基于驾驶情境的语音主动推荐系统及方法与流程
本发明涉及语音识别,更具体地说,本发明涉及基于驾驶情境的语音主动推荐系统及方法。
背景技术:
1、随着车机屏向国内外市场的深度发展以及面对不同客户的差异性需求,对语音的定制化程度越来越高,且随着车型范围不断扩增,整体成本也在不断的增加;在车载语音交互系统的发展过程中,语音音色和语音风格方面存在一些局限性,这与当前智能车载语音方案无法满足市场快速迭代需求相关联。
2、现有的车载语音系统往往只提供有限的几种标准音色选择,如常见的一两种男性音色和女性音色。这些音色在音质和自然度上无法满足用户对于高品质语音的需求。例如,音色可能听起来较为机械、生硬,缺乏情感和个性,在长时间使用过程中容易让用户产生听觉疲劳。且在不同的应用场景下,如导航、娱乐推荐、车辆信息提示等,使用的语音风格变化不大。例如,导航指令可能一直是一种简洁但略显单调的风格,没有根据路况的复杂程度、行驶的时间段(如高峰时段和非高峰时段)等因素进行调整;娱乐推荐也可能只是用一种通用的风格进行内容介绍,无法与娱乐内容本身的情感色彩和特点相匹配,不能很好地激发用户的兴趣。
3、公开号为cn115762503a的中国专利申请公开了车载语音系统、车载语音的自主学习方法、设备及介质,包括用户交互前端和策略管理后端,所述用户交互前端,用于获取用户行为画像数据;将所述用户行为画像数据发送至所述策略管理后端;所述策略管理后端,用于基于所述用户行为画像数据进行模型训练确定语音控制更新策略,基于所述语音控制更新策略更新对应的历史语音控制策略得到当前语音控制策略。该发明解决了现有车载语音系统中的语音控制策略在出厂前预置,且无法满足不同用户的个性需求,且无法跟随用户需求的变化自主学习的问题。
4、上述方法虽能满足大部分场景,但对上述方法以及现有技术进行研究和实际应用发现,上述方法以及现有技术至少存在以下部分缺陷:
5、(1)基于一些基本的用户画像标签进行简单的分类和推荐,对于用户的个性化需求挖掘不够深入。
6、(2)基于较为简单的用户行为画像数据进行分析和学习,对于复杂的驾驶情境信息的收集和利用不足,导致无法根据全面的驾驶情境为用户提供最贴切的语音服务。
7、(3)采用的推荐策略相对简单,只是基于已有的用户行为画像数据进行模型训练和推荐,缺乏对不同驾驶情境下用户需求的动态分析和预测。
8、鉴于此,本发明提出基于驾驶情境的语音主动推荐系统及方法以解决上述问题。
技术实现思路
1、为了克服现有技术的上述缺陷,为实现上述目的,本发明提供如下技术方案:基于驾驶情境的语音主动推荐方法,包括如下步骤:
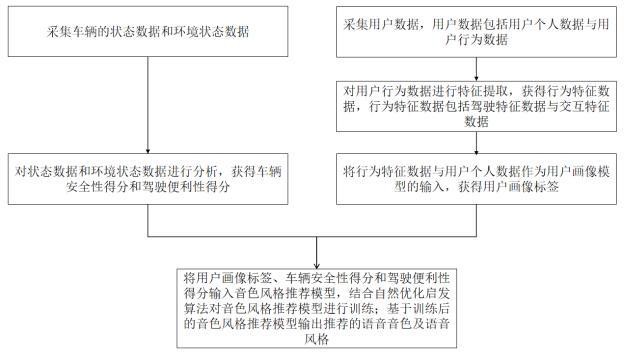
2、采集车辆的状态数据和环境状态数据;
3、采集用户数据,用户数据包括用户个人数据与用户行为数据;
4、对用户行为数据进行特征提取,获得行为特征数据,行为特征数据包括驾驶特征数据与交互特征数据;
5、将行为特征数据与用户个人数据作为用户画像模型的输入,获得用户画像标签;
6、对状态数据和环境状态数据进行分析,获得车辆安全性得分和驾驶便利性得分;
7、将用户画像标签、车辆安全性得分和驾驶便利性得分输入音色风格推荐模型,结合自然优化启发算法对音色风格推荐模型进行训练;基于训练后的音色风格推荐模型输出推荐的语音音色及语音风格。
8、进一步地,所述交互特征数据包括交互语音数据的语调特征、快慢特征与情感词得分特征;
9、获得语调特征的方法包括:
10、对采集到的交互语音数据进行采样和量化,将交互语音数据转换为数字信号,并将交互语音数据划分为短帧,使用自相关法、倒谱法或基于神经网络的方法提取每一帧语音的基频,将基频的均值作为语调特征;
11、获得快慢特征的方法包括:
12、计算交互语音数据的时长,标记为语音时长;然后用音节数量除以语音时长得到的结果作为快慢特征。
13、进一步地,获得所述情感词得分特征的方法包括:
14、选择情感词典,使用语音识别技术将交互语音数据转换为语音文本,对转换后的语音文本进行预处理,包括语音文本清洗和分词处理;对经过预处理后的语音文本中的每个词语,根据每个词语的拼音及声调进行编码得到词语编码,将预处理后的语音文本中的每个词语编码与情感词典中的词汇编码进行逐一匹配,获取情感词典中对应的情感词;
15、将同一类别的情感词建立对应的情感词类别集合,将同一情感词类别集合中的情感词在预设情感词量化表中匹配,获得每个情感词的量化得分,将同一情感词类别集合中每个情感词的量化得分之和作为该情感词类别集合的得分;对不同情感词类别集合的得分进行加权求和得到情感词得分特征。
16、进一步地,所述用户画像模型的训练方法包括:
17、预先收集r组训练数据,训练数据包括行为特征数据、用户个人数据与用户画像标签;
18、将每组行为特征数据与用户个人数据作为用户画像模型的输入,所述用户画像模型以每组行为特征数据与用户个人数据对应的用户画像标签作为输出,以每组行为特征数据与用户个人数据对应的实际用户画像标签作为预测目标;以最小化所有用户画像标签的预测误差之和作为训练目标;对用户画像模型进行训练,直至预测误差之和达到收敛时停止训练;所述用户画像模型为深度神经网络模型。
19、进一步地,所述环境状态数据包括周围环境数据和天气状况;所述周围环境数据包括道路标志以及与障碍物之间的距离;所述道路标志包括指向标识与提示标识;
20、获得所述与障碍物之间的距离的方法包括:
21、步骤101、将车载摄像头采集的道路影像输入预构建的影像识别模型中,影像识别模型输出道路影像是否含有障碍物;
22、步骤102、若道路影像含有障碍物,则通过车载雷达获取本车辆与障碍物的距离,若本车辆与障碍物的距离有多个时,则将最小的本车辆与障碍物的距离作为与障碍物之间的距离。
23、进一步地,所述驾驶特征数据包括速度平均值与速度标准差;
24、获得所述驾驶特征数据的方法包括:
25、用户行为数据包括驾驶操作数据与交互语音数据;驾驶操作数据为次车辆起步开始到预定时间的加速数据;
26、将次车辆起步开始到预定时间的加速数据建立速度分析集合,计算速度分析集合的速度平均值与标准差;将速度分析集合的速度平均值作为速度平均值;将速度分析集合的标准差作为速度标准差。
27、进一步地,所述状态数据包括车辆行驶数据、剩余能量与道路信息;车辆行驶数据包括车辆当前的行驶速度、加速度与转向角度;道路信息为车辆当前所处的坡度和曲率数据;将状态数据和环境状态数据输入安全分析模型,获得车辆安全性得分。
28、进一步地,获得驾驶便利性得分的方法包括:
29、基于实时位置信息获取到达目的地的n条导航路径,若n为1时,则获取所述导航路径对应剩余时间,剩余时间为实时位置信息达到目的地所需时间;
30、若n大于1时,n条导航路径中包含一条当前导航路径,将当前导航路径剩余时间标记为第一剩余时间,当前导航路径为车辆导航系统当前选择的导航路径;从n条导航路径中选择剩余时间最小的时间,标记为第二剩余时间,将第二剩余时间与第一剩余时间的比值标记为时间特征值;若时间特征值大于或等于1,则当前导航路径为n条导航路径中最优的路径;若时间特征值小于1,则当前导航路径不为n条导航路径中最优的路径;
31、将获取的剩余能量能够支撑的里程数与剩余路程的比值,标记为路程特征值;
32、将时间特征值与路程特征值进行加权求和,得到驾驶便利性得分;
33、;
34、式中,为驾驶便利性得分;和为预设权重;为时间特征;为路程特征。
35、进一步地,所述音色风格推荐模型的训练方法包括:
36、预先收集训练数据,训练数据包括综合特征数据以及综合特征数据对应的语音音色和语音风格;综合特征数据包括用户画像标签、车辆安全性得分和驾驶便利性得分;
37、将每组综合特征数据作为音色风格推荐模型的输入,所述音色风格推荐模型以每组综合特征数据对应的语音音色和语音风格作为输出,以每组综合特征数据对应的实际语音音色和语音风格作为预测目标;其中,以最小化所有语音音色和语音风格的损失函数值之和作为训练目标,基于自然优化启发算法对音色风格推荐模型进行训练,直至预测误差之和达到收敛时停止训练;所述音色风格推荐模型为深度神经网络模型。
38、进一步地,所述音色风格推荐模型的损失函数值如下:
39、;
40、式中,为损失函数值;为训练数据数量;为音色风格推荐模型的预测函数,基于参数对第个训练数据进行预测输出;为第个训练数据实际对应的输出,即实际语音音色和语音风格,为第个训练数据;为音色风格推荐模型的参数,即用户画像标签、车辆安全性得分和驾驶便利性得分的权重,音色风格推荐模型的参数使用布谷鸟优化算法训练优化得到。
41、进一步地,使用布谷鸟优化算法训练优化音色风格推荐模型的参数的方法包括:
42、步骤1、随机生成h组初始解,即为巢,每个巢代表一组音色风格推荐模型的参数,如下:
43、;
44、式中,为音色风格推荐模型输出;为用户画像标签;为车辆安全性得分;为驾驶便利性得分;为用户画像标签权重;为车辆安全性得分权重;为驾驶便利性得分权重;
45、步骤2、迭代更新,产生新巢,产生新巢的方法包括:
46、;
47、式中,为第次迭代的参数;为第次迭代的参数;为步长因子,控制搜索步伐的大小;为服从levy分布的随机步长,即分布的随机数,levy飞行有助于跳出局部最优解;为尺度参数,控制分布的形状;
48、步骤3、使用计算新巢的损失函数值;
49、步骤4、若新巢的损失函数值小于h组中任一巢的损失函数值,则以预设概率用新巢替换h组中大于新巢的损失函数值对应的巢;
50、当达到预设迭代次数时,选择损失函数值最小的巢,作为音色风格推荐模型的参数。
51、基于驾驶情境的语音主动推荐系统,包括:
52、第一采集模块,用于采集车辆的状态数据和环境状态数据;
53、第二采集模块,用于采集用户数据,用户数据包括用户个人数据与用户行为数据;
54、第一分析模块,用于对用户行为数据进行特征提取,获得行为特征数据,行为特征数据包括驾驶特征数据与交互特征数据;
55、画像构建模块,用于将行为特征数据与用户个人数据作为用户画像模型的输入,获得用户画像标签;
56、数据分析模块,用于对状态数据和环境状态数据进行分析,获得车辆安全性得分和驾驶便利性得分;
57、语音推荐模块,用于将用户画像标签、车辆安全性得分和驾驶便利性得分输入音色风格推荐模型,结合自然优化启发算法对音色风格推荐模型进行训练;基于训练后的音色风格推荐模型输出推荐的语音音色及语音风格。
58、本发明基于驾驶情境的语音主动推荐系统及方法的技术效果和优点:
59、本发明综合考虑用户个人数据和用户行为数据构建用户画像,充分挖掘用户的偏好,对用户的个性化需求进行深度挖掘和精准匹配,提供更具个性化的语音推荐服务;还采集多方面驾驶信息,分析实际驾驶情境中的驾驶安全性和驾驶便利性,能够更准确地把握用户在驾驶过程中的实际需求,提供更精准的语音推荐服务,综合考虑用户画像,以及驾驶情境中的驾驶安全性和驾驶便利性,训练优化的音色风格推荐模型推荐最符合用户需求以及当前驾驶情境的语音音色和语音风格,能够满足用户多样化需求;且适应市场发展趋势,为智能车载语音系统发展提供有效思路与实践参考。
- 还没有人留言评论。精彩留言会获得点赞!