一种基于Chat-TTS模型的自然语音阅读方法及系统与流程
本发明涉及语音阅读,具体的说是一种基于chat-tts模型的自然语音阅读方法及系统。
背景技术:
1、传统的电子阅读器主要依赖于文字显示,缺乏语音交互和情感表达,难以满足用户的个性化阅读需求。近年来,随着人工智能技术的快速发展,chat-tts模型(聊天式文本到语音合成)技术逐渐成熟,能够根据文本内容生成自然流畅的语音,并具备情感表达能力。chat-tts模型是一个专门为对话场景设计的文本生成语音模型,它支持多种语言,包括英语和中文,最大的模型采用了10万小时的中英文数据进行训练,在huggingface中开源的版本为4万小时训练且未sft的版本。为确保声音合成的高质量和自然度,chat-tts模型采用了多种先进的技术,例如神经网络、注意力机制、情感表达和风格迁移等。
2、jessibuca.js是一个基于webassembly的高性能web播放器,支持多种音频格式,包括pcm格式。pcm格式是一种未经压缩的音频格式,能够保留音频的原始信息,保证音质的高保真度。jessibuca.js通过webassembly技术将c++代码编译成webassembly模块,在浏览器中运行,从而实现高性能的音频播放。
3、然而,现有的语音阅读器在功能、操作便捷性和用户体验方面仍有待提升。例如,一些语音阅读器只能将文本转换为单调的语音,缺乏情感表达能力,一些语音阅读器无法实现文本与语音的同步播放,影响用户的阅读体验;同时一些语音阅读器操作复杂,难以上手。
技术实现思路
1、本发明针对目前技术发展的需求和不足之处,提供一种基于chat-tts模型的自然语音阅读方法及系统,为用户带来沉浸式的阅读体验,并支持指定时长音频缓存,满足不同用户的需求。
2、第一方面,本发明提供一种基于chat-tts模型的自然语音阅读方法,解决上述技术问题采用的技术方案如下:
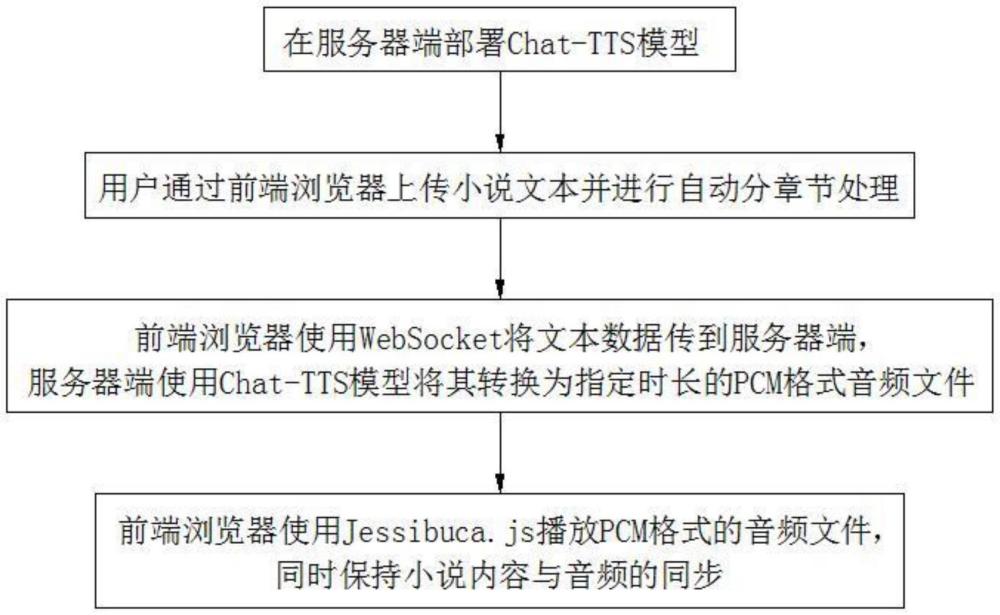
3、一种基于chat-tts模型的自然语音阅读方法,其包括如下步骤:
4、s1、在服务器端部署chat-tts模型;
5、s2、用户通过前端浏览器上传小说文本并进行自动分章节处理;
6、s3、前端浏览器使用websocket将步骤s2输出的文本数据传到服务器端,服务器端使用chat-tts模型将小说文本转换为指定时长的pcm格式音频文件;
7、s4、前端浏览器使用jessibuca.js播放pcm格式的音频文件,同时保持小说内容与音频的同步。
8、可选的,执行步骤s1,在服务器端部署chat-tts模型,具体部署流程如下:
9、s1.1、准备服务器环境:确保服务器具备的计算资源和存储空间满足chat-tts模型的运行需求,同时,安装必要的操作系统和依赖库;
10、s1.2、下载chat-tts模型:从官方渠道获取chat-tts模型,并解压到服务器指定目录;
11、s1.3、配置模型参数:根据服务器硬件配置和实际需求,调整chat-tts模型的参数,以优化语音合成效果;
12、s1.4、部署模型:将chat-tts模型部署到服务器端,并确保chat-tts模型能够正常运行。
13、可选的,执行步骤s2,用户通过前端浏览器上传小说文本并进行自动分章节处理,具体实现操作如下:
14、s2.1、通过前端浏览器的web页面上传小说;
15、s2.2、前端浏览器利用自然语言处理技术,对上传的小说进行自动分章节处理:首先读取小说的文本内容,分析段落结构;随后根据章节标题和段落长度,自动识别章节边界,生成章节目录,实现自动分章节。
16、可选的,执行步骤s3,前端浏览器使用websocket将步骤s2输出的文本数据传到服务器端,服务器端使用chat-tts模型将小说文本转换为指定时长的pcm格式音频文件,具体实现操作如下:
17、s3.1、前端浏览器使用websocket协议与服务器端建立连接,实现实时数据传输;
18、s3.2、用户选择小说章节后,前端浏览器将选中的文本数据通过websocket发送到服务器端;
19、s3.3、服务器端根据用户指定时长缓存音频:首先接收前端浏览器传输过来的文本数据,随后使用chat-tts模型将文本转换为指定时长的pcm格式音频文件,最后将生成的音频文件缓存到服务器端。
20、可选的,执行步骤s4,前端浏览器使用jessibuca.js播放pcm格式的音频,同时保持小说内容与音频的同步,具体实现操作如下:
21、使用jessibuca.js播放器播放服务器端缓存的pcm格式音频文件;
22、播放过程中,通过音频播放控制,查看播放进度、调节播放速度和播放音量,满足用户的个性化需求;
23、播放过程中,监听音频播放进度,实时更新小说内容的滚动位置;支持用户点击小说内容,实现音频的跳转播放。
24、第二方面,本发明提供一种基于chat-tts模型的自然语音阅读系统,解决上述技术问题采用的技术方案如下:
25、一种基于chat-tts模型的自然语音阅读系统,其包括:
26、模型部署模块,用于将chat-tts模型部署在服务器端;
27、上传分节模块,用于辅助用户通过前端浏览器上传小说文本并进行自动分章节处理;
28、传输调用模块,用于将前端浏览器输出的文本数据传到服务器端,并调用chat-tts模型将小说文本转换为指定时长的pcm格式音频文件;
29、缓存传输模块,用于将chat-tts模型转换输出的pcm格式音频文件缓存在服务器端,并传输至前端浏览器;
30、音频播放模块,用于使用jessibuca.js播放pcm格式的音频文件,同时保持小说内容与音频的同步。
31、可选的,所涉及模型部署模块将chat-tts模型部署在服务器端的流程如下:
32、准备服务器环境:确保服务器具备的计算资源和存储空间满足chat-tts模型的运行需求,同时,安装必要的操作系统和依赖库;
33、下载chat-tts模型:从官方渠道获取chat-tts模型,并解压到服务器指定目录;
34、配置模型参数:根据服务器硬件配置和实际需求,调整chat-tts模型的参数,以优化语音合成效果;
35、部署模型:将chat-tts模型部署到服务器端,并确保chat-tts模型能够正常运行。
36、可选的,所涉及上传分节模块具体包括:
37、上传单元,用于辅助用户通过前端浏览器的web页面上传小说文本;
38、分节单元,用于利用自然语言处理技术,对上传的小说进行自动分章节处理,具体过程包括:首先读取小说的文本内容,分析段落结构;随后根据章节标题和段落长度,自动识别章节边界,生成章节目录,实现自动分章节。
39、可选的,所涉及传输调用模块具体包括:
40、连接单元,用于使用websocket协议建立前端浏览器与服务器端的连接,实现实时数据传输;
41、传输单元,用于将用户选定的文本内容通过websocket发送到服务器端;
42、调用单元,用于调用服务器端部署的chat-tts模型,chat-tts模型将发送过来的文本内容转换为指定时长的pcm格式音频文件。
43、可选的,所涉及音频播放模块包括:
44、音频播放单元,用于使用jessibuca.js播放pcm格式的音频文件;
45、音频控制单元,用于查看和调节播放进度、调节播放速度和播放音量,满足用户的个性化需求;
46、音频监听单元,用于监听音频播放进度,实时更新小说内容的滚动位置;
47、音频跳转单元,用于根据用户的点击操作,实现音频的跳转播放。
48、本发明的一种基于chat-tts模型的自然语音阅读方法及系统,与现有技术相比具有的有益效果是:
49、1、本发明可以为用户带来沉浸式的阅读体验,并支持根据需求调整音频缓存时长,以满足不同用户的需求;
50、2、本发明借助chat-tts和javascript的易于学习、使用和丰富的api,可以简化大量业务无关的代码,代码逻辑更简单清晰,有利于编码人员开发工作;通过chat-tts技术能够生成自然流畅、具备情感表达能力的语音,为用户提供沉浸式的阅读体验;jessibuca.js通过webassembly技术可以实现高性能的音频播放,为用户提供流畅的语音阅读体验。
- 还没有人留言评论。精彩留言会获得点赞!