情感语音合成方法、装置、计算机设备及存储介质与流程
本技术涉及语音处理,尤其涉及一种情感语音合成方法、装置、计算机设备及存储介质。
背景技术:
1、随着人工智能技术的发展,语音合成在人机对话领域占有越来越重要的地位。情感语音合成作为语音合成的重要补充,大大提升了语音合成的应用场景,根据不同的场景和环境,切换对应的情绪表达对于如在金融系统布置智能客服时通过对智能客服合成富有感染力的语音能够大幅提升用户的使用体验。
2、传统的情感语音合成需要在标注的合成语料的基础上,录制大量的与情感和风格相关的数据。导致存在下列问题:第一是情感数据的录制难度很大,单说话人的情感音库无法迁移到其它的音库;第二是标注情感的难度加大,情感相对来说是比较主观的表达特征,不同人员对不同情感的表达的认知和理解不同。基于以上两点,传统的语音情感合成系统受数据标注条件限制较大,导致所合成的语音效果不佳。
技术实现思路
1、本技术提供了一种情感语音合成方法、装置、计算机设备及存储介质,旨在解决传统模式下,当给予用于的角色包含许多用户无需使用的权限时,存在用户利用这些权限获取相关隐私资料的风险,但是若不授予用户相应角色权限则会为相应上级管理人员带来巨大的工作量,导致当下的情感语音合成方法存在着权限数据安全隐患、数据泄露风险、权限体系标准不统一等诸多问题。所提供的方法能形成一套完整、标准、安全的自动化情感语音合成方案,确保预设系统在业务快速响应的同时也能得以安全运行。
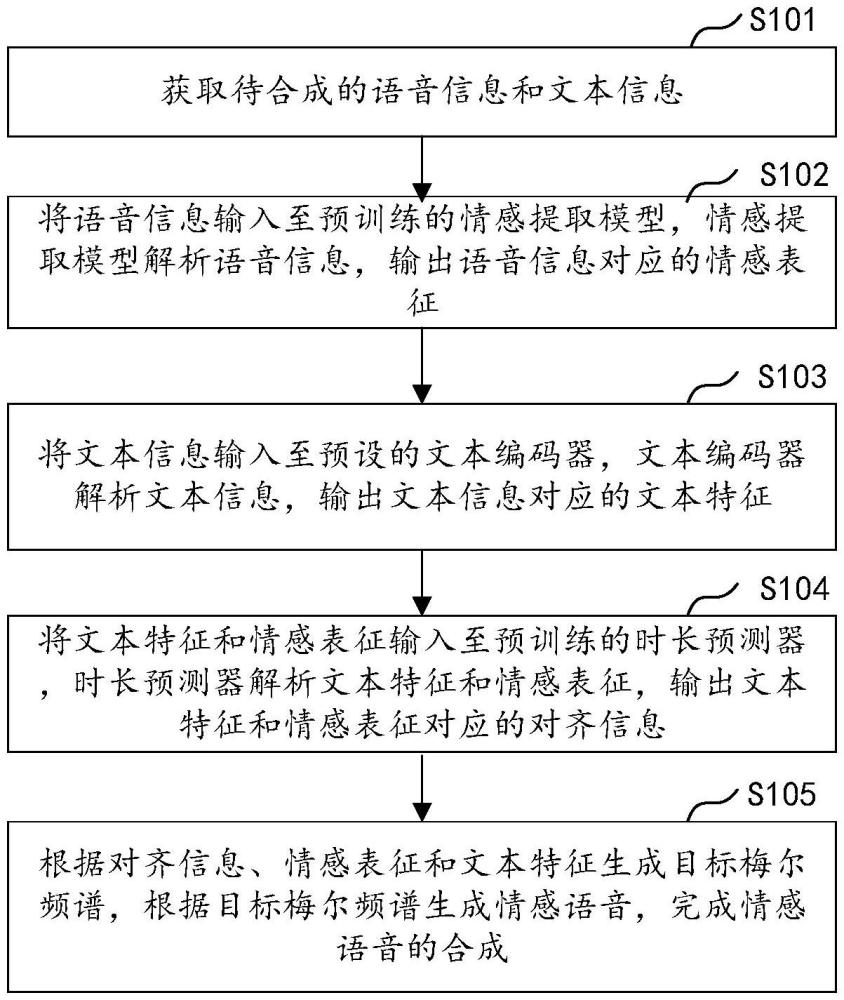
2、第一方面,本技术提供了一种情感语音合成方法,方包括:
3、获取待合成的语音信息和文本信息;
4、将语音信息输入至预训练的情感提取模型,情感提取模型解析语音信息,输出语音信息对应的情感表征;
5、将文本信息输入至预设的文本编码器,文本编码器解析文本信息,输出文本信息对应的文本特征;
6、将文本特征和情感表征输入至预训练的时长预测器,时长预测器解析文本特征和情感表征,输出文本特征和情感表征对应的对齐信息;
7、根据对齐信息、情感表征和文本特征生成目标梅尔频谱,根据目标梅尔频谱生成情感语音,完成情感语音的合成。
8、在一些实施例中,在将语音信息输入至预训练的情感提取模型之前,还包括:获取已合成的历史情感语音、历史情感语音对应的历史语音信息和历史文本信息;将历史情感语音输入至待训练的情感提取模型,输出历史情感语音对应的历史情感表征;将历史文本信息输入至预训练的文本编码器,输出历史文本信息对应的历史文本特征;将历史情感表征和历史文本特征输入至预训练的时长预测器,时长预测器输出历史文本特征和历史情感表征对应的历史对齐信息;根据历史对齐信息、历史情感表征和历史文本特征生成预测梅尔频谱,根据预测梅尔频谱生成预测情感语音;根据历史情感语音和预测情感语音完成对情感提取模型的训练。
9、示例性的,在将历史文本信息和历史文本特征输入至预训练的时长预测器之前,还包括:获取历史情感语音对应的线性谱信息,将线性谱信息输入至预设的后验编码器,后验编码器解析线性谱信息,输出线性谱信息对应的隐变量信息和声学特征;将隐变量信息和历史文本信息输入至预设的强制对齐模块,强制对齐模块输出隐变量信息和历史文本信息对应的强制对齐信息;将历史情感表征和历史文本特征输入至待训练的时长预测器,时长预测器输出历史文本特征和历史情感表征对应的预测对齐信息根据预测对齐信息和强制对齐信息完成对时长预测器的训练。
10、需要说明的是,在一些实施例中,在根据目标梅尔频谱生成情感语音之前,还包括:将声学特征输入至待训练的语音解码器,语音解码器解析声学特征,输出声学特征对应的预测语音信息;根据历史语音信息和预测语音信息完成对语音解码器的训练,以将目标梅尔频谱输入至训练完成的语音解码器,输出情感语音。
11、需要说明的是,在一些实施例中,根据对齐信息、情感表征和文本特征生成目标梅尔频谱,根据目标梅尔频谱生成情感语音,包括:将对齐信息、情感表征和文本特征输入至预设的流模型,流模型输出目标梅尔频谱;其中,后验编码器解析线性谱信息,输出线性谱信息对应的隐变量信息为简单隐变量信息;在将隐变量信息和历史文本信息输入至预设的强制对齐模块之前,还包括:将简单隐变量信息逆输入至流模型,流模型输出简单隐变量信息对应的复杂隐变量信息,以将复杂隐变量信息输入强制对齐模块。
12、需要说明的是,在一些实施例中,在将历史文本信息输入至预训练的文本编码器之前,还包括:将历史文本信息输入至待训练的文本编码器,输出历史文本信息对应的预测文本特征获取声学特征与预测文本特征的相对熵信息;根据相对熵信息完成对文本编码器的训练。
13、示例性的,根据历史情感语音和预测情感语音完成对情感提取模型的训练,包括:获取历史情感语音对应的历史梅尔频谱;获取历史梅尔频谱与预测梅尔频谱的交叉损失信息;根据交叉损失信息、历史情感语音和预测情感语音完成对情感提取模型的训练。
14、第二方面,本技术提供了一种情感语音合成装置,包括:
15、信息获取单元,语音获取待合成的语音信息和文本信息;
16、表征提取单元,用于将语音信息输入至预训练的情感提取模型,情感提取模型解析语音信息,输出语音信息对应的情感表征;
17、特征输出单元,用于将文本信息输入至预设的文本编码器,文本编码器解析文本信息,输出文本信息对应的文本特征;
18、时长预测单元,用于将文本特征和情感表征输入至预训练的时长预测器,时长预测器解析文本特征和情感表征,输出文本特征和情感表征对应的对齐信息;
19、语音合成单元,用于根据对齐信息、情感表征和文本特征生成目标梅尔频谱,根据目标梅尔频谱生成情感语音,完成情感语音的合成。第三方面,本技术还提供了一种计算机设备,包括:
20、存储器和处理器;
21、所述存储器用于存储计算机程序;
22、所述处理器,用于执行所述计算机程序并在执行所述计算机程序时实现如上第一方面所述的情感语音合成方法的步骤。
23、第四方面,本技术还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时使所述处理器实现如上第一方面所述的情感语音合成方法的步骤。
24、本技术公开了一种情感语音合成方法、装置、计算机设备及存储介质。方法通过获取待合成的语音信息和文本信息;将语音信息输入至预训练的情感提取模型,情感提取模型解析语音信息,输出语音信息对应的情感表征;将文本信息输入至预设的文本编码器,文本编码器解析文本信息,输出文本信息对应的文本特征;将文本特征和情感表征输入至预训练的时长预测器,时长预测器解析文本特征和情感表征,输出文本特征和情感表征对应的对齐信息;根据对齐信息、情感表征和文本特征生成目标梅尔频谱,根据目标梅尔频谱生成情感语音,完成情感语音的合成。
25、通过提取语音信息和文本信息,所提供的方法能够将语言信息对应的情感表征和文本信息对应的文本特征进行时长对齐和融合,进而在无需对训练样本进行标注的情况下通过端到端的方法对相关模型进行训练实现情感语音的精准合成。
26、进而所提供的方法通过实现无标注的情感语音合成解决了情感标注数据难的问题,能够直接学习情感表征在语音合成模型的作用。不仅仅如此,整个方法还能根据需求实现任意多情感风格的语音合成。
27、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
- 还没有人留言评论。精彩留言会获得点赞!