一种超级芯片及其制备方法和应用与流程
本发明涉及生物技术领域,具体地,本发明涉及一种超级芯片及其制备方法和应用。
背景技术:
全基因组测序是对已知基因组序列的物种进行不同个体的基因组测序,并在此基础上对个体或群体进行差异性分析。一般来讲,全基因组测序包括以下步骤:提取基因组DNA,随机打断,电泳回收所需长度的DNA片段(0.2-5Kb),加接头,进行基因簇制备或电子扩增,对片段进行测序,通过生物信息手段,分析不同个体基因组间的结构差异,完成SNP或基因组结构性变异查找和注释。全基因组测序虽然在最近几年内的价格大幅下降,但其作为大规模的检测变异的方法,价格仍然不菲。外显子重测序渐渐成为一种检验和疾病相关的基因的标准工具,但现有的芯片覆盖的基因组的范围较小,很多区域无法捕获到,致使和疾病相关的一些基因无法通过外显子测序研究。目前本领域内尚缺乏能检测多种疾病的芯片及其制备方法,因此严重阻碍了疾病的筛选和诊断。因此本领域迫切需要开发针对多种疾病检测和诊断的芯片及其制备方法。
技术实现要素:
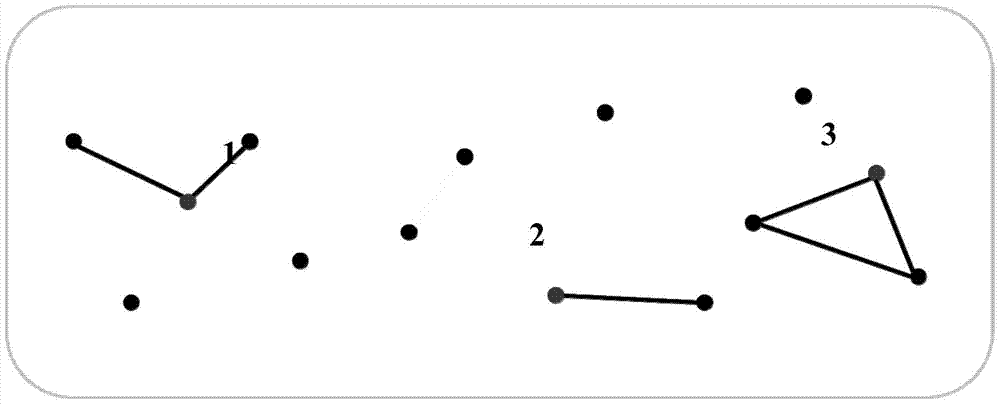
本发明的目的是提供一种超级芯片及其应用。本发明的另一目的是提供一种超级芯片的制备方法。在本发明的第一方面,提供了一种超级芯片,所述超级芯片包括核酸检测区,各核酸检测区包括多个检测点,各检测点固定有用于与待检测核酸杂交的寡核苷酸探针,所述的检测区包括:(a)外显子检测区;(b)Tag-SNP检测区;和(c)白细胞抗原检测区。在另一优选例中,所述芯片具有固相载体,较佳地,所述的固相载体为基片或微球,更佳地,所述的固相载体为荧光微球,最佳地为聚苯乙烯微球。在另一优选例中,所述芯片为:包括探针组合物的液相芯片。在另一优选例中,所述检测区还包括:(d)单基因病检测区。在另一优选例中,所述的单基因病选自下组:3β-羟类固醇脱氢酶缺陷症;3-甲基巴豆酰辅酶A羧化酶缺乏症;3-羟酰辅酶A脱氢酶缺乏症;Alagille综合症(先天性胆道闭锁综合症);Alport综合征(遗传性肾炎);Apert综合征;Arts综合征;Diamond-Blackfan贫血(先天性纯红细胞再生障碍性贫血);Emery-Dreifuss型肌营养不良;Friedreich共济失调;Gilbert综合症;Jackson-Weiss颅缝早闭综合征;Joubert综合症;Marshall综合症;Meckel综合征;Pallister-Hall综合征;QT间期延长综合征;Waardenburg综合征;Weissenbacher-Zweymuller综合征;Wolfram综合征1型;X连锁铁粒幼细胞贫血;红细胞生成性原卟啉症;先天性角化不全症;X连锁型鱼鳞病;X连锁性视网膜色素变性3型;X连锁隐性耳聋;X连锁重症联合免疫缺陷;β地中海贫血;氨甲酰磷酸合成酶缺乏症;巴特综合征;半胱氨酸尿症;半乳糖血症;丙二酰辅酶A脱羧酶缺乏症;丙酸血症;丙酮酸羧化酶缺乏症;丙酮酸脱氢酶复合物E3结合蛋白缺乏症;丙酮酸脱氢酶磷酸酶缺乏症;丙酮酸脱羧酶缺乏症;长链酰基辅酶A脱氢酶缺陷症;常染色体显性非综合征型耳聋;常染色体显性营养不良性大疱性表皮松解;常染色体隐性多囊性肾病;常染色体隐性非综合征型耳聋;成骨不全;丑胎(丑角样鱼鳞病);板层性鱼鳞病;单纯性三角头畸形;短链羟酰基辅酶A脱氢酶缺乏症;短链酰基辅酶A脱氢酶缺乏症;多巴反应性肌张力障碍(张力障碍);多发性内分泌腺瘤病;多种酰基辅酶A脱氢酶缺乏症;苯丙酮尿症;法布瑞氏症;范可尼贫血;非酮症性高甘氨酸血症;腓骨肌萎缩症;枫糖尿病(支链酮酸尿症);肝豆状核变性;高脯氨酸血症II型;高脯氨酸血症I型;高甲硫氨酸血症;高鸟氨酸血症;各型鱼鳞病;共济失调伴选择性维生素E缺乏症;共济失调性毛细血管扩张症;骨硬化症;瓜胺酸血症;赫尔勒综合征(粘多糖贮积病1H型);黑斑息肉综合征;活化蛋白C抵抗引起的易栓症;肌-眼-脑病;极长链酰基辅酶A脱氢酶缺乏症;脊髓性肌萎缩(脊肌萎缩症,SMA);家族性腺瘤性息肉病;甲基丙二酸血症;假性软骨发育不全;渐冻人症;交界型大疱性表皮松解症,赫利茨型;角化症掌跖病纹状体;结节性硬化病;进行性肌阵挛性癫痫;进行性家族性肝内胆汁瘀积;进行性假肥大性肌营养不良症;精氨酸琥珀酸尿症;精氨酸酶缺乏症;胫骨肌营养不良症;局灶性节段性肾小球硬化症;克拉伯病;酪氨酸羟化酶缺乏症(Segawa综合征);酪氨酸血症;硫解酶缺乏症;马凡综合症;囊性纤维化;尼曼-皮克病;尼曼-皮克病(磷脂贮积症);年龄相关性黄斑变性;胼胝体发育不全及周围神经病变;葡萄糖-6-磷酸脱氢酶缺乏症;强直性肌营养不良1型;肉毒碱棕榈酰转移酶I缺乏症;II缺乏症;肉碱棕榈酰转移酶Ⅱ缺乏症;肉碱棕榈酰转移酶I缺乏症;沙勒沃伊-萨格奈常染色体隐性遗传痉挛性共济失调;神经节苷脂贮积症;神经纤维瘤病;神经元蜡样质脂褐质沉积症1型;肾病型胱胺酸症;史蒂克勒氏综合征;视网膜色素变性;舒-戴二氏综合症;双氢嘧啶脱氢酶缺乏症;糖原累积病;特雷彻-柯林斯综合征;天冬氨酰葡萄糖胺尿症;同型半胱氨酸尿症;同型瓜氨酸尿症综合症;透克氏症;瓦登伯格综合征;戊二酸血症I型;先天性纯巨核细胞再障血小板减少症;先天性胆汁淤积;先天性耳聋伴甲状腺肿大(Pendred综合征);先天性肌强直;先天性肌弛缓;先天性甲状腺功能减退症;先天性软骨发育不全;先天性视网膜劈裂症;先天性糖蛋白糖基化缺陷Ia型;显性多发性骨骺发育异常(MED);小儿异染性脑白质营养不良;新生儿永久性糖尿病;新生儿致命的软骨发育不良;新生儿重症脑病;血友病;牙本质发育不全;延森氏综合征;Mohr-Tranebjaerg综合征;眼白化病;遗传性X连锁性痉挛性截瘫;遗传性多发性外生骨疣;软骨肉瘤;遗传性非息肉病性结直肠癌(Lynch综合征);遗传性非息肉性结直肠癌2型;遗传性共济失调性多发性神经炎样病(Refsum综合征);遗传性果糖不耐症;遗传性家族性颅面骨发育不全;遗传性酪氨酸血症1型;遗传性乳腺癌;遗传性显性痉挛性截瘫;遗传性眼球萎缩病;遗传性隐性痉挛性截瘫;异戊酸血症;隐性多发性骨骺发育异常(MED);尤塞氏综合症;有汗型外胚层发育不良;幼婴癫痫性脑病;原发性高草酸盐尿症2型;早年衰老综合症;扩张型心肌病1A型;肢带型肌营养不良症;粘多糖贮积症Ⅱ型;掌跖角化病(掌跖硬化病);肢带型进行性肌肉萎缩症;中链酰基辅酶A脱氢酶缺乏症;侏儒-面部毛细血管扩张综合征(布卢姆综合征);综合征型耳聋;组氨酸血症;家族性腺瘤样息肉病;软骨发育不良;家族性高胆固醇血症;多指畸形;马凡综合症;遗传性舞蹈病;秃发;胱氨酸尿症;遗传性高度近视;抗D佝偻病;血友病;节性脑硬化综合症;杜氏肌营养不良;进行性肌营养不良;多囊肾综合症;性别决定基因突变所致的性反转,或其组合。在另一优选例中,所述外显子检测区覆盖20-100M大小的基因组区域。在另一优选例中,所述外显子检测区覆盖35M-70M大小的基因组区域,较佳地,覆盖45M大小的基因组区域。在另一优选例中,所述检测区的探针特异性地针对人或非人哺乳动物的核苷酸序列。在另一优选例中,所述的Tag-SNP检测区用于检测在个人基因组中存在的SNP。在另一优选例中,所述的用于检测Tag-SNP的寡核苷酸探针是对泛基因组的SNP进行聚类并挑选Tag-SNP而获得的。在另一优选例中,Tag-SNP的寡核苷酸探针包括序列如SEQIDNO.1-SEQIDNO.10任一所示的探针。在本发明的第二方面,提供了本发明第一方面所述超级芯片的用途,所述超级芯片用于获取人基因组的核苷酸序列信息。在另一优选例中,所述的核苷酸序列信息包括SNP信息。在本发明的第三方面,提供了一种超级芯片的制备方法,包括步骤:将寡核苷酸探针组成包括多个检测点的检测区,所述检测区包括:(a1)外显子检测区;(b1)Tag-SNP检测区;和(c1)白细胞抗原检测区。在另一优选例中,所述检测区还包括:(d1)单基因病检测区。在另一优选例中,所述芯片具有固相载体,较佳地,所述固相载体为基片或微球,更佳地,所述固相载体为荧光微球,最佳地为聚苯乙烯微球。在另一优选例中,所述芯片为:包括探针组合物的液相芯片。在另一优选例中,所述方法还包括位于在点样之前的以下步骤:(i)从数据库中过滤筛选SNP,获得初始SNP数据集;(ii)从初始SNP数据集中选择标签SNP(Tag-SNP);(iii)合成针对标签SNP的寡核苷酸。在另一优选例中,步骤(i)中的初始SNP满足下述条件:在数据库所选人群中多态性碱基型为二种的位点;在数据库所选人群中,数据缺失率<0.1的位点;等位基因碱基型出现次数大于一次的位点。在另一优选例中,步骤(ii)中的Tag-SNP包括:标准的Tag-SNP部分;和Y染色体Tag-SNP部分。在另一优选例中,标准的Tag-SNP是通过最优聚类,根据连锁不平衡数据,将群体多态位点聚类并挑选获得的。在本发明的第四方面,提供了一种筛选标签SNP(Tag-SNP)的方法,包括步骤:(A)从数据库中过滤筛选SNP,获得初始SNP数据集;(B)从初始SNP数据集中,通过最优聚类,根据连锁不平衡数据,将群体多态位点聚类获得,从而选出标签SNP。在本发明的第五方面,提供了一种试剂盒,包括一容器以及位于所述容器内的本发明第一方面所述的超级芯片。在另一优选例中,试剂盒还包括任选自下组的试剂:测序用引物;PCR反应试剂及纯化试剂;测序芯片;或其组合。应理解,在本发明范围内中,本发明的上述各技术特征和在下文(如实施例)中具体描述的各技术特征之间都可以互相组合,从而构成新的或优选的技术方案。限于篇幅,在此不再一一累述。附图说明下列附图用于说明本发明的具体实施方案,而不用于限定由权利要求书所界定的本发明范围。图1显示了群体多态SNP位点,各个点代表孤点。图2显示了孤点初始化结果,黑线代表的是连接数(此时R2阈值为0.99),点1-3代表tag-SNP。图3显示了最优聚类的结果,点1-3代表tag-SNP,孤点和孤点发生连接,直接聚集成一个新的簇,并挑选假定tag-SNP(图3标“a”处);簇和孤点发生连接,如果可以产生符合条件的tag-SNP,则簇将孤点吞并,并更新tag-SNP,否则,不发生任何吞并(图3标“b”处);簇和簇发生连接,如果可以产生符合条件的tag-SNP,则簇的合并,并更新tag-SNP,否则,不发生任何吞并(图3标“c”处)。图4显示了最终聚类结果,包括每个簇的组成、假定tag-SNP等信息,虚线段代表R2超过最低阈值,但是不满足合并条件。图5显示了在本发明的一个优选例中,超级芯片(ALLINONE)的基本组成。图6显示了本发明超级芯片(ALLINONE)和对照组芯片(Asiom_GW_ASI)对基因组覆盖程度检测结果,结果表明,本发明的超级芯片对全基因组的覆盖度会比对照(Asiom_GW_ASI)要高。图7显示了本发明的超级芯片(ALLINONE)和对照组芯片(Asiom_GW_ASI)的MAF分布的检测结果,结果表明,超级芯片的MAF比对照组要低,特别在2.5%~10%这个区间尤为集中,表明超级芯片对流行病学的研究非常有利。图8显示了本发明的超级芯片(ALLINONE)和对照组芯片对tag-SNP覆盖度的检测结果。图9显示了超级芯片(ALLINONE)和对照组芯片对tag-SNP之间距离检测结果,结果表明,超级芯片(ALLINONE)的tag-SNP之间的距离更接近1kb,探针距离分布比较接近SNP的自然发生距离,而且明显比对照组Asiom_GW_ASI更密集。图10显示了tag-SNP单碱基深度分布图。具体实施方式本发明人经过广泛而深入的研究,首次开发了一种能够筛选群体特异性和代表性位点的超级芯片(ALLINONE),所述超级芯片至少包括外显子检测区,Tag-SNP检测区,人类白细胞抗原(HLA)检测区。所述超级芯片能够在短时间内检测多种疾病,与现有芯片相比,疾病覆盖率大,大大提高捕获区域,并显著降低了检测成本。本发明还提供了所述芯片的制备方法和用途。在此基础上完成了本发明。术语如本文所用,术语“含有”包括“具有(comprise)”、“基本上由…构成”和“由…构成”。如本文所用,术语“以上”和“以下”包括本数,例如“80%以上“指≥80%,“2%以下”指≤2%。单核苷酸多态性(SNP)SNP是指在基因组上单个核苷酸的变异,包括置换、颠换等情况。SNP形成的遗传标记数量很多,多态性丰富。转换和颠换二者之比一般为2:1。SNP在CG序列上出现最为频繁,而且多是C转换为T,原因是CG中的C常为甲基化的,自发地脱氨后即成为胸腺嘧啶。它是人类可遗传的变异中最常见的一种,占所有已知多态性的90%以上。正因为如此,SNP成为第三代遗传标志,人体的许多表型差异,如对药物或疾病的易感性等都可能与SNP有关。SNP检测作为一个强有力的工具,可用于高危群体的发现、疾病相关基因的鉴定、药物的设计和测试以及生物学的基础研究等。大量存在的SNP位点,使人们有机会发现与各种疾病,包括肿瘤相关的基因组突变;从实验操作来看,通过SNP发现疾病相关基因突变要比通过家系来得容易;有些SNP并不直接导致疾病基因的表达,但由于它与某些疾病基因相邻,而成为重要的标记。SNP在基础研究中也发挥了巨大的作用,近年来对Y染色体SNP的分析,使得在人类进化、人类种群的演化和迁徙领域取得了一系列重要成果。SNP既有可能在基因序列内,也有可能在基因以外的非编码序列上,位于编码区内的SNP(codingSNP,cSNP)比较少,但它在遗传性疾病研究中却具有重要意义,因此cSNP的研究更受关注。SNP自身的特性决定了它非常适合于对复杂性状与疾病的遗传解剖以及基于群体的基因识别等方面的研究:1.SNP数量多,分布广泛。据估计,人类基因组中每1000个核苷酸就有一个SNP,人类30亿碱基中共有300万以上的SNPs;2.SNP适于规模化筛查,由于SNP的二态性,非此即彼,在基因组筛选中SNPs往往只需+/-的分析,而不用分析片段的长度,这就利于发展自动化技术筛选或检测SNPs;3.SNP等位基因频率容易估计;4.易于基因分型等。单基因病如本文所用,“单基因病”一词是指由一对等位基因控制的疾病或病理性状,又称孟德尔遗传病,可以分为常染色体显性遗传病、常染色体隐性遗传病、x伴性遗传病、Y伴性遗传病。常染色体显性遗传病致病基因定位于常染色体上,常见的亚型:完全显性:正常纯合子和杂合子的患者在表型上无差异;不完全显性:杂合子表现介于显性纯合子患者和正常人之间,常表现为轻病型;不规则显型:由于某种原因可使杂合子的显性基因不表现出相应的症状;共显性:等位基因之间无显性与隐性之分,在杂合体时都能表现两种基因作用;延迟显性:杂合子在生命早期显性基因不表达,待一定年龄后才表达;从性显性:杂合子的表达受性别的影响,在某一性别表达出相应的表现型,在另一性别不表达相应表现型。常染色体隐性遗传病的常染色体上的致病基因在杂合状态时不表现相应的疾病,而只在纯合子时才致病。定位于X染色体上的致病基因随X染色体而遗传疾病,包括X连锁显性遗传和X连锁隐性遗传。定位于Y染色体上的致病基因随Y染色体而遗传疾病。适用于本发明超级芯片的单基因病包括但不限于:在另一优选例中,所述的单基因病选自下组:3β-羟类固醇脱氢酶缺陷症;3-甲基巴豆酰辅酶A羧化酶缺乏症;3-羟酰辅酶A脱氢酶缺乏症;Alagille综合症(先天性胆道闭锁综合症);Alport综合征(遗传性肾炎);Apert综合征;Arts综合征;Diamond-Blackfan贫血(先天性纯红细胞再生障碍性贫血);Emery-Dreifuss型肌营养不良;Friedreich共济失调;Gilbert综合症;Jackson-Weiss颅缝早闭综合征;Joubert综合症;Marshall综合症;Meckel综合征;Pallister-Hall综合征;QT间期延长综合征;Waardenburg综合征;Weissenbacher-Zweymuller综合征;Wolfram综合征1型;X连锁铁粒幼细胞贫血;红细胞生成性原卟啉症;先天性角化不全症;X连锁型鱼鳞病;X连锁性视网膜色素变性3型;X连锁隐性耳聋;X连锁重症联合免疫缺陷;β地中海贫血;氨甲酰磷酸合成酶缺乏症;巴特综合征;半胱氨酸尿症;半乳糖血症;丙二酰辅酶A脱羧酶缺乏症;丙酸血症;丙酮酸羧化酶缺乏症;丙酮酸脱氢酶复合物E3结合蛋白缺乏症;丙酮酸脱氢酶磷酸酶缺乏症;丙酮酸脱羧酶缺乏症;长链酰基辅酶A脱氢酶缺陷症;常染色体显性非综合征型耳聋;常染色体显性营养不良性大疱性表皮松解;常染色体隐性多囊性肾病;常染色体隐性非综合征型耳聋;成骨不全;丑胎(丑角样鱼鳞病);板层性鱼鳞病;单纯性三角头畸形;短链羟酰基辅酶A脱氢酶缺乏症;短链酰基辅酶A脱氢酶缺乏症;多巴反应性肌张力障碍(张力障碍);多发性内分泌腺瘤病;多种酰基辅酶A脱氢酶缺乏症;苯丙酮尿症;法布瑞氏症;范可尼贫血;非酮症性高甘氨酸血症;腓骨肌萎缩症;枫糖尿病(支链酮酸尿症);肝豆状核变性;高脯氨酸血症II型;高脯氨酸血症I型;高甲硫氨酸血症;高鸟氨酸血症;各型鱼鳞病;共济失调伴选择性维生素E缺乏症;共济失调性毛细血管扩张症;骨硬化症;瓜胺酸血症;赫尔勒综合征(粘多糖贮积病1H型);黑斑息肉综合征;活化蛋白C抵抗引起的易栓症;肌-眼-脑病;极长链酰基辅酶A脱氢酶缺乏症;脊髓性肌萎缩(脊肌萎缩症,SMA);家族性腺瘤性息肉病;甲基丙二酸血症;假性软骨发育不全;渐冻人症;交界型大疱性表皮松解症,赫利茨型;角化症掌跖病纹状体;结节性硬化病;进行性肌阵挛性癫痫;进行性家族性肝内胆汁瘀积;进行性假肥大性肌营养不良症;精氨酸琥珀酸尿症;精氨酸酶缺乏症;胫骨肌营养不良症;局灶性节段性肾小球硬化症;克拉伯病;酪氨酸羟化酶缺乏症(Segawa综合征);酪氨酸血症;硫解酶缺乏症;马凡综合症;囊性纤维化;尼曼-皮克病;尼曼-皮克病(磷脂贮积症);年龄相关性黄斑变性;胼胝体发育不全及周围神经病变;葡萄糖-6-磷酸脱氢酶缺乏症;强直性肌营养不良1型;肉毒碱棕榈酰转移酶I缺乏症;II缺乏症;肉碱棕榈酰转移酶Ⅱ缺乏症;肉碱棕榈酰转移酶I缺乏症;沙勒沃伊-萨格奈常染色体隐性遗传痉挛性共济失调;神经节苷脂贮积症;神经纤维瘤病;神经元蜡样质脂褐质沉积症1型;肾病型胱胺酸症;史蒂克勒氏综合征;视网膜色素变性;舒-戴二氏综合症;双氢嘧啶脱氢酶缺乏症;糖原累积病;特雷彻-柯林斯综合征;天冬氨酰葡萄糖胺尿症;同型半胱氨酸尿症;同型瓜氨酸尿症综合症;透克氏症;瓦登伯格综合征;戊二酸血症I型;先天性纯巨核细胞再障血小板减少症;先天性胆汁淤积;先天性耳聋伴甲状腺肿大(Pendred综合征);先天性肌强直;先天性肌弛缓;先天性甲状腺功能减退症;先天性软骨发育不全;先天性视网膜劈裂症;先天性糖蛋白糖基化缺陷Ia型;显性多发性骨骺发育异常(MED);小儿异染性脑白质营养不良;新生儿永久性糖尿病;新生儿致命的软骨发育不良;新生儿重症脑病;血友病;牙本质发育不全;延森氏综合征;Mohr-Tranebjaerg综合征;眼白化病;遗传性X连锁性痉挛性截瘫;遗传性多发性外生骨疣;软骨肉瘤;遗传性非息肉病性结直肠癌(Lynch综合征);遗传性非息肉性结直肠癌2型;遗传性共济失调性多发性神经炎样病(Refsum综合征);遗传性果糖不耐症;遗传性家族性颅面骨发育不全;遗传性酪氨酸血症1型;遗传性乳腺癌;遗传性显性痉挛性截瘫;遗传性眼球萎缩病;遗传性隐性痉挛性截瘫;异戊酸血症;隐性多发性骨骺发育异常(MED);尤塞氏综合症;有汗型外胚层发育不良;幼婴癫痫性脑病;原发性高草酸盐尿症2型;早年衰老综合症;扩张型心肌病1A型;肢带型肌营养不良症;粘多糖贮积症Ⅱ型;掌跖角化病(掌跖硬化病);肢带型进行性肌肉萎缩症;中链酰基辅酶A脱氢酶缺乏症;侏儒-面部毛细血管扩张综合征(布卢姆综合征);综合征型耳聋;组氨酸血症;家族性腺瘤样息肉病;软骨发育不良;家族性高胆固醇血症;多指畸形;马凡综合症;遗传性舞蹈病;秃发;胱氨酸尿症;遗传性高度近视;抗D佝偻病;血友病;节性脑硬化综合症;杜氏肌营养不良;进行性肌营养不良;多囊肾综合症;性别决定基因突变所致的性反转,或其组合。外显子及外显子组如本文所用,“外显子”一词是指在成熟mRNA中被保留下的部分,即成熟mRNA对应于基因中的部分。内含子是在mRNA加工过程中被剪切掉的部分,在成熟mRNA中不存在。外显子和内含子都是对于基因而言的,编码的部分为外显子,不编码的为内含子,内含子没有遗传效应。如本文所用,“外显子组”一词是指样本在一定的时刻所有表达的外显子的组合。人类白细胞抗原(HLA)人类白细胞抗原HLA是具有高度多态性的同种异体抗原,其化学本质为一类糖蛋白,由一条α重链(被糖基化的)和一条β轻链非共价结合而成,其肽链的氨基端向外(约占整个分子的3/4),羧基端穿入细胞质,中间疏水部分在胞膜中。HLA按其分布和功能分为Ⅰ类抗原和Ⅱ类抗原。HLA的多态性极为突出。保守估计,至少存在1300个不同的单体型,相应地约有17×107个基因型。这就是除同卵双生子以外几乎无HLA相同者的遗传基础,从而HLA可视作个体的“身份证”,作为疾病检测的标志。泛基因组(pan-genome)如本文所用,“泛基因组”一词是某一物种全部基因的总称,泛基因组包括核心基因组(coregenome)以及非必须基因组。核心基因组是在某一物种的群体中普遍存在的基因;非必须基因组是在部分群体中存在的基因。在实际研究中,泛基因组也可以分成核心基因组(在所有群体中都存在的基因)、非必须基因组(在2个以及2个以上的群体中存在的基因),以及群体特有基因(strains-specificgene,即仅在某一个群体中存在的基因)。根据物种的泛基因组大小与群体数目的关系,将物种的泛基因组分为开放型(open)泛基因组和闭合型(close)泛基因组。开放型的泛基因组是指,随着测序的基因组数目的增加,物种的泛基因组大小也不断增加。闭合性的泛基因组是指,随着测序的基因组数目增加,物种的泛基因组大小增加到一定的程度后收敛于某一值。本发明的超级芯片包括了通过pan-genome分析策略获得的SNP数据,用于疾病检测和筛选。芯片本发明提供了一种芯片及其制备方法。芯片包括核酸检测区,各核酸检测区包括多个检测点,各检测点固定有用于与待检测核酸杂交的寡核苷酸探针,所述的检测区包括:外显子检测区、Tag-SNP检测区和白细胞抗原检测区。在本发明另一优选例中,所述芯片具有固相载体,较佳地,固相载体为基片或微球,更佳地,所述固相载体为荧光微球,最佳地为聚苯乙烯微球。在本发明的另一优选例中,所述芯片为包括探针组合物的液相芯片。超级芯片(ALLINONE)本发明提供了一种超级芯片,所述芯片表面的探针种类可达上百万种,能一次对同一个待测样品检测多种疾病。该超级芯片能覆盖人类的外显子区域和多达几百种疾病相关的基因,大约150M的基因区域。该超级芯片具有外显子检测区,Tag-SNP检测区,人类白细胞抗原(HLA)检测区,在一个优选例中,还包括单基因病致病基因检测区。本发明超级芯片的外显子检测区包括目前最新的约50M大小的基因组区域,提供功能基因相关变异信息;Tag-SNP检测区涵盖人种中的代表性信息,该部分通过对现有公共SNP数据以及泛基因组(pan-genome)分析策略获得的数据进行筛选得到,对挖掘研究样品中群体特异性基因组信息有显著价值;ALLINONE还整合了整个HLA区域的信息。由于该区域和疾病的发生以及免疫具有密切关系,因此该部分信息的涵盖无论对人类疾病的机理研究还是药物研发具有重要意义。在一个优选例中,还可以把已经确认的致病基因,尤其是孟德尔疾病致病基因位点设计到ALLINONE中,从而提供更丰富的数据。本发明还提供了一种超级芯片的制备方法,包括步骤:将寡核苷酸探针组成包括多个检测点的检测区,所述检测区包括:(a1)外显子检测区;(b1)Tag-SNP检测区;和(c1)白细胞抗原检测区。在另一优选例中,所述检测区还包括:(d1)单基因病检测区。在另一优选例中,所述芯片具有固相载体,较佳地,固相载体包括基片或微球,更佳地,所述微球为荧光微球,最佳地为聚苯乙烯微球。在另一优选例中,所述芯片为包括探针组合物的液相芯片。外显子数据来源基于ensembl,refgene,CCDS及genecode数据的库整合。ensembl:ftp://ftp.ensembl.org/pub/current/gtf/homo_sapiens/Homo_sapiens.GRCh37.61.gtf.gzrefgene:ftp://hgdownload.cse.ucsc.edu/goldenPath/hg19/database/refGene.txt.gzCCDS:ftp://ftp.ncbi.nih.gov/pub/CCDS/current_human/CCDS.current.txtgenecode:ftp://ftp.sanger.ac.uk/pub/gencode/exome/GENCODE_exome_design_target.gtf.gzHLA区域数据来源:http://www.ebi.ac.uk/imgt/hla/单基因病致病基因区域数据来源于孟德尔在线:http://www.ncbi.nlm.nih.gov/omim,http://omim.org/这些外显子、HLA区域以及单基因病致病基因区域的数据库的信息可通过公开途径获得。在一个优选例中,所述方法还包括位于在点样之前的以下步骤:i.从数据库中过滤筛选SNP,获得初始SNP数据集;ii.从初始SNP数据集中选择标签SNP;iii.合成针对标签SNP的寡核苷酸。在步骤(i)中,初始SNP满足下列三个条件:在数据库所选人群中多态性碱基型为二种的位点;在数据库所选人群中,数据缺失率<0.1的位点;等位基因碱基型出现次数大于一次的位点。在步骤(ii)中,Tag-SNP包括标准的Tag-SNP部分和Y染色体Tag-SNP部分。探针如本文所用,“探针”一词是指能够检测互补核酸序列的简单DNA或RNA分子。探针必须是纯净的,而且不受其他不同序列核酸的影响。典型的探针是克隆的DNA序列或通过PCR扩增获得的DNA,人工合成的寡核苷酸或从体外转录克隆DNA序列后获得的RNA,也可以作为探针。探针长度可以从20-120mer,较佳地50-100mer,更佳地60-90mer。探针设计和合成方法为本领域技术人员所熟知,根据单基因病的已知的致病基因的外显子及其前后两端序列(较佳地前后200bp左右),设计探针。在一个优选例中,探针长度50-80mer。可以使用人工化学合成法合成探针或使用市售探针。本发明的核酸探针根据Tag-SNP设计而来,如,Tag-SNP的寡核苷酸探针包括序列如SEQIDNO.1-SEQIDNO.10任一所示的探针。引物如本文所用,术语“引物”指的是能与模板互补配对,在DNA聚合酶的作用合成与模板互补的DNA链的寡聚核苷酸的总称。引物可以是天然的RNA、DNA,也可以是任何形式的天然核苷酸,引物甚至可以是非天然的核苷酸如LNA或ZNA等。引物“大致上”(或“基本上”)与模板上一条链上的一个特殊的序列互补。引物必须与模板上的一条链充分互补才能开始延伸,但引物的序列不必与模板的序列完全互补。比如,在一个3’端与模板互补的引物的5’端加上一段与模板不互补的序列,这样的引物仍大致上与模板互补。只要有足够长的引物能与模板充分的结合,非完全互补的引物也可以与模板形成引物-模板复合物,从而进行扩增。高通量测序基因组的“再测序”使得人类能够尽早地发现与疾病相关基因的异常变化,有助于对个体疾病的诊断和治疗进行深入的研究。本领域技术人员通常可以采用三种第二代测序平台进行高通量测序:454FLX(Roche公司)、SolexaGenomeAnalyzer(Illumina公司)和AppliedBiosystems公司的SOLID等。这些平台共同的特点是极高的测序通量,相对于传统测序的96道毛细管测序,高通量测序一次实验可以读取40万到400万条序列,根据平台的不同,读取长度从25bp到450bp不等,因此不同的测序平台在一次实验中,可以读取1G到14G不等的碱基数。其中,Solexa高通量测序包括DNA簇形成和上机测序两个步骤:PCR扩增产物的混合物与固相载体上固定的测序探针进行杂交,并进行固相桥式PCR扩增,形成测序簇;对所述测序簇用“边合成-边测序法”进行测序,从而得到样本中核酸分子的核苷酸序列。DNA簇的形成是使用表面连有一层单链引物(primer)的测序芯片(flowcell),单链状态的DNA片段通过接头序列与芯片表面的引物通过碱基互补配对的原理被固定在芯片的表面,通过扩增反应,固定的单链DNA变为双链DNA,双链再次变性成为单链,其一端锚定在测序芯片上,另一端随机和附近的另一个引物互补从而被锚定,形成“桥”;在测序芯片上同时有上千万个DNA单分子发生以上的反应;形成的单链桥,以周围的引物为扩增引物,在扩增芯片的表面再次扩增,形成双链,双链经变性成单链,再次成为桥,称为下一轮扩增的模板继续扩增;反复进行了30轮扩增后,每个单分子得到1000倍扩增,称为单克隆的DNA簇。DNA簇在Solexa测序仪上进行边合成边测序,测序反应中,四种碱基分别标记不同的荧光,每个碱基末端被保护碱基封闭,单次反应只能加入一个碱基,经过扫描,读取该次反应的颜色后,该保护集团被除去,下一个反应可以继续进行,如此反复,即得到碱基的精确序列。在Solexa多重测序(MultiplexedSequencing)过程中会使用Index(标签)来区分样品,并在常规测序完成后,针对Index部分额外进行7个循环的测序,通过Index的识别,可以在1条测序甬道中区分12种不同的样品。Tag-SNP的筛选方法此外,本发明还提供了一种Tag-SNP的筛选方法。在一个优选例中,所述方法包括步骤:i.从数据库中过滤筛选SNP,获得初始SNP数据集;ii.从初始SNP数据集中,通过最优聚类,根据连锁不平衡数据,将群体多态位点聚类获得,从而选出Tag-SNP。试剂盒本发明还提供了一种试剂盒,所述试剂盒包括:容器以及位于容器内本发明的超级芯片。在本发明的一个优选例中,试剂盒还包括任选自下组的试剂:测序用引物;PCR反应试剂及纯化试剂;测序芯片;或其组合。本发明的主要优点1.本发明的超级芯片整合多种检测区域,如外显子检测区,Tag-SNP检测区,人类白细胞抗原(HLA)检测区,以及单基因病检测区等;2.该超级芯片疾病覆盖率大,能够在短时间内检测多达300种或更多种类的疾病。与现有芯片相比,大大提高捕获区域,疾病覆盖率大,检测完全;3.与全基因测序相比,大大降低了检测成本。下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。下列实施例中未注明具体条件的实验方法,通常按照常规条件如Sambrook等人,分子克隆:实验室手册(NewYork:ColdSpringHarborLaboratoryPress,1989)中所述的条件,或按照制造厂商所建议的条件。实施例1原始数据准备从千人SNP数据库(http://www.1000genomes.org/,release/20100804)中挑选93个中国人(68个北方汉族人和25个南方汉族人)的SNP数据,并将挑选出的SNP数据集按以下三个条件过滤:在数据库所选人群中多态性碱基型为二种的位点;在数据库所选人群中,数据缺失率<0.1的位点;等位基因碱基型出现次数大于一次的位点。满足以上3个条件的位点将构成初始的SNP数据集。实施例2选取tag-SNP1.标准tag-SNP部分利用haploview软件计算两两tag-snp位点之间的连锁不平衡R2值。参数如下:java-jarhaploview.jar-n-memory25000-dprime-blockoutputALL-maxDistance100-minMAF0.01-pairwiseTagging通过最优聚类,根据连锁不平衡数据,将群体多态位点聚类,然后再从聚类结果中挑选合适的位点充当tag-SNP。最优聚类过程为:将基因组中没有个群体多态SNP位点理解为“孤点”(point),当两个SNP之间的R2达到预定阈值后,则认为此两点之间有“关联”(linkage),可以用线段连接,然后通过特定条件“聚集”,形成“簇”(cluster);当R2阈值从大到小,一直递减至预设值,簇之间无法再发生吞并,整个最优聚类结束。所有能成功设置探针的标准tag-SNP在配套结果文件中,标注为“Reason=R0”。详细过程如下:a.读入所有多态SNP位点的信息,包括位置、等位基因频率和R2(只记录大于或等于预定R2阈值的信息),得到散在的孤点图。图1中黑点代表群体多态SNP位点。b.初始化:将所有两两R2大于或等于0.99的所有孤点连接(完全不考虑在基因组中的位置关系),并默认为最初的簇,在这个簇中挑选假定的tag-SNP(图2)。图2中黑线代表的是连接数(此时R2阈值为0.99),点1-3代表tag-SNP。c.最优聚类:降低一个步长的R2阈值,从染色体起点到终点,将可能出现新的连接,出现的新的连接可以归为下述三类:孤点和孤点发生连接,直接聚集成一个新的簇,并挑选假定tag-SNP;(图3标“a”处);簇和孤点发生连接,如果可以产生符合条件的tag-SNP,则簇将孤点吞并,并更新tag-SNP,否则,不发生任何吞并(图3标“b”处);簇和簇发生连接,如果可以产生符合条件的tag-SNP,则簇的合并,并更新tag-SNP,否则,不发生任何吞并(图3标“c”处)。循环直到在给定R2阈值内没有出现任何吞并现象;进入下一个R2阈值。d.输出最终聚类结果,包括每个簇的组成、假定tag-SNP等信息。图4中虚线段代表R2超过最低阈值,但是不满足合并条件。e.挑选tag-SNP不考虑所有无法合并到“簇”的孤点,直接选取假定的tag-SNP,或者根据聚类信息重新选取tag-SNP。2.挑选假定tag-SNP的标准挑选假定tag-SNP的标准,条件按优先级从高到低排列:在本簇中,连接最多,而且代表率=(连接数+1)/本簇的孤点数,代表率>预设值;次等位基因频率(MAF)最接近0.1;对基因组的覆盖度最大。3.相关参数R2下限:0.8;MAF最小值0.05;代表率最小值0.85。4.其他补全或者过滤部分由于除去外显子区的标准tag-SNP(一些并不是随机的自由组合,而是更加倾向于连在一起连锁不平衡的位点形成的区域,这个区域中比较有代表性的单核苷酸多态性位点),对基因组的覆盖度有限,为了提供更好基因组覆盖度,本发明人将所有剩余的孤点,按照其对全基因组的覆盖率排序,取其前若干作为补充;结果文件中标记为“Reason=R1”。在过滤外显子区tag-SNP(一些并不是随机的自由组合,而是更加倾向于连在一起连锁不平衡的位点形成的区域,这个区域中比较有代表性的单核苷酸多态性位点)时,因为不必额外设计探针,会将部分位点删除;结果文件中标记为“Reason=R3”。在第一轮设计的时候,将tag-SNP(一些并不是随机的自由组合,而是更加倾向于连在一起连锁不平衡的位点形成的区域,这个区域中比较有代表性的单核苷酸多态性位点)集合与以往基于黄种人的GWAS(全基因组关联分析)(全基因组关联分析)结果进行了比较,在覆盖度达到99%以上的情况下,剩余的1%则没有出现在7Mb多态位点中(可能MAF(次等位基因频率)太低);直接将这1%的位点补全到第二轮设计里面,在结果文件中标记为“Reason=R4”。在第一轮设计后,将tag-SNP(一些并不是随机的自由组合,而是更加倾向于连在一起连锁不平衡的位点形成的区域,这个区域中比较有代表性的单核苷酸多态性位点)集合与基于此7Mb多态位点Haploview运行结果中的tag-snp(一些并不是随机的自由组合,而是更加倾向于连在一起连锁不平衡的位点形成的区域,这个区域中比较有代表性的单核苷酸多态性位点)结果进行比较,在覆盖度达到75%以上的情况下,剩余的部分补全到第二轮设计里面,在结果文件中标记为“Reason=R5”。如果两个SNP(单核苷酸多态性)之间的距离小于60-bp,则会去掉MAF(次等位基因频率)比较小的那个;因为在捕获时也能正常被捕获,故结果文件中未有标注。Tag-SNP成簇归类的例子cluster的格式>92472[block起点]94288[block终点]snp=3[SNP数目]M_rs6560827[建议tag]0.279569892473118[建议tag的MAF]M_rs6560827[SNP编号]10[染色体]93603[位置]2[能代表的SNP数]MAF=0.279569892473118[MAF]5.Y染色体部分直接引用了Hapmap3在Y染色体上的所有多态位点。实施例31.基本评估为了得到更加科学可观的结果,本实施例的评估引用了Agilent公司(美国)基于千人中亚洲人的数据研发的GWAS芯片Asiom_GW_ASI(598K)作为对照。2.芯片基本组成本实施例中芯片的基本组成见表1。图5显示了芯片的基本能组成结构。表13.对基因组覆盖程度检测对基因组覆盖程度检测结果(图6)表明,芯片对全基因组的覆盖度比对照(Asiom_GW_ASI)要高,可能的原因在于:一方面基于的数据集以及设计选取tag-snp的方法不一样,另一方面由于评价所用的tag-snp位点数的差异。4.MAF分布检测对MAF分布的检测结果(图7)表明,总体而言,本发明芯片的MAF比对照组Agilent公司的Asiom_GW_ASI要低,特别在2.5%~10%这个区间尤为集中,对流行病学的研究非常有利。5.tag-SNP之间距离检测图8显示了本发明的超级芯片(ALLINONE)和对照组芯片对tag-SNP覆盖度的检测结果。图9显示了超级芯片(ALLINONE)和对照组芯片对tag-SNP之间距离检测结果,结果表明,超级芯片(ALLINONE)的tag-SNP之间的距离更接近1kb,探针距离分布比较接近SNP的自然发生距离,而且明显比对照组Asiom_GW_ASI更密集。实施例4验证1.实验材料:1MtagSNP液相芯片(130M)参考序列基因组:人类hg19参考序列2.方法:从千人SNP数据库中挑选93个中国人(68个北方汉族人和25个南方汉族人)的SNP数据,并将挑选出的SNP数据集按照以下三个条件过滤:在数据库所选人群中多态性碱基型为二种的位点;在数据库所选人群中,数据缺失率<0.1的位点;等位基因碱基型出现次数大于一次的位点。3.挑选tag-SNP,得到1Mtag-SNP的液相芯片,本实施例的芯片可以捕获大概130M的人类基因组区域。用此芯片捕获YH(炎黄)样本并分析得到如表2所述的信息数据。表2Tag-SNP单碱基深度分布如图10所示。根据图10及表2数据可以看出挑选的区域被覆盖情况良好。因此本方法挑选出的位点设计而成的芯片捕获区域大大提高,成本又大为降低。实施例5试剂盒本发明还提供了一种试剂盒,所述试剂盒包括:(1)第一容器以及位于容器内的超级芯片;(2)第二容器以及位于容器内的测序用引物;(3)第三容器以及位于容器内的测序用接头;(4)第四容器以及位于容器内的测序芯片;(5)第五容器以及位于容器内的PCR反应试剂;(6)检测说明书。在本发明提及的所有文献都在本申请中引用作为参考,就如同每一篇文献被单独引用作为参考那样。此外应理解,在阅读了本发明的上述讲授内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1