一种基于多目标对比学习的水声目标识别方法
本发明属于数字信号处理和海洋学的交叉领域,具体涉及一种基于多目标对比学习的水声目标识别方法。
背景技术:
1、声信号在水中的传播具有距离远、衰减小等特点,因此,水下目标识别最有效、运用最广泛的方式是使用声呐。但海洋环境错综复杂,且其中存在的干扰因素也随着人类社会的发展不断增多。由声呐兵进行人工进行监听分析,进而实现对目标的准确识别逐渐变得困难重重且成本高昂。
2、使用传统数学建模方法和人工构造特征向量的方法在特定环境和条件可以取得较好的目标识别效果,整体的计算复杂度也较低。但受训练数据分布和模型体量的限制,其总体方法泛化能力和可扩展性较低,应用价值有限。在传感器数量和数据总量爆炸式增长的当代,这些传统方法不足以在海量的数据中高效地学习到目标特征,因此难以得到在不同海洋环境下都能稳定运行的目标识别系统。
技术实现思路
1、本发明所要解决的技术问题是:提出了一种基于多目标对比学习的水声目标识别方法,通过用大量无标注数据训练mtc(multi target contrastive,端到端多目标学习)框架,使模型对样本数据具备了一定的表征能力,随后只需要再使用少量的有标注数据对模型进行微调,就能达到较好的识别效果,从而降低了数据标注的工作量,提升了模型的训练效率。
2、本发明为解决上述技术问题采用以下技术方案:
3、一种基于多目标对比学习的水声目标识别方法,包括如下步骤:
4、s1、通过分帧操作对水声目标辐射噪声原始数据进行预处理,将数据按照是否有标注分成有标注数据集和无标注数据集,并对无标注数据集和有标注数据集进行划分。
5、s2、分析预处理后的水声目标辐射噪声数据的频域特征和时序特征,分别构建对比学习代理任务。
6、s3、基于频域特征和时序特征的代理任务,分别构建频域信息自监督特征提取网络和时序信息自监督特征提取网络。
7、s4、使用适当的权重共同优化代理任务目标,将步骤s3的两个自监督特征提取网络进行融合,构建mtc框架,实现同时训练。
8、s5、使用预处理过的无标注数据集对mtc框架进行自监督预训练。
9、s6、将完成自监督预训练的mtc框架中的频域信息和时序信息的特征提取结果进行拼接,并添加一层全连接神经网络构建分类器。
10、s7、使用预处理过的有标注数据集对下游分类任务进行监督训练,获得mtc框架在下游任务中的分类准确率,基于该评估结果调整该框架的超参数。
11、s8、将待测样本输入到分类器中,得到预测类别标签,完成识别。
12、进一步的,步骤s1中,数据预处理包括以下内容:
13、对数据进行分帧操作:将数据按照原始采样率读取后,每一帧取设定时间的目标辐射噪声噪声数据,并在相邻帧之间设置一定量的重叠。
14、进一步的,步骤s1中,数据集划分包括以下内容:
15、本身含有标签信息的数据,在自监督训练过程中,需要在读取数据后丢弃标签信息。根据使用大量无标注数据和少量有标注数据训练模型的构想,将用于自监督学习的无标注数据集,分为无标注训练数据集ssl_train和无标注验证数据集ssl_valid;将用于下游任务监督学习的有标注数据集,分为有标注训练数据集sup_train和有标注验证数据集sup_valid。
16、进一步的,步骤s2中,构建对比学习代理任务包括以下内容:
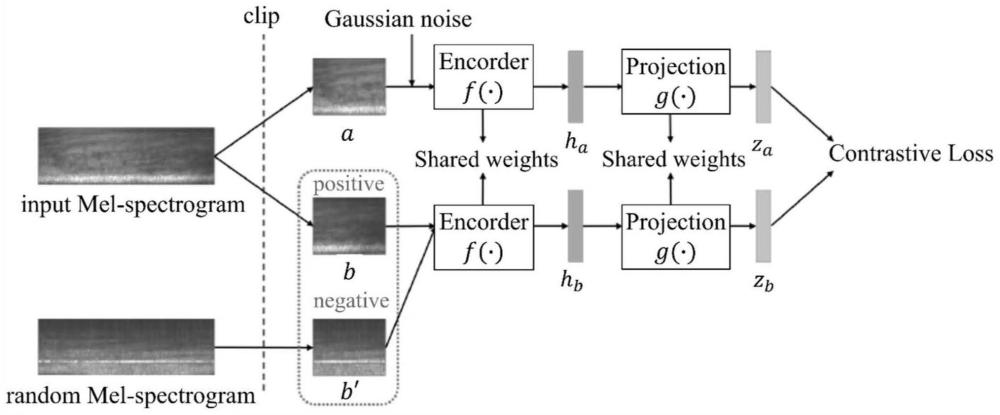
17、针对频域特征,有同类样本的频谱之间相似度明显大于不同类样本的频谱之间相似度的特征,利用这个性质,按照频谱相似度定义从同一个样本中切分的不同片段(clip)为正例,从不同样本中切分的不同片段clip为反例,构建的代理任务为最大化同样本clip之间的相似度以及最小化不同样本clip之间的相似度。
18、针对时序特征,根据水声目标辐射噪声在短时间内的稳态特征,将同一个样本的若干帧按时序排列为正例,将最后一帧或几帧更换为其他样本数据为反例,构建的代理任务为最大化正例的相似度以及最小化反例之间的相似度。
19、进一步的,步骤s3中,构建频域信息自监督特征提取网络,在形式上借鉴cola(contrastive learning of representations,通用音频对比)模型,包括以下子步骤:
20、(1)对输入的噪声数据进行在线裁剪,截取为原来长度1/2、1/4甚至更短的片段,并利用傅里叶变换和倒谱操作转换为梅尔频谱,经过对数运算得到log-mel(logarithmicmel spectrogram,对数梅尔)频谱。
21、构建输入层,使用数组接收输入的log-mel频谱。
22、(2)利用efficientnet-b0轻量化卷积神经网络架构构造编码器f(h),其中,该编码器包括输入层、第一卷积层、重复堆叠的mbconv(mobile inverted bottleneckconvolution,移动翻转瓶颈卷积)模块、第二卷积层、全局平均池化层和全连接层。
23、其中,卷积层包括批归一化层和switch函数。
24、(3)在编码器层中,对同一张输入频谱进行两次起始位置随机、长度相同的截取操作,得到两个维度相同的裁剪频谱,并对其中一个添加随机高斯噪声,作为正例样本对,将结果输入到编码器f(·),获得中间特征ha。
25、(4)在第一卷积层中,对输入频谱进行卷积操作,将多个卷积层堆叠,并对每个卷积层使用dsc(depthwise separable convolution,深度可分离卷积)技术,以减少计算量,对完成卷积操作的数据进行批归一化处理和激活函数处理。
26、(5)在重复堆叠的mbconv模块的第一部分,使用扩张比例为1的mbconv对第一卷积层输出的数据进行深度卷积,并进行压缩与激发操作。
27、(6)在重复堆叠的mbconv模块的第二部分,使用扩张比例更大的mbconv对数据进行逐点卷积,根据扩张比例将通道维度提升为原来的数倍,并进行批归一化和激活函数处理;进行深度卷积,并进行压缩与激活操作,使用1×1的逐点卷积恢复通道维度。
28、(7)在重复堆叠的mbconv模块的第三部分,使用扩张比例更大的、核步长为1的mbconv对数据进行逐点卷积,根据扩张比例将通道维度提升为原来的数倍,并进行批归一化和激活函数处理;进行深度卷积,并进行连接失活和跳跃连接操作,使用1×1的逐点卷积恢复通道维度。
29、(8)在重复堆叠的mbconv模块的第四部分,重复操作步骤(6)-(7)。
30、(9)在第二卷积层中,使用1×1的卷积核对输入进行卷积操作,将多个卷积层堆叠,并对每个卷积层使用深度可分离卷积技术,对完成卷积操作的数据进行批归一化处理和激活函数处理。
31、(10)在全局平均池化层中,通过对特征图进行全局平均池化操作,将特征图的高度和宽度降低到1,并将每个通道的特征进行平均。
32、(11)在全连接层中,将全局平均池化后的特征向量映射为中间特征ha。
33、(12)使用同样共享权重的单层全连接神经网络作为投影部g(·),利用线性变换处ha,得到最终的表征向量zt。
34、(13)构建输出层,输出表征向量的相似度矩阵,采用点积形式和温度系数计算正反例的表征向量的相似度,具体公式为:
35、
36、其中,s(x,y)表示相似度,x、y均表示特征向量,τ表示温度系数,∥∥表示取范数。
37、(14)使用多分类交叉熵作为损失函数,具体公式为:
38、
39、其中,p(x)表示真实值,即相似度标签;q(x)表示预测值,即输出端相似度,lspec表示频域信息的损失函数;χ表示一组样本。
40、(15)输入层、第一卷积层、重复堆叠的mbconv模块、第二卷积层、全局平均池化层和全连接层的编码器、投影部、输出层构成频域信息自监督特征提取网络。
41、进一步的,步骤s3中,构建时序信息自监督特征提取网络,在形式上借鉴了cpc(contrastive predictive coding,对比预测编码)模型,包括以下子步骤:
42、(1)构建输入层,接收输入的log-mel频谱。
43、(2)使用efficientnet-b0轻量化卷积神经网络构建共享权重的非线性编码器genc,该编码器的结构与编码器f(·)结构相同;将输入数据编码为表征向量zt=genc(x)。
44、(3)采用4个gru(gated recurrent units,门控循环单元)构造循环神经网络,对zt提取上下文信息ct;4个gru单元全部设置为开启输出的形式。
45、(4)将4个门控循环单元输出的ct进行拼接,作为输入片段的时序信息,基于正例的时序信息,通过一层并联的全连接神经网络对反例的表征向量zt进行预测,得到预测结果
46、(5)构建输出层,输出表征向量的相似度矩阵,采用点积形式和温度系数计算正反例的表征向量的相似度,具体公式为:
47、
48、(6)对和zt进行展平操作,使用多分类交叉熵作为损失函数,具体公式为:
49、
50、其中,ltemp表示时序信息的损失函数。
51、(7)输入层、非线性编码器、4个gru构成的循环神经网络、一层并联的全连接神经网络、输出层构成时序信息自监督特征提取网络。
52、进一步的,步骤s4中,构建端到端多目标学习框架包括以下子步骤:
53、s401、构建输入端,接收输入的log-mel频谱。
54、s402、构建并联特征提取模块,并联频域和时序信息自监督特征提取网络,对裁剪和转换后的输入噪声数据同时进行处理。
55、s403、在端到端多目标学习框架的输出端,采用带权重加和的形式将频域和时序两个信息自监督特征提取网络输出的损失函数合并成一个整体损失,且时序网络的loss的权重更高,具体公式为:
56、ltotal=ft·ltemp+lspec
57、其中,ft表示放缩因子,ft>1;ltotal表示整体损失。
58、s404、构建输出端,输出相似度,对频域和时序信息自监督特征提取网络的相似度进行调整,具体公式为:
59、
60、
61、其中,表示时序信息自监督特征提取网络的相似度,zb表示时序信息自监督特征提取网络中样本b的特征向量的真实值,表示时序信息自监督特征提取网络中样本b的特征向量的预测值,τ1表示时序信息自监督特征提取网络的温度系数,zbt表示zb的转置,sspec(zta,ztb)表示频域信息自监督特征提取网络的相似度,zta表示频域信息自监督特征提取网络中样本a的特征向量的真实值,ztb频域信息自监督特征提取网络中样本b的特征向量的真实值,τ2表示频域信息自监督特征提取网络的温度系数。
62、s405、完成两个自监督特征提取网络的融合,融合后的网络即为mtc框架,该框架包括输入端、并联特征提取模块、输出端。
63、进一步的,步骤s5中,进行自监督预训练包括以下子步骤:
64、s501、将ssl_train中的数据输入mtc框架的输入端,进行在线裁剪,并转换成log-mel频谱。
65、s502、将log-mel频谱输入到mtc框架的并联特征提取模块中,输出相似度。
66、s503、对于一批样本(batch)中的一个样本,设定其他样本均作为该样本的反例,提取ai和bi两张裁剪频谱作为一对正例,得到对应的表征向量和进而获得和之间的相似度sij组成相似度矩阵,sij作为第i行第j列元素;其中,i,j∈[1,n],n表示一批样本中样本的总数。
67、当i=j时,表明同一个裁剪频谱的计算结果,输出高相似度,其它位置均输出低相似度。保留数据经编码器处理后的表征向量,作为用于下游任务的特征向量。
68、s504、将log-mel频谱输入到mtc的时序信息自监督特征提取模块中,输出相似度。
69、s505、计算频域和时序信息自监督特征提取网络的整体损失并输出,用于表示模型在时序和频域上的综合表征能力,并结合对应输出的损失函数值来优化网络参数。
70、进一步的,步骤s6中,构建分类器,并用有标注数据集进行有监督训练,具体方法为:
71、选取时序信息自监督特征提取网络gru输出的上下文信息ct和频域信息自监督特征提取网络编码器输出的中间特征ha,作为模型对输入数据提取的时序和频域特征进行拼接,添加一层全连接神经网络进行特征投影,即使用一层全连接神经网络进行非线性变换,将原始特征映射到新的空间,以便完成后续分类任务。由此全连接神经网络加上softmax分类层,完成分类器的构建。
72、进一步的,步骤s7中,使用有标注数据集进行有监督训练,具体方法为:
73、s301、分类器对提取出的中间特征ha、上下文信息ct和最后的分类标签,即要完成区分的不同类别的标签,建立映射关系,完成分类任务。
74、s302、数据经过下游分类器处理,获得相应的softmax交叉熵损失函数输出,来度量模型的预测结果与真实标签之间的差异。
75、s303、接着通过反向传播算法,根据损失函数的梯度信息,更新模型的参数以最小化损失函数。
76、本发明采用以上技术方案,与现有技术相比,其显著技术效果如下:
77、1、本发明构建了一种端到端多目标对比学习框架,将频域和时序两个自监督特征提取网络在无标注数据上同时进行表征学习,随后在少量有标注的数据上进行有监督的模型微调,可以达到使用少量有标注数据就获得较高的目标识别准确率的目的,大大降低了模型训练对标注数据的依赖性,减低数据标注成本;节省了单独训练两个模型再进行融合的时间,也降低了模型融合的参数量和代码量。
78、2、本发明的使用无标注数据进行自监督训练模型,再使用少量有标注数据微调的策略,相对于使用同样数量标注数据的监督训练模型,可以提升模型性能、提高综合分类准确性、防止过拟合。
79、3、本发明的不同表征进行拼接,再用全连接层进行特征投影的方式,相比于频域和时序两个信息自监督特征提取网络单独使用,大部分情况下具有更好的下游任务性能。
80、4、本发明的将经过自监督训练提取到的水声目标用于下游分类任务的策略,相比于直接使用传统的人工构造特征log-mel频谱和mfcc(mel-scale frequency cepstralcoefficients,梅尔倒谱系数)特征,提高了分类准确率,当标注数据增多时能达到较高的准确率。
- 还没有人留言评论。精彩留言会获得点赞!