语音识别方法和装置、电子设备及存储介质与流程
本技术涉及金融科技,尤其涉及一种语音识别方法和装置、电子设备及存储介质。
背景技术:
1、在现代通信和数据处理领域,准确识别和处理包含多个说话人的目标语音数据是一项重要任务。例如,在一个金融业务办理时,会产生由一个业务人员与多个业务办理对象进行交流会话的多说话人语音数据,针对这种语音数据,往往需要准确地识别各个说话人所描述的语音内容是什么。
2、针对这一需求,相关技术中的语音识别方法通常依赖于复杂的算法和模型,以从语音信号中提取有用的信息。然而,当目标语音数据包含多个说话人时,传统的语音识别系统往往难以区分和识别每个说话人的声音特征,会导致语音识别准确性下降。
技术实现思路
1、本技术实施例的主要目的在于提出一种语音识别方法和装置、电子设备及存储介质,旨在提高对包含多个说话人的语音的识别准确性。
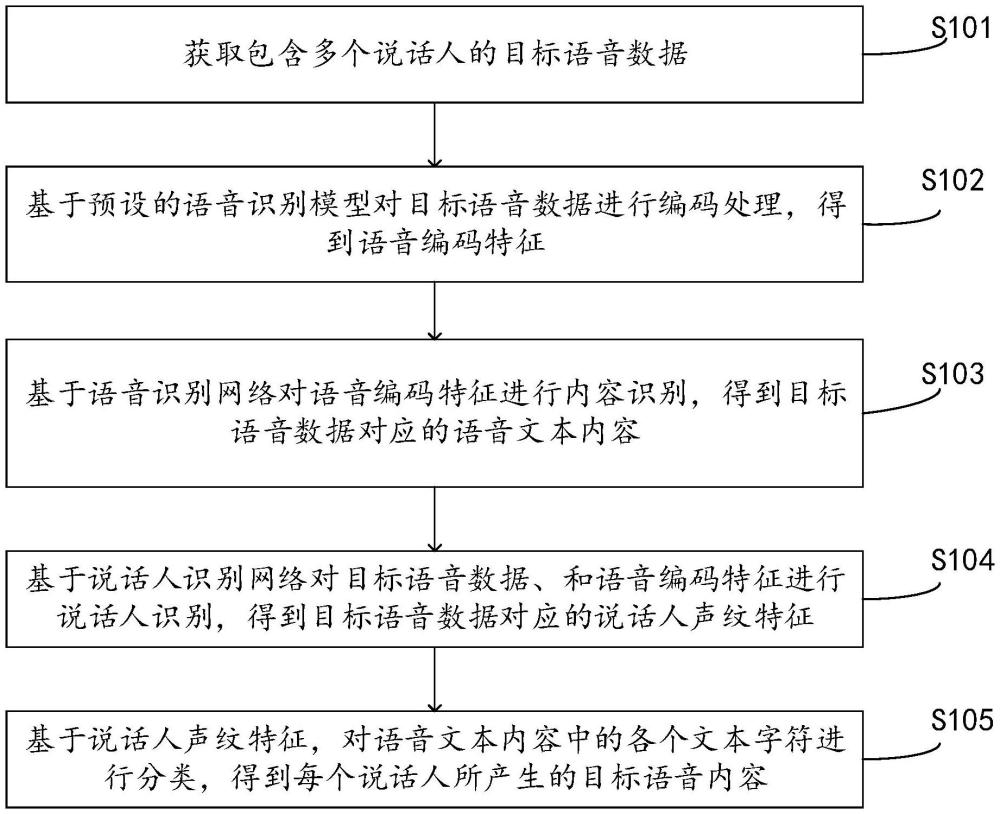
2、为实现上述目的,本技术实施例的第一方面提出了一种语音识别方法,所述方法包括:
3、获取包含多个说话人的目标语音数据;
4、基于预设的语音识别模型对所述目标语音数据进行编码处理,得到语音编码特征,其中,所述语音识别模型包括语音识别网络、和说话人识别网络;
5、基于所述语音识别网络对所述语音编码特征进行内容识别,得到所述目标语音数据对应的语音文本内容;
6、基于所述说话人识别网络对所述目标语音数据、和所述语音编码特征进行说话人识别,得到所述目标语音数据对应的说话人声纹特征;
7、基于所述说话人声纹特征,对所述语音文本内容中的各个文本字符进行分类,得到每个所述说话人所产生的目标语音内容,其中,所述目标语音内容由多个所述文本字符组成。
8、在一些实施例,所述语音识别网络包括第一解码器、第二解码器、第三解码器和特征变换网络;
9、所述基于所述语音识别网络对所述语音编码特征进行内容识别,得到所述目标语音数据对应的语音文本内容,包括:
10、基于所述第一解码器对所述语音编码特征进行特征对齐,得到第一语音解码特征;
11、基于所述第二解码器对所述语音编码特征进行音素特征识别,得到第二语音解码特征;
12、基于所述第三解码器对所述语音编码特征进行特征映射,得到第三语音解码特征;
13、对所述第一语音解码特征、所述第二语音解码特征和所述第三语音解码特征进行特征聚合,得到语音聚合特征;
14、基于所述特征变换网络对所述语音聚合特征进行特征变换,得到所述语音文本内容。
15、在一些实施例,所述说话人识别网络包括说话人编码器和说话人解码器;
16、所述基于所述说话人识别网络对所述目标语音数据、和所述语音编码特征进行说话人识别,得到所述目标语音数据对应的说话人声纹特征,包括:
17、对所述目标语音数据和所述语音编码特征进行特征拼接,得到目标拼接特征;
18、基于所述说话人编码器对所述目标拼接特征进行说话人特征提取,得到说话人编码特征;
19、基于所述说话人解码器对所述说话人编码特征进行说话人识别,得到所述说话人声纹特征。
20、在一些实施例,所述说话人声纹特征包括所述语音文本内容中的各个文本字符对应的子声纹特征;
21、所述基于所述说话人声纹特征,对所述语音文本内容中的各个文本字符进行分类,得到每个所述说话人所产生的目标语音内容,包括:
22、获取各个参考说话对象的参考声纹特征和参考对象标识;
23、针对各个所述文本字符,对所述子声纹特征与所述参考声纹特征进行声纹相似度计算,得到所述子声纹特征与各个所述参考声纹特征的声纹相似度;
24、将所述声纹相似度最大的所述参考声纹特征对应的所述参考对象标识作为所述文本字符的说话人标识,其中,所述说话人标识用于指示所述说话人的身份;
25、基于各个所述文本字符的说话人标识,将具有相同的所述说话人标识的所述文本字符划分到同一个文本字符组;
26、基于所述文本字符组,确定每个所述说话人所产生的目标语音内容。
27、在一些实施例,所述语音识别网络通过以下过程训练得到:
28、获取样本音频数据、和所述样本音频数据对应的标注文本数据;
29、基于预设的第一原始网络对所述样本音频数据的样本音频编码特征进行特征对齐,得到第一样本解码特征,并确定基于所述第一样本解码特征生成所述标注文本数据的第一概率;
30、基于所述第一原始网络对所述样本音频编码特征进行音素特征识别,得到第二样本解码特征,并确定基于所述第二样本解码特征生成所述标注文本数据的第二概率;
31、基于所述第一原始网络对所述样本音频编码特征进行特征映射,得到第三样本解码特征,并确定基于所述第三样本解码特征生成所述标注文本数据的第三概率;
32、基于所述第一概率、所述第二概率和所述第三概率,训练所述第一原始识别网络,得到所述语音识别网络。
33、在一些实施例,所述说话人识别网络通过以下过程训练得到:
34、获取多个样本语音帧、和各个所述样本语音帧对应的样本说话人声纹特征;
35、基于所述样本语音帧、和所述样本说话人声纹特征构造样本对,所述样本对包括由所述样本语音帧、和所述样本语音帧对应的样本说话人声纹特征构成的正样本对、以及由所述样本语音帧、和不与所述样本语音帧对应的样本说话人声纹特征构成的负样本对;
36、将所述正样本对输入至预设的第二原始网络进行说话人识别,得到第一预测声纹特征,并确定所述第一预测声纹特征与所述正样本对中的所述样本说话人声纹特征的第一相似度;
37、将所述负样本对输入至所述第二原始网络进行说话人识别,得到第二预测声纹特征,并确定所述第二预测声纹特征与所述负样本对中的所述样本说话人声纹特征的第二相似度;
38、基于多个所述样本语音帧的所述第一相似度和所述第二相似度,训练所述第二原始网络,得到所述说话人识别网络。
39、在一些实施例,所述获取包含多个说话人的目标语音数据,包括:
40、获取包含多个说话人的原始语音数据;
41、对所述原始语音数据进行去噪处理,得到去噪语音数据;
42、对所述去噪语音数据进行傅里叶变换,得到语音频域数据;
43、对所述语音频域数据进行梅尔滤波,得到所述目标语音数据。
44、为实现上述目的,本技术实施例的第二方面提出了一种语音识别装置,所述装置包括:
45、获取单元,用于获取包含多个说话人的目标语音数据;
46、编码单元,用于基于预设的语音识别模型对所述目标语音数据进行编码处理,得到语音编码特征,其中,所述语音识别模型包括语音识别网络、和说话人识别网络;
47、内容识别单元,用于基于所述语音识别网络对所述语音编码特征进行内容识别,得到所述目标语音数据对应的语音文本内容;
48、说话人识别单元,用于基于所述说话人识别网络对所述目标语音数据、和所述语音编码特征进行说话人识别,得到所述目标语音数据对应的说话人声纹特征;
49、字符分类单元,用于基于所述说话人声纹特征,对所述语音文本内容中的各个文本字符进行分类,得到每个所述说话人所产生的目标语音内容,其中,所述目标语音内容由多个所述文本字符组成。
50、为实现上述目的,本技术实施例的第三方面提出了一种电子设备,所述电子设备包括存储器、处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述第一方面所述的语音识别方法。
51、为实现上述目的,本技术实施例的第四方面提出了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面所述的语音识别方法。
52、本技术提出的语音识别方法和装置、电子设备及存储介质,其通过获取包含多个说话人的目标语音数据;基于预设的语音识别模型对目标语音数据进行编码处理,得到语音编码特征,能将原始语音信号转换成一系列语音编码特征,并通过语音编码特征表示语音信号的关键属性(如音高、音强和音色等)。进一步地,基于语音识别网络对语音编码特征进行内容识别,得到目标语音数据对应的语音文本内容,将语音编码特征映射到对应的语音文本内容,从而生成目标语音数据的文本表示,能够实现对目标语音数据的语音内容的准确识别。进一步地,基于说话人识别网络对目标语音数据、和语音编码特征进行说话人识别,得到目标语音数据对应的说话人声纹特征,能够捕捉到目标用于数据的说话人的声纹特点。最后,基于说话人声纹特征,对语音文本内容中的各个文本字符进行分类,得到每个说话人所产生的目标语音内容,能够对每个说话人所产生的目标语音内容准确地识别和区分,能够提高对包含多个说话人的语音的识别准确性。
- 还没有人留言评论。精彩留言会获得点赞!