音频处理方法、装置、系统及存储介质与流程
本公开涉及数据处理,尤其涉及音频处理方法、装置、系统及存储介质。
背景技术:
1、随着如智慧医疗和金融领域等各个服务领域的语音智能化发展需求,音频处理已成为一种日益增长的应用趋势,而音频编解码技术在音频的数字信号处理中具有重要的应用价值。为了确保音频数据可以高效地存储、传输和播放,在当前音频编解码过程中,通常将音频信号从模拟转换为数字,并通过压缩和编码减小数据大小,然后通过解码和重构恢复为模拟信号,以实现将音频信号转化为模拟信号输出。因上述模拟信号是基于压缩和编码减小数据大小这一信号压缩处理技术得到的,会过滤一些频段使用较少的比特数信号,从而导致输出的音频失真严重,特别是在比特数极低的情况下(例如16千比特每秒或更低),上述音频编解码方式会使输出的音频出现明显的失真,极大地影响听觉效果,不具有实用价值。
技术实现思路
1、本发明提供一种音频处理方法、装置、系统及存储介质,以至少解决相关技术中输出的音频失真严重的问题。本发明的技术方案如下:
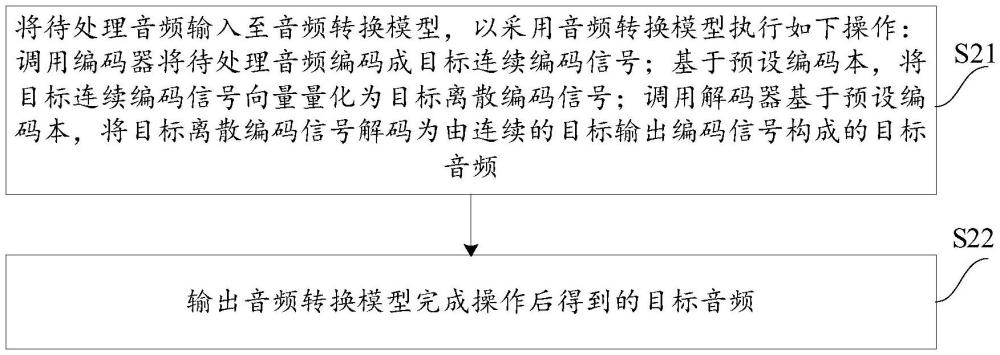
2、根据本发明实施例的第一方面,提供了一种音频处理方法,该方法包括:将待处理音频输入至音频转换模型,以采用音频转换模型执行如下操作:调用编码器将待处理音频编码成目标连续编码信号;基于预设编码本,将目标连续编码信号向量量化为目标离散编码信号;调用解码器基于预设编码本,将目标离散编码信号解码为由连续的目标输出编码信号构成的目标音频;其中,预设编码本包括连续编码信号与离散编码信号之间的关联映射关系,音频转换模型是以重构损失、码本损失和编码器和解码器的编解码的保持损失为约束目标训练而成的;输出音频转换模型完成操作后得到的目标音频。
3、在一种实现方式中,重构损失表征音频转换模型输入的输入样本音频与音频转换模型对应输出的输出音频之间的音频信号损失;码本损失表征在编码器的第一网络参数和解码器的第二网络参数确定的情况下,编码器输出的连续编码信号与基于预设编码本向量量化处理后的离散编码信号之间的编码损失;保持损失表征在预设码本中表征连续编码信号与离散编码信号之间关联映射关系的各个码字对应的码字值确定的情况下,编码器输出的连续编码信号与基于预设编码本向量量化处理后的离散编码信号之间的编码损失。
4、另一种实现方式中,约束目标包括第一约束目标和第二约束目标;在将待处理音频输入至音频转换模型之前,该方法还包括:交替执行以下训练过程,直至得到满足第一约束目标的预设编码本和满足第二约束目标的第一网络参数下的编码器和第二网络参数下的解码器:以重构损失小于第一损失阈值和码本损失小于第二损失阈值为第一约束目标,对预设编码本中表征连续编码信号与离散编码信号之间关联映射关系的各个码字对应的码字值进行训练;以及,以重构损失小于第一损失阈值和保持损失小于第三损失阈值为第二约束目标,对编码器的第一网络参数和解码器的第二网络参数进行训练。
5、另一种实现方式中,以重构损失小于第一损失阈值和码本损失小于第二损失阈值为第一约束目标,对预设编码本中表征连续编码信号与离散编码信号之间关联映射关系的各个码字对应的码字值进行训练,包括:当码本损失大于或等于第二损失阈值时,从各个码字中,确定出离散编码信号与连续编码信号之间信号差异大于或等于第一预设差异的目标码字;基于目标码字对应的码字值与相邻码字之间所表征的线性关系,确定表征目标码字的码字值的变化趋势的第一梯度;根据第一梯度,对应调整目标码字的码字值。
6、另一种实现方式中,根据第一梯度,对应调整目标码字的码字值,包括:在第一梯度大于或等于0时,将目标码字的码字值调小;在第一梯度小于0时,将目标码字的码字值调大。
7、另一种实现方式中,以重构损失小于第一损失阈值和保持损失小于第三损失阈值为第二约束目标,对编码器的第一网络参数和解码器的第二网络参数进行训练,包括:按照编码器输出的连续编码信号之间的变化趋势的第二梯度,确定对连续编码信号向量量化处理后的离散编码信号的第三梯度;在保持损失大于或等于第三损失阈值时,若连续编码信号与对应的样本连续编码信号的信号损失大于第四损失阈值,根据第二梯度与第一网络参数之间映射关系,调整编码器的第一网络参数;以及,若离散编码信号与对应的样本离散编码的信号损失大于第五损失阈值,根据第三梯度与第二网络参数之间映射关系,调整解码器的第二网络参数。
8、另一种实现方式中,以重构损失小于第一损失阈值和码本损失小于第二损失阈值为第一约束目标,对预设编码本中表征连续编码信号与离散编码信号之间关联映射关系的各个码字对应的码字值进行训练,包括:在重构损失大于或等于第一损失阈值和/或码本损失大于或等于第二损失阈值时,对预设编码本中各个码字对应的码字值进行调整;以重构损失小于第一损失阈值和保持损失小于第三损失阈值为第二约束目标,对编码器的第一网络参数和解码器的第二网络参数进行训练,包括:在重构损失大于或等于第一损失阈值和/或保持损失大于或等于第三损失阈值,对第一网络参数和第二网络参数进行调整。
9、根据本发明实施例的第二方面,提供了一种音频处理装置,该音频处理装置包括:输入单元,用于将待处理音频输入至音频转换模型,以采用音频转换模型执行如下操作:调用编码器将待处理音频编码成目标连续编码信号;基于预设编码本,将目标连续编码信号向量量化为目标离散编码信号;调用解码器基于预设编码本,将目标离散编码信号解码为由连续的目标输出编码信号构成的目标音频;其中,预设编码本包括连续编码信号与离散编码信号之间的关联映射关系,音频转换模型是以重构损失、码本损失和编码器和解码器的编解码的保持损失为约束目标训练而成的;输出单元,用于输出音频转换模型完成操作后得到的目标音频。
10、根据本发明实施例的第三方面,提供了一种音频处理系统,该系统包括编码器、解码器和预设编码本以及该系统设置有音频转换模型,该系统被配置为执行如第一方面及其任一种可能的实现方式的音频处理方法。
11、根据本发明实施例的第四方面,提供了一种电子设备,包括:处理器和用于存储处理器可执行指令的存储器;其中,处理器被配置为执行可执行指令,以实现如第一方面及其任一种可能的实现方式的音频处理方法。
12、根据本发明实施例的第五方面,提供了一种计算机可读存储介质,计算机可读存储介质上存储有指令,当计算机可读存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行如第一方面及其任一种可能的实现方式的音频处理方法。
13、根据本公开实施例的第六方面,提供一种计算机程序产品,计算机程序产品包括计算机指令,当计算机指令在电子设备上运行时,使得电子设备执行上述第一方面及其任一种可能的实现方式的音频处理方法。
14、本发明的实施例提供的技术方案至少带来以下有益效果:直接依据音频转换模型将待处理音频直接转化为输出的目标音频,实现简单、易操作,无需额外的信号处理模块,减少了硬件成本和操作流程。采用音频转换模型将待处理音频直接转化为目标音频的过程中,基于预设编码本,将编码器中的目标连续编码信号向量量化为目标离散编码信号,以保证能对原音频中各个频段的音频信号转换成对应的目标离散编码信号,从而保证输入至解码器的目标离散编码信号能更加完整地表征原始音频信息,以使解码器依据预设编码本能更好地还原原始音频信息,从而保证输出音频更加真实。同时,音频转换模型是以重构损失、码本损失和所述编码器和所述解码器的编解码的保持损失三个维度约束目标训练而成的,进而保证了编码器、解码器和预设编码本的精准度,从而提高了音频转换模型的音频转换精度。
15、上述音频信号转换过程中是基于音频转换模型将输出的待处理音频直接转换还原为目标音频,并不是相关技术中依赖信号处理过程对信号过滤和压缩,能更好地还原和保留原始音频的音频信息,从而减少输出的音频失真,提高输出音频的听觉效果。
16、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
- 还没有人留言评论。精彩留言会获得点赞!