结合变分自编码和马尔科夫随机场的声纹识别方法及系统与流程
本发明属于声纹识别,尤其涉及一种结合变分自编码和马尔科夫随机场的声纹识别方法及系统。
背景技术:
1、声纹识别技术是一种基于生物特征的识别方法,也被称作说话人识别技术。它主要分为两个子领域:说话人辨认和说话人确认。声纹识别的核心过程是将声音信号转换为电信号,然后利用计算机进行分析和识别。在不同的应用场景和任务中,会采用不同的声纹识别技术。目前,在声纹识别的过程中,一段语音中与说话人相关的信息通常是由一组难以解释、初始时变化多端的隐含特征所驱动的。这些隐含特征经过多轮随机过程的迭代后,最终形成了说话人的独特声音特征。
2、传统的声纹识别方法在提取隐含变量时,往往无法确定这些隐含变量究竟来自于哪一轮随机过程。因此,为了提高识别的准确性,研究人员需要采集大量的样本数据。然而,即便如此,由于隐含变量的难以分辨性,声纹识别系统仍然容易出现错误和遗漏。也就是说,在采集到说话人的声音数据后,用于区分不同说话人的隐含变量仍然极难被准确识别和区分,这在很大程度上限制了声纹识别技术的准确性和可靠性。
技术实现思路
1、本发明提供一种结合变分自编码和马尔科夫随机场的声纹识别方法及系统,用于区分说话人的隐含变量。
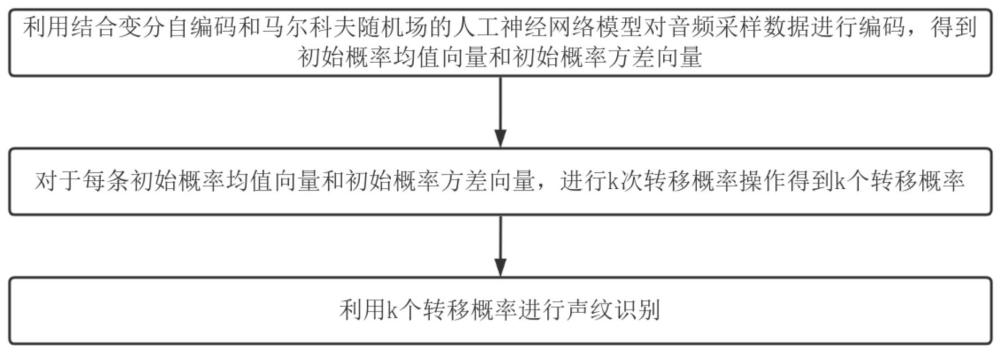
2、为实现上述发明目的,本发明的第一目的是提供一种结合变分自编码和马尔科夫随机场的声纹识别方法,包括:
3、s1、利用结合变分自编码和马尔科夫随机场的人工神经网络模型对音频采样数据进行编码,得到初始概率均值向量和初始概率方差向量;
4、s2、对于每条初始概率均值向量和初始概率方差向量,进行k次转移概率操作得到k个转移概率,k为大于9的自然数;每次转移概率操作的步骤为:
5、s201、对所述初始概率均值向量和初始概率方差向量进行转移概率特征重采样得到转移概率;
6、s202、对所述转移概率进行编码得到转移概率均值向量和转移概率方差向量;
7、s3、利用k个转移概率进行声纹识别;具体包括:
8、s301、对k个转移概率逐一进行量化,得到一个转移概率矩阵;
9、s302、利用卷积神经网络对转移概率矩阵进行卷积操作,输出一个卷积向量;
10、s303、利用多层感知机对所述卷积向量进行处理得到c个感知输出,c为用户自定义的声纹类别个数;
11、s304、利用softmax算法对c个感知输出进行处理得到音频采样数据在每个类别中的概率,选出概率最大的那个类别,即为声纹识别的结果。
12、优选的,所述softmax算法的公式为:
13、;
14、其中,为多层感知机的输出,包括c个分量,指它的第i个分量。
15、优选的,所述人工神经网络模型包括:
16、音频数据编码器,对音频采样数据进行编码,得到初始概率均值向量和初始概率方差向量;
17、转移概率循环生成模块,对于每条初始概率均值向量和初始概率方差向量,进行k次转移概率操作得到k个转移概率;
18、转移概率编码器,对每个转移概率进行编码,得到转移概率均值向量和转移概率方差向量;
19、解码器,对转移概率均值向量和转移概率方差向量进行隐含特征重采样和解码,得到生成的音频数据。
20、优选的,所述人工神经网络模型的训练过程包括:
21、准备数据集;首先对采集的音频波形数据进行规整,得到大小一致的音频波形数据;然后对所述音频波形数据进行类别标注;
22、设计损失函数;具体包括:
23、计算变分自编码损失l1;
24、(1)
25、其中,指的是第k次产生的转移概率均值,为第k次产生的转移概率均方差,x为输入的音频采样数据,为生成的音频数据,n为数据集中的数据条数,λ为用户自定义的损失项微调参数;
26、计算分类损失l2;
27、(2)
28、其中,为音频采样数据x所属类别的one-hot编码,是第i个分量,为多层感知机的输出,包括c个分量,指它的第i个分量;
29、合并损失l;
30、(3)
31、将数据集中的数据逐条输入人工神经网络模型,使用adam优化算法,运行若干个epoch,取出人工神经网络权值参数,完成训练过程。
32、本发明的第二目的是提供一种结合变分自编码和马尔科夫随机场的声纹识别系统,包括:
33、结合变分自编码和马尔科夫随机场的人工神经网络模型;对音频采样数据进行编码,得到初始概率均值向量和初始概率方差向量;对于每条初始概率均值向量和初始概率方差向量,进行k次转移概率操作得到k个转移概率,k为大于9的自然数;每次转移概率操作的步骤为:首先对所述初始概率均值向量和初始概率方差向量进行转移概率特征重采样得到转移概率;然后对所述转移概率进行编码得到转移概率均值向量和转移概率方差向量;
34、利用k个转移概率进行声纹识别的声纹识别模型;具体识别过程包括:首先对k个转移概率逐一进行量化,得到一个转移概率矩阵;然后利用卷积神经网络对转移概率矩阵进行卷积操作,输出一个卷积向量;随后利用多层感知机对所述卷积向量进行处理得到c个感知输出,c为用户自定义的声纹类别个数;最后利用softmax算法对c个感知输出进行处理得到音频采样数据在每个类别中的概率,选出概率最大的那个类别,即为声纹识别的结果。
35、优选的,所述softmax算法的公式为:
36、;
37、其中,为多层感知机的输出,包括c个分量,指它的第i个分量。
38、优选的,所述人工神经网络模型包括:音频数据编码器、转移概率循环生成模块、转移概率编码器和解码器。
39、优选的,所述人工神经网络模型的训练过程包括:
40、准备数据集;首先对采集的音频波形数据进行规整,得到大小一致的音频波形数据;然后对所述音频波形数据进行类别标注;
41、设计损失函数;具体包括:
42、计算变分自编码损失l1;
43、(1)
44、其中,指的是第k次产生的转移概率均值,为第k次产生的转移概率均方差,x为输入的音频采样数据,为生成的音频数据,n为数据集中的数据条数,λ为用户自定义的损失项微调参数;
45、计算分类损失l2;
46、(2)
47、其中,为音频采样数据x所属类别的one-hot编码,是第i个分量,为多层感知机的输出,包括c个分量,指它的第i个分量;
48、合并损失l;
49、(3)
50、将数据集中的数据逐条输入人工神经网络模型,使用adam优化算法,运行若干个epoch,取出人工神经网络权值参数,完成训练过程。
51、本发明的第三目的是提供一种计算机可读存储介质,其存储有计算机程序,该程序被处理器执行时实现上述的结合变分自编码和马尔科夫随机场的声纹识别方法。
52、本发明的第四目的是提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述的结合变分自编码和马尔科夫随机场的声纹识别方法。
53、本技术具有的优点和积极效果是:
54、本发明通过结合变分自编码器(vae)和马尔科夫随机场(mrf)的人工神经网络模型,来实现高效的声纹识别。具体来说,该技术方案首先利用变分自编码器提取初始的隐含变量,这些隐含变量能够捕捉到声音信号中的关键特征。随后,这些隐含变量被用来驱动一个马尔科夫过程,该过程进一步细化声音特征的表示。通过这种方式,模型能够有效地捕捉声音信号的动态变化,并将其转化为可用于分类的特征表示。
55、这种技术方案的优势在于,它能够在样本数量较少的情况下,依然取得较高的声纹识别精度。传统的声纹识别方法通常需要大量的训练样本才能达到较高的识别率,而本发明的技术方案通过结合vae和mrf的优势,能够在有限的样本条件下,依然提取出具有区分性的特征,从而显著提高识别精度。这种创新的模型不仅提高了声纹识别的效率,还降低了对大规模数据集的依赖,使得声纹识别技术在实际应用中更具可行性和灵活性。
- 还没有人留言评论。精彩留言会获得点赞!