一种在线辅助语音对话场景的多模态情感提示方法及系统与流程
本发明涉及人工智能,尤其涉及一种在线辅助语音对话场景的多模态情感提示方法及系统。
背景技术:
1、在线辅助语音场景的多模态情感提示在诸多领域有着重要应用,例如在智能客服系统中,准确识别客户的情感变化有助于提供更加个性化的服务;在教育和心理健康监测领域,对人类情感状态的准确把握也为教学方式的调整和心理干预提供了依据。然而,当前在语音情感分析领域中,研究主要集中在对语音进行情感分类的任务上,这种方法往往存在局限性。具体表现为:
2、尽管在线辅助语音场景的多模态情感提示方法具有重要的应用前景,但在当前基于深度学习技术下仍然面临以下两方面的阻碍:
3、一、当前的语音情感分析技术主要集中于对语音进行单一标签的情感分类,如“愉快”“愤怒”“悲伤”等。然而,实际对话场景中的情感表达往往更加复杂,可能在同一段对话中包含多种情感的交替或情感波动。这种情感的多样性和细微变化,仅依靠单一标签的分类方法很难全面捕捉。例如,用户的情感可能在对话中从“轻微愤怒”过渡到“失望”,但传统情感分类模型难以精确表达这种情感变化。正如陶建华等人在2023年《信号处理》杂志上发表的《语音情感识别综述》中所指出的,现有方法往往对情感的细粒度识别能力不足,尤其是在多情感交替的场景中表现出局限性。缺乏对细粒度情感的识别,使得模型在复杂场景中的情感识别准确性和实用性受到限制。
4、二、情感表达并不仅仅限于语音特征,还包括面部表情、文字内容等多种模态信息。在语音情感识别中,仅依赖语音信号进行情感分析会导致情感识别的片面性和不准确性。例如,语音中的语调和节奏可以表达情感强度,而文字内容往往提供了情感的语境和背景信息。当前大多数语音情感识别系统缺乏对多模态信息的有效融合,使得其在捕捉复杂的情感线索上存在不足。正如蔡宇扬等人在2023年《计算机应用研究》上发表的《基于模态信息交互的多模态情感分析》中所指出的,多模态信息的有效融合是实现情感识别准确性和全面性的重要手段。只有将语音、文本等多模态信息结合起来,才能更全面地理解和识别用户的情感状态。然而,现有技术在如何实现多模态信息的对齐和融合方面仍面临挑战,这阻碍了模型在情感提示准确性和全面性上的提升。
技术实现思路
1、基于背景技术存在的技术问题,本发明提出了一种在线辅助语音对话场景的多模态情感提示方法及系统,实现了对在线辅助语音对话场景下语音情感的精准分析与提示。
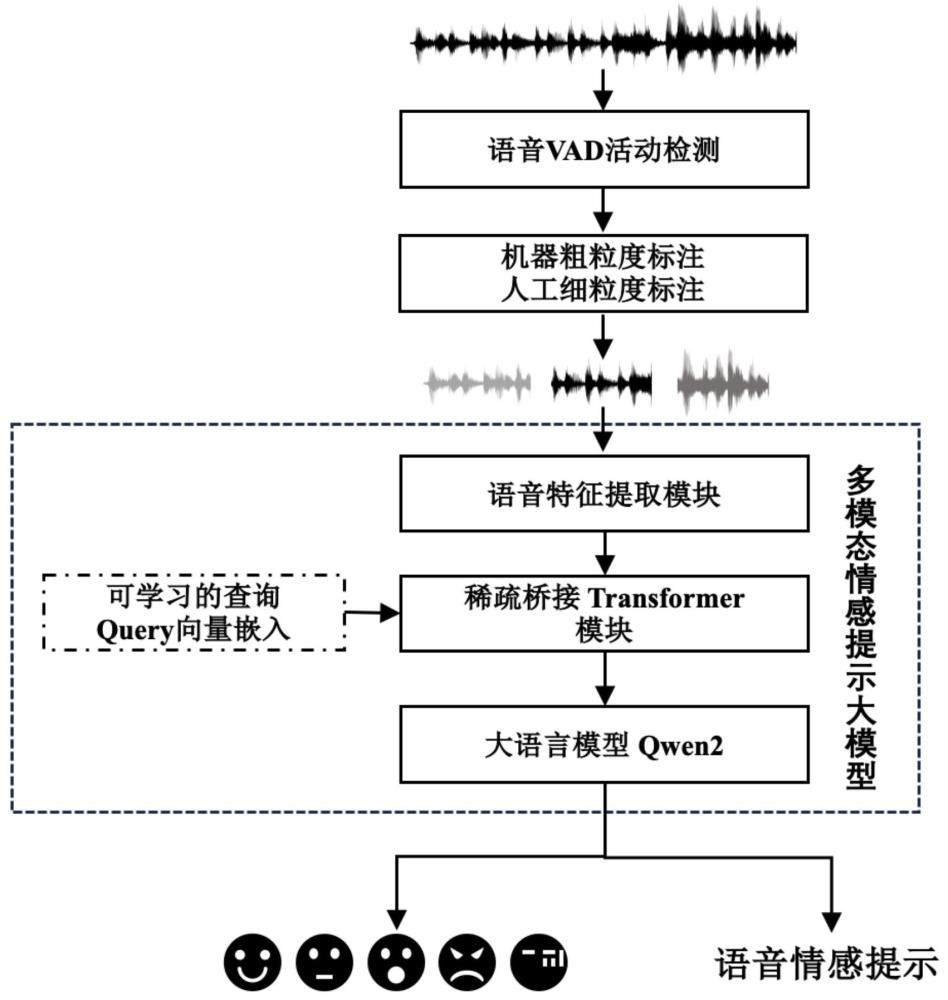
2、本发明提出的一种在线辅助语音对话场景的多模态情感提示方法,将语音对话场景中的语音信号输入到训练好的多模态情感提示大模型中,输出情感标签及语音情感提示信息;
3、所述多模态情感提示大模型的训练过程如下:
4、构建情感识别的训练数据集;
5、对训练数据集中的原始语音数据进行特征提取后输入到稀疏桥接transformer模块中,得到融合特征;
6、将融合特征输入到大语言模型中,通过文本解码生成连贯的语音情感提示信息,构建总损失函数,反向传播调整多模态情感提示大模型的可训练参数。
7、进一步地,在步骤一中,训练数据集的构建如下:
8、对获取的原始语音数据集合进行降噪处理、归一化处理和滤波操作,去除环境噪声并增强语音信号的清晰度,得到处理后的语音数据集合,,表示第个语音数据;
9、使用语音活动检测算法计算处理后的每条语音数据中每一帧的短时能量并设定阈值,当时,将对应帧标记为语音活动区,当时,将对应帧标记为静音区;
10、根据语音活动区和静音区信息,检测处理后的每条语音数据中的停顿端点,将处理后的每条语音数据划分成多个独立的语音片段,得到组高保真的语音片段集合;
11、对每个语音片段关联情感标签,以构建训练数据集。
12、进一步地,在对每个独语音片段关联情感标签中,具体包括:
13、粗粒度标签生成:对于每个语音片段,通过情感分类模型计算情感类别的概率分布并降序排列,将排在第一位的情感类别分配给对应语音片段,作为粗粒度标签;
14、细粒度标签生成:人工根据语音片段的情感特征及情境,将粗粒度标签转换为符合情感表达的细粒度标签,并将细粒度标签通过映射函数映射得到对应语音片段的情感标签。
15、进一步地,融合特征的生成过程如下:
16、对训练数据集中的原始语音数据进行特征提取,得到原始语音特征向量;
17、设计prompt提示词并转换为文本向量,将原始语音特征向量输入到稀疏桥接transformer模块中,将查询q-query与稀疏自注意力机制的键和值进行匹配,生成语音情感向量,将语音情感向量作为查询,将原始语音特征向量作为键和值,基于稀疏交叉注意力机制计算得到对齐后的语音情感向量,将文本向量与经过线性层处理后的语音情感向量融合得到融合特征,所述q-query是随机初始化的可学习向量。
18、进一步地,在步骤三中,对齐后的语音情感向量生成如下:
19、;
20、;
21、其中,为语音情感向量,为对齐后的语音情感向量,为激活函数,为查询q-query,用于提取原始语音特征向量的可学习参数,、、分别为稀疏自注意力机制的查询矩阵、键矩阵和值矩阵,、、分别为稀疏交叉注意力机制的查询矩阵、键矩阵和值矩阵,为原始语音特征向量,为键向量的维度。
22、进一步地,在步骤三中,将文本向量与经过线性层处理后的语音情感向量融合得到融合特征,具体为:
23、将经过线性层处理后的语音情感向量拼接在文本向量之后,得到融合特征。
24、进一步地,在步骤四中,总损失函数构建过程如下:
25、基于语音-转录互信息学习构建互信息损失;
26、基于预测输出的语音情感提示信息与人工标注的真实字幕构建交叉熵损失;
27、将互信息损失和交叉熵损失相加得到总损失函数。
28、进一步地,总损失函数如下:
29、;
30、;
31、;
32、其中,为交叉熵损失,为互信息损失,分别表示交叉熵损失和互信息损失的权重系数,为第个语音数据,表示语音数据的总数,表示第个语音数据对应人工标注的真实标签,表示在输入数据属于情感标签的概率,为原始语音特征向量与文本向量之间的互信息量,表示原始语音特征向量中特征的边际概率分布,表示文本向量中特征的边际概率分布,表示特征和特征之间的联合分布概率。
33、进一步地,在步骤二中,基于wavlm预训练语音模型对对训练数据集中的原始语音数据进行特征提取,得到原始语音特征向量。
34、一种在线辅助语音对话场景的多模态情感提示系统,将语音对话场景中的语音信号输入到训练好的多模态情感提示大模型中,输出情感标签及语音情感提示信息;
35、所述多模态情感提示大模型的训练过程包括数据准备与语音特征提取模块、稀疏桥接transformer模块、大语言模型模块以及损失构建模块;
36、所述数据准备与语音特征提取模块用于构建情感识别的训练数据集,对情感识别的训练数据集中的原始语音数据进行特征提取,得到原始语音特征向量;
37、所述稀疏桥接transformer模块用于对所输入的原始语音特征向量处理,得到融合特征;
38、所述大语言模型模块用于将融合特征输入到大语言模型中,通过文本解码生成连贯的语音情感提示信息;
39、所述损失构建模块用于构建总损失函数,反向传播调整多模态情感提示大模型的可训练参数。
40、本发明提供的一种在线辅助语音对话场景的多模态情感提示方法及系统的优点在于:结合了数据准备与语音特征提取模块、稀疏桥接transformer模块、大语言模型模块以及损失构建模块,实现了对在线辅助语音对话场景下语音情感的精准分析与提示;该架构设计使得多模态情感提示大模型能够在不同情感层次上提取并捕捉语音信号中的丰富声学特征,如语义、语气、语调等,从而显著提升了情感分析的精度和连贯性;通过稀疏桥接transformer模块的稀疏自注意力和稀疏交叉注意力机制,进一步强化了语音特征与文本向量的对齐效果,从而增强了情感提示信息的准确性。此外,构建的总损失函数结合了交叉熵和互信息学习等优化策略,使多模态情感提示大模型在训练过程中逐步优化情感标签和提示信息的匹配度,为在线语音情感分析和情感提示生成提供了强大的支持,有效克服了传统模型在复杂对话情感场景下的适应性和表达不充分的问题。
- 还没有人留言评论。精彩留言会获得点赞!