稀疏自适应多模态视听语音识别方法和系统
本发明涉及语音技术处理领域,尤其涉及一种基于transformer的稀疏自适应多模态视听语音识别方法。
背景技术:
1、随着计算机技术和人工智能的持续进步,视听语音识别(avsr)已成为提高自动语音识别(asr)在噪声环境下性能的关键技术。这种技术利用视觉信息来辅助声音数据的处理,从而有效地克服了传统语音识别在嘈杂环境中遇到的挑战。
2、最近,基于transformer的结构被用于对avsr的音频和视频序列进行建模,取得了不错的性能。transformer是一种端到端的基于自注意力的神经网络模型,通过自注意力机制,为不同位置的输入分配不同的注意力权重,其结构包括输入、编码器、解码器、输出四部分。输入序列经过编码器和解码器处理,通过线性变换和softmax函数得到输出概率分布,概率最大的单词为预测结果。然而,transformer结构使用的是全局注意力,在处理长序列时,计算注意力得分和注意力权重的复杂度会非常高,导致计算资源和内存占用过大。全局注意力允许每个位置关注序列中的所有其他位置,这会导致注意力过于分散,模型难以集中关注重要信息,在处理长序列数据时,序列中的位置可能只与其局部邻居有关,不需要关注远处的位置,过多的注意力可能会导致无关信息的干扰,进而导致模型性能下降,识别精度降低。另外,在自然条件下,外界存在一定的噪音,固定的注意力权重难以调整对视频信息的依赖,无法最优地利用音视频信息,从而影响模型的整体识别性能。
技术实现思路
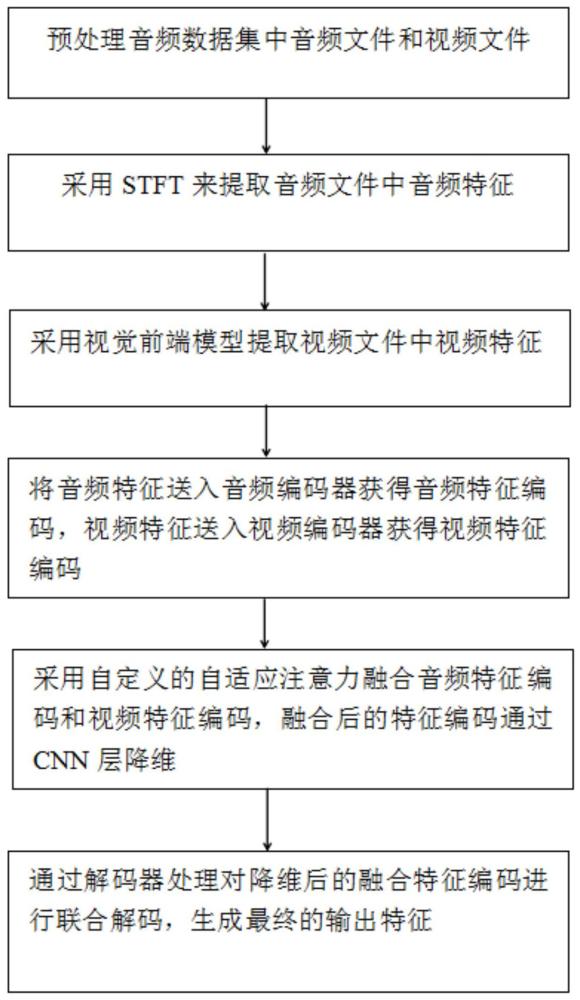
1、本发明针对现有视听语音识别利用transformer结构,但transformer结构难以集中关注重要信息,导致识别精度降低,且固定的注意力权重难以调整对视频信息的依赖,无法最优地利用音视频信息,从而影响会模型的整体识别性能的问题,提出一种基于transformer的稀疏自适应多模态视听语音识别方法,所述方法包括:
2、步骤s1:预处理音频数据集中音频文件和视频文件;
3、步骤s2:采用stft来提取音频文件中音频特征;
4、步骤s3:采用视觉前端模型提取视频文件中视频特征;
5、步骤s4:将音频特征送入音频编码器获得音频特征编码,视频特征送入视频编码器获得视频特征编码;
6、步骤s5:采用自定义的自适应注意力融合音频特征编码和视频特征编码,融合后的特征编码通过cnn层降维;
7、步骤s6:通过解码器对降维后的融合特征编码进行联合解码,生成最终的输出特征。
8、进一步的,还提出一种优选方式,所述步骤s1包括:
9、将获取到的音视频数据集使用ffmpeg工具进行分离,获取音频文件和视频文件;
10、提取视频文件中视频帧,将所述视频帧进行灰度处理,获取灰度图像;
11、剪裁灰度图像中人物嘴部区域,提取人物嘴部区域的roi区域,并对roi区域进行归一化处理,获取图像序列。
12、进一步的,还提出一种优选方式,所述步骤s2包括:
13、采用hamming窗函数仅保留stft的幅值部分提取音频文件中音频特征:
14、
15、其中,x(n)是输入信号,w(n)是窗口函数,m是时间帧的索引,r是帧移,n是fft点数,k是频率索引,n为时间索引,j为虚数单位;
16、通过1d cnn将音频特征降维,标记为,t为序列长度。
17、进一步的,还提出一种优选方式,所述步骤s3包括:
18、通过一个三维卷积块对输入视频数据进行初步的时空特征提取;
19、通过一个18层的resnet结构进一步提炼时空特征;
20、通过平均池化层处理提炼后的时空特征,生成每个视频帧的特征向量,标记为,t为序列长度。
21、进一步的,还提出一种优选方式,所述步骤s4中将音频特征送入音频编码器获得音频特征编码包括:
22、计算查询、键和值,通过查询和键的点积计算注意力得分;
23、将稀疏掩码sm应用于注意力得分,限制每个位置只能关注稀疏范围内的位置,获取稀疏注意力得分;
24、采用softmax函数处理稀疏注意力得分,获取注意力权重;
25、利用注意力权重对值矩阵v进行加权求和,得到输出,输出结果传递给前馈神经网络层,前馈神经网络层包括两个线性变换和一个激活函数relu,第一层线性变换,权重矩阵为和偏置,计算公式为:
26、
27、第二层线性变换,权重矩阵为和偏置,计算公式为:
28、
29、前馈网络的输出为:
30、
31、通过层归一化在每层的输出上进行归一化,计算公式为:
32、
33、其中,是output的均值,是output的方差,为一个小常数,和为偏移参数;
34、在前馈神经网络层和归一化层之间添加一个残差块,公式为:
35、
36、y为残差连接后的输出;
37、在归一化层后加入一层丢弃层,丢弃率为p,计算公式为:
38、
39、其中,m是与y维度相同的掩码矩阵,元素按概率p取0或1;
40、通过丢弃层处理后得到音频特征编码。
41、进一步的,还提出一种优选方式,所述步骤s5包括:
42、将音频特征编码和视频特征编码分别作为多头注意力的输入,得到音频对视频的注意力:
43、
44、其中,为将音频特征编码转换为查询向量的权重矩阵,为将视频特征编码转换为键向量的权重矩阵,为将视频特征编码转换为值向量的权重矩阵;
45、音频对视频的注意力得分为:
46、
47、其中,是模型的维度,为转置的视频特征键向量;
48、音频特征对视频特征的注意力权重为:
49、
50、得到音频特征对视频特征输出为:
51、
52、视频对音频的注意力:
53、
54、其中,为将视频特征编码转换为查询向量的权重矩阵,为将视频特征编码转换为键向量的权重矩阵,为将视频特征编码转换为值向量的权重矩阵;
55、视频对音频的注意力得分为:
56、
57、其中,为转置的音频特征键向量;
58、视频特征对音频特征的注意力权重为:
59、
60、得到视频特征对音频特征输出为:
61、
62、使用softmax函数对权重参数和进行归一化,得到两模态的权重:
63、
64、其中,为音频权重,为视频权重;
65、对权重进行加权融合:
66、
67、其中,为经过softmax后的音频权重,为经过softmax后的视频权重;
68、融合后的特征编码通过cnn层降维。
69、进一步的,还提出一种优选方式,所述方法还包括:采用宽度为50的beam search优化解码结果,并且在推理的过程中使用字符级语言模型修正新路径的概率。
70、基于同一发明构思,本发明还提出一种基于transformer的稀疏自适应多模态视听语音识别系统,所述系统包括:
71、预处理模块,用于预处理音频数据集中音频文件和视频文件;
72、音频特征提取模块,用于采用stft来提取音频文件中音频特征;
73、视频特征提取模块,用于采用视觉前端模型提取视频文件中视频特征;
74、编码模块,用于将音频特征送入音频编码器获得音频特征编码,视频特征送入视频编码器获得视频特征编码;
75、融合模块,用于采用自定义的自适应注意力融合音频特征编码和视频特征编码,融合后的特征编码通过cnn层降维;
76、输出模块,用于通过解码器对降维后的融合特征编码进行联合解码,生成最终的输出特征。
77、基于同一发明构思,本发明还提出一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机程序,当所述处理器运行所述存储器存储的计算机程序时,所述处理器执行根据上述任一项所述的一种基于transformer的稀疏自适应多模态视听语音识别方法。
78、基于同一发明构思,本发明还提出一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行如上述任一项所述的一种基于transformer的稀疏自适应多模态视听语音识别方法的步骤。
79、本发明的有益之处在于:
80、传统的transformer结构在处理视听语音识别时,无法有效集中注意力于关键信息,导致识别精度下降。全局注意力机制可能导致注意力分散,不利于提取重要特征。本发明所述的一种基于transformer的稀疏自适应多模态视听语音识别方法中,通过引入稀疏自适应注意力机制,允许模型根据输入数据的特点动态调整注意力权重,集中关注重要信息,从而提高识别精度。
81、传统transformer使用固定的注意力权重,无法有效应对现实中音视频数据的变化和噪声,导致模型在不同环境下的表现不佳。本发明中,采用自适应注意力机制,可以根据实际情况调整注意力权重,增强模型对音视频信息的适应能力,提高整体识别性能。
82、本发明所述的一种基于transformer的稀疏自适应多模态视听语音识别方法中,通过稀疏自适应注意力机制,能够动态调整注意力权重,集中关注视听信息中的关键信息,减少无关信息的干扰,从而提升识别精度。自适应注意力机制使得模型能够根据实际数据变化进行调整,提高了对噪声和环境变化的适应能力,增强了模型的鲁棒性。采用自适应注意力机制融合音频和视频特征,能够有效整合多模态信息,提高特征表示的全面性和准确性。cnn层进一步降维,有助于减小计算复杂度和提升处理效率。稀疏注意力机制减少了计算资源的消耗,使得模型在处理长序列和大规模数据时更为高效。这对于实际应用中的实时识别尤为重要。
83、本发明提出一种基于transformer的稀疏自适应多模态视听语音识别方法,能够大大减少计算和内存需求,动态调整两种模态的权重,使模型能够更好地捕捉局部依赖关系,更加高效地处理长序列数据。
84、本发明应用于人工智能领域。
- 还没有人留言评论。精彩留言会获得点赞!