基于信息融合的识别处理方法、装置、设备及存储介质与流程
本技术实施例涉及信息融合的,尤其涉及一种基于信息融合的识别处理方法、装置、设备及存储介质。
背景技术:
1、随着网络科技的不断发展,观看视频数据时的字幕越来越成为必要。但是针对视频中说话人的角色与台词的匹配情况一般采用识别算法来匹配字母台词与角色名。
2、但是在目前的说话人识别项目中,算法识别的准确率有限,对于一些难例算法无法给出明确的识别结果。例如,有说话人声音,但是画面中的人脸是侧脸情况时,无法判断正在说话的人是那个角色,导致识别错误;在有人说话,但是属于画外音时,同样无法针对判断正在说话的是谁来识别角色;还有的画面中的人物嘴部有运动(例如吃饭、喝水等动作),但是此时说话的声音并不是画中角色,也会导致识别错误,对于用户的体验度大大下降。
3、诸如以上情况,算法都不能明确的给出识别结果,这就大大的影响了观看视频时的体验。
技术实现思路
1、鉴于此,为解决上述针对视频中说话人识别台词不准确的问题,本技术实施例提供一种基于信息融合的识别处理方法、装置、设备及存储介质。
2、第一方面,本技术实施例提供一种基于信息融合的识别处理方法,包括:
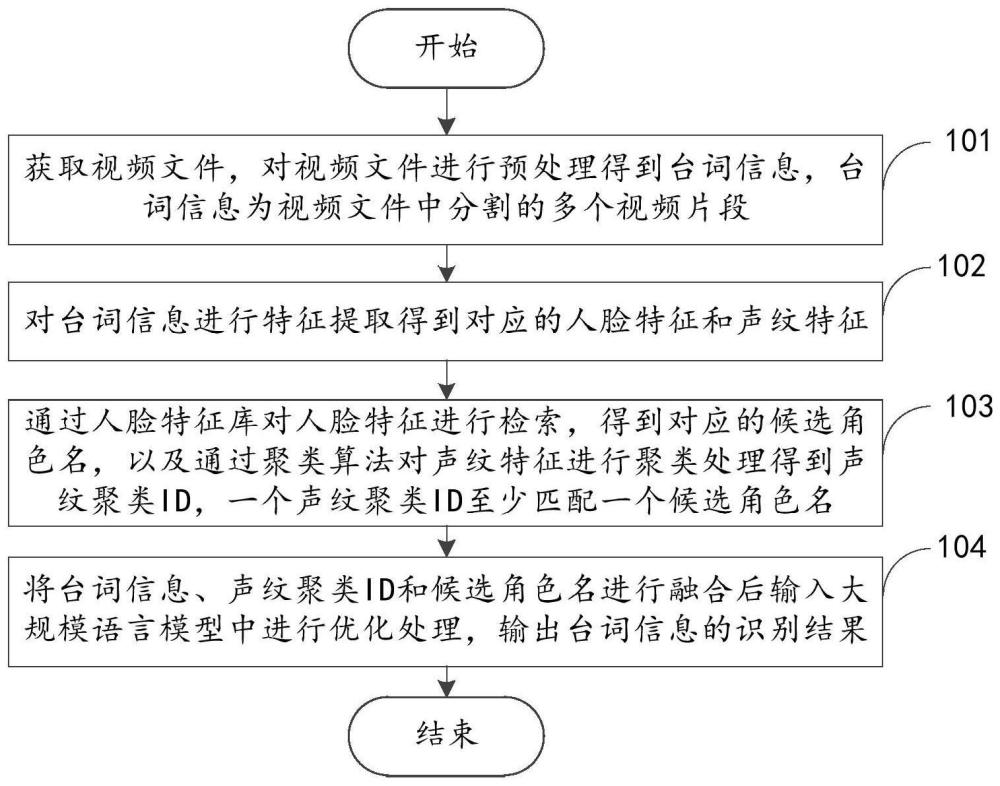
3、获取视频文件,对所述视频文件进行预处理得到台词信息,所述台词信息为所述视频文件中分割的多个视频片段;
4、对所述台词信息进行特征提取得到对应的人脸特征和声纹特征;
5、通过人脸特征库对所述人脸特征进行抽取,得到对应的候选角色名,以及通过聚类算法对所述声纹特征进行聚类处理得到声纹聚类id,一个所述声纹聚类id至少匹配一个所述候选角色名;
6、将所述台词信息、所述声纹聚类id和所述候选角色名进行融合后输入大规模语言模型中进行优化处理,输出所述台词信息的识别结果。
7、在一个可能的实施方式中,所述对所述视频文件进行预处理得到台词信息,包括:
8、利用镜头检测算法对所述视频文件进行镜头分割,得到多个镜头信息;
9、利用所述镜头检测算法对每个所述镜头信息进行台词检测处理,得到对应每个所述镜头信息的台词信息。
10、在一个可能的实施方式中,所述对所述台词信息进行特征提取得到对应的人脸特征和声纹特征,包括:
11、对所述台词信息对应的视频数据进行抽帧处理,得到对应的人脸数据和音频数据;
12、利用人脸检测算法获取所述台词信息对应的人脸数据的人脸检测框;
13、利用卷积神经网络对所述人脸检测框进行人脸特征提取,得到对应所述台词信息的人脸特征;
14、利用卷积神经网络对所述音频数据进行声纹特征提取,得到对应所述台词信息的声纹特征。
15、在一个可能的实施方式中,在所述对所述台词信息进行特征提取得到对应的人脸特征和声纹特征之后,所述方法,还包括:
16、利用交叉注意力算法对所述人脸特征进行特征增强,得到对应的人脸增强特征;
17、利用交叉注意力算法对所述声纹特征进行特征增强,得到对应的声纹增强特征。
18、在一个可能的实施方式中,所述通过人脸特征库对所述人脸特征进行检索,得到对应的候选角色名,包括:
19、在人脸特征库中检索所述人脸特征,得到对应的人脸检索结果;
20、当检索到所述人脸特征时,确定所述人脸检索结果为人脸匹配结果;
21、基于所述人脸匹配结果得到对应人脸特征的候选角色名,一个所述人脸特征至少对应一个候选角色名。
22、在一个可能的实施方式中,所述通过聚类算法对所述声纹特征进行聚类处理得到声纹聚类id,包括:
23、通过聚类算法对所述台词信息对应的所述声纹特征进行聚类处理,得到所述台词信息对应的多个声纹聚类名;
24、对每个所述声纹聚类名匹配对应的声纹聚类id。
25、在一个可能的实施方式中,所述将所述台词信息、所述声纹聚类id和所述候选角色名进行融合后输入大规模语言模型中进行优化处理,输出所述台词信息的识别结果,包括:
26、将同一镜头下的所述台词信息、所述声纹聚类id和所述候选角色名进行融合,并将融合后的信息输入预先训练好的大规模语言模型中进行角色匹配处理,输出每句台词的匹配信息,所述匹配信息为每句台词对应的声纹聚类id和候选角色名列表;
27、将包含台词对应多个候选角色名的匹配信息重新输入到所述大规模语言模型中,对所述匹配信息中的候选角色名进行重新匹配,输出所述台词信息的识别结果。
28、在一个可能的实施方式中,所述对台词与候选角色名进行重新匹配,输出所述台词信息的识别结果,包括:
29、通过说话人识别算法对大规模语言模型进行微调提问处理,重新匹配台词与候选角色名,得到对应的匹配结果;
30、将所述匹配结果作为所述台词信息的识别结果;
31、或,
32、利用同一个提问指令对同一个镜头下的所述台词信息进行多次提问处理,得到对应多个提问结果;
33、对全部提问结果进行投票融合处理,得到对应的投票结果;
34、将所述投票结果作为所述台词信息的识别结果。
35、第二方面,本技术实施例提供一种基于信息融合的识别处理装置,应用于第一方面中任一所述的基于信息融合的识别处理方法,包括:
36、预处理模块,用于获取视频文件,对所述视频文件进行预处理得到台词信息,所述台词信息为所述视频文件中分割的多个视频片段;
37、特征提取模块,用于对所述台词信息进行特征提取得到对应的人脸特征和声纹特征;
38、聚类处理模块,用于通过人脸特征库对所述人脸特征进行检索,得到对应的候选角色名,以及通过聚类算法对所述声纹特征进行聚类处理得到声纹聚类id,一个所述声纹聚类id至少匹配一个所述候选角色名;
39、融合识别模块,用于将所述台词信息、所述声纹聚类id和所述候选角色名进行融合后输入大规模语言模型中进行优化处理,输出所述台词信息的识别结果。
40、第三方面,本技术实施例提供一种电子设备,包括:处理器和存储器,所述处理器用于执行所述存储器中存储的基于信息融合的识别处理程序,以实现第一方面中任一所述的基于信息融合的识别处理方法。
41、第四方面,本技术实施例提供一种存储介质,所述存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现第一方面中任一所述的基于信息融合的识别处理方法。
42、本技术实施例提供的基于信息融合的识别处理方案,通过获取视频文件,对所述视频文件进行预处理得到台词信息,所述台词信息为所述视频文件中分割的多个视频片段;对所述台词信息进行特征提取得到对应的人脸特征和声纹特征;通过人脸特征库对所述人脸特征进行检索,得到对应的候选角色名,以及通过聚类算法对所述声纹特征进行聚类处理得到声纹聚类id,一个所述声纹聚类id至少匹配一个所述候选角色名;将所述台词信息、所述声纹聚类id和所述候选角色名进行融合后输入大规模语言模型中进行优化处理,输出所述台词信息的识别结果。通过对视频片段提取人脸特征和声纹特征两方面数据,再经过处理后得到对应的候选角色名和声纹聚类id,再将得到的台词信息、声纹聚类id和候选角色名进行融合处理,在将融合后的数据作为输入数据输入到大规模语言模型中,通过对每句台词与候选角色名进行匹配得到每句台词对应声纹聚类id和候选角色名之间的关系,针对一句台词对应多个候选角色名的情况,将匹配失败的台词信息、声纹聚类id和候选角色名重新融合后输入大规模语言模型中重新匹配,通过微调提问的方式,结合台词上下关联关系,匹配对应的角色名,将匹配成功后的数据作为识别结果输出,进而实现对台词与角色名识别不准确的情况进行后处理,对算法识别精度较低的结果进行角色重定位。由本方案,可以实现提高说话人识别算法的识别精度,达到提高匹配精度的技术效果。
- 还没有人留言评论。精彩留言会获得点赞!