一种基于情感迁移和特征插值的说话人匿名化方法
本发明属于深度学习领域,具体涉及一种基于情感迁移和特征插值的说话人匿名化方法。
背景技术:
1、说话人匿名化是一项旨在保护说话人隐私的技术,主要应用于语音数据处理和传输的过程中。随着语音识别、语音合成等语音技术的迅猛发展,越来越多的语音数据被采集、存储和分析。语音数据中包含了许多敏感信息,包括但不限于说话人的身份、情感、健康状况等。如果这些信息被不法分子获取,可能会被用于恶意用途,如身份盗窃、社会工程攻击等。因此,如何在保证语音数据可用性的同时保护说话人的隐私成为一个重要任务。
2、说话人匿名化技术的主要目标是改变或隐藏语音信号中的说话人身份信息,同时尽可能保持语音内容的自然性和可理解性。这一技术的应用不仅可以保护用户隐私,还能在医疗、司法和智能助手等领域提供安全保障。
3、目前的说话人匿名化方法主要分为两类:基于语音转换和语音合成的方法。基于语音转换的方法通过将输入语音转换为不同说话人的声音,从而隐藏原始说话人的身份。基于语音合成的方法则是根据输入文本合成语音,完全替换原始声音。
4、尽管这些技术在实验中取得了一定成果,但仍存在一些挑战。首先,在匿名化处理后,语音信号的自然性和可理解性常常会受到影响。其次,现有的匿名化技术在面对多种语言、多种音域和复杂环境时的鲁棒性仍需提高。最后,如何在匿名化的同时保证语音数据在特定任务中的有效性(如情感分析、语音识别)也是一个亟待解决的问题。
5、因此,研究和开发更高效、更鲁棒的说话人匿名化技术具有重要的现实意义。这不仅能有效保护用户隐私,还能推动语音技术在更多领域的安全应用。
技术实现思路
1、本发明所要解决的技术问题在于:针对现有技术中的说话人匿名化系统在对语音匿名化后,语音信号的可理解性和情感信息会受到影响。本发明提供一种基于情感迁移和特征插值的说话人匿名化方法,该方法能够较好地维持语音的情绪状态以及语言内容。
2、为解决以上技术问题,本发明提供如下技术方案:一种基于情感迁移和特征插值的说话人匿名化方法,包括训练和转换阶段,所述训练阶段包括以下步骤:
3、(1.1)构建训练语料,训练语料由多名说话人的语音构成,所述说话人的语料包含不同情绪状态;
4、(1.2)遍历数据集中的每个音频文件,采用wavlm模型提取自监督特征,构建匹配和合成池,并计算匹配结果;
5、(1.3)采用wav2vec2-large-robust-12-ft-emotion-msp-dim模型提取语音的情绪特征向量;
6、(1.4)构建基于hifi-gan的声码器网络;
7、(1.5)将说话人的预匹配特征和情绪特征输入到声码器网络进行训练;
8、所述转换阶段包括以下步骤:
9、(2.1)利用预训练的wavlm模型作为特征提取器来提取语言内容和说话人信息;
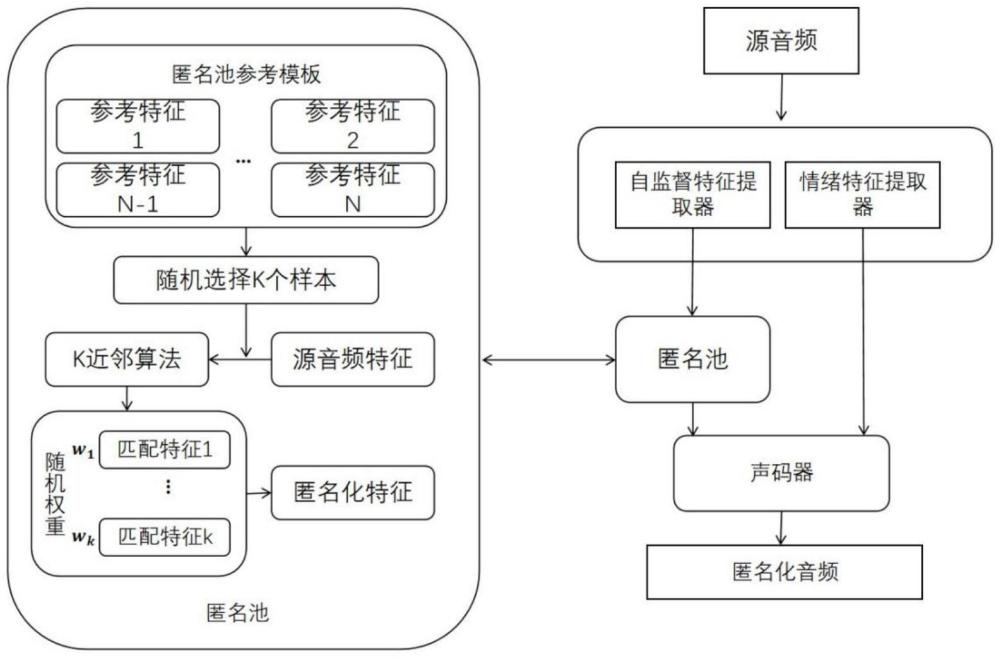
10、(2.2)构建说话人匿名池,通过生成虚拟的说话人,并根据特定规则选择和插值特征;
11、(2.3)将步骤(2.1)中提取的特征,通过步骤(2.2)构建的匿名池,进行匿名化处理,转换为伪说话人特征。
12、(2.4)采用wav2vec2-large-robust-12-ft-emotion-msp-dim模型提取语音的情绪特征向量;
13、(2.5)将步骤(2.3)和(2.4)生成的特征向量,送入训练好的模型,进行语音合成,得到匿名化后的说话人语音。
14、进一步的,包括:
15、步骤(1.2)中,我们使用从wavlm-large的第6层提取的特征,该特征为每20ms的16khz音频生成一个向量。根据当前音频文件的说话人,从相同说话人的其他音频文件中构建匹配池和合成池。并且使用快速余弦距离计算方法,评估当前音频特征与匹配池中特征的相似性。最后选择最匹配的特征,并将其合成为最终的特征表示。
16、进一步的,包括:
17、步骤(1.3)中,所述的wav2vec2-large-robust-12-ft-emotion-msp-dim模型是基于wav2vec2.0框架的变种,通过大量的未标注语音数据进行预训练,并在标注数据上进行微调,以提升情感识别任务的性能。通过该预训练模型来提取情感特征,其提取过程包括以下步骤:
18、(1)构建回归头,将特征映射到情感标签。回归头通过一系列的线性变换、非线性激活和dropout层,成功地将wav2vec 2.0模型提取的特征转化为情感标签。
19、(2)构建情感识别模型,加载预训练的wav2vec 2.0模型并添加回归头。
20、(3)将输入音频信号通过模型进行推理,生成情感特征嵌入。
21、进一步的,包括:
22、步骤(1.5)中采用hifigan-v1声码器来训练,并且以自监督特征和情绪特征作为输入。
23、进一步的,包括:
24、步骤(2.2)匿名池的构建和伪说话人的生成是匿名化过程中的关键步骤,其构建过程包括以下步骤:
25、(1)从语料库中随机选择n个说话人,并且利用wavlm模型来对说话人的多条音频进行特征提取,并将各个音频特征拼接在一起,形成转换过程中的参考特征。
26、(2)从参考匿名池中随机选择m个说话人来提供语音嵌入,其中
27、(3)对于每个说话人,使用k最近邻(knn)算法从目标参考匿名池获取最近表示。这一步可以描述为:
28、
29、其中knn(x,y,k)表示在集合y中找到离向量x最近的k个向量。t表示说话人spk的源帧长度。
30、(7)获取每个说话人的最近表示后,我们需要对这些目标说话人的向量进行特征插值,以生成伪说话人。假设随机生成的说话人权重向量w=(w1,w2,...,wk),权重向量的计算公式为:
31、
32、其中spk表示从参考匿名池中随机选择的说话人数量,n(0,1)表示权重向量w介于0到1之间。
33、(8)通过softmax函数将权重之和约束为1。
34、(9)最终,通过对每个说话人的表示进行加权求和,得到目标伪说话人表示d,其计算公式为:
35、d=∑wspkdspk
36、进一步的,包括:
37、在语音合成阶段,除了利用语音和情绪特征的融合输入外,我们还对损失函数进行了调整。我们将生成的语音输入到一个情绪特征提取器中,这是一个被设计用来捕捉输入的情绪特征的网络,以获得情绪特征。我们将合成的语音情绪向量与原始语音的情绪向量进行了比较,从而迫使模型在对输入的反应中产生相同的情绪。我们所采用的损失函数的结构如下:
38、loss=lhifi-gan+λcos_sim(emoorig,emogen)
39、其中,emoorig和emogen分别表示输入语音的情感特征和合成语音的特征。λ控制情绪损失函数的权重。
40、进一步的,包括:
41、前述步骤(2.2)构建匿名池的说话人数量n=30,随机选择m=4个说话人来提供语音嵌入。
42、相较于现有技术,本发明采用以上技术方案的有益技术效果如下:
43、1.利用情感迁移技术将原始语音信号中的情感特征进行转换,使得转换后的语音信号在情感表达上与目标语音相似。
44、2.在特征空间中对原始语音信号的说话人特征进行插值,生成新的说话人特征,从而隐藏原始说话人的身份信息。
45、3.本方法采用预训练模型的自监督特征作为输入,能够很好的保存语音的语言信息,使得经过匿名化处理后的语言在能够满足后续使用的需求,如语音识别。
- 还没有人留言评论。精彩留言会获得点赞!