一种用于网络会议的音频阵列互动方法及系统与流程
本发明涉及音频处理,尤其涉及一种用于网络会议的音频阵列互动方法及系统。
背景技术:
1、音频阵列(microphone array)是一种由多个麦克风组成的系统,用于捕捉和处理声音信号,通过对不同麦克风接收到的声音信号进行组合和分析,音频阵列能够增强某一方向的声音,同时抑制其他方向的噪音。其核心在于其能够实现波束成形(beamforming),这是一种通过调整麦克风接收到的信号相位和幅度,从而实现特定方向上的声音增强或抑制的方法。
2、音频阵列技术常用于提高语音识别的准确性和语音通信的清晰度,如在进行网络会议时,通常存在多个参会者,这时则需要定位发言人,使其他参会者可以清晰听到发言内容,不被其它噪声干扰。目前的网络会议系统在音频处理方面已经有了显著进步,许多系统已经集成了基本的噪音抑制和回声消除功能,但对非发言内容干扰以及发言流利度方面并没有进行有效的改进,影响用户体验。
技术实现思路
1、有鉴于此,本发明目的在于提供一种用于网络会议的音频阵列互动方法及系统,以实现在网络会议中对音频中的音色以及发言内容有效处理后提高参会者的体验度。
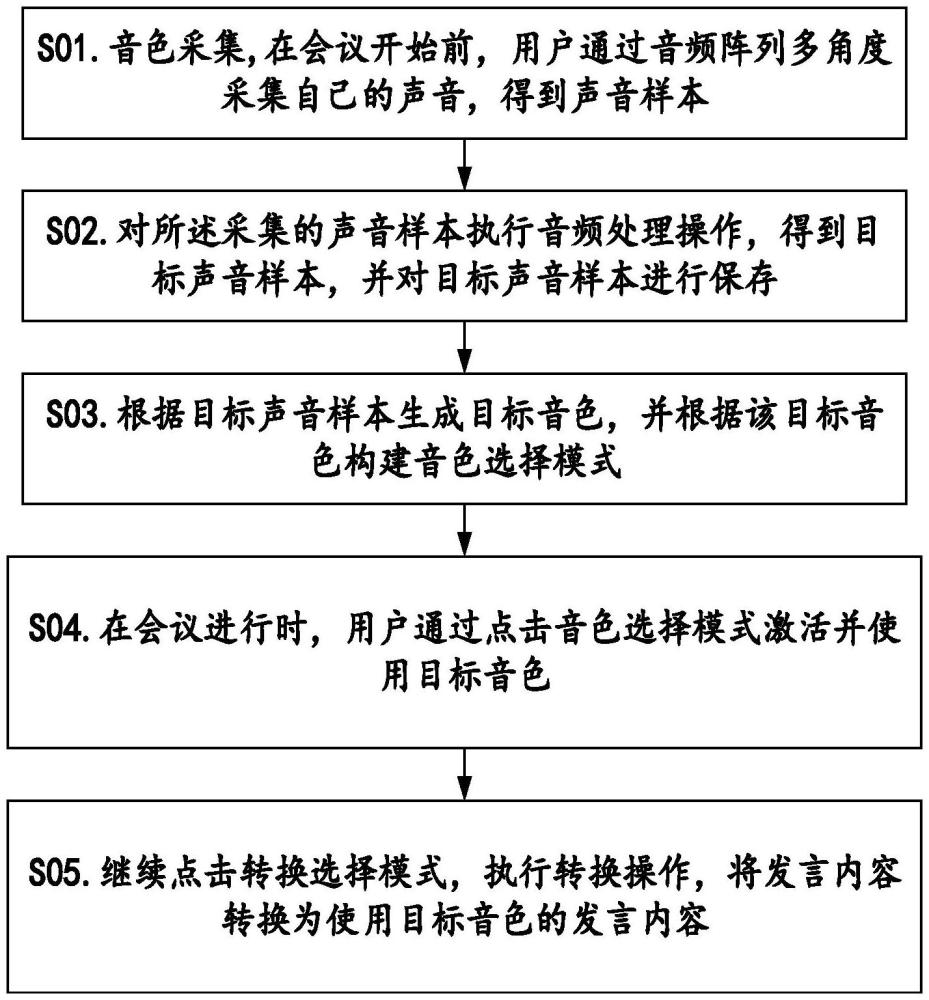
2、本发明第一方面公开了一种用于网络会议的音频阵列互动方法,该方法包括以下步骤:
3、s01.音色采集,在会议开始前,用户通过音频阵列多角度采集自己的声音,得到声音样本;
4、s02.对所述采集的声音样本执行音频处理操作,得到目标声音样本,并对目标声音样本进行保存;
5、s03.根据目标声音样本生成目标音色,并根据该目标音色构建音色选择模式;
6、s04.在会议进行时,用户通过点击音色选择模式激活并使用目标音色;
7、s05.继续点击转换选择模式,执行转换操作,将发言内容转换为使用目标音色的发言内容。
8、进一步地,所述步骤s05中的转换选择模式包括语音转换子模式和文字转换子模式。
9、进一步地,通过所述语音转换子模式将用户的实时语音发言内容转换为使用目标音色的发言内容后进行语音输出。
10、进一步地,通过所述文字转换子模式将用户预输入的文字发言内容转换为使用目标音色的发言内容后进行语音输出。
11、进一步地,当有用户语音发言时,采用音频阵列采集室内的声音信号,通过波束成形算法实时确定会议中的发言人位置,并利用时间差和强度差分析,准确识别当前发言人。
12、进一步地,在识别当前发言人后,使用音频信号处理技术实时分析音频阵列采集到的室内的声音信号,识别环境噪声和发言人的语音信号,并通过自适应噪音消除算法动态调整噪音过滤参数,得到目标语音。
13、进一步地,所述方法还包括构建纯净人声模式,用户通过点击纯净人声模式对目标语音执行滤除发言噪声操作,所述发言噪声包括发言过程中的咳嗽声、打喷嚏声。
14、进一步地,所述构建纯净人声模式的过程包括:
15、准备包含发言内容和发言噪声的音频数据集,并对数据集进行标注,区分发言内容与非发言内容;其中,所述音频数据集包括训练音频数据集和验证音频数据集;
16、选择深度学习架构训练纯净人声模型,将所述训练音频数据集作为训练模型的输入数据,将该数据集中区分出来的发言内容作为训练模型的输出数据,训练得到第一纯净人声模型;
17、将所述验证音频数据集输入所述第一纯净人声模型,验证通过第一纯净人声模型输出的结果与从验证音频数据集区分出的发言内容相比是否达到预设值,在达到预设值的情况下,将所述第一纯净人声模型作为训练好的目标纯净人声模型;
18、基于目标纯净人声模型构建纯净人声模式。
19、本发明第二方面公开了一种用于网路会议的音频阵列互动系统,该系统基于第一方面公开的方法实现,系统包括采集模块、音频处理模块、存储模块、构建模块以及控制模块;
20、采集模块用于在会议开始前,供用户通过音频阵列多角度采集自己的声音,得到声音样本;
21、音频处理模块用于对采集的声音样本执行音频处理操作,得到目标声音样本;
22、存储模块用于对目标声音样本进行保存;
23、构建模块用于根据目标声音样本生成目标音色,并根据该目标音色构建音色选择模式;
24、控制模块用于提供界面供用户选择音频处理模式以控制系统对音频进行相应处理;其中,所述音频处理模式包括音色选择模式、转换选择模式;
25、在会议进行时,用户通过点击音色选择模式激活并使用目标音色;并继续点击转换选择模式,通过控制模块控制系统执行转换操作,将发言内容转换为使用目标音色的发言内容。
26、进一步地,转换选择模式包括语音转换子模式和文字转换子模式。
27、进一步地,通过所述语音转换子模式将用户的实时语音发言内容转换为使用目标音色的发言内容后进行语音输出。
28、进一步地,通过所述文字转换子模式将用户预输入的文字发言内容转换为使用目标音色的发言内容后进行语音输出。
29、进一步地,当有用户语音发言时,所述采集模块还用于采用音频阵列采集室内的声音信号,通过音频处理模块基于波束成形算法实时确定会议中的发言人位置,并利用时间差和强度差分析,准确识别当前发言人。
30、进一步地,在识别当前发言人后,通过音频处理模块使用音频信号处理技术实时分析音频阵列采集到的室内的声音信号,识别环境噪声和发言人的语音信号,并通过自适应噪音消除算法动态调整噪音过滤参数,得到目标语音。
31、进一步地,所述音频处理模式还包括纯净人声模式,所述构建模块还用于构建纯净人声模式,用户通过点击纯净人声模式对目标语音执行滤除发言噪声操作,所述发言噪声包括发言过程中的咳嗽声、打喷嚏声。
32、进一步地,所述构建纯净人声模式的过程包括:
33、准备包含发言内容和发言噪声的音频数据集,并对数据集进行标注,区分发言内容与非发言内容;其中,所述音频数据集包括训练音频数据集和验证音频数据集;
34、选择深度学习架构训练纯净人声模型,将所述训练音频数据集作为训练模型的输入数据,将该数据集中区分出来的发言内容作为训练模型的输出数据,训练得到第一纯净人声模型;
35、将所述验证音频数据集输入所述第一纯净人声模型,验证通过第一纯净人声模型输出的结果与从验证音频数据集区分出的发言内容相比是否达到预设值,在达到预设值的情况下,将所述第一纯净人声模型作为训练好的目标纯净人声模型;
36、基于目标纯净人声模型构建纯净人声模式。
37、与现有技术相比,本发明的有益效果为:
38、本发明通过音频阵列技术对用户声音信号进行预采集并处理形成目标音色,对发言人的语言发言内容以及文字发言内容转换为应用该目标音色的发言语音进行输出,降低发言人发言压力的同时,提高了与会者的听觉体验,使与会者更清晰获取发言者所要表达的内容;此外,本发明还基于深度学习算法构建纯净人声模型来滤除发言者在发言过程中发出的与发言内容无关的发言噪声,进一步提高了用户体验度。
- 还没有人留言评论。精彩留言会获得点赞!