一种基于自适应多通道线性预测的低复杂度语音去混响方法
本发明属于语音去混响,更为具体地讲,涉及一种基于自适应多通道线性预测的低复杂度语音去混响方法。
背景技术:
1、室内混响是一种广泛存在的房间声学现象,它由声波在墙面、天花板和地板多径反射产生。在免提话音通信和人机交互等应用系统中,麦克风拾取的语音信号常受到室内混响的影响,严重降低语音的质量、清晰度和可懂度。因此,语音去混响在应用系统中具有重要的现实意义。
2、通常,由于说话人到麦克风传感器间的房间声脉冲响应的影响,麦克风拾取的语音信号由三部分组成:直达声、早期反射声和中晚期反射声。早期反射声使语音饱满圆润,然而构成混响成分的中晚期反射声通常会降低语音的质量和可懂度。语音去混响的目的是降低中晚期反射声的影响,由此恢复直达声和早期反射声以提高麦克风语音信号的质量、清晰度和可懂度。
3、针对语音去混响问题,研究人员已经开发了大量的去混响算法,比如基于多通道线性预测的方法、基于信道均衡的方法、基于波束形成的方法以及基于深度神经网络的方法。在这些方法中,基于多通道线性预测方法是最流行的技术之一,该方法首先利用阵列麦克风信号预测出这些信号中的混响成分,然后从麦克风信号中减去估计的混响成分,达到去混响目的。在实时应用中,通常以自适应方式估计出多通道线性预测滤波器,比如基于递归最小二乘准则的自适应多通道线性预测滤波器,然而,该方法具有较高的计算复杂度。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种基于自适应多通道线性预测的低复杂度语音去混响方法,以降低自适应多通道线性预测的计算复杂度。
2、为实现上述发明目的,本发明基于自适应多通道线性预测的低复杂度语音去混响方法,其特征在于,包括以下步骤:
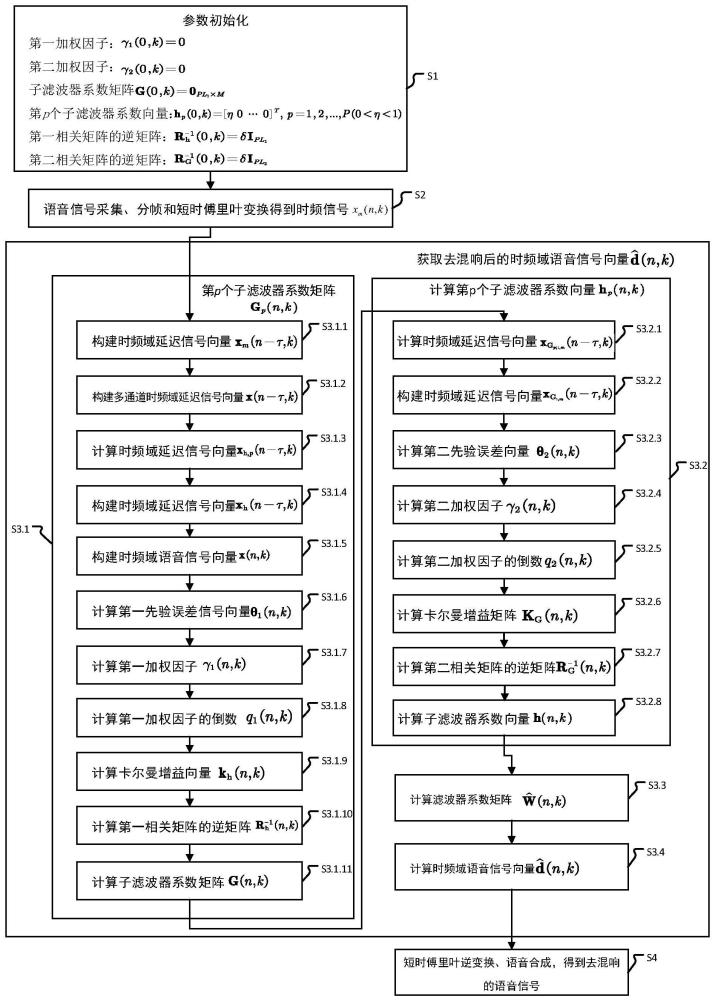
3、(1)、参数初始化
4、初始化信号第0帧时间第k个频率柜的以下参数:
5、第一加权因子γ1(0,k)=0,第二加权因子γ2(0,k)=0;
6、子滤波器系数矩阵
7、第p个子滤波器系数向量hp(0,k)=[η 0 … 0]t,p=1,2,...,p(0<η<1);
8、第一相关矩阵的逆矩阵
9、第二相关矩阵的逆矩阵
10、其中,p为调整参数,子滤波器系数矩阵由p个l1×m大小的子滤波器系数矩阵构成,m为麦克风的数量,子滤波器系数向量的长度为l2,l1×l2=mlg,lg为预测误差滤波器系数向量的长度,δ是正则化参数;
11、(2)、对m只麦克风获得的语音信号进行采集、分帧和短时傅里叶变换,得到时频信号xm(n,k),其中,m表示麦克风的编号,n和k分别表示信号帧时间和频率柜;
12、(3)、从第n=1帧时间开始,获取去混响后的时频域语音信号向量
13、3.1)、计算第n帧时间的第p个子滤波器系数矩阵gp(n,k)
14、3.1.1)、构建第m只麦克风的时频域延迟信号向量xm(n-τ,k):
15、xm(n-τ,k)=[xm(n-τ,k)xm(n-τ-1,k)…xm(n-τ-lg+1,k)]t
16、其中,参数τ是一个用于区分早期和中晚期反射声的延迟时间;
17、3.1.2)、构建多通道时频域延迟信号向量x(n-τ,k):
18、
19、3.1.3)、计算基于第p个子滤波系数向量hp(n-1,k)的时频域延迟信号向量xh,p(n-τ,k):
20、
21、3.1.4)、构建基于p个子滤波系数向量的时频域延迟信号向量xh(n-τ,k):
22、
23、3.1.5)、构建时频域语音信号向量x(n,k):
24、x(n,k)=[x1(n,k)x2(n,k)…xm(n,k)]t;
25、3.1.6)、根据构建的时频域延迟信号向量以及时频域信号向量,计算第n帧时间的第一先验误差信号向量θ1(n,k):
26、θ1(n,k)=x(n,k)-gh(n-1,k)xh(n-τ,k);
27、3.1.7)、计算第n帧时间的第一加权因子γ1(n,k):
28、
29、其中,α是一平滑因子,ε为防止分母为零的正常数;
30、3.1.8)、计算第n帧时间第一加权因子倒数q1(n,k):
31、
32、3.1.9)、计算第n帧时间的卡尔曼增益向量kh(n,k):
33、
34、其中,0<λ1<1是一个遗忘因子;
35、3.1.10)、计算第n帧时间的第一相关矩阵的逆矩阵
36、
37、3.1.11)、计算第n帧时间的子滤波器系数矩阵g(n,k):
38、
39、这样,得到第n帧时间的第p个子滤波器系数矩阵gp(n,k),p=1,2,...,p;
40、3.2)、计算第n帧时间的第p个子滤波器系数向量hp(n,k)
41、3.2.1)、计算基于子滤波向量gp;:,m(n-1,k)的时频域延迟信号向量
42、
43、其中,gp;:,m(n-1,k),m=1,2,...,m表示第p个子滤波器系数矩阵gp(n-1,k)的第m列;
44、3.2.2)、构建基于子滤波矩阵g:,m(n-1,k)的时频域延迟信号向量
45、
46、从而得到基于子滤波矩阵g(n-1,k)的多通道时频域延迟信号矩阵xg(n-τ,k):
47、
48、3.2.3)、计算第n帧时间的第二先验误差向量θ2(n,k):
49、
50、其中,(·)*表示复数取共轭;
51、3.2.4)、计算第n帧时间的第二加权因子γ2(n,k):
52、
53、其中,0<λ2<1是一个遗忘因子;
54、3.2.5)、计算第n帧时间第二加权因子倒数q2(n,k)
55、
56、3.2.6)、计算第n帧时间的卡尔曼增益矩阵kg(n,k):
57、
58、3.2.7)、计算第n帧时间的第二相关矩阵的逆矩阵
59、
60、3.2.8)、计算第n帧时间的子滤波器系数向量h(n,k):
61、
62、这样,得到第n帧时间的第p个子滤波器系数向量hp(n,k),p=1,2,...,p;
63、3.3)、计算第n帧时间的滤波器系数矩阵
64、
65、3.4)、计算第n帧时间的时频域语音信号向量
66、
67、(4)、对时频域语音信号向量中的每一路信号进行短时傅里叶逆变换,然后对得到的m路语音信号进行语音合成,得到去混响的语音信号。
68、本发明的发明目的是这样实现的:
69、本发明基于自适应多通道线性预测的低复杂度语音去混响方法为降低自适应多通道线性预测算法的计算复杂度,提出了一种基于最近克罗内克积分解的自适应算法。利用克罗内克积将线性预测滤波器的系数矩阵分解成一组低维滤波器系数矩阵和一组短的滤波器系数向量,由此建立误差信号模型、代价函数和自适应去混响算法,并求解出去混响的语音信号。仿真实验验证了发明方法的有效性和计算效率。
- 还没有人留言评论。精彩留言会获得点赞!