用于调用自动助理的动态和/或场境特定热词的制作方法
背景技术:
1、人们可以参与和在此称为“自动助理”(也称为“聊天机器人”、 “交互式个人助理”、“智能个人助理”、“个人语音助理”、“会话代理”、“虚拟助理”等)的人机对话。例如,人类(其当他们与自动助理交互时可以称为“用户”)可以使用自由形式的自然语言输入来提供命令、查询和/或请求(本文被统称为“查询”),其中自由形式的自然语言输入可以包括被转换成文本然后被处理的有声话语和/或键入的自由形式的自然语言输入。
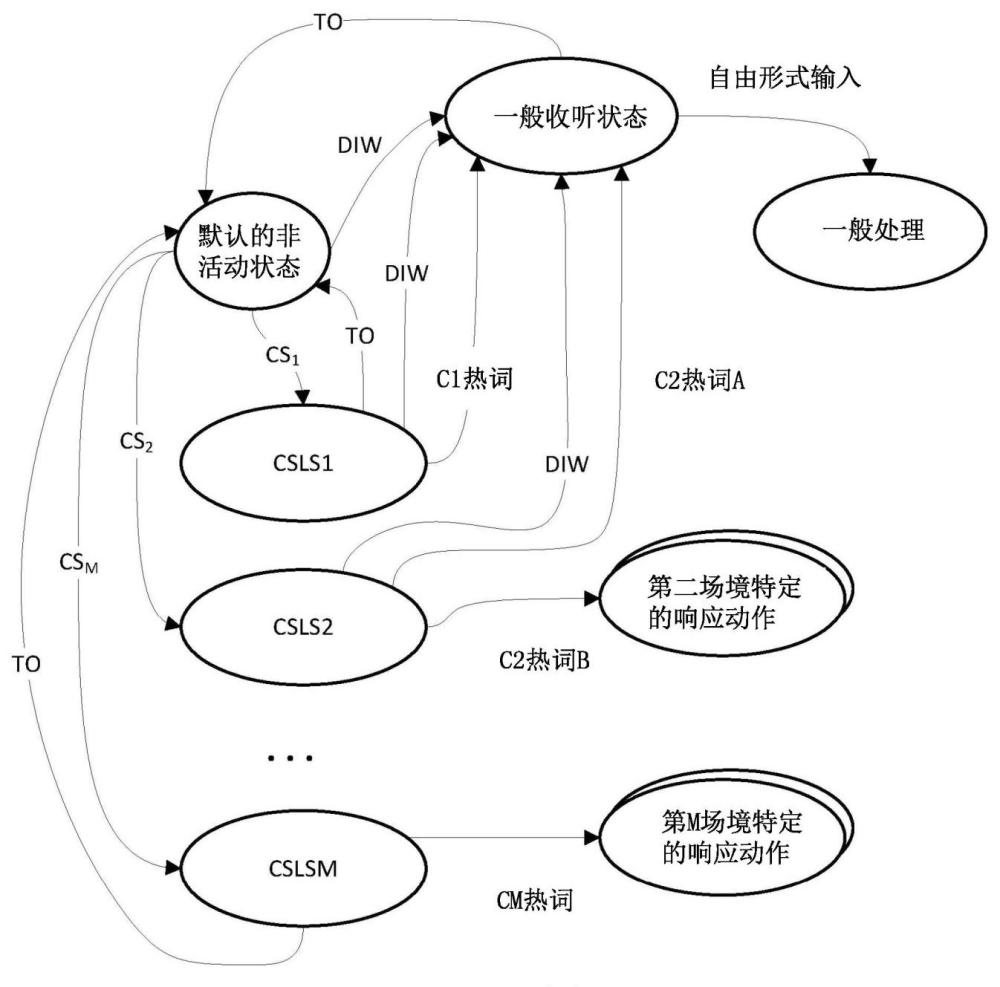
2、在许多情况下,在自动助理可以解释并响应用户的请求之前,它必须首先例如使用通常被称为“热词”或“唤醒词”的预定义口头调用短语来被“调用”。因此,许多自动助理在本文中称为“有限的热词收听状态”或“默认收听状态”下操作,在该状态下,它们总是“收听”由麦克风针对有限(或受限,或者“默认”)的热词集采样的音频数据。音频数据中捕获的除了默认的热词集以外的任何话语都将被忽略。一旦用默认的热词集中的一个或多个热词调用了自动助理,它就可以在此处称为“语音识别状态”的状态下操作,其中在调用之后的至少一些时间间隔内,自动助理对于由麦克风采样的音频数据进行语音到文本(“stt”)处理以生成文本输入,继而对该文本输入进行语义处理以确定用户的意图(并实现该意图)。
3、在默认收听状态下操作自动助理提供了多种好处。限制被“收听”的热词的数量可以节省功率和/或计算资源。例如,可以训练设备上机器学习模型以生成指示何时检测到一个或多个热词的输出。实施这样的模型可能仅需要最少的计算资源和/或功率,其对于经常受到资源限制的助理设备尤其有用。在客户端设备上本地存储这样的训练模型还提供了与隐私有关的优点。例如,大多数用户不希望在运行自动助理的计算设备的听力能力范围内对他们说的一切执行stt处理。另外,设备上模型还防止将指示不打算由自动助理处理的用户话语的数据提供给通常至少部分在云上运行的语义处理器。
4、除了这些优点之外,在有限的热词收听状态下操作自动助理也带来了各种挑战。为了避免无意中调用自动助理,通常将热词选择为在日常对话中不经常说出的单词或短语(例如“长尾”单词或短语)。但是,存在其中要求用户在调用自动助理执行某些操作之前说出长尾热词可能会很麻烦的各种情况。一些自动助理可以在用户说出命令之后提供用于“连续收听”模式的选项,从而用户在执行后续命令之前不需要用热词“重新唤醒”自动助理。但是,将自动助理转换到连续收听模式意味着自动助理可能正在对于多得多话语执行多得多的stt处理,从而可能浪费功率和/或计算资源。另外,并且如上所述,大多数用户更喜欢仅提交给(addressed to)自动助理的话语被stt处理。
技术实现思路
1、本文描述了用于使自动助理能够使用“动态”热词的技术。在各种情况下,配置有本公开的所选方面的自动助理可以更智能地收听场境特定热词,有时体现在本文中称为“增强”的热词集中。在各种实施方式中,补充或代替用于调用自动助理的默认热词,自动助理可以收听这些场境特定热词。换句话说,在各种实施方式中,配置有本公开的所选方面的自动助理可以在某些情况下至少暂时地扩展或改变其热词词汇。
2、在各种实施方式中,可以在各种不同的情况下选择性地启用动态热词,诸如用户足够接近助理设备,或者基于用户的外观、语音和/或其它识别特性来识别用户。这些其它识别特性可能包括,例如,rfid徽章、视觉标记、制服、才华(a piece of flair)、用户的身材(这可能指示用户是成年人)、可能影响用户口头交流和/或经由常规用户输入(例如,鼠标、触摸屏等)交流的能力的身体障碍等等。
3、作为示例,在一些实施方式中,如果通过接近传感器检测到用户,例如,在能够用于与自动助理接洽的计算设备的预定接近度内,则可以激活一个或多个附加的热词以使邻近的用户能够更轻松地调用自动助理。在一些实施方式中,用户越靠近助理设备,就可以激活越多的动态热词。例如,在助理设备的三米之内检测到的用户可以激活第一动态热词集。如果在例如一米之内的更近接近度检测到用户,则可以激活附加或替代的热词。
4、作为另一示例,在一些实施方式中,可以下载和/或“激活”与用户相关联(例如,定制给用户)的一个或多个动态热词,诸如用户手动选择或输入的热词。然后,用户可以说出这些自定义热词中的一个或多个热词来调用自动助理,而无需说出人们通常可以用来调用自动助理的默认的热词集。
5、在一些实施方式中,可以基于接近度和识别的一些组合来激活动态热词。这在嘈杂和/或拥挤的环境中可能特别有益。例如,在这样的环境中,任何数量的其它人也可能正在试图使用可能相对标准化的默认热词与自动助理进行交互。为了避免其它人意外激活自动助理,当用户足够靠近自动助理时(例如,握住她的智能手机或戴上她的智能手表,例如,可能会检测到接合的卡扣或紧固件并触发增强的热词集的激活)并且识别时,自动助理可以停止收听标准或默认的热词,并且可以改为收听针对特定用户量身定制的自定义热词。或者,在可替代的方案中,自动助理可以继续收听默认热词,但是可以提升基于这些默认热词的调用所需的置信度阈值,同时激活或降低与自定义热词相关联的阈值。
6、作为另一示例,在一些实施方式中,动态热词可以与一群人(例如,雇员、性别、年龄范围、共享视觉特性等)相关联,并且在检测到和/或识别出这些人中的一个或多个人的情况下,可以激活该动态热词。例如,一群人可以共享视觉特性。在一些实施方式中,当助理设备的一个或多个硬件传感器检测到这些视觉特性中的一个或多个视觉特性时,可以激活一个或多个动态热词,否则该一个或多个动态热词对于非群组成员是不可用的。
7、可以由自动助理或代表自动助理以各种方式来检测热词。在一些实施方式中,可以训练机器学习模型(诸如神经网络),以检测音频数据流中一个或多个热词的有序或无序序列。在一些这样的实施方式中,可以针对每个适用的热词(或包含多个热词的“热短语”)来训练单独的机器学习模型。
8、在一些实施方式中,可以根据需要下载经训练以检测这些动态热词的机器学习模型。例如,假设例如基于对捕获的用户的一个或多个图像执行的面部识别处理或对于根据用户语音而生成的音频数据执行的语音识别处理来识别特定用户。如果这些模型在设备上尚不可用,则可以基于用户的在线个人资料从云中下载这些模型。
9、在一些实施方式中,为了改善用户体验并减少延迟,可以将当检测到场境特定热词时意欲由自动助理执行的响应动作被预先缓存在用户与自动助理接洽的设备上。这样,一旦检测到场境特定热词,自动助理便可以采取立即动作。这与自动助理首先可能与一个或多个计算系统(例如,云)进行往返网络通信以满足用户的请求的情况形成对比。
10、本文描述的技术引起多种技术优势。扩展或者变更在某些情况下(至少暂时)可用于调用自动助理的词汇可以减少在使自动助理执行一些场境相关的操作(例如停止计时器、暂停音乐等)之前首先调用自动助理的需要。一些现有的助理设备通过允许用户通过简单地点击设备表面的活动部分(例如,电容式触摸板或显示器),从而使暂停媒体播放或停止计时器变得容易,而无需必须首先调用自动助理。但是,肢体残疾的用户和/或被其它事务(例如,做饭、开车等)占用的用户可能无法轻松触摸设备。因此,本文描述的技术使那些用户能够更容易和快速地使自动助理执行一些响应动作,例如停止计时器,而无需首先调用它。
11、另外,如本文所述,在一些实施方式中,自动助理可以主动下载响应于场境特定热词的内容。例如,假设用户倾向于重复特定的请求,诸如“what’s the weather forecasttoday?(今天的天气预报是什么?)”,“what’s on my schedule?(我的日程安排是什么?)”等。响应于这些请求的信息可以抢先下载并缓存在内存中,并且这些命令(或其部分)可用于激活特定的动态热词。因此,与自动助理必须首先执行通过一个或多个网络对一个或多个远程资源进行联系以获得响应信息的情况相比,当说出该一个或多个热词时,自动助理能够更快地提供响应信息。当助理设备在可能驶入/驶出其中可用数据网络的区域的车辆中时,这也可能是有益的。通过(例如当车辆处于数据覆盖区域中时)抢先下载和缓存响应于某些场境特定热词的内容,,则如果用户在数据覆盖区域之外旅行时请求该数据,该数据可用。
12、作为又一个示例,本文描述的技术可以使用户能够触发响应动作而无需全面的语音到文本(“stt”)处理。例如,当某些场境调用模型被激活并检测场境特定热词时,可以基于这些模型的输出来触发响应动作,而无需使用stt处理将用户的话语转换为文本。这可以节省客户端设备上的计算资源,和/或可以避免与云基础设施的往返通信以进行用户话语的stt和/或语义处理,这节省了网络资源。而且,避免往返传输可以改善延迟并且避免向云基础设施发送至少一些数据,这从用户隐私的角度来看可能是有利的和/或期望的。
13、在一些实施方式中,提供了一种由一个或多个处理器执行的方法,该方法包括:在默认收听状态下执行自动助理,其中该自动助理至少部分地在由用户操作的一个或多个计算设备上执行;当在默认收听状态下时,对由一个或多个麦克风捕获的音频数据监视一个或多个热词的默认集中的一个或多个热词,其中,检测到默认集中的一个或多个热词将触发自动助理从默认收听状态转换到语音识别状态;检测由与一个或多个计算设备集成的一个或多个硬件传感器生成的一个或多个传感器信号;分析该一个或多个传感器信号以确定用户的属性;基于以上分析,将自动助理从默认收听状态转换到增强收听状态;以及当处于增强收听状态时,对由一个或多个麦克风捕获的音频数据监视一个或多个热词的增强集中的一个或多个热词,其中到检测到增强集中的一个或多个热词将触发自动助理以执行响应动作而无需检测到默认集合中的一个或多个热词,并且其中增强集中的一个或多个热词不在默认集中。
14、本文公开的技术的这些和其它实施方式可以可选地包括以下特征中的一个或多个。
15、在各种实施方式中,所述一个或多个硬件传感器可以包括接近传感器,并且用户的属性可以包括:通过接近传感器检测到用户,或者通过接近传感器检测到用户在该一个或多个计算设备的预定距离内。
16、在各种实施方式中,所述一个或多个硬件传感器可以包括相机。在各种实施方式中,用户的属性可以包括:通过相机检测到用户、或者通过相机检测到用户在一个或多个计算设备的预定距离内。在各种实施方式中,分析可以包括面部识别处理。在各种实施方式中,用户的属性可以包括用户的身份。在各种实施方式中,用户的属性可以包括用户在群组中的成员资格。
17、在各种实施方式中,所述一个或多个硬件传感器可以包括一个或多个麦克风。在各种实施方式中,一个或多个属性可以包括基于由一个或多个麦克风生成的音频数据而在听觉上检测到用户。在各种实施方式中,分析可以包括语音识别处理。在各种实施方式中,用户的属性可以包括用户的身份。在各种实施方式中,用户的属性可以包括用户在群组中的成员资格。
18、在各种实施方式中,响应动作可以包括将自动助理转换到语音识别状态。在各种实施方式中,响应动作可以包括自动助理执行由用户使用增强集中的一个或多个热词所请求的任务。
19、另外,一些实施方式包括一个或多个计算设备的一个或多个处理器,其中,该一个或多个处理器可操作以执行存储在相关联的存储器中的指令,并且其中,所述指令被配置成引起前述任何一个方法的执行。一些实施方式还包括一个或多个非暂时性计算机可读存储介质,该一个或多个非暂时性计算机可读存储介质存储能够由一个或多个处理器执行以执行任何前述方法的计算机指令。
20、应当理解的是,本文中更详细描述的前述概念和附加概念的所有组合被认为是本文公开的主题的一部分。例如,出现在本公开的开头处的要求保护的主题的所有组合被认为是本文公开的主题的一部分。
- 还没有人留言评论。精彩留言会获得点赞!