使用说话者嵌入和所训练的生成模型的说话者日志的制作方法
本公开涉及使用说话者嵌入和所训练的生成模型的说话者日志。
背景技术:
1、说话者日志(diarization)是根据说话者身份,将输入音频流分成同质分段(segment)的过程。回答了在多说话者环境中“谁在何时说话”的问题。例如,可以利用说话者日志来标识输入音频流的第一分段可归因于第一人类说话者(没有特别地标识谁是第一人类说话者)、输入音频流的第二分段可归因于不同的第二人类说话者(没有特别地标识谁是第一人类说话者)、输入音频流的第三分段可归因于第一人类说话者等等。说话者日志具有广泛的应用,包括多媒体信息检索、说话者轮次分析和音频处理。
2、典型的说话者日志系统通常包括四个步骤:(1)语音分段,其中,将输入音频分段为假定具有单个说话者的短片段(section),并且过滤掉非语音片段;(2)音频嵌入提取,其中,从分段的片段中提取特定特征;(3)聚类,其中,确定说话者的数量,并且将所提取的音频嵌入聚类成这些说话者;以及可选地,(4)再分段,其中,进一步细化聚类结果以生成最终的日志结果。
3、利用这种典型的说话者日志系统,日志不能准确地识别在给定分段期间多个说话者说话的发生。相反,这样的典型系统将给定分段归因于仅一个说话者,或者不能将给定分段归因于任何说话者。这导致不正确的日志,并且可能对可能依赖于日志结果的其他应用生成不利影响。
4、而且,利用这样的典型的说话者系统,在每个步骤中都会引入错误,并且会传播到其他步骤,由此导致错误的日志结果,从而不利地影响可能依赖于错误的日志结果的其他应用。例如,由于长分段的低分辨率的结果和/或由于具有不足以生成准确的音频嵌入的音频的短分段的结果,在语音分段中可能会引入错误。作为另一个示例,可以在不使用任何全局信息的情况下,在本地生成音频嵌入,这可能附加或替代地引入错误。作为又一个示例,音频嵌入的聚类可以附加地或替代地引入错误,因为它涉及假定精度低的无监督学习。
技术实现思路
1、本文中描述了说话者日志技术,其使得能够处理音频数据序列以生成音频数据的一个或多个细化版本,其中,音频数据的每个细化版本分离单个相应的人类说话者的一个或多个话语,从而使得能够确定音频数据序列的哪一部分对应于相应的人类说话者。例如,假设音频数据序列包括来自第一人类说话者的第一话语、来自第二人类说话者的第二话语以及各种背景噪声的发生。本文公开的实现方式可以被用来生成第一细化的音频数据,该第一细化的音频数据仅包括来自第一人类说话者的第一话语,并且排除第二话语和背景噪声。此外,可以生成第二细化的音频数据,该第二细化的音频数据仅包括来自第二人类说话者的第二话语,并且排除第一话语和背景噪声。再者,在那些实现方式中,即使当第一和第二话语中的一个或多个在音频数据序列中重叠时,也可以分离第一和第二话语。
2、各种实现方式生成音频数据的细化版本,该音频数据的细化版本通过为单个人类说话者生成说话者嵌入,并且使用所训练的生成模型来处理音频数据,以及在处理期间,将说话者嵌入用在确定所训练的生成模型的隐藏层的激活中,分离单个人类说话者的话语。基于该处理,在所训练的生成模型上顺序地生成输出,并且该输出是音频数据的细化版本。
3、在为单个人类说话者生成说话者嵌入时,可以使用所训练的说话者嵌入模型来处理与该人类说话者相对应的一个或多个说话者音频数据实例,以生成一个或多个相应的输出实例。然后,可以基于一个或多个相应的输出实例来生成说话者嵌入。所训练的说话者嵌入模型可以是机器学习模型,诸如递归神经网络(rnn)模型,其将任何长度的相应的音频数据帧的特征序列接受为输入,并且可以用来将相应的嵌入生成为基于该输入的输出。使用所训练的说话者嵌入模型处理序列的音频数据帧的每个特征以生成相应的嵌入可以基于音频数据的相应实例的相应部分,诸如25毫秒或其他持续时间部分。音频数据帧的特征可以是例如音频数据帧的梅尔频率倒谱系数(mfcc)和/或其他特征。在所训练的说话者嵌入模型是rnn模型的情况下,rnn模型包括一个或多个存储器层,每个存储器层包括可以顺序地对其应用输入的一个或多个存储器单元,并且在所应用的输入的每次迭代中,可以利用存储器单元来基于该迭代的输入和基于(可以基于先前迭代的输入的)当前隐藏状态来计算新的隐藏状态。在一些实现方式中,存储器单元可以是长短期(lstm)lstm单元。在一些实现方式中,可以利用附加的或替代的存储器单元,诸如门控循环单元(“gru”)。
4、作为生成用于给定说话者的说话者嵌入的一个示例,可以在注册过程期间,生成说话者嵌入,在注册过程中给定说话者说出多种话语。每个话语可以具有相同的短语(与文本相关),也可以具有不同的短语(与文本无关)。可以在说话者嵌入模型上处理与说出相应话语的给定说话者的每个实例相对应的音频数据的特征,以生成作为值的相应向量的相应输出。例如,可以处理用于第一话语的第一音频数据以生成值的第一向量,可以处理用于第二话语的第二音频数据以生成值的第二向量等等。然后,可以基于值的向量来生成说话者嵌入。例如,说话者嵌入本身可以是值的向量,诸如值的相应向量的形心或其他函数。
5、在利用(例如,在注册过程期间)预生成的用于给定说话者的说话者嵌入的实现方式中,本文所述的技术可以将预先生成的说话者嵌入用在生成音频数据的细化版本中,从而分离给定说话者的话语,其中,经由与注册过程相关联的客户端设备和/或数字系统(例如,自动助理),从用户接收音频数据。例如,如果经由给定用户的客户端设备接收音频数据和/或(例如,使用来自较早话语的语音指纹和/或其他生物特征验证)验证给定用户之后接收到音频数据,可以利用用于给定用户的说话者嵌入以实时地生成音频数据的细化版本。可以将这种细化版本用于各种目的,诸如细化的音频数据的语音到文本转换、验证音频数据的分段来自该用户,和/或本文所述的其他目的。
6、在一些附加或替代实现方式中,用在生成音频数据的细化版本中的说话者嵌入可以基于(待细化的)音频数据本身的一个或多个实例。例如,可以使用语音活动检测器(vad)来确定音频数据中的语音活动的第一实例,以及可以将第一实例的一部分用在生成用于第一人类说话者的第一说话者嵌入中。例如,可以基于使用说话者嵌入模型,处理语音活动的第一实例的第一x(例如0.5、1.0、1.5、2.0)秒的特征,生成第一说话者嵌入(可以假定语音活动的第一实例是来自单个说话者)。例如,基于该处理生成为输出的值的向量可以被用作第一说话者嵌入。然后,可以利用第一说话者嵌入来生成音频数据的第一细化版本,其分离第一说话者的话语,如本文所述。在那些实现方式中的一些实现方式中,可以利用音频数据的第一细化版本来确定对应于第一说话者话语的音频数据的那些分段以及可以利用vad来确定音频数据中,在那些分段之外发生的语音活动的附加实例(如果有的话)。如果确定了附加实例,则可以使用说话者嵌入模型,基于附加实例的处理部分,为第二人类说话者生成第二说话者嵌入。然后,可以利用第二说话者嵌入来生成音频数据的第二细化版本,其分离了第二说话者的话语,如本文所述。该过程可以继续,直到例如在音频数据中没有识别出归因于附加人类说话者的进一步的话语为止。因此,在这些实现方式中,可以由音频数据本身生成用在生成音频数据的细化版本中的说话者嵌入。
7、不管用于生成说话者嵌入的技术如何,本文公开的实现方式都使用所训练的生成模型来处理音频数据和说话者嵌入,以生成音频数据的细化版本,其分离与说话者嵌入相对应的说话者的话语(如果有的话)。例如,可以使用所训练的生成模型来顺序地处理音频数据,并且在顺序处理期间,将说话者嵌入用在确定用于所训练的生成模型的层的激活中。所训练的生成模型可以是序列到序列模型,并且可以将音频数据的细化版本顺序地生成为来自所训练的生成模型的直接输出。所训练的生成模型的层是隐藏层,并且可以包括例如扩张因果(dilated causal)卷积层的堆叠。扩张因果卷积层的堆叠使得卷积层的感受野能够随深度呈指数增长,这对于建模音频信号中的远程时间依存关系是有益的。在各种实现方式中,使用所训练的生成模型处理的音频数据可以处于波形级别,并且使用所训练的生成模型生成的细化的音频数据也可以处于波形级别。在一些实现方式中,所训练的生成模型具有wavenet模型架构,并且已经根据本文描述的技术训练过。
8、在各种实现方式中,训练所训练的生成模型以对条件分布p (x | h)进行建模,其中x表示音频数据的细化版本,以及h表示说话者嵌入。更正式地说,p (x | h)可以表示为:
9、
10、其中,x1...xt-1表示(可以以源音频数据为条件的)t个细化音频样本预测的序列,以及xt表示下一个细化音频样本预测(即,用于音频数据的细化版本的下一个音频样本预测)。如上所述,h表示说话者嵌入,并且可以是尺寸固定的实际值的向量。
11、此外,在各种实现方式中,可以由下述等式表示在所训练的生成模型的一层或多层的每一层处(例如,在每个因果卷积层处)的输出过滤器:
12、
13、其中,w表示过滤器,而v表示另一过滤器。因此,通过利用过滤器v变换h、利用过滤器w变换音频样本x,并且将两个运算的结果相加,执行将说话者嵌入h与音频样本x的组合。这两个运算的结果(z)将成为下一层的输入x。在训练生成模型期间学习的生成模型的权重可以包括过滤器w和v的权重。本文提供了生成模型及其训练的附加描述。
14、鉴于给定说话者的给定说话者嵌入,利用所训练的生成模型来处理给定音频数据将生成与当给定音频数据仅包括来自给定说话者的话语时的给定音频数据相同的细化的音频数据。此外,将导致当给定音频数据缺少来自给定说话者的任何话语时,为空/零的细化的音频数据。更进一步,当给定音频数据包括来自给定说话者的话语和附加声音时(例如,重叠和/或不重叠其他人类说话者的话语),将导致排除附加声音,同时隔离来自给定说话者的话语的细化的音频数据。
15、音频数据的细化版本可以由各种组件利用并且用于各种目的。作为一个示例,可以对分离来自单个人类说话者的话语的音频数据的细化版本执行语音到文本处理。由于例如细化版本缺少背景噪声、其他用户的话语(例如重叠话语)等,相对于对音频数据(或音频数据的替代预处理版本)执行处理,对音频数据的细化版本执行语音到文本处理可以提高语音到文本处理的准确性。此外,对音频数据的细化版本执行语音到文本处理确保所得的文本属于单个说话者。改进的准确性和/或确保所得的文本属于单个说话者可以直接导致进一步的技术优势。例如,提高的文本准确性可以增加依赖于所得文本的一个或多个下游组件(例如,自然语言处理器、基于以文本的自然语言处理为基础而确定的意图和参数生成响应的模块)的准确性。同样,例如,当与自动助理和/或其他交互式对话系统结合地实现时,提高的文本准确性可以减少交互式对话系统无法将所说的话语转换为文本的机会和/或减少交互式对话系统可能会错误地将口头话语转换为文本,从而导致对话系统提供对话语的错误的响应的机会。这可以减少对话轮次的数量,否则用户将需要对交互式对话系统再次提供所说的话语和/或其他澄清。
16、附加地或可替代地,音频数据的细化版本可以被用来将音频数据的分段分配给相应的人类说话者。将分段分配给人类说话者可以在语义上有意义(例如,识别说话者的属性),或者可以仅指示该分段属于一个或多个非语义上有意义的说话者标签中的哪一个。与其他说话者日志技术相比,本文公开的实现方式可以导致生成更健壮和/或更准确的分配。例如,可以通过利用本文公开的实现方式,减轻其他技术(诸如上文背景技术中提到的技术)引入的各种错误。附加地或可替代地,使用本文公开的实现方式可以使得能够确定包括来自两个或以上人类说话者中的每一个的相应话语的分段,这是利用各种其他说话者日志技术无法实现的。此外,附加地或可替代地,与现有的说话者日志技术相比,本文公开的实现方式可以使得能够以计算上更有效的方式执行说话者日志。例如,在本文公开的各种实现方式中,可以消除现有技术的计算密集型聚类。
17、在各种实现方式中,本文描述的技术被用来生成说话者日志结果、执行自动语音识别(asr)(例如,语音到文本处理)和/或对(例如,经由应用编程接口(api))作为语音处理请求的一部分提交的音频数据的其他处理。在那些实现方式中的一些实现方式中,响应于语音处理请求来生成对音频数据的处理的结果,并且将其发送回发送语音处理请求的计算设备,或者发送回相关的计算设备。
18、在各种实现方式中,本文描述的技术被用来生成由客户端设备的麦克风捕获的音频数据的说话者日志结果,该客户端设备包括用于自动助理的自动助理界面。例如,音频数据可以是捕获来自一个或多个说话者的所说的话语的音频数据流,并且本文所述的技术可以被用来生成说话者日志结果、执行自动语音识别(asr),和/或对音频数据流的其他处理。
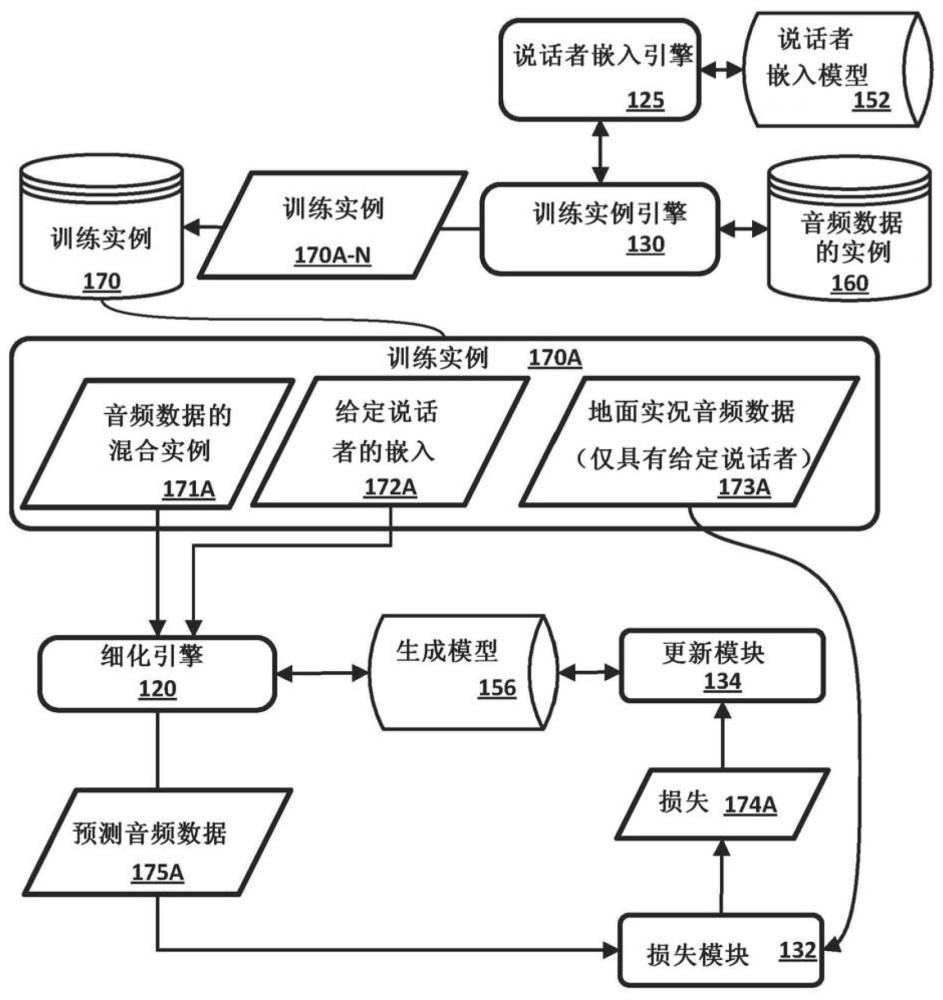
19、提供以上描述作为本文公开的各种实现方式的概述。在本文中更详细地描述这些各种实现方式以及附加实现方式。
20、在一些实现方式中,提供了一种方法,该方法包括生成针对人类说话者的说话者嵌入。生成针对人类说话者的说话者嵌入可以可选地包括:使用所训练的说话者嵌入模型来处理与所述人类说话者相对应的一个或多个说话者音频数据实例,以及基于一个或多个输出实例生成所述说话者嵌入,每个输出实例基于使用所训练的说话者嵌入模型来处理所述一个或多个说话者音频数据实例中的相应实例而生成。该方法进一步包括:接收音频数据,所述音频数据捕获所述人类说话者的一个或多个话语,并且还捕获不是来自所述人类说话者的一个或多个附加声音;生成所述音频数据的细化版本,其中,所述音频数据的细化版本将所述人类说话者的一个或多个话语与不是来自所述人类说话者的一个或多个附加声音分离,并且对所述音频数据的细化版本执行进一步处理。
21、这些和其他实现方式可以包括下述一个或多个特征。
22、在一些实现方式中,生成音频数据的细化版本包括:使用所训练的生成模型顺序地处理所述音频数据并且在所述顺序处理期间,在确定所训练的生成模型的层的激活中使用所述说话者嵌入,以及基于所述顺序处理并且作为来自所训练的生成模型的直接输出,顺序地生成所述音频数据的细化版本。
23、在一些实现方式中,执行进一步处理包括:对所述音频数据的细化版本执行语音到文本处理,以生成针对所述人类说话者的一个或多个话语的预测文本;和/或基于至少对应于所述音频数据的细化版本中的音频的阈值水平的一个或多个时间部分,将单个给定的说话者标签分配给所述音频数据的一个或多个时间部分。
24、在一些实现方式中,提供一种方法,包括在客户端设备处调用自动助理客户端,其中,调用所述自动助理客户端是响应于在所接收的用户界面输入中检测到一个或多个调用队列。该方法进一步包括:响应于调用所述自动助理客户端:对经由所述客户端设备的一个或多个麦克风接收到的初始口头输入执行某些处理;基于所述初始口头输入的某些处理生成响应动作;使得执行所述响应动作;以及确定对所述客户端设备上的自动助理客户端激活继续收听模式。该方法进一步包括响应于激活所述继续收听模式:在使得执行所述响应动作的至少一部分后,自动地监视附加口头输入;在所述自动监视期间接收音频数据;以及确定所述音频数据是否包括来自提供所述初始口头输入的同一人类说话者的任何附加口头输入。确定所述音频数据是否包括来自同一人类说话者的附加口头输入包括:识别用于提供所述初始口头输入的人类说话者的说话者嵌入;生成分离来自所述人类说话者的任何音频数据的所述音频数据的细化版本,其中,生成所述音频数据的细化版本包括:使用所训练的生成模型处理所述音频数据,并且在所述处理期间,将所述说话者嵌入用在确定用于所训练的生成模型的层的激活中;以及基于所述处理,生成所述音频数据的细化版本;以及基于所述音频数据的细化版本的任何部分是否至少对应于音频的阈值水平,确定所述音频数据是否包括来自同一人类说话者的任何附加口头输入。该方法进一步包括响应于确定所述音频数据不包括来自同一人类说话者的任何附加口头输入,抑制下述中的一者或两者:对于所述音频数据,执行至少一些某些处理;以及生成适合于所述音频数据的任何附加响应动作。
25、在一些实现方式中,提供一种方法,该方法包括:接收经由所述客户端设备的一个或多个麦克风捕获的音频数据流;从所述客户端设备的本地存储中检索用于所述客户端设备的人类用户的先前生成的说话者嵌入;在接收所述音频数据流的同时,生成所述音频数据的细化版本,其中,所述音频数据的细化版本将所述人类用户的一个或多个话语与不是来自所述人类说话者的任何附加声音分离,并且其中,生成所述音频数据的细化版本包括:使用所训练的生成模型处理所述音频数据,并且使用说话者嵌入(例如在所述处理期间,确定用于所训练的生成模型的层的激活中);以及基于所述处理并且作为来自所训练的生成模型的直接输出,生成所述音频数据的细化版本。该方法进一步包括:对所述音频数据的细化版本执行本地语音到文本处理,和/或将所述音频数据的细化版本发送到远程系统,以使得对所述音频数据的细化版本执行远程语音到文本处理。
26、在一些实现方式中,提供一种训练机器学习模型以生成音频数据的细化版本的方法,该音频数据的细化版本分离目标人类说话者的任何话语。该方法包括:识别包括仅来自第一人类说话者的口头输入的音频数据的实例;为所述第一人类说话者生成说话者嵌入;识别缺少来自所述第一人类说话者的任何口头输入并且包括来自至少一个附加人类说话者的口头输入的音频数据的附加实例;生成组合所述音频数据的实例和所述音频数据的附加实例的音频数据的混合实例;使用所述机器学习模型,处理所述音频数据的混合实例并且在所述处理期间,将所述说话者嵌入用在确定用于所述机器学习模型的层的激活中;基于所述处理并且作为所述机器学习模型的直接输出,生成所述音频数据的预测细化版本;基于将所述音频数据的预测细化版本与包括仅来自所述第一人类说话者的口头输入的音频数据的实例进行比较来生成损失;以及基于所述损失,更新所述机器学习模型的一个或多个权重。
27、另外,一些实现方式包括一个或多个计算设备的一个或多个处理器,其中,一个或多个处理器可操作以执行存储在相关联的存储器中的指令,并且其中,所述指令被配置为使得执行本文所述的任一方法。一些实现方式还包括一个或多个非暂时性计算机可读存储介质,其存储可由一个或多个处理器执行以执行本文所述的任一方法的计算机指令。
28、应当意识到,本文更详细描述的前述概念和附加概念的所有组合被认为是本文公开的主题的一部分。例如,出现在本公开的结尾处的所要求保护的主题的所有组合被认为是本文公开的主题的一部分。
- 还没有人留言评论。精彩留言会获得点赞!