基于语义分析的会议记录生成方法及其装置、电子设备与流程
本发明涉及人工智能领域,具体而言,涉及一种基于语义分析的会议记录生成方法及其装置、电子设备。
背景技术:
1、记录会议纪要是日常会议不可或缺的步骤,准确完整的会议纪要,对准确传达会议内容十分重要。但是,当前大多数会议仍然依靠人工记录会议内容,形成会议纪要,该方式可能会存在漏记、错记的情况,若使用会议录音,靠人工把语音转成文字,人工成本高,且效率慢。因此,开发一个结合语音识别和声纹识别的系统,实现自动把语音数据转化为文字记录,并准确标记说话人,具有重要意义。
2、相关技术中,提出了一种会议纪要的生成方法,通过发言终端获取发言人的语音数据,并将该语音数据发送给服务器,然后服务器通过发言终端获取发言人的语音数据,并将语音数据转换成文本,之后服务器按照预设的会议纪要格式,将发言人的标识、语音数据以及文本进行关联,生成会议纪要,最后服务器将会议纪要发送给发言终端。然而,现实开会中,发言人的语音可能会受到环境影响发生改变,如掌声、其他说话声等,从而影响声纹识别准确率,因此,上述方案通过声纹比对完成发言人的身份认证的准确率较低,容易导致说话人标记错误。
3、相关技术中,还可以通过结合人脸、语音识别或者声纹识别的方式,生成会议记录。然而,人脸加语音识别的方式,要额外安装摄像头进行人脸识别,成本较高,而声纹加语音识别的方式,声纹识别的准确率容易受到环境背景音的影响,导致说话人标记错误。
4、针对上述的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本发明实施例提供了一种基于语义分析的会议记录生成方法及其装置、电子设备,以至少解决相关技术中对声纹识别的准确率较低,导致生成的会议记录中容易对说话人标记错误的技术问题。
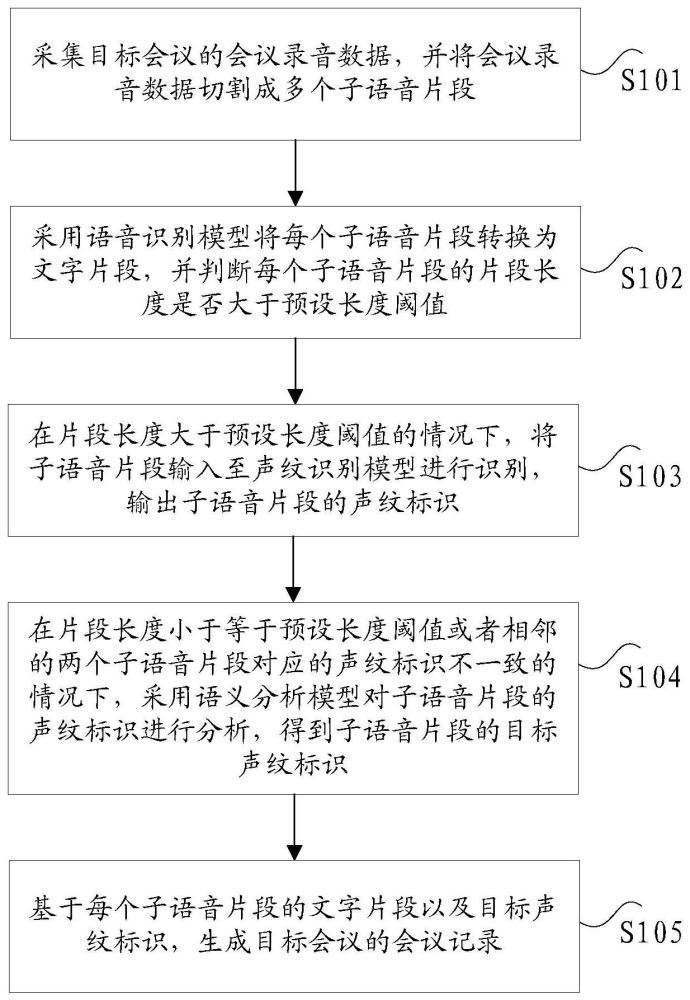
2、根据本发明实施例的一个方面,提供了一种基于语义分析的会议记录生成方法,包括:采集目标会议的会议录音数据,并将所述会议录音数据切割成多个子语音片段;采用语音识别模型将每个所述子语音片段转换为文字片段,并判断每个所述子语音片段的片段长度是否大于预设长度阈值;在所述片段长度大于所述预设长度阈值的情况下,将所述子语音片段输入至声纹识别模型进行识别,输出所述子语音片段的声纹标识;在所述片段长度小于等于所述预设长度阈值或者相邻的两个所述子语音片段对应的所述声纹标识不一致的情况下,采用语义分析模型对所述子语音片段的所述声纹标识进行分析,得到所述子语音片段的目标声纹标识;基于每个所述子语音片段的所述文字片段以及所述目标声纹标识,生成所述目标会议的会议记录。
3、进一步地,在将所述会议录音数据切割成多个子语音片段之前,还包括:确定所述会议录音数据中的静音数据,并将所述静音数据进行清除;对已清除所述静音数据的所述会议录音数据进行降噪处理。
4、进一步地,所述语音识别模型包括:声学模型、语言模型,采用语音识别模型将每个所述子语音片段转换为文字片段的步骤,包括:提取每个所述子语音片段的特征,得到特征向量;采用所述声学模型对所述特征向量进行处理,得到所述子语音片段的音素信息,其中,所述音素信息包括:多个音素;基于预设字典确定每个所述音素对应的目标字词,其中,所述预设字典用于记录音素与字词之间的对应关系;采用所述语言模型对每个所述目标字词进行分析,得到每个所述目标字词的关联字词集合,其中,所述关联字词集合包括:多个关联字词,每个所述关联字词对应有关联概率;对于每个所述目标字词,将最大关联概率指示的所述关联字词与所述目标字词进行关联,并基于所有关联后的所述目标字词,生成所述子语音片段的目标字词序列;基于所述目标字词序列,生成所述子语音片段的所述文字片段。
5、进一步地,将所述子语音片段输入至声纹识别模型进行识别,输出所述子语音片段的声纹标识的步骤,包括:从预设声纹库中提取所述目标会议的参会人员的声纹特征,构建参会声纹库,其中,所述预设声纹包括:注册人员的所述声纹特征;对所述子语音片段进行预处理,得到多维向量,并对所述多维向量进行卷积处理,得到特征向量;将所述特征向量与所述参会声纹库的每个所述声纹特征进行匹配,得到目标声纹特征,其中,所述目标声纹特征是最大匹配度指示的所述声纹特征,每个所述声纹特征关联有所述声纹标识;在所述最大匹配度大于预设匹配度阈值的情况下,将所述目标声纹特征关联的所述声纹标识作为所述子语音片段的所述声纹标识。
6、进一步地,在将所述特征向量与所述参会声纹库的每个所述声纹特征进行匹配,得到目标声纹特征之后,还包括:在所述最大匹配度小于等于所述预设匹配度阈值的情况下,将所述特征向量作为匿名人员的所述声纹特征注册至所述预设声纹库以及所述参会声纹库;将匿名声纹标识与所述匿名人员的所述声纹特征进行关联;将所述匿名声纹标识作为所述子语音片段的所述声纹标识。
7、进一步地,采用语义分析模型对所述子语音片段的所述声纹标识进行分析,得到所述子语音片段的目标声纹标识的步骤,包括:在所述片段长度小于等于所述预设长度阈值的情况下,确定所述片段长度指示的当前子语音片段的当前文字片段以及前一个子语音片段的前一个文字片段;将所述当前文字片段的前n个字和所述前一个文字片段的后n个字进行拼接,得到预设文字片段,其中,n为正整数;将所述预设文字片段与预设语料库中的语料片段进行匹配,其中,所述预设语料库包括:多个所述语料片段,所述语料片段是预先构建的文字片段;在所述预设文字片段与任一所述语料片段匹配成功的情况下,确定所述当前子语音片段与所述前一个文字片段属于同一个所述声纹标识,或者,在所述预设文字片段与所有所述语料片段都匹配失败的情况下,确定所述当前子语音片段与下一个文字片段属于同一个所述声纹标识。
8、进一步地,相邻的两个所述子语音片段包括:第一个子语音片段与第二个子语音片段,采用语义分析模型对所述子语音片段的所述声纹标识进行分析,得到所述子语音片段的目标声纹标识的步骤,还包括:在相邻的两个所述子语音片段对应的所述声纹标识不一致的情况下,确定所述第一个子语音片段的第一个文字片段以及所述第二个子语音片段的第二个文字片段;将所述第一个文字片段的前n个字和所述第二个文字片段的后n个字进行拼接,得到预设文字片段;将所述预设文字片段与预设语料库中的语料片段进行匹配;在所述预设文字片段与任一所述语料片段匹配成功的情况下,重新确定所述第一个子语音片段和所述第二个子语音片段的所述声纹标识。
9、根据本发明实施例的另一方面,还提供了一种基于语义分析的会议记录生成装置,包括:切割单元,用于采集目标会议的会议录音数据,并将所述会议录音数据切割成多个子语音片段;转换单元,用于采用语音识别模型将每个所述子语音片段转换为文字片段,并判断每个所述子语音片段的片段长度是否大于预设长度阈值;输入单元,用于在所述片段长度大于所述预设长度阈值的情况下,将所述子语音片段输入至声纹识别模型进行识别,输出所述子语音片段的声纹标识;分析单元,用于在所述片段长度小于等于所述预设长度阈值或者相邻的两个所述子语音片段对应的所述声纹标识不一致的情况下,采用语义分析模型对所述子语音片段的所述声纹标识进行分析,得到所述子语音片段的目标声纹标识;生成单元,用于基于每个所述子语音片段的所述文字片段以及所述目标声纹标识,生成所述目标会议的会议记录。
10、进一步地,所述生成装置还包括:第一确定模块,用于在将所述会议录音数据切割成多个子语音片段之前,确定所述会议录音数据中的静音数据,并将所述静音数据进行清除;第一降噪模块,用于对已清除所述静音数据的所述会议录音数据进行降噪处理。
11、进一步地,所述语音识别模型包括:声学模型、语言模型,所述转换单元包括:第一提取模块,用于提取每个所述子语音片段的特征,得到特征向量;第一处理模块,用于采用所述声学模型对所述特征向量进行处理,得到所述子语音片段的音素信息,其中,所述音素信息包括:多个音素;第二确定模块,用于基于预设字典确定每个所述音素对应的目标字词,其中,所述预设字典用于记录音素与字词之间的对应关系;第一分析模块,用于采用所述语言模型对每个所述目标字词进行分析,得到每个所述目标字词的关联字词集合,其中,所述关联字词集合包括:多个关联字词,每个所述关联字词对应有关联概率;第一关联模块,用于对于每个所述目标字词,将最大关联概率指示的所述关联字词与所述目标字词进行关联,并基于所有关联后的所述目标字词,生成所述子语音片段的目标字词序列;第一生成模块,用于基于所述目标字词序列,生成所述子语音片段的所述文字片段。
12、进一步地,所述输入单元包括:第二提取模块,用于从预设声纹库中提取所述目标会议的参会人员的声纹特征,构建参会声纹库,其中,所述预设声纹包括:注册人员的所述声纹特征;第二处理模块,用于对所述子语音片段进行预处理,得到多维向量,并对所述多维向量进行卷积处理,得到特征向量;第一匹配模块,用于将所述特征向量与所述参会声纹库的每个所述声纹特征进行匹配,得到目标声纹特征,其中,所述目标声纹特征是最大匹配度指示的所述声纹特征,每个所述声纹特征关联有所述声纹标识;第一作为模块,用于在所述最大匹配度大于预设匹配度阈值的情况下,将所述目标声纹特征关联的所述声纹标识作为所述子语音片段的所述声纹标识。
13、进一步地,所述生成装置还包括:第一注册模块,用于在将所述特征向量与所述参会声纹库的每个所述声纹特征进行匹配,得到目标声纹特征之后,在所述最大匹配度小于等于所述预设匹配度阈值的情况下,将所述特征向量作为匿名人员的所述声纹特征注册至所述预设声纹库以及所述参会声纹库;第二关联模块,用于将匿名声纹标识与所述匿名人员的所述声纹特征进行关联;第二作为模块,用于将所述匿名声纹标识作为所述子语音片段的所述声纹标识。
14、进一步地,所述分析单元包括:第三确定模块,用于在所述片段长度小于等于所述预设长度阈值的情况下,确定所述片段长度指示的当前子语音片段的当前文字片段以及前一个子语音片段的前一个文字片段;第一拼接模块,用于将所述当前文字片段的前n个字和所述前一个文字片段的后n个字进行拼接,得到预设文字片段,其中,n为正整数;第二匹配模块,用于将所述预设文字片段与预设语料库中的语料片段进行匹配,其中,所述预设语料库包括:多个所述语料片段,所述语料片段是预先构建的文字片段;第四确定模块,用于在所述预设文字片段与任一所述语料片段匹配成功的情况下,确定所述当前子语音片段与所述前一个文字片段属于同一个所述声纹标识,或者,在所述预设文字片段与所有所述语料片段都匹配失败的情况下,确定所述当前子语音片段与下一个文字片段属于同一个所述声纹标识。
15、进一步地,相邻的两个所述子语音片段包括:第一个子语音片段与第二个子语音片段,所述分析单元还包括:第五确定模块,用于在相邻的两个所述子语音片段对应的所述声纹标识不一致的情况下,确定所述第一个子语音片段的第一个文字片段以及所述第二个子语音片段的第二个文字片段;第二拼接模块,用于将所述第一个文字片段的前n个字和所述第二个文字片段的后n个字进行拼接,得到预设文字片段;第三匹配模块,用于将所述预设文字片段与预设语料库中的语料片段进行匹配;第六确定模块,用于在所述预设文字片段与任一所述语料片段匹配成功的情况下,重新确定所述第一个子语音片段和所述第二个子语音片段的所述声纹标识。
16、根据本发明实施例的另一方面,还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行上述任意一项基于语义分析的会议记录生成方法。
17、根据本发明实施例的另一方面,还提供了一种电子设备,包括一个或多个处理器和存储器,所述存储器用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现上述任意一项基于语义分析的会议记录生成方法。
18、在本发明中,采集目标会议的会议录音数据,并将会议录音数据切割成多个子语音片段,采用语音识别模型将每个子语音片段转换为文字片段,并判断每个子语音片段的片段长度是否大于预设长度阈值,在片段长度大于预设长度阈值的情况下,将子语音片段输入至声纹识别模型进行识别,输出子语音片段的声纹标识,在片段长度小于等于预设长度阈值或者相邻的两个子语音片段对应的声纹标识不一致的情况下,采用语义分析模型对子语音片段的声纹标识进行分析,得到子语音片段的目标声纹标识,基于每个子语音片段的文字片段以及目标声纹标识,生成目标会议的会议记录。
19、在本发明中,可以先将会议录音数据切割成多个子语音片段,然后采用语音识别模型将每个子语音片段转换为文字片段,并采用声纹识别模型识别片段长度大于预设长度阈值的子语音片段,得到该子语音片段的声纹标识,之后可以采用语义分析模型分析片段长度小于等于预设长度阈值的子语音片段以及识别出的声纹标识不一致的相邻的两个子语音片段,能够得到更加准确的目标声纹标识,以生成更加准确的会议记录,如此,通过语义分析能够对声纹识别结果进行校验,有效提高了声纹识别的准确率,提高了会议记录的完整性以及准确性,进而解决了相关技术中对声纹识别的准确率较低,导致生成的会议记录中容易对说话人标记错误的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!