基于离散Diffusion的语音合成方法及系统与流程
本发明涉及语音合成领域,特别公开了一种基于离散diffusion的语音合成方法及系统。
背景技术:
1、基于离散编码的零样本语音合成模型主要分为自回归模型和非自回归模型两种。其中自回归模型通常使用一个语言模型来建模音频的离散编码,在生成语音的过程中,在每个时间步下音频编码的预测依赖于之前时间步的信息。而针对离散非自回归模型来说,则以离散diffusion的建模方式为主,这种方式分为前向过程和反向过程,其中前向过程通过逐步掩码离散编码为噪声,并预测被掩码的噪声进行建模,而在反向过程一般按照以下几种形式选取被恢复的音频编码,分别是随机选取若干个位置,按照概率进行采样,或者根据熵的大小选取若干个位置,从而逐步从噪声中恢复音频离散编码来获取待合成语音。
2、目前,基于离散diffusion方法的语音合成模型,其在反向过程中恢复音频编码中,通常采用随机选取,概率采样或者根据熵的大小来选取恢复位置,但是根据这些方式推理容易出现以下两种问题:第一是过度依赖上一步音频编码的恢复结果,而不是声学提示对应的音频以及待合成文本信息;第二是存在同时推出相邻位置,产生局部冲突的可能。
3、举个例子,假设在训练集中不存在相邻位置同为离散编码a的数据,但是如果采用上述方式进行推理,可能存在在相邻位置同时推出相同的离散编码a,从而产生局部冲突。因此根据上述推理流程,会使得模型容易出现吞字和漏字的现象。
技术实现思路
1、本发明提供了一种基于离散diffusion的语音合成方法,能至少部分的改善上述问题。
2、为实现上述目的,本发明采用以下技术方案:
3、一种基于离散diffusion的语音合成方法,其包括:
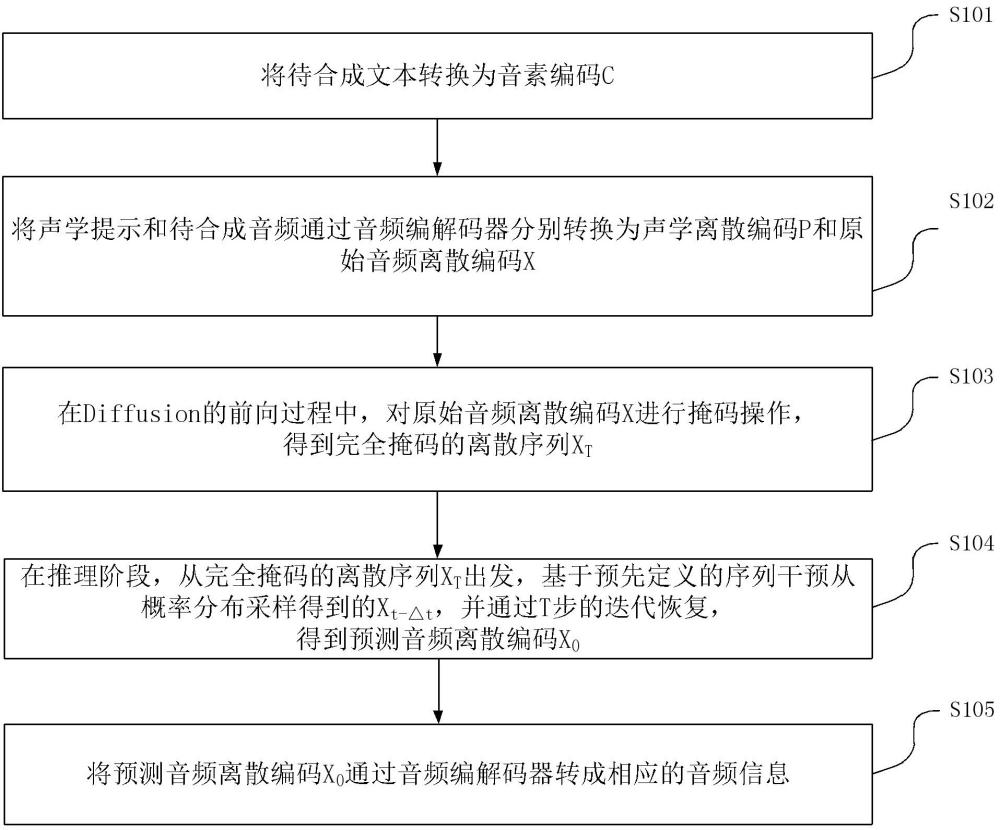
4、s101,将待合成文本转换为音素编码c;
5、s102,将声学提示和待合成音频通过音频编解码器分别转换为声学离散编码p和原始音频离散编码x;
6、s103,在diffusion的前向过程中,对原始音频离散编码x进行掩码操作,得到完全掩码的离散序列xt;
7、s104,在推理阶段,从完全掩码的离散序列xt出发,基于预先定义的序列s干预从概率分布采样得到的,并通过t步的迭代恢复,得到预测音频离散编码x0;其中,t表示时间步的总数,表示步长,序列s为偶数长度的序列,序列s中的元素决定了在第步所恢复的音频离散编码的位置,且序列s中的元素满足相对于已经选择的其他位置距离最远;分别表示第t步和第步的音频离散编码;从diffusion网络输出的概率分布中采样得到,为diffusion网络的参数;
8、s105,将预测音频离散编码x0通过音频编解码器转成相应的音频信息。
9、优选地,步骤s101具体包括:
10、将待合成文本通过g2p模型转为音素,并通过映射字典将所述音素转换为音素编码;表示音素编码的长度。
11、优选地,步骤s103具体包括:
12、在diffusion的前向过程的时间步t中,定义一个二进制掩码矩阵对原始音频离散编码x进行掩码,得到完全掩码的离散序列xt;其中,对于完全掩码的离散序列xt中的第m个编码,满足;表示在掩码过程,将原始音频离散编码x中对应为1的部分代替为一个特殊字符[mask],而为0的部分仍然保持原始的编码,,为一个固定的值,n为原始音频离散编码x的维度,t表示第t个时间步。
13、优选地,还包括:
14、在diffusion的反向过程中,从完全掩码的离散序列xt出发,逐步根据反向分布进行采样来逐步恢复得到预测音频离散编码;其中,在训练阶段,根据声学提示的声学离散编码p和所述音素编码c来预测音频离散编码的信息;在预测时,使用所述diffusion网络来预测在每一步中被掩码的音频编码信息。
15、优选地,通过最小化被掩码音频编码的负对数似数来训练所述diffusion网络:
16、
17、其中,为损失函数,n为原始音频离散编码的维度,为生成的第i个离散音频编码;
18、基于所述diffusion网络,根据得到所预测的预测音频离散编码;
19、从进行采样得到,并将和作为条件得到:
20、,
21、e表示期望,et表示第t步的期望。
22、优选地,s104具体包括:
23、根据序列s得到掩码矩阵,其中:
24、
25、
26、a为根据待合成音频的序列长度生成的递增序列,且待合成音频的序列长度等于原始音频离散编码的维度,为掩码矩阵的元素,r表示序列s中的推理位置,%表示取余操作,n为序列s的长度;掩码矩阵中每行关于推理位置r相关的元素为1,其他元素为0;
27、在得到后,根据、和来决定第步的推理位置,即:
28、;
29、通过t步的迭代恢复,得到预测音频离散编码x0。
30、本发明实施例还提供了一种基于离散diffusion的语音合成系统,其包括:
31、文本转换单元,用于将待合成文本转换为音素编码c;
32、编码单元,用于将声学提示和待合成音频通过音频编解码器分别转换为声学离散编码p和原始音频离散编码x;
33、掩码单元,用于在diffusion的前向过程中,对原始音频离散编码x进行掩码操作,得到完全掩码的离散序列xt;
34、推理单元,用于在推理阶段,从完全掩码的离散序列xt出发,基于预先定义的序列干预从概率分布采样得到的,并通过t步的迭代恢复,得到预测音频离散编码x0;其中,t表示时间步的总数,表示步长,序列s为偶数长度的序列,序列s中的元素决定了在第步所恢复的音频离散编码的位置,且序列s中的元素满足相对于已经选择的其他位置距离最远;分别表示第t步和第步的音频离散编码;从diffusion网络输出的概率分布中采样得到,为diffusion网络的参数;
35、音频合成单元,用于将预测音频离散编码x0通过音频编解码器转成相应的音频信息。
36、优选地,掩码单元具体用于:
37、在diffusion的前向过程的时间步t中,定义一个二进制掩码矩阵对原始音频离散编码x进行掩码,得到完全掩码的离散序列xt;其中,对于完全掩码的离散序列xt中的第m个编码,满足;表示在掩码过程,将原始音频离散编码x中对应为1的部分代替为一个特殊字符[mask],而为0的部分仍然保持原始的编码,,为一个固定的值,n为原始音频离散编码x的维度,t表示第t个时间步。
38、优选地,推理单元具体用于:
39、根据序列s得到掩码矩阵,其中:
40、
41、
42、a为根据待合成音频的序列长度生成的递增序列,且待合成音频的序列长度等于原始音频离散编码的维度,为掩码矩阵的元素,r表示序列s中的推理位置,%表示取余操作,n为序列s的长度;掩码矩阵中每行关于推理位置r相关的元素为1,其他元素为0;
43、在得到后,根据、和来决定第步的推理位置,即:
44、;
45、通过t步的迭代恢复,得到预测音频离散编码x0。
46、综上所述,本实施例通过设定一个序列s来干预所恢复音频离散编码的顺序,使模型更依赖于声学提示对应的音频和待合成文本,而不是上一步所恢复的音频编码,并解决推理中出现的局部冲突问题。
47、具体来说,本实施例根据上一步所恢复的音频编码的位置,选择相对最远的音频编码位置进行恢复,从而降低对上一步所恢复的音频编码的依赖,并不会出现局部冲突问题。本实施例可以有效缓解合成语音中的吞字漏字问题,提高模型的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!