一种车载语音识别方法及装置与流程
本技术涉及语音识别,具体而言,涉及一种车载语音识别方法及装置。
背景技术:
1、目前,随着智能驾驶技术的快速发展,车载语音识别系统作为人机交互的重要方式备受关注。现有的车载语音识别方法,通常通过语音处理器对采集的语音信息进行放大、滤波去噪、模数转换,获得语音数字信号,然后再输入至语音识别处理器,语音识别处理器再对语音数字信号进行识别获得语音指令。然而,在实践中发现,现有方法难以在保证识别精度的同时满足车载环境的实时性,计算资源约束,精确度低,从而降低了识别效率。
技术实现思路
1、本技术实施例的目的在于提供一种车载语音识别方法及装置,能够大幅降低车载语音识别的参数量和计算复杂度,能够适应车载环境的算力限制,提高了对语音的理解和建模能力,从而提升了车载语音识别的准确性和效率。
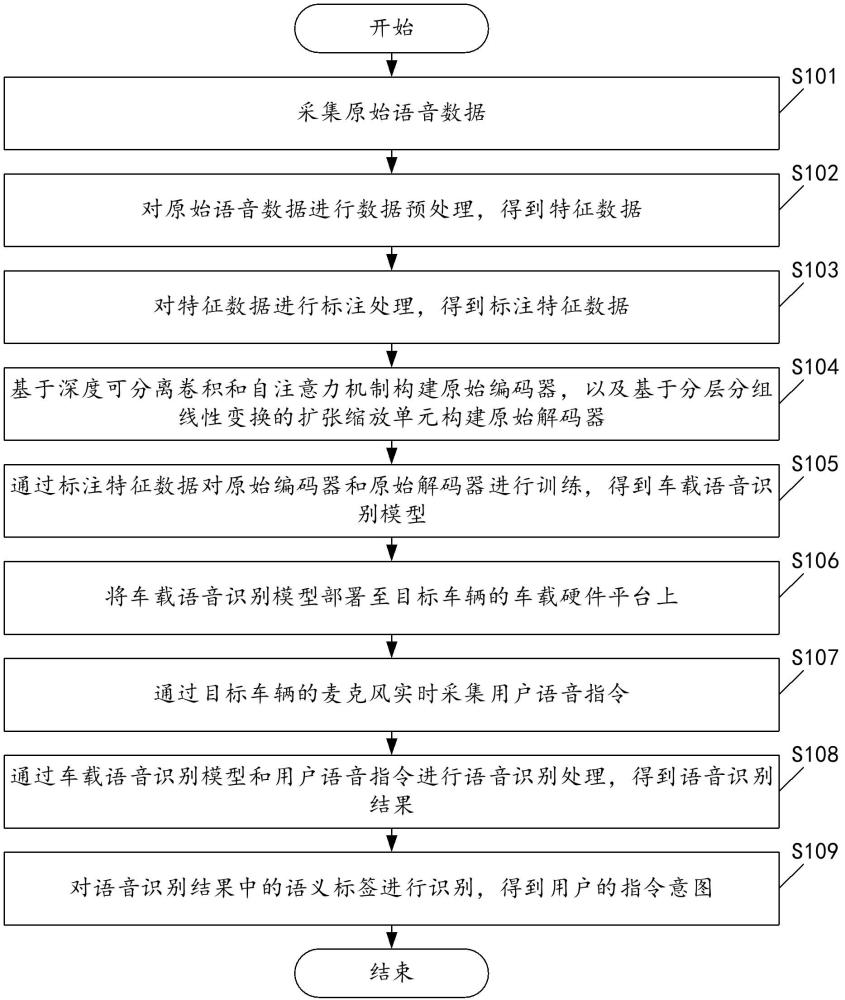
2、本技术第一方面提供了一种车载语音识别方法,包括:
3、采集原始语音数据;
4、对所述原始语音数据进行数据预处理,得到特征数据;
5、对所述特征数据进行标注处理,得到标注特征数据;
6、基于深度可分离卷积和自注意力机制构建原始编码器,以及基于分层分组线性变换的扩张缩放单元构建原始解码器;
7、通过所述标注特征数据对所述原始编码器和所述原始解码器进行训练,得到车载语音识别模型;
8、将所述车载语音识别模型部署至目标车辆的车载硬件平台上;
9、通过所述目标车辆的麦克风实时采集用户语音指令;
10、通过所述车载语音识别模型和所述用户语音指令进行语音识别处理,得到语音识别结果;
11、对所述语音识别结果中的语义标签进行识别,得到用户的指令意图。
12、在上述实现过程中,该方法能够通过改进transformer模型的编码器和解码器结构,降低模型参数量和计算复杂度,同时还能够保持足够的识别精度,使其能够满足新能源汽车实时响应和有限计算资源的要求。
13、进一步地,所述对所述原始语音数据进行数据预处理,得到特征数据,包括:
14、利用预先配置的噪声缩减单元对所述原始语音数据进行噪声去除处理,得到第一处理数据;
15、对所述第一处理数据进行数据清理处理,得到第二处理数据;
16、对所述第二处理数据进行数据分割处理,得到预处理数据;
17、对所述预处理数据进行特征提取,得到特征数据。
18、进一步地,所述对所述预处理数据进行特征提取,得到特征数据,包括:
19、对所述预处理数据进行预加重处理,得到预加重音频数据;
20、对所述预加重音频数据进行划分处理,得到多帧音频数据;
21、对每帧所述音频数据分别施加窗函数,得到每帧所述音频数据的窗加权序列;
22、对所述窗加权序列进行快速傅里叶变换,得到频域数据;
23、将所述频域数据映射到梅尔频率,得到梅尔频率三角滤波器组系数;
24、对所述梅尔频率三角滤波器组系数进行取对数计算,得到对数梅尔频谱系数;
25、对所述对数梅尔频谱系数进行离散余弦变换,得到mfcc系数;
26、将所述mfcc系数确定为特征数据。
27、进一步地,所述对所述特征数据进行标注处理,得到标注特征数据,包括:
28、对所述特征数据进行转录处理,得到每个所述特征数据对应的文本数据;
29、对所述文本数据进行识别,得到每个所述文本数据对应的语义标签;
30、根据所述语义标签对每个所述特征数据进行标注处理,得到标注特征数据。
31、进一步地,所述原始编码器包括输入表示层、多个编码器块以及残差连接和归一化层;其中,所述输入表示层用于通过线性投影算法将输入数据转换为编码器模型维度的连续表示空间;所述编码器块包括深度可分离卷积编码层和多头自注意力层;
32、所述原始解码器包括基于分层分组线性变换的扩张缩放单元;其中,所述扩张缩放单元的参数包括层数、输入维度、输出维度以及分层分组线性变换的最大组数。
33、进一步地,所述通过所述标注特征数据对所述原始编码器和所述原始解码器进行训练,得到车载语音识别模型,包括:
34、对所述原始编码器和所述原始解码器进行整合,得到原始识别模型;
35、对所述标注特征数据进行数据增强处理,得到训练数据集;
36、确定模型训练参数;其中,所述模型训练参数包括损失函数、模型优化算法、梯度更新算法、层别自适应学习率以及训练终止条件;
37、根据所述模型训练参数和所述训练数据集对所述原始识别模型进行训练,得到车载语音模型。
38、进一步地,在所述对所述语音识别结果中的语义标签进行识别,得到用户的指令意图之后,所述方法还包括:
39、根据所述指令意图控制所述目标车辆执行相应的操作。
40、本技术第二方面提供了一种车载语音识别装置,所述车载语音识别装置包括:
41、第一采集单元,用于采集原始语音数据;
42、预处理单元,用于对所述原始语音数据进行数据预处理,得到特征数据;
43、标注单元,用于对所述特征数据进行标注处理,得到标注特征数据;
44、构建单元,用于基于深度可分离卷积和自注意力机制构建原始编码器,以及基于分层分组线性变换的扩张缩放单元构建原始解码器;
45、训练单元,用于通过所述标注特征数据对所述原始编码器和所述原始解码器进行训练,得到车载语音识别模型;
46、部署单元,用于将所述车载语音识别模型部署至目标车辆的车载硬件平台上;
47、第二采集单元,用于通过所述目标车辆的麦克风实时采集用户语音指令;
48、第一识别单元,用于通过所述车载语音识别模型和所述用户语音指令进行语音识别处理,得到语音识别结果;
49、第二识别单元,用于对所述语音识别结果中的语义标签进行识别,得到用户的指令意图。
50、进一步地,所述预处理单元包括:
51、噪声去除子单元,用于利用预先配置的噪声缩减单元对所述原始语音数据进行噪声去除处理,得到第一处理数据;
52、数据清理子单元,用于对所述第一处理数据进行数据清理处理,得到第二处理数据;
53、数据分割子单元,用于对所述第二处理数据进行数据分割处理,得到预处理数据;
54、特征提取子单元,用于对所述预处理数据进行特征提取,得到特征数据。
55、进一步地,所述特征提取子单元包括:
56、预加重模块,用于对所述预处理数据进行预加重处理,得到预加重音频数据;
57、划分模块,用于对所述预加重音频数据进行划分处理,得到多帧音频数据;
58、施加模块,用于对每帧所述音频数据分别施加窗函数,得到每帧所述音频数据的窗加权序列;
59、变换模块,用于对所述窗加权序列进行快速傅里叶变换,得到频域数据;
60、映射模块,用于将所述频域数据映射到梅尔频率,得到梅尔频率三角滤波器组系数;
61、计算模块,用于对所述梅尔频率三角滤波器组系数进行取对数计算,得到对数梅尔频谱系数;
62、所述变换模块,还用于对所述对数梅尔频谱系数进行离散余弦变换,得到mfcc系数;
63、确定模块,用于将所述mfcc系数确定为特征数据。
64、进一步地,所述标注单元包括:
65、转录子单元,用于对所述特征数据进行转录处理,得到每个所述特征数据对应的文本数据;
66、识别子单元,用于对所述文本数据进行识别,得到每个所述文本数据对应的语义标签;
67、标注子单元,用于根据所述语义标签对每个所述特征数据进行标注处理,得到标注特征数据。
68、进一步地,所述原始编码器包括输入表示层、多个编码器块以及残差连接和归一化层;其中,所述输入表示层用于通过线性投影算法将输入数据转换为编码器模型维度的连续表示空间;所述编码器块包括深度可分离卷积编码层和多头自注意力层;
69、所述原始解码器包括基于分层分组线性变换的扩张缩放单元;其中,所述扩张缩放单元的参数包括层数、输入维度、输出维度以及分层分组线性变换的最大组数。
70、进一步地,所述训练单元包括:
71、整合子单元,用于对所述原始编码器和所述原始解码器进行整合,得到原始识别模型;
72、数据增强子单元,用于对所述标注特征数据进行数据增强处理,得到训练数据集;
73、确定子单元,用于确定模型训练参数;其中,所述模型训练参数包括损失函数、模型优化算法、梯度更新算法、层别自适应学习率以及训练终止条件;
74、训练子单元,用于根据所述模型训练参数和所述训练数据集对所述原始识别模型进行训练,得到车载语音模型。
75、进一步地,所述车载语音识别装置还包括:
76、控制单元,用于在第二识别单元对所述语音识别结果中的语义标签进行识别,得到用户的指令意图之后,根据所述指令意图控制所述目标车辆执行相应的操作。
77、本技术第三方面提供了一种电子设备,包括存储器以及处理器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述电子设备执行本技术第一方面中任一项所述的车载语音识别方法。
78、本技术第四方面提供了一种计算机可读存储介质,其存储有计算机程序指令,所述计算机程序指令被一处理器读取并运行时,执行本技术第一方面中任一项所述的车载语音识别方法。
79、本技术的有益效果为:
80、(1)能够通过改进transformer模型的编码器和解码器的结构得到适用于车载语音识别场景的轻量级高效模型,降低模型参数量和计算复杂度,并且能够在保持足够的识别精度的同时,满足新能源汽车实时响应和有限计算资源的要求;
81、(2)该模型可以通过数据增强、噪声去除等方法,提高了对低信噪比环境的适应性,使其能够在嘈杂的车内环境中,保持较高的识别准确率;
82、(3)该模型融合了深度可分离卷积和自注意力机制作为编码器,能够大幅降低了参数量和计算复杂度,适应车载环境的算力限制;同时,创新性地采用了分层分组线性变换的扩张缩放单元作为解码器,在保留表达能力的同时进一步减小了参数规模;
83、(4)通过采用自回归的端到端训练方式,能够使得模型在生成每个时间步的输出时,不仅考虑当前的输入,还会参考之前时间步的输出。可见,这种方式有助于模型更好地捕捉语音数据中的时间相关性和序列信息,提高了对语音的理解和建模能力,从而提升了识别的准确性。
- 还没有人留言评论。精彩留言会获得点赞!