通过先知经验确定可能的摆放角度,从而对进行调整修正。从而更准确地生成设备摆放方位角,提高设备方位调整的准确性。同时公式中的各坐标值与修正值根据实际情况进行调整,应用于不同的使用者与使用环境,提高了算法的灵活性与适用性。
38、优选地,步骤s4包括以下步骤:
39、步骤s41:对错误口型数据进行唇部开合分析,生成唇部开合运动数据;基于唇部开合运动数据对错误口型数据进行开口时间图像截取,生成开口图像数据;
40、步骤s42:根据开口图像数据进行齿位开合分析,生成齿位开合运动数据;基于齿位开合运动数据对开口图像数据进行开齿时间图像截取,生成开齿图像数据;
41、步骤s43:对开齿图像数据进行降噪平滑处理,生成清晰开齿图像数据;根据清晰开齿图像数据进行舌尖位置标记,生成舌尖运动轨迹数据;
42、步骤s44:将唇部开合运动数据与齿位开合运动数据与舌尖运动轨迹数据进行时序关联,生成口型变化特征数据;
43、步骤s45:根据口型变化特征数据进行异常变化点标记,生成口型异常范围数据;
44、步骤s46:根据音素错误数据对口型异常范围数据进行异常时间点标记,生成综合口型异常数据。
45、本发明通过对口型数据进行唇部开合分析,提取唇部运动数据,有助于了解发音时唇部的运动情况。基于唇部开合运动数据,截取开口图像数据,用以记录唇部在发音过程中的开合情况。利用开口图像数据进行齿位开合分析,提取齿位开合运动数据,以了解发音时齿位的动态变化。基于齿位开合运动数据,截取开齿图像数据,记录发音过程中齿位的变化情况。对开齿图像数据进行降噪平滑处理,以减少图像中的噪音,提取清晰的开齿图像数据。基于清晰开齿图像数据,进行舌尖位置标记,提取舌尖运动轨迹数据,以记录舌尖在发音过程中的运动轨迹。将唇部开合运动数据、齿位开合运动数据和舌尖运动轨迹数据进行时序关联,整合形成口型变化特征数据。提供了更综合的口型特征,有助于全面理解口型变化。根据口型变化特征数据标记异常变化点,确定口型异常范围,可能涉及到异常的唇部、齿位或舌尖运动。确定口型异常的范围,使得后续的分析和改进可以更集中在特定的口型异常区间。根据音素错误数据对口型异常范围数据进行异常时间点标记,将口型异常与具体的音素错误相联系。将口型异常数据与发音错误关联,为改进提供更精准的口型与发音错误的关联性分析。
46、优选地,步骤s44包括以下步骤:
47、步骤s441:将唇部开合运动数据与齿位开合运动数据与舌尖运动轨迹数据进行时序关联,生成口型运动变化数据;
48、步骤s442:对口型运动变化数据进行轨迹图像转换,生成二维侧方运动图;
49、步骤s443:利用角度变化评估公式,并根据二维侧方运动图对舌尖运动轨迹数据进行运动倾向分析,生成运动方向特征数据;
50、步骤s444:利用运动方向特征数据对舌尖运动轨迹数据进行轨迹模糊估计,生成舌尖运动优化数据;
51、步骤s445:根据舌尖运动优化数据对二维侧方运动图进行运动补充,生成侧方运动优化图;
52、步骤s446:基于侧方运动优化图进行运动特征评估,生成口型变化特征数据。
53、本发明通过将唇部开合、齿位开合、舌尖运动数据进行时序关联,生成口型运动变化数据。整合了口型各部位的运动变化,提供了更全面的口型运动特征,有助于更深入理解口型变化。将口型运动变化数据转换成二维侧方运动图,以图像方式展示口腔器官运动变化的侧面视角。二维侧方运动图有助于直观地展示口型的运动情况,提供口型运动的可视化信息。利用角度变化评估公式对二维侧方运动图进行分析,评估舌尖运动轨迹的运动倾向。生成运动方向特征数据,标记舌尖运动的倾向性,可能是向上、向下或水平移动的趋势。基于运动方向特征数据进行轨迹模糊估计,优化舌尖运动轨迹数据。估计优化舌尖运动,提高口型运动数据的准确性和清晰度,以更精确地反映舌尖运动情况。基于舌尖运动优化数据对二维侧方运动图进行运动补充,生成优化的侧方口型运动图。优化的侧方运动图更清晰地展示口型运动,提供更直观的口型运动视觉信息。基于优化的侧方运动图进行口型运动特征评估,分析口型变化的特征和规律。为口语发音中口型变化的具体特征提供更详细的描述。
54、优选地,步骤s443中的角度变化评估公式如下所示:
55、;
56、式中,为角度平均变化值,为评估的开始时间,为评估的结束时间,为时间变化的索引值,为反余弦函数,为时间为时的舌尖位置横坐标,为时间为时的舌尖位置横坐标,为时间为时的舌尖位置纵坐标,为时间为时的舌尖位置纵坐标,为时间为时的舌尖位置横坐标,为时间为时的舌尖位置纵坐标,为角度偏差修正值。
57、本发明构建了一种角度变化评估公式,用于根据二维侧方运动图对舌尖运动轨迹数据进行运动倾向分析,生成运动方向特征数据。该公式充分考虑了评估的开始时间,评估的结束时间,时间变化的索引值,反余弦函数,时间为时的舌尖位置横坐标,时间为时的舌尖位置横坐标,时间为时的舌尖位置纵坐标,时间为时的舌尖位置纵坐标,时间为时的舌尖位置横坐标,时间为时的舌尖位置纵坐标,角度偏差修正值以及变量间的相互作用关系,构成以下函数关系式:
58、;
59、通过和,表示舌尖位置在时间点和处的横纵坐标。在公式中,它们构成了两个相邻时间点的向量,用于计算角度变化。在公式中被用来计算夹角的第三个点,帮助确定两个向量的方向。反余弦函数计算向量之间的夹角。这个函数将内积除以模的乘积,然后反向地得出两向量之间的夹角。它的作用是将向量的夹角转换为实际角度。通过求和符号,对指定时间范围内的夹角进行求和,从而计算该时间范围内的角度变化总和。用于将总和的夹角值归一化为时间范围内的平均值。这个平均值以代表角度的平均变化速率。该函数关系式可快速评估每一段发音过程中的舌尖变化位置与速度,从而预见口型闭合期间的舌尖运动状态,以提高后续发音错误位置评估的准确性。利用角度偏差修正值对函数关系式进行修正,减少了异常数据于误差数据带来的误差影响,从而更准确地生成角度平均变化值,提高了计算结果的准确性和可靠性。同时该公式中的修正值可以根据实际情况进行调整,应用于不同轨迹数据计算其运动倾向,提高了算法的灵活性与适用性。
60、优选地,步骤s5包括以下步骤:
61、步骤s51:基于综合口型异常数据进行口型示范纠错,生成纠错跟读数据;
62、步骤s52:对纠错跟读数据进行发音再评分,生成再评分数据;利用预设的分数阈值对再评分数据进行合格性评估,若再评分数据大于或等于预设的分数阈值,则进行纠错过程总结,生成纠错过程数据;
63、步骤s53:若再评分数据小于预设的分数阈值,则生成二次不合格数据,并根据二次不合格数据进行重复错误分析纠错,直至生成纠错过程数据;
64、步骤s54:根据纠错过程数据进行难点聚类划分,生成重难点发音数据;
65、步骤s55:根据重难点发音数据进行训练策略制定,生成训练策略数据;
66、步骤s56:根据训练策略数据进行发音训练,生成优化发音数据。
67、本发明通过综合口型异常数据,进行口型示范纠错,生成纠错跟读数据。纠错跟读数据提供了正确口型的示范,以帮助用户理解和模仿正确的口型。对纠错跟读数据进行发音再评分,生成再评分数据。利用预设的分数阈值进行合格性评估,若符合预设标准,则生成纠错过程数据,总结纠错过程。如果再评分数据低于预设的分数阈值,则生成二次不合格数据,进行迭代错误分析和纠错。迭代分析纠错过程,不断改进口语发音直到达到预设的合格性评估标准。基于纠错过程数据,对纠错过程中的难点进行聚类划分,区分出重点和难点发音数据。通过聚类,确定发音中特定的重难点,帮助更有针对性地进行后续训练。根据重难点发音数据,制定针对性的训练策略,包括特定的练习、技巧和方法。制定针对性的训练策略,使得训练更贴近个体的发音问题,提高训练效果。
68、优选地,步骤s54包括以下步骤:
69、步骤s541:对纠错过程数据进行相同错误词汇聚合,生成聚合词汇数据;
70、步骤s542:根据聚合词汇数据进行错误频率估计,生成纠错频率分布数据;
71、步骤s543:基于纠错频率分布数据进行音素错误频率估计,生成音素频率分布数据;
72、步骤s544:根据音素频率分布数据进行相同音素聚类划分,生成聚合音素数据;
73、步骤s545:对聚合音素数据进行音素位置再划分,生成重难点发音数据。
74、本发明通过将纠错过程数据中相同的错误词汇进行聚合,生成聚合词汇数据。将出现频率较高的相同错误词汇聚合在一起,有助于识别出常见的发音问题,集中处理。基于聚合词汇数据进行错误频率的估计,生成纠错频率分布数据。提供了发音错误的分布情况,有助于了解不同错误的发生频率及其严重程度。基于纠错频率分布数据进行音素错误频率的估计,生成音素频率分布数据。提供了特定音素错误的频率和分布情况,帮助识别出发音问题中特定音素的频繁出错情况。根据音素频率分布数据,将发音错误中相同音素的数据进行聚合划分,生成聚合音素数据。通过聚合音素数据,将发现频率高的相同音素进行聚类,以便更有效地识别出发音中的重点音素。基于聚合音素数据,对音素的位置进行再划分,区分出发音过程中的重难点发音数据。以更准确地确定在发音过程中哪些音素更容易出错或更难发音,以便进一步针对性地进行训练和改进。
75、本技术的有益效果在于,本发明通过对示范发音和用户跟读数据进行对比评分,生成跟读发音分数。这个步骤评估了用户的发音准确度和质量。提供了一个标准化的评分方式,帮助用户了解自己的发音水平。也为后续的错误分析提供了基础数据。通过设置预设的分数阈值,识别并筛选出发音不合格的数据。这些数据可能包含了发音准确度不高的部分。对发音不合格数据进行详细的分析,识别出其中的音素错误数据。这些错误数据标识出具体的发音问题,帮助精确定位错误。通过摄像头设备采集口型数据,用于分析用户的口型动作。基于发音不合格数据,筛选出口型错误的数据,这些数能包括了用户发音时口型动作不正确的部分。对错误口型数据进行变化特征分析,识别口型动作的变化特征。根据口型变化特征数据,标记出口型动作中的异常点,识别出口型异常数据。基于综合口型异常数据,进行口型示范纠错,指导用户正确的口型动作。根据纠错过程数据,识别出发音过程中的重难点,可能是口型动作中的特定部分。针对重难点发音数据进行训练,帮助用户改善发音,提高口型动作的正确性和准确性。因此,本发明的点读笔的语音识别方法通过细粒度分析以得到音素细节问题的同时,还对用户的跟读口型数据进行口型错误分析,从而综合评估用户的错误发音点,以提高纠错的准确性,改进用户发音习惯。
- 还没有人留言评论。精彩留言会获得点赞!