一种基于BERT特征和风格编码的低资源语音合成系统的制作方法
本发明涉及语音合成,特别涉及一种基于bert特征和风格编码的低资源语音合成系统。
背景技术:
1、近年来,语音合成随着ai技术的进步,在大规模的高质量的语音数据前提下,目前的tts模型(语音合成模型)已经有较好的表现。但是在低资源数据情况下,即仅用用户少量的录音数据来进行语音合成的情况下。语音合成的效果往往会出现音色不像,韵律欠缺,发音不准确的问题。因此,就目前的tts技术来说,在少量数据的基础下,给定指定的文本,可以合成在音色和音质上可媲美单人语音合成的高质量的音频,是比较具有挑战性的任务。
2、然而,目前低资源个性化的语音合成算法策略主要是采用预训练与微调结合的策略,即先在一个很大的多说话人语料数据集上做模型预训练,然后用目标说话人的少量数据去对模型做微调。由于目标说话人的数据量较少,目前的语音合成技术往往会出现音色相似度较低,韵律性欠缺,发音不准确的问题。
技术实现思路
1、本技术提供一种基于bert特征和风格编码的低资源语音合成系统,以解决现有声音合成技术无法在低资源的情况下合成较为准确的人声问题。
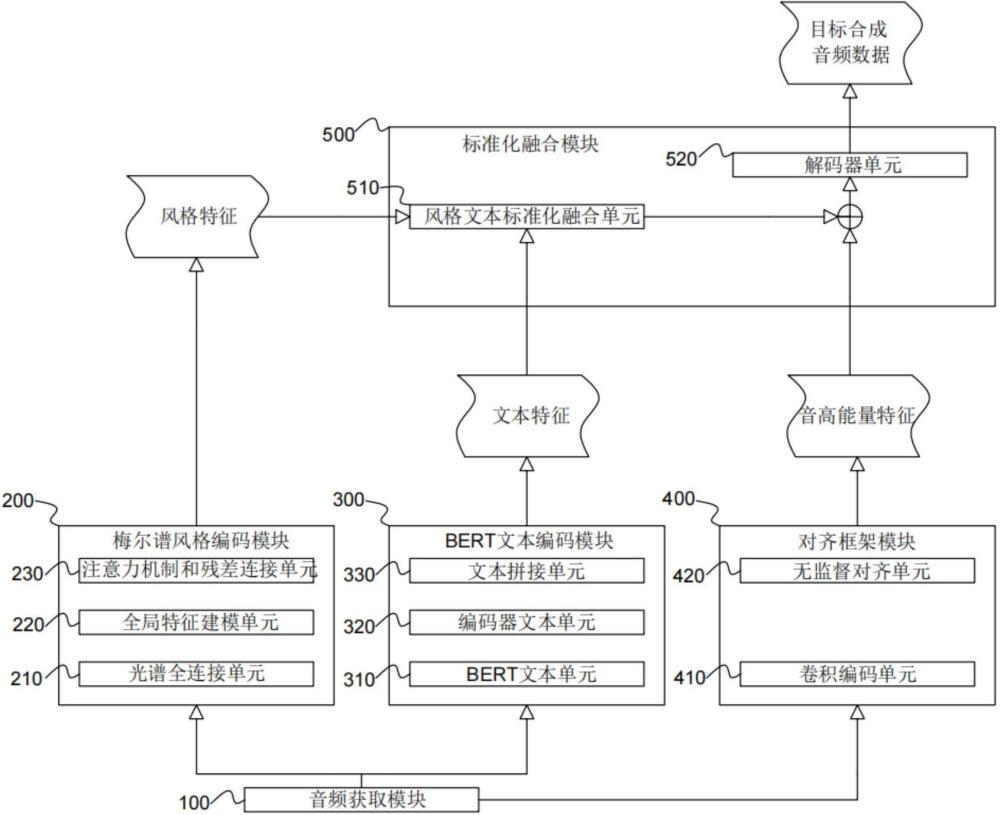
2、所述系统包括:
3、音频获取模块,所述音频获取模块被配置为获取待合成的音频数据,所述音频数据包括梅尔谱和文本数据;
4、梅尔谱风格编码模块,所述梅尔谱风格编码模块被配置为根据所述梅尔谱进行音色预测处理,得到风格特征;所述音色预测处理包括根据帧数级别的所述梅尔谱以及所述梅尔谱对应的时序进行全局编码;其中,所述梅尔谱风格编码模块包括多个采用层叠分布的注意力层,每一个注意力层由多个并行设置的注意力头构成;所述梅尔谱风格编码模块还配置为,根据所述梅尔谱划得到多个子序列,动态确定每一子序列对应的一个或多个注意力头,以根据所述注意力层中的所述一个或多个注意力头分别对所述子序列进行注意力权重的计算,并根据注意力权重完成全局编码;
5、bert文本编码模块,所述bert文本编码模块被配置为根据所述文本数据进行词语语句预测处理,得到文本特征;所述词语语句预测处理包括句子编码预测、词语编码预测、根据句子编码预测和词语编码预测的结果进行拼接处理以及根据拼接处理后的结果进行文本训练;
6、对齐框架模块,所述对齐框架模块被配置为根据所述梅尔谱和所述文本数据进行音高对齐预测处理,得到音高能量特征;
7、标准化融合模块,所述标准化融合模块被配置为将所述风格特征、所述文本特征和所述音高能量特征进行标准化融合处理,得到目标合成音频数据。
8、优选的,所述梅尔谱风格编码模块还被配置为:
9、对所述梅尔谱进行帧数级别的注意力机制特征预测,得到所述风格特征;所述注意力机制特征预测按照时序进行。
10、优选的,所述梅尔谱风格编码模块包括:
11、光谱全连接单元,所述光谱全连接单元被配置为通过内置的全连接层将所述梅尔谱转换为帧数级别的隐状态序列;
12、全局特征建模单元,所述全局特征建模单元被配置为利用门控卷积神经网络捕获所述隐状态序列中的时序信息,所述时序信息包括对应所述隐状态序列每一帧数的时序;其中,所述门控卷积神经网络包括多个门控卷积层,多个门控卷积层之间采用残差连接的方式进行处理;
13、注意力机制和残差连接单元,所述注意力机制和残差连接单元由多个采用层叠分布的注意力层构成,多个注意力层之间采用残差连接,每一个注意力层由多个并行设置的注意力头构成;所述注意力机制和残差连接单元被配置为根据所述时序信息对所述隐状态序列进行全局编码,得到所述风格特征;
14、所述注意力机制和残差连接单元中,每一所述注意力层包括有预设的一个或多个第一注意力头,以及一个或多个第二注意力头;其中,所述第一注意力头均为激活状态,所述第二注意力头配置为,根据上一层级所述注意力层输出的注意力权重,将当前层级的注意力层中的至少部分第二注意力头调整为激活状态;
15、根据所述第一注意力头以及处于激活状态的第二注意力头对所述子序列进行注意力权重的计算。
16、优选的,所述注意力机制和残差连接单元还被配置为:
17、对所述隐状态序列的每一帧数进行多次注意力机制计算,得到对应同一帧数的多个注意力机制计算结果;
18、计算同一帧数的所有所述注意力机制计算结果的平均,得到平均向量;
19、将每一帧数的所有平均向量进行残差加和,得到所述风格特征。
20、优选的,所述bert文本编码模块还被配置为:
21、根据所述文本数据分别进行词语编码预测和句子编码预测,分别得到词语语义特征和句子语义特征;
22、将所述词语语义特征和所述句子语义特征进行拼接,得到所述文本特征。
23、优选的,所述bert文本编码模块包括:
24、bert文本单元,所述bert文本单元被配置为对所述文本数据进行句子编码预测,得到所述句子语义特征;所述句子编码预测在文本句子级别下进行;
25、编码器文本单元,所述编码器文本单元被配置为对所述文本数据进行词语编码预测,得到所述词语语义特征;所述词语编码预测在文本词级别下进行;
26、文本拼接单元,所述文本拼接单元被配置为将所述句子语义特征和所述词语语义特征进行拼接处理,得到拼接文本单元,并对根据所述拼接文本单元进行文本训练,得到所述文本特征。
27、优选的,所述bert文本单元包括若干个变压器编码、若干个注意力机制头和若干个隐层单元;
28、所述编码器文本单元包括高层次特征提取单元和全连接层。
29、优选的,所述对齐框架模块还被配置为:
30、分别对所述梅尔谱和所述文本数据进行卷积编码,得到卷积梅尔谱和卷积文本数据;
31、将所述卷积梅尔谱和所述卷积文本数据进行无监督对齐计算,得到音高特征和能量特征;
32、所述音高能量特征包括所述音高特征和所述能量特征。
33、优选的,所述对齐框架模块包括:
34、卷积编码单元,所述卷积编码单元被配置为分别对所述梅尔谱和所述文本数据进行卷积编码,得到卷积梅尔谱和卷积文本数据;
35、无监督对齐单元,所述无监督对齐单元被配置为将所述卷积梅尔谱和所述卷积文本数据按照成对的l2距离进行无监督对齐计算,得到所述音高能量特征;采用前向和算法将无监督对齐计算过程中得到的对齐数据进行加和。
36、优选的,所述标准化融合模块还包括:
37、风格文本标准化融合单元,所述风格文本标准化融合单元被配置为:
38、将所述风格特征进行归一化处理,得到归一化数据;
39、分别对所述归一化数据进行缩放处理和移位处理,得到缩放移位数据;
40、对所述缩放移位数据进行全连接层的计算,得到激活函数和偏执数据;
41、将所述激活函数、所述偏执数据、所述文本数据和所述音高能量特征进行拼接处理,得到合成音频数据;
42、解码器单元,所述解码器单元被配置为对所述合成音频数据进行解码处理,得到所述目标合成音频数据。
43、由上述内容可知,本技术提供一种基于bert特征和风格编码的低资源语音合成系统,所述系统包括音频获取模块,所述音频获取模块被配置为获取待合成的音频数据,所述音频数据包括梅尔谱和文本数据;梅尔谱风格编码模块,所述梅尔谱风格编码模块被配置为根据所述梅尔谱进行音色预测处理,得到风格特征;bert文本编码模块,所述bert文本编码模块被配置为根据所述文本数据进行词语语句预测处理,得到文本特征;对齐框架模块,所述对齐框架模块被配置为根据所述梅尔谱和所述文本数据进行音高对齐预测处理,得到音高能量特征;标准化融合模块,所述标准化融合模块被配置为将所述风格特征、所述文本特征和所述音高能量特征进行标准化融合处理,得到目标合成音频数据。本技术通过上述系统解决了现有声音合成技术无法在低资源的情况下合成较为准确的人声问题。
- 还没有人留言评论。精彩留言会获得点赞!