一种面向DAS系统的高质量音频生成方法
本发明涉及音频合成和分析、分布式光纤声学传感领域,尤其涉及一种面向das系统的高质量音频生成方法。
背景技术:
1、分布式声学传感(distributed acoustic sensing,以下简称das)系统在近年来得到了广泛应用,通过在不同位置分布多个声学传感器,das系统能够对环境声音进行全面监测。然而,das系统采集到的音频数据质量参差不齐,通常受到环境噪声、传感器质量和安装位置等因素的影响,导致音频信号存在大量噪声和失真。这种低质量的音频数据在后续处理和应用中面临诸多挑战,尤其是在需要高质量音频输入的场景中,其表现尤为不理想。高质量音频意味着音频中的信号强度大于噪声强度且失真度较低,听觉上感受良好。
2、传统的音频处理方法依赖于大量的人工干预和复杂的预处理步骤,包括降噪、信号增强和特征提取等,这些方法不仅耗时费力,而且难以保证处理效果的一致性。尤其是在面对低质量音频数据时,这些传统方法的局限性更加明显,无法有效提升音频的整体质量。另一方面,现有的一些机器学习和深度学习方法在音频处理领域取得了一定进展,但这些方法通常需要大量高质量的音频数据进行训练,从数据中学习到清晰和准确的音频特征,在音频处理领域,收集大量高质量的音频数据是一个耗时且成本高昂的过程,且这些方法对于低质量音频数据的处理效果仍有待提高。
技术实现思路
1、针对现有技术的不足,本发明提出一种面向das系统的高质量音频生成方法。
2、具体技术方案如下:
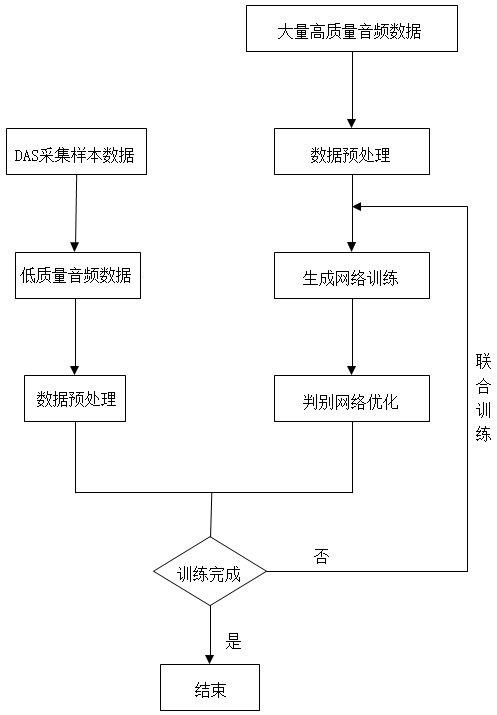
3、一种面向das系统的高质量音频生成方法,包括以下步骤:
4、s1:针对das系统的多个光纤点进行数据采集和处理得到低质量音频数据,对其进行预处理及特征提取,得到多个短时间帧的音高特征-梅尔频谱特征数据对,集合得到数据集d1;
5、s2:获取高质量音频数据,采用s1的方法对其进行预处理及特征提取,得到数据集d2;
6、s3:根据d2提取出的声音特征,构建高质量音频生成模型,高质量音频生成模型包括多通道输入的生成网络和判别网络;所述生成网络根据线性插值函数和音高特征-梅尔频谱特征数据对得到与梅尔频谱特征长度匹配的音高特征,基于此生成多通道的信号模板后,进行下采样和上采样,其中第一层上采样卷积层的输入为下采样模块的输出与卷积后的梅尔频谱特征的拼接结果,后续上采样卷积层的输入为上一层下采样卷积层的输出和上采样卷积层的输出的拼接结果;所述判别网络包括用于捕捉音频信号的周期性特征的多周期判别器,以及用于在不同频率上分析音频信号细节的多分辨率判别器;
7、s4:以d2为训练集训练生成网络,学习高质量音频的先验分布;判别网络对生成网络的生成信号进行判断,并根据判断结果计算损失函数,对生成网络与判别网络进行优化;判断损失函数是否小于设定阈值,若否,则重复训练过程;反之,则执行s5;
8、s5:以数据集d1和d2为训练集,采用s4的方法对生成网络和判别网络进行联合训练,最终得到训练好的高质量音频生成模型;
9、s6:将待处理的低质量音频进行预处理和特征提取后,输入训练好的高质量音频生成模型,得到高质量音频。
10、进一步地,所述s1中,预处理及特征提取通过如下子步骤实现:
11、s1.1:对音频信号进行幅度标准化,使其具有统一的音量水平;对音频信号进行均值归一化,得到归一化后的音频信号xnorm(n);
12、使用滑动窗口法将xnorm(n)分割成多个短时间帧,其中,第m个短时间帧信号以xn(m)表示;
13、s1.2:采用改进的音高提取算法提取各短时间帧中音频信号的音高特征f0;改进的音高提取算法包括语音端点检测和高频信号增强,具体如下:
14、s1.2.1、语音端点检测:计算输入的短时间帧信号的短时能量和零交叉率,再根据设定的阈值判断该短时间帧信号是否为音频信号;
15、第m个短时间帧信号的短时能量e(m)的表达式如下:
16、;
17、式中,r表示重叠率,表示第m个短时间帧的样本点,n表示第m个短时间帧的帧长度;
18、短时能量的阈值表达式为:
19、;
20、式中,ρ是小于1的比例系数,由人为设定;
21、第m个短时间帧信号的零交叉率z(m)的表达式如下:
22、;
23、式中,sgn( )表示符号函数,如果输入值为正,则输出sgn( )为1;如果输入值为零或负,则输出sgn( )为0;
24、零交叉率的阈值zthreshold由人为设定;
25、短时能量的阈值和零交叉率的阈值进行端点检测,若vad(m)为1,则判定第m帧短时间帧信号为音频信号,若vad(m)为0,则判定第m帧短时间帧信号为非音频信号,并将该短时间帧信号舍去;端点检测的判断表达式如下:
26、;
27、s1.2.2、高频信号增强:对于通过语音端点检测的音频信号,使用预加重滤波器强调高频部分,再进行自相关计算,检测信号中的周期性;根据自相关函数的最大值对应的最佳周期,计算音高特征f0,表达式如下:
28、;
29、;
30、;
31、式中,xpe表示预加重后的音频信号,α表示预加重系数;r(τ)表示自相关函数,τ表示时间延迟,τbest表示自相关函数最大时对应的最佳周期;
32、s1.3、使用梅尔频谱表示音高特征f0:对s1.2.2处理后的音频信号进行短时傅里叶变换,并将频谱映射到梅尔尺度上,得到梅尔频谱特征,表达式如下:
33、;
34、;
35、式中,x(f,t)表示在频率f和时间t下的短时傅里叶变换结果,w[ ]表示窗函数,n0表示窗函数起始位置,表示短时傅里叶变换的复指数项;fmel表示梅尔频谱特征;
36、每个短时间帧得到一组f0和梅尔频谱特征fmel,所有短时间帧的音高特征-梅尔频谱特征数据对的集合为数据集d1。
37、进一步地,所述生成网络包括:音高插值模块、模板生成模块、下采样模块、梅尔频谱卷积模块、上采样模块、leakyrelu激活函数、tanh激活函数;
38、所述音高插值模块的输入为音高特征-梅尔频谱特征数据对,通过线性插值函数,基于音高特征f0的时间索引和f0特征值,在梅尔频谱图的时间索引上进行插值,得到与梅尔频谱特征长度匹配的音高特征,表达式如下:
39、;
40、式中,ti为原始音高特征的时间索引,f0(ti)为时间索引ti处的f0特征值,tmel为梅尔频谱图的时间索引;
41、所述模板生成模块用于根据与梅尔频谱特征长度匹配的音高特征生成一个多通道的信号模板,表达式如下:
42、;
43、;
44、式中,ta(t)表示第a通道的信号模板,a(t)表示振幅,表示第a通道的相位;表示多通道信号模板的集合,c为通道数,a=1,2,…,c;
45、所述下采样模块包括三个7×7下采样卷积层,按顺序其膨胀率分别为1、3、5;每个下采样卷积层后使用leakyrelu激活函数;
46、所述梅尔频谱卷积模块包括一个带权重归一化的一维7×7卷积层,填充为3,其输入的梅尔频谱特征的长度与输出的卷积后的梅尔频谱特征的长度一致;
47、所述上采样模块包括一个膨胀率为1的3×3上采样卷积层,一个膨胀率为3的7×7上采样卷积层,一个膨胀率为5的11×11上采样卷积层,并在每个上采样卷积层后使用leakyrelu激活函数;第一层上采样卷积层的输入为下采样模块的输出与卷积后的梅尔频谱特征的拼接结果;
48、相同层的下采样卷积层和上采样卷积层通过拼接层跳越连接,所述拼接层用于将两个输入在通道维度上拼接;拼接层的两个输入分别为对应层数的下采样卷积层的输出、对应层数的上采样卷积层的输出,本层拼接层的输出作为下一层上采样卷积层的输入。
49、进一步地,所述多周期判别器包括:频谱转化模块、卷积层、leakyrelu激活函数;所述频谱转换模块用于通过短时傅里叶变换将时间域信号转换为频域信号;所述卷积层包括5个3×3卷积层,并在每个卷积层后使用leakyrelu激活函数,其中初始卷积层用于将输入的频谱图从单通道扩展到32通道,保持特征图的空间维度;中间三个卷积层用于逐层将特征图的通道数保持在32,以逐步减小特征图的高度,逐层提取更深层次的特征;最后一个卷积层将输出的通道数减少到1,以整合特征;
50、所述多分辨率判别器包括:周期处理模块、卷积层、leakyrelu激活函数;所述周期处理模块用于根据周期列表中的周期,使时间长度能被设定的周期整除,以避免信息丢失;此过程包括反射填充以调整长度,并将一维信号转换为二维格式;卷积层包括5个5×5卷积层,并在每个卷积层后使用leakyrelu激活函数,其中初始卷积层,将输入信号从单通道扩展到64通道,保持特征图的空间维度;中间三个卷积层用于逐层将特征图的通道数提升到128、256和512,以提取深层次的特征信息;最后一个卷积层将输出通道数减少到1,以整合特征。
51、进一步地,所述s4中,以d2为训练集训练生成网络,具体通过如下子步骤实现:
52、s4.1.1:根据d2中的音高特征f0,确定f0的时间索引,并得到与梅尔频谱特征长度匹配的音高特征;使用模板生成模块,根据梅尔频谱特征长度匹配的音高特征生成一个多通道的信号模板;
53、s4.1.2:将多通道的信号模板进行下采样,每次下采样后,信号的长度减半;
54、s4.1.3:对梅尔频谱特征进行卷积,将s4.1.2、得到的下采样后的特征与卷积后的梅尔频谱特征进行拼接,得到拼接后的特征c;
55、s4.1.4:对特征c进行上采样,在第一层上采样时,将特征c与第一层上采样的特征进行拼接,作为下一层上采样的输入;之后的上采样阶段,将本层上采样的特征与对应层数的下采样的特征进行拼接,作为下一层上采样的输入;在最后一次上采样并完成拼接后,使用tanh作为非线性激活函数,将输出值限制在(-1,1)范围内。
56、进一步地,所述s4中,使用判别网络对生成网络的生成信号进行判断,具体如下:
57、多通道的判别网络用于同时处理多个光纤点的音频数据,其输入原始信号为:
58、;
59、式中,表示第c个通道经过生成网络的输出;
60、将生成的音频信号和真实的高质量音频信号分别输入到多分辨率判别器中,进行判别和特征提取,首先将两种多通道输入数据分别转换为频谱图,然后通过三个卷积层和leakyrelu激活函数,最后通过一个卷积层并展平输出;并且根据设定的分辨率数组进行重复,针对不同的分辨率重复执行;表达式如下:
61、;
62、;
63、;
64、式中,dγ表示多分辨率判别器的第γ个卷积层,cin_3表示多分辨率判别器的第γ个卷积层的输入通道数,cout_3表示多分辨率判别器的第γ个卷积层的输出通道数,kγ_3表示多分辨率判别器的第γ个卷积层卷积核的大小,sγ_3表示多分辨率判别器的第γ个卷积层的卷积步长;ymrd为多分辨率判别器最后的输出,根据ymrd中的第二维度判断信号的真实性,若第二维度中的值为0,则信号为假,为1,则信号为真;
65、同时,将生成的音频信号和真实的高质量音频信号分别输入到多周期判别器中,进行判别和特征提取,输入数据首先根据判别器的周期性进行处理,其中包括对输入数据进行填充以确保其长度符合周期性;若输入长度不是周期peroid的整数倍,则通过反射填充计算所需的填充量npad,表达式如下:
66、;
67、填充后,输入数据重新排列为二维形式,表达式如下:
68、;
69、式中,view为调整维度的函数,x表示填充后的输入数据;
70、接着,输入数据通过三个卷积层和leakyrelu激活函数进行处理,其表达式如下:
71、;
72、;
73、式中,dp表示多周期判别器的第p个卷积层,cin表示多周期判别器的输入通道数,cout表示多周期判别器的输出通道数,kp表示多周期判别器的第p个卷积层卷积核的大小,sp表示多周期判别器的第p个卷积层的卷积步长;根据ympd中的第二维度判断信号的真实性,若第二维度中的值为0,则信号为假,为1,则信号为真;
74、此过程由设定的周期数组进行控制,该过程重复执行m次,m为周期数组中的元素个数;每个周期的多周期判别器用于捕获与该周期相对应的时间序列特征,从而允许网络在多个时间尺度上分析输入信号。
75、进一步地,所述s4中,使用损失函数,对生成网络与判别网络进行优化,判断损失函数是否小于设定阈值,若是,则结束训练,执行s5;反之则重复训练;
76、生成网络的损失函数表达式如下:
77、;
78、式中,w为梅尔频谱图损失的权重,w大于1;lmel为基于梅尔频谱图的损失,lenv为基于包络的损失;
79、基于梅尔频谱图的损失lmel为:
80、;
81、;
82、式中,表示高质量音频信号的梅尔频谱图的第个尺度的梅尔变换,表示生成网络输出的梅尔频谱图的第个尺度的梅尔变换;为第个尺度的梅尔频谱损失,表示平滑l1损失函数;
83、基于包络的损失lenv为:
84、;
85、;
86、;
87、式中,y为高质量音频信号,为生成网络输出的信号,e(y)为y的包络,为的包络,e(-y)为y的负信号的包络,e(-)为的负信号的包络;表示最大池化函数,表示l1损失函数,计算两个信号包络之间的绝对差值之和;
88、判别网络的损失函数ldiscriminator将基于多周期判别器的损失lmpd和基于多分辨率判别器lmrd的损失相结合,表达式如下:
89、;
90、;
91、;
92、式中,为多周期判别器对高质量音频信号的评分,为多周期判别器对生成信号的评分,为多分辨率判别器对高质量音频信号的评分,为多分辨率判别器对生成信号的评分;m为高质量音频信号的样本数量,yj为第j个高质量音频信号的样本,为第j个生成信号。
93、一种面向das系统的高质量音频生成系统,包括:数据采集模块、预处理和特征提取模块、生成网络、判别网络、训练模块、转换模块;
94、所述数据采集模块用于针对das系统的多个光纤点数据进行数据采集和处理得到低质量音频数据,以及获取高质量音频数据;
95、所述预处理和特征提取模块用于对低质量音频数据进行幅度标准化、归一化、分割为多个短时间帧后,再根据音高提取算法得到每个短时间帧的音高特征-梅尔频谱特征数据对,集合得到数据集d1;以及对高质量音频数据进行相同的操作,得到数据集d2;
96、所述生成网络包括:音高插值模块、模板生成模块、下采样模块、梅尔频谱卷积模块、上采样模块、leakyrelu激活函数、tanh激活函数;所述音高插值模块的输入为音高特征-梅尔频谱特征数据对,通过线性插值函数,基于音高特征f0的时间索引和f0特征值,在梅尔频谱图的时间索引上进行插值,得到与梅尔频谱特征长度匹配的音高特征;所述模板生成模块用于根据与梅尔频谱特征长度匹配的音高特征生成一个多通道的信号模板;所述梅尔频谱卷积模块用于对梅尔频谱特征进行卷积;
97、所述下采样模块和上采样模块遵循u-net网络架构,下采样模块包括多层下采样卷积层,上采样模块包括多层上采样卷积层;第一层上采样卷积层的输入为下采样模块的输出与卷积后的梅尔频谱特征的拼接结果,后续上采样卷积层的输入为上一层下采样卷积层的输出和上采样卷积层的输出的拼接结果;
98、所述判别网络包括用于捕捉音频信号的周期性特征的多周期判别器,以及用于在不同频率上分析音频信号细节的多分辨率判别器;所述多周期判别器包括:频谱转化模块、卷积层、leakyrelu激活函数;所述频谱转换模块用于通过短时傅里叶变换将时间域信号转换为频域信号;所述卷积层包括5个3×3卷积层,并在每个卷积层后使用leakyrelu激活函数,其中初始卷积层用于将输入的频谱图从单通道扩展到32通道,保持特征图的空间维度;中间三个卷积层用于逐层将特征图的通道数保持在32,以逐步减小特征图的高度,逐层提取更深层次的特征;最后一个卷积层将输出的通道数减少到1,以整合特征;
99、所述多分辨率判别器包括:周期处理模块、卷积层、leakyrelu激活函数;所述周期处理模块用于根据周期列表中的周期,使时间长度能被设定的周期整除,以避免信息丢失;此过程包括反射填充以调整长度,并将一维信号转换为二维格式;卷积层包括5个5×5卷积层,并在每个卷积层后使用leakyrelu激活函数,其中初始卷积层,将输入信号从单通道扩展到64通道,保持特征图的空间维度;中间三个卷积层用于逐层将特征图的通道数提升到128、256和512,以提取深层次的特征信息;最后一个卷积层将输出通道数减少到1,以整合特征;
100、所述训练模块用于分阶段训练生成网络和判别网络,第一阶段以d2为训练集进行训练,第二阶段以d1和d2为训练集进行联合训练,输出训练好的高质量音频生成模型至转换模块;
101、所述转换模块中训练好的高质量音频生成模型的输入为由数据采集模块采集、预处理和特征提取模块处理后的低质量音频数据,输出为高质量音频数据。
102、进一步地,所述下采样模块包括三个7×7下采样卷积层,按顺序其膨胀率分别为1、3、5;每个下采样卷积层后使用leakyrelu激活函数;所述梅尔频谱卷积模块包括一个带权重归一化的一维7×7卷积层,填充为3,其输入的梅尔频谱特征图的长度与输出的卷积后的梅尔频谱特征图的长度一致;
103、所述上采样模块包括一个膨胀率为1的3×3上采样卷积层,一个膨胀率为3的7×7上采样卷积层,一个膨胀率为5的11×11上采样卷积层,并在每个上采样卷积层后使用leakyrelu激活函数;第一层上采样卷积层的输入为下采样模块的输出与卷积后的梅尔频谱特征的拼接结果;相同层的下采样卷积层和上采样卷积层通过拼接层跳越连接,所述拼接层用于将两个输入在通道维度上拼接;拼接层的两个输入分别为对应层数的下采样卷积层的输出、对应层数的上采样卷积层的输出,本层拼接层的输出作为下一层上采样卷积层的输入。
104、本发明的有益效果是:
105、(1)本发明提出的面向das的高质量音频生成方法,可以将das输出的包含嘈杂声、闷音、炸音的低质量音频转换为音质更高的高质量音频,这一过程显著提升了音频的清晰度和细节表现,使得处理后的音频适用于高要求的应用场景。
106、(2)本发明提出的多通道输入和多通道判别方法,通过同时处理多个光纤点的音频数据,充分利用空间信息,提高了音频信号的空间分辨率和一致性。多通道的判别网络能够更好地捕捉不同光纤点的音频特征,增强音频生成的准确性和真实感。
107、(3)本发明提出的音高提取方法,可以更有效地获得音频信号的关键特征。这些特征输入网络后,能够更精确地进行高质量音频的生成,确保音频信号的真实感和清晰度。
108、(4)本发明采用多周期判别器和多分辨率判别器相结合,从不同的时间尺度和频率分辨率上对音频信号进行判别和优化。多周期判别器专注于捕捉音频信号的周期性特征,而多分辨率判别器则能够在不同频率上分析音频信号的细节。这种多层次的判别方法显著增强了音频生成的质量和细节,使得生成的高质量音频在各种应用场景中都能表现出色。
- 还没有人留言评论。精彩留言会获得点赞!