一种语音转换方法、装置、计算机设备和存储介质与流程
本技术涉及音频生成,尤其涉及一种语音转换方法、装置、计算机设备和存储介质。
背景技术:
1、语音转换是在不改变话语内容信息的情况下,让某个人说的话听起来像是另一个人说的,在驾驶导航、视频制作、游戏制作、语音客服和语音社交等多个领域中发挥出了很强的应用价值。传统的语音转换技术需要选择音库内某一发音人作为目标,通过提取该发音人语音中的特征进行语音转换,但该种方式存在着转换效率低、用户等待时间长等缺陷。
技术实现思路
1、本技术的目的旨在至少能解决上述的技术缺陷之一,特别是现有技术中语音转换效率低、用时长的缺陷。
2、第一方面,本技术提供了一种语音转换方法,包括:
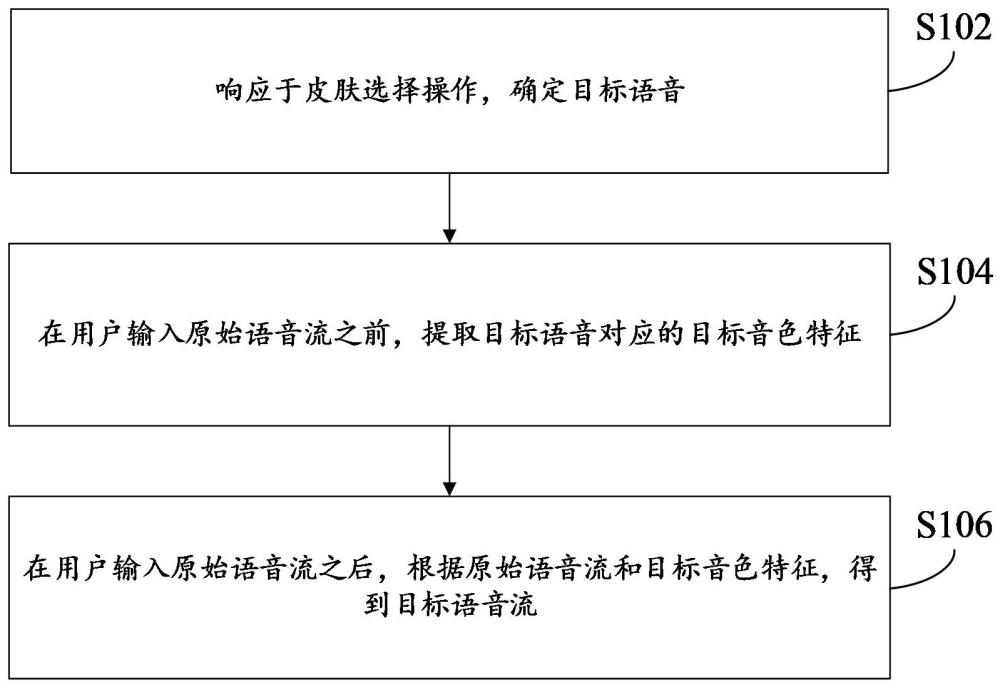
3、响应于皮肤选择操作,确定目标语音;
4、在确定出目标语音时,提取目标语音对应的目标音色特征;
5、在用户输入原始语音流之后,根据原始语音流和目标音色特征,得到目标语音流。
6、在其中一个实施例中,根据原始语音流和目标音色特征,得到目标语音流,包括:
7、将原始语音流输入到第一特征提取模型,得到原始语音特征;原始语音特征包括原始语音流的浅层音色特征和语义特征;
8、根据原始语音特征与目标音色特征,得到目标语音流。
9、在其中一个实施例中,第一特征提取模型的构建过程包括:
10、构建初始的自编码器模型;自编码器模型包括第一编码器和第一解码器,第一编码器用于对输入语音提取浅层音色特征和语义特征,并输出到第一解码器,第一解码器用于根据接收到的特征得到输入语音的重构结果;
11、以缩小重构结果与第一语音训练集的样本之间的差距为目标,利用第一语音训练集对初始的自编码器模型进行训练;
12、将训练完成的自编码器模型中的第一编码器作为第一特征提取模型。
13、在其中一个实施例中,目标音色特征包括目标全局音色特征,提取目标语音对应的目标音色特征,包括:
14、将目标语音输入到第二特征提取模型,得到目标全局音色特征;目标全局音色特征的维度高于浅层音色特征。
15、在其中一个实施例中,第二特征提取模块的构建过程包括:
16、构建初始的分类识别模型;分类识别模型包括特征提取部分和分类部分,特征提取部分用于对输入语音提取全局音色特征,并输出到分类部分,分类部分用于根据接收到的特征得到对输入语音的分类结果;
17、以缩小分类结果与第二语音训练集的分类标签之间的差距为目标,利用第二语音训练集对初始的分类识别模型进行训练;
18、将训练完成的分类识别模型的特征提取部分作为第二特征提取模型。
19、在其中一个实施例中,根据原始语音特征与目标音色特征,得到目标语音流,包括:
20、将原始语音特征作为输入、目标全局音色特征作为条件输入,输入到第一特征生成模型,得到第一目标语音特征;第一目标语音特征包括原始语音流的语义特征和目标全局音色特征;
21、根据第一目标语音特征,得到目标语音流。
22、在其中一个实施例中,第一特征生成模型的构建过程包括:
23、构建初始的第一条件自编码器模型;第一条件自编码器模型包括第二编码器和第二解码器,第二编码器用于对输入和条件进行特征融合,得到第一语音特征,第一语音特征包含输入中的语义特征和条件中的全局音色特征,第二解码器用于将遮罩后的第一语音特征还原为遮罩前的第一语音特征;
24、以缩小第二解码器的还原结果与第二编码器对语音特征第一训练集和全局音色特征训练集的特征融合结果之间的差距为目标,利用语音特征第一训练集和全局音色特征训练集对第一条件自编码器模型进行训练;
25、将训练完成的第一条件自编码器模型中的第二编码器作为第一特征生成模型。
26、在其中一个实施例中,以缩小第二解码器的还原结果与第二编码器对语音特征第一训练集和全局音色特征训练集的特征融合结果之间的差距为目标,利用语音特征第一训练集和全局音色特征训练集对第一条件自编码器模型进行训练,还包括:
27、对语音特征第一训练集进行音色扰动,并以缩小第二编码器音色扰动前后同一语音特征样本与同一全局特征训练样本的特征融合结果之间的差异为目标,对第一条件自编码器模型进行训练。
28、在其中一个实施例中,将原始语音特征作为输入、目标全局音色特征作为条件输入,输入到第一特征生成模型,得到第一目标语音特征,包括:
29、对原始语音特征进行音色扰动,并将音色扰动之后的原始语音特征作为输入、目标全局音色特征作为条件输入,输入到第一特征生成模型,得到第一目标语音特征。
30、在其中一个实施例中,目标音色特征还包括目标完整音色特征,提取目标语音对应的目标音色特征,还包括:
31、对目标语音进行特征提取,得到目标完整音色特征;目标完整音色特征的维度高于目标全局音色特征。
32、在其中一个实施例中,对目标语音进行特征提取包括:
33、根据目标语音,生成对应的梅尔频谱矩阵。
34、在其中一个实施例中,根据第一目标语音特征,得到目标语音流,包括:
35、将第一目标语音特征作为输入、目标完整音色特征作为条件输入,输入到第二特征生成模型,得到第二目标语音特征;第二目标语音特征包括原始语音流的语义特征和目标完整音色特征;
36、根据第二目标语音特征,得到目标语音流。
37、在其中一个实施例中,第二特征生成模型的构建过程包括:
38、构建初始的第二条件自编码器模型;第二条件自编码器模型包括第三编码器和第三解码器,第三编码器用于将输入和条件进行特征融合,得到第二语音特征,第二语音特征包含输入中的语义特征和条件中的完整音色特征,第三解码器用于将遮罩后的第二语音特征还原为遮罩前的第二语音特征;
39、以缩小第三解码器的还原结果与第三编码器对语音特征第二训练集和完整音色特征训练集的特征融合结果之间的差距为目标,利用语音特征第二训练集和完整音色特征训练集对第二条件自编码器模型进行训练;
40、将训练完成的第二条件自编码器模型中的第三编码器作为第二特征生成模型。
41、在其中一个实施例中,根据第二目标语音特征,得到目标语音流,包括:
42、将第二目标语音特征输入到语音生成模型,得到目标语音流。
43、第二方面,本技术提供了一种语音转换装置,包括:
44、目标语音确定模块,用于响应于皮肤选择操作,确定目标语音;
45、目标音色特征提取模块,用于在确定出目标语音时,提取目标语音对应的目标音色特征;
46、语音转换模块,用于在用户输入原始语音流之后,根据原始语音流和目标音色特征,得到目标语音流。
47、第三方面,本技术提供了一种计算机设备,包括一个或多个处理器,以及存储器,存储器中存储有计算机可读指令,计算机可读指令被一个或多个处理器执行时,执行上述任一实施例中的语音转换方法的步骤。
48、第四方面,本技术提供了一种存储介质,存储介质中存储有计算机可读指令,计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述任一实施例中的语音转换方法的步骤。
49、从以上技术方案可以看出,本技术实施例具有以下优点:
50、基于本技术实施例中的语音转换方法,首先响应用户的皮肤选择操作,确定目标语音,在确定出目标语音的同时,即开始对目标语音执行特征提取,得到目标语音对应的目标音色特征。最后,当用户输入原始语音流后,根据原始语音流和预先提取的目标音色特征,生成目标语音流。该方法可提供高度个性化的用户体验,允许用户根据自己的偏好制语音输出,在需要增加新的可选语音皮肤时,只需要音库中添加对应的参考语音即可,提高了音色的可拓展性。另外,其利用了用户执行选择操作到输入完原始语音流之间的空闲时间进行特征提取,大幅缩短了用户等待语音转换的时间,能够在实时或近实时条件下完成转换,提升用户体验感。
- 还没有人留言评论。精彩留言会获得点赞!