双链核酸的合成的制作方法
发明背景
核酸的大规模平行测序(Massive parallel sequencing,MPS)需要制备扩增文库,其中待测序的DNA区域位于已知的5’-和3’-末端序列之间。用于MPS文库构建的当前方法利用RNA或DNA接头(adaptor)连接到RNA或DNA样品的5’和3’末端。接头的连接不仅耗时,而且是需要以微克级输入(microgram inputs)核酸样品的低效率过程。此外,所得cDNA文库受到接头交叉和自我连接副产物污染,并且在预扩增之前和之后需要额外的纯化步骤。十多年前,Clontech实验室描述了利用莫洛尼鼠白血病病毒逆转录酶(MMLV-RT)的模板转换活性选择地将接头连接至由聚(A)加尾的mRNA分子产生cDNA的5’-末端的方法。同时,将3’-接头序列并入聚(dT)逆转录引物中。这种称为SMART的原理目前用于Illumina Ultra Low RNA测序试剂盒(Clontech)中以从单个细胞产生mRNA分子的全长cDNA拷贝。然而,该方法仍然需要在模板合成后进行:(1)扩增的cDNA的片段化,(2)平台特异性5’/3’-端接头的连接和(3)接头连接的DNA片段的预扩增。虽然SMART方法能够从单细胞量的RNA制备用于测序的cDNA,但是其耗时、昂贵并且限于mRNA测序。到目前为止,使用MMLV-RT的模板转换活性的方法还没有应用于对(1)除长RNA之外的RNA分子和(2)任何DNA分子进行测序。本发明描述了在仅几小时的时间范围内从皮克(pg)量的RNA或DNA分子产生即时可测序的双链或单链DNA,优选DNA文库的方法。小的(<150bp)RNA或DNA(例如miRNA(微小RNA)、piRNA(piwiRNA)、降解的或亚硫酸氢盐转化的DNA)可直接用作输入。然而,长的RNA或DNA必须首先通过相应的方法(例如,对于DNA进行超声处理或对于RNA进行Mg2+孵育)片段化。本发明的方法提供了若干优点,其包括明显降低提供即时可测序DNA(其可基于DNA或RNA)所需的时间,所述方法与任何现有技术方法相比,明显成本更低。目前用于RNA和DNA的新一代测序之cDNA文库制备的商业试剂盒,根据应用、试剂盒类型和供应商品牌,样品定价在200至500美元之间。使用本发明的方法进行单个DNA文库制备所需的成本的粗略估计至少低20倍,并且本发明的方法将允许对来自由于可从样品获得最小量的DNA和/或RNA之前不可能测序来源的核酸进行测序。那些样品的实例包括:来自小(诊断)量的液体和固体活检样品的DNA和RNA、细胞的靶区室(例如,微核、内质网)、化石、灭绝生物体的残余物和含有微小和高度片段化的DNA分子的法医学样品。本发明在一定程度上基于这样的发现,即DNA也可作为逆转录酶的底物。
技术实现要素:
在第一方面,本发明提供了用于从包含单链核酸的样品合成具有限定的3’和5’端核苷酸序列的双链核酸的方法,所述方法包括以下步骤:
a)提供包含单链核酸或双链核酸的样品,任选地使所述双链核酸变性;
b)向单链核酸或双链核酸的3’-端添加至少5个,优选10至50个连续的核苷酸,
c)使与所添加核苷酸序列互补的引发寡核苷酸杂交并用模板依赖性DNA或RNA聚合酶合成cDNA或cRNA以产生双链核酸,
d)使模板转换寡核苷酸(TSO)与所述双链核酸杂交,以及
e)使cDNA或cRNA链的3’末端延伸以合成双链核酸,其中所述核酸的一条链包含所述引发寡核苷酸以及与所述单链核酸和所述模板转换寡核苷酸互补的cDNA或cRNA。
在第二方面,本发明提供了包含以下序列元件的引发寡核苷酸:
3’-Wm-X-Yn-Z1o-Qt-Z2s-5’,
其中
W在每种情况下独立地选自:dA、dG、dC、dT和dU;
X选自:dA、dG、dC、dT、dU、rA、rG、rC、rT和rU;
Y是至少10个核苷酸长度的多核苷酸,其中所述序列的80%或更多由选自以下的相同的核苷酸或二核苷酸构成:dA、dG、dC、dT、dU、rA、rG、rC、rT、rU、AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TC、TG、TU、AA、CC、GG、TT、UU、UA、UC、UG和UT,其中所述序列的另外至多20%或更少由不同于主要核苷酸或二核苷酸并且也选自以下的核苷酸或二核苷酸构成:dA、dG、dC、dT、dU、rA、rG、rC、rT、rU、AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TC、TG、TU、AA、CC、GG、TT、UU、UA、UC、UG和/或UT,前提条件是X不同于构成Y大部分的核苷酸或二核苷酸;
Q是连续的简并(摆动)DNA碱基的序列,优选地选自:N、V、H、D、B和J,其中N是并入来自dA、dT、dC和dG等摩尔混合物的核苷酸的产物;B是并入来自dT、dC和dG等摩尔混合物的核苷酸的产物;D是并入来自dA、dT和dG等摩尔混合物的核苷酸的产物;H是并入来自dA、dT和dC等摩尔混合物的核苷酸的产物;V是并入来自dA、dC和dG等摩尔混合物的核苷酸的产物,J是并入来自(0-100%dA)比(0-100%dG)比(0-100%dC)比(0-100%dT)比(0-100%dU)比(0-100%rA)比(0-100%rG)比(0-100%rC)比(0-100%rT)比(0-100%rU)的混合物的核苷酸的产物;
Z1是限定序列的至少5个核苷酸长度的多核苷酸,其中所述序列不同于Wm-X-Yn,优选地所述序列也不同于Qt-Z2s;
Z2是限定序列的至少5个核苷酸长度的多核苷酸,其中所述序列不同于Wm-X-Yn-Z1o-Qt;
m是0至6的整数,即0、1、2、3、4、5或6;
如果Y选自dA、dG、dC、dT、dU、rA、rG、rC、rT和rU,则n是10至100的整数,如果Y选自AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TC、TG、TU、AA、CC、GG、TT、UU、UA、UC、UG和UT,则n是5至50的整数;
o是0或1;
s是0或1;并且
t是0至6的整数,即0、1、2、3、4、5或6。
在第三方面,本发明提供了包含以下序列元件的模板转换寡核苷酸
5’-Xp-Y-Qt-Zq-Ar-3’
其中
X是选自氨基、生物素、甘油、胆固醇、地高辛、氟残基或核苷酸衍生物的化学基团,所述核苷酸衍生物包括脱碱基核苷酸、双脱氧核糖核苷酸、3’-脱氧核苷酸、2’-脱氧肌苷、2’-脱氧尿苷;
Y是已知的寡核苷酸序列;
Q是连续的简并(摆动)DNA碱基的序列,优选地选自:N、V、H、D、B和J,其中N是并入来自dA、dT、dC和dG等摩尔混合物的核苷酸的产物;B是并入来自dT、dC和dG等摩尔混合物的核苷酸的产物;D是并入来自dA、dT和dG等摩尔混合物的核苷酸的产物;H是并入来自dA、dT和dC等摩尔混合物的核苷酸的产物;V是并入来自dA、dC和dG等摩尔混合物的核苷酸的产物,J是并入来自(0-100%dA)比(0-100%dG)比(0-100%dC)比(0-100%dT)比(0-100%dU)比(0-100%rA)比(0-100%rG)比(0-100%rC)比(0-100%rT)比(0-100%rU)的混合物的核苷酸的产物;
Z是选自AMP、CMP、GMP、TMP和UMP的核糖核苷酸,
A是选自氨基、生物素、甘油、胆固醇、地高辛、磷酸/盐/酯、氟残基或核苷酸衍生物的化学基团,所述核苷酸衍生物包括脱碱基核苷酸、双脱氧核糖核苷酸、3’-脱氧核苷酸、2’-脱氧肌苷、2’-脱氧尿苷;
t是0至6的整数,即0、1、2、3、4、5或6;
p是0至10的整数,即0、1、2、3、4、5、6、7、8、9或10;
q是至少为1的整数;并且
r是0至10的整数,即0、1、2、3、4、5、6、7、8、9或10。
在第四方面,本发明提供了包含本发明第二方面的引发寡核苷酸的核酸。
在第五方面,本发明提供了试剂盒,其包含:
a)能够向单链核酸的3’-端添加核苷酸的试剂,优选酶,更优选聚(A)聚合酶或末端转移酶(terminal transferase,TT)以及任选嵌段核苷酸,优选3d-NTP、3-Me-NTP和ddNTP,
b)逆转录酶,
c)根据第二方面的引发寡核苷酸,和
d)根据第三方面的模板转换寡核苷酸。
在第六方面,本发明提供了包含至少一种核酸的阵列,所述核酸包含本发明第四方面的引发寡核苷酸。
在第七方面,本发明提供所述试剂盒和合成的双链核酸在以下方面的用途:个体化医疗;治疗监测;人或动物疾病的预测、预后、早期检测或法医学;病毒、细菌、动物或植物或由其来源的细胞的核酸序列的分析。
附图说明
在下文中,描述了包含在本说明书中的附图的内容。在这种情况下,还请参考上文和/或下文的本发明的详细描述。
图1:使用聚A(dA)加尾和MMLV-RT的模板转换能力的组合之cDNA制备方法的示意图。简言之,用聚(A)聚合酶或末端脱氧转移酶将短的单链RNA或DNA片段聚腺苷酸化或聚脱氧腺苷酸化。然后,在含有定制的3’-接头序列的锚定的聚(dT)寡核苷酸的存在下进行互补DNA链合成。任选地,寡核苷酸在其3’末端(prime end)包含三个不同的核苷酸,即,C,G或A(=图1的示意图中的V)。当逆转录酶到达RNA(或DNA)模板的5’末端时,酶的末端转移酶活性添加不由模板编码的额外的核苷酸(主要是dC)。在下一步骤中,含有三个末端rG核苷酸和定制5’-接头序列的模板转换寡核苷酸被添加到RT反应中并用作逆转录酶的第二模板。认为在TSO的3’末端的三个连续的rG核苷酸与富含dC的cDNA的延伸序列的互补相互作用促进模板转换。在标准PCR反应的第一个循环期间由与第一cDNA链的3’-端完全或部分互补的正向引物产生第二cDNA链。此外,用于cDNA的PCR扩增的反向引物(与正向引物一起)与第二cDNA链的3’-端完全或部分互补。
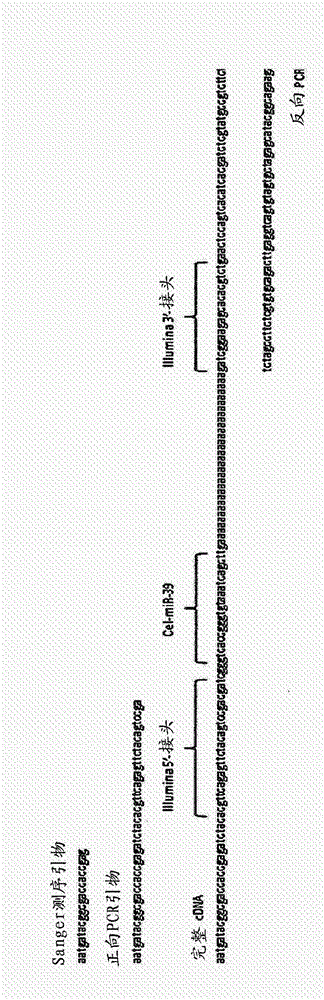
图2:为了构建适于Illumina MiSeq或HiSeq平台的DNA文库,我们使用来自NEBnext Small RNA测序试剂盒(New England Biolabs)的接头序列。将对应于5’-接头的序列并入TSO中,并使用3’-接头序列来设计聚(dT)引物的末端标签(图2A)。使用1ng或5pg的22nt RNA和DNA作为DNA文库制备的输入(图2B)。对于DNA和RNA,cDNA合成的效力相同。当使用1ng的核酸时,在17轮PCR预扩增循环后(1/100cDNA进行PCR稀释)出现单个PCR产物。当使用5pg的核酸作为输入时,预扩增cDNA所需的PCR循环数量增加至26。当使用10/100cDNA进行PCR稀释时,产生DNA文库所需的循环数量成比例地减少(数据未示出)。反应中唯一的污染副产物是过量的PCR引物,其大部分可通过柱纯化除去。Sanger测序已进一步证实了由合成的短DNA制备的cDNA是纯的(数据未示出)。
图3:DNA文库制备方案I的关键参数。首先,聚(A)加尾反应对于cDNA的最佳产量是至关重要的。过长的聚(A)尾部将最终降低聚(dT)引物的有效浓度,这不仅降低cDNA的量,而且导致凝胶上具有更大的副产物的污点,因为聚(dT)引物将与聚(A)尾部内的多个位点杂交。图3A在上方的图中示出了使用不同的孵育时间和ATP浓度之聚(A)加尾的1ng cel-miR-39进行3%琼脂糖凝胶电泳后获得的电泳图。下方的图示出了使用100nM ILPdTPo由1ng相应的聚(A)加尾的cel-miR-39产生的DNA文库进行3%琼脂糖凝胶电泳后获得的电泳图。在图3B中,示出了在使用100nM单碱基锚定的聚dT引物(ILPdTPo)或100nM双碱基锚定的聚dT引物(ILPcTPt)由1ng的cel-miR-39(使用不同浓度的ATP进行聚(A)加尾10分钟)产生的DNA文库进行3%琼脂糖凝胶电泳后获得的电泳图。图3C示出了在使用不同品牌的MMLV-RT以及使用1μM或0.1μM的TSO8由1ng的cel-miR-39(使用0.1mM ATP聚(A)加尾10分钟)产生的DNA文库进行3%琼脂糖凝胶电泳后获得的电泳图。上图:cDNA的PCR扩增进行17个循环。下图:cDNA的PCR扩增进行21个循环。10分钟聚(A)加尾时间和最终为0.1mM的ATP得到22nt RNA克隆的最佳结果。其次,MMLV-RT的供应商和品牌似乎对该方法的灵敏度至关重要。因此,在6家商用MMLV-RT中,SuperScribe II(Invitrogen)、SMARTScribe RT(Clontech)和SMART RT(Clontech)在用当前方案预扩增后最有效地提供可检测量的cDNA,而SuperScribe III Invitrogen)、Multiscribe RT(Applied Biosystems)和来自NEB的M-MLV需要4个额外的预扩增循环以使DNA文库在琼脂糖凝胶上可见(图3C)。这种现象可通过不同的MMLV-RT变体可能具有不同的RNA酶H和末端转移酶活性(后者被认为促进模板转换反应)的事实来解释。因此,优选选择具有RNA酶H活性的RT。
图4:cDNA文库方案II的关键参数。示出了在使用1μM的终浓度的不同模板转换寡核苷酸(TSO)由1ng的cel-miR-39(使用0.1mM ATP聚(A)加尾10分钟)产生的DNA文库进行3%琼脂糖凝胶电泳后获得的电泳图。上图:cDNA的PCR扩增进行17个循环。下图:cDNA的PCR扩增进行21个循环(图4A)。TSO的结构似乎对该方法的灵敏度和性能至关重要。纯DNA和纯RNA TSO两者在17个循环的预扩增PCR后均未能产生任何足够量的靶向cDNA。这可通过以下事实来解释:三个鸟嘌呤核糖核酸(riboG)序列对模板转换的亲和力比三个鸟嘌呤脱氧核糖强得多,而纯RNA寡核苷酸倾向于形成明显的二级结构,所述二级结构减少了3’-端的可用性。此外,当使用具有四个而不是三个末端鸟嘌呤核糖核苷酸的TSO时,cDNA的产量显著降低(图4A),推测是因为四个连续的G能够形成四链体结构(quadruplex structure)。还测试了选择封闭TSO的末端3-OH基团以防止当聚(A)聚合酶没有完全失活时其可能发生的聚(A)加尾。尽管大肠杆菌(E.coli)聚(A)聚合酶在RT反应完成之前在65℃下热失活20分钟,但在以下情况下要强制使用3-OH封闭的TSO:(1)聚(A)加尾和RT同时进行或(2)RNA的聚(A)加尾不能被热灭活。出乎意料地,用单磷酸或生物素封闭TSO的3-OH末端在所使用的条件下消除了有效的cDNA合成(图4A)。然而,当用磷酸酯或双脱氧胞苷(ddC)封闭TSO的3-OH基团时,在四个PCR循环后出现类似量的cDNA产物。在图4B中,示出了在使用5’端未封闭的TSO3或5’-生物素封闭的TSO8由1ng的cel-miR-39(使用0.1mM ATP聚(A)加尾10分钟)产生的DNA文库进行4%琼脂糖凝胶电泳(左)和Agilent Bioanalyser(右)后获得的电泳图。注意~30bp更长的DNA文库的小部分,其可能对应于第二模板转换事件的产物(白色箭头)。
图5:DNA文库制备方案III的关键参数。图A:示出了由1ng的不同的模板cel-miR-39寡核苷酸(使用0.1mM ATP对RNA进行聚(A)加尾10分钟;使用0.1mM ATP对DNA进行聚(dA)加尾30分钟)产生的DNA文库进行3%琼脂糖凝胶电泳后获得的电泳图。与5’-OH或5’-磷酸模板相比,由含有5’-生物素的DNA模板合成DNA文库的效力显著更低。图B:示出了使用水或20%DMSO(最终反应中5%)作为RT反应的介质由1ng的cel-miR-39RNA(使用0.1mM ATP聚(A)加尾10分钟)产生的DNA文库进行3%琼脂糖凝胶电泳后获得的电泳图。DMSO的加入不干扰DNA文库制备的效力。
图6:由人RNA和DNA制备DNA文库。图A:由1ng的对照cel-miR-39(C39R)和1ng分离自U2OS细胞的富含聚(A)的RNA(其通过用镁离子孵育10分钟片段化)(R10)产生的DNA文库进行4%琼脂糖凝胶电泳(左)后获得的电泳图。此外,由聚(A)加尾(-RNK标记的)之前没有用T4PNK预处理的R10样品产生一个DNA文库。在电泳图下方对于每个样品示出了用于cDNA文库的预扩增的PCR循环的数目和聚(dT)反向引物(ILPdTPo)的浓度。从琼脂糖凝胶上切下在Illumina MiSeq上测序的DNA文库,通过PureLink凝胶纯化试剂盒分离并通过Agilent Bioanalyser高灵敏度DNA芯片(右)进行分析。图B:左:示出了由来自U2OS细胞的约3ng亚硫酸氢盐转化的DNA产生的DNA文库进行3%琼脂糖凝胶电泳后获得的电泳图(图6B)。此外,由聚(dA)反应之前用T4PNK预处理的B样品产生一个DNA文库(+RNK标记的)。在阴性对照文库中,使用1μL水(H2O)。右:示出了由1ng的来自U2OS细胞的富含聚(A)的RNA(其通过用镁离子孵育5分钟片段化)(R5)、亚硫酸氢盐转化的DNA(B)和1ng对照的cel-miR-39 RNA(C39R)产生的凝胶纯化的DNA文库之Agilent Bioanalyser电泳图。图C:由分离自两个健康供体(DI和DII)的约150pg的人血浆DNA产生的DNA文库进行4%琼脂糖凝胶电泳(左)和Agilent Bioanalyser(右)后获得的电泳图。在对照实验中,使用水(H2O)或1ng的合成cel-miR-39DNA(C39D)。在电泳图下方对于每个样品示出了用于cDNA文库的预扩增的PCR循环数目和聚(dT)反向引物(ILPdTPo)的浓度。图D:由分离自两个健康供体(RI和RII)的约200pg的人血浆RNA产生的DNA文库进行4%琼脂糖凝胶电泳后获得的电泳图。在对照实验中,使用水(H2O)或1ng的合成cel-miR-39 RNA(C39R)。此外,由聚(A)加尾(-RNK标记的)之前未用T4 PNK预处理的循环RNA样品产生DNA文库。在电泳图下方对于每个样品示出了用于cDNA文库的预扩增的PCR循环数目和聚(dT)反向引物(ILPdTPo)的浓度。由琼脂糖凝胶纯化来自两个个体的循环血浆RNA的DNA文库,但是,仅RI文库在Illumina MiSeq上进行测序。
图7:根据引发寡核苷酸的序列,在一个测序通道中多重样品文库索引读取的准确度。示出了根据用于产生双链核酸的引发寡核苷酸的序列组成,更精确地根据与在该方法的先前步骤中所产生的聚(A)尾部互补的部分以零错误和一个错误鉴定的索引读取的各个比率。使用所示的四种不同引发寡核苷酸和每种寡核苷酸的两个重复,由相同量(1ng)的输入来源材料(人基因组DNA)平行地产生8个DNA片段文库。将8个所得的文库用适当的引物进行预扩增以用于在目前的Illumina测序系统上进行多重测序,每个反向引物包括不同的索引序列,其用于确定所鉴定的读数的来源文库。所使用的索引序列对应于Illumina索引序列1-8,并且每个索引序列在至少3个位置与所有其他索引序列不同。汇集等摩尔量的各个文库,并在Illumina MiSeq系统上在一个泳道上进行单端测序,针对读取#1以70个循环,针对索引读取以6个循环。对于具有不同的索引序列的8个文库中的每一个,记录不含错误或含有1个错误的索引序列读取的相应数量。以0或1个错误描绘了分别用四种不同类型的引发寡核苷酸中的每一种产生的两个文库之索引序列读取的平均频率值,误差条表示平均值与单个文库的值的差异。显然,与“30A”引发寡核苷酸相比,使用引发寡核苷酸“20G”使得索引读取序列的精确性显著增加,同时维持相同效率的DNA片段文库产生。
图8:在DNA和RNA模板上可控的与非可控的多核苷酸加尾的优点。
证明了可控的聚(A)加尾和聚(dA)加尾对由合成cel-miR-39DNA(左)和cel-miR-39RNA(右)产生的cDNA的产量的有益效果的实例。使用相同浓度的RT引物和/或当溶液中ATP的浓度为次优时,可控的聚(A)和聚(dA)加尾使得更有效地产生文库。如果ATP(或dATP)与RNA(或DNA)模板的比率高于最佳,则会产生长(>300nt)尾部。长的多核苷酸尾部降低了聚(dT)引物的有效浓度,降低了文库的产量并在凝胶上产生较大的副产物的污点,原因是过量的聚(dT)引物与大的聚(A)尾部内的位点杂交。A:在1ng的cel-miR-39 DNA模板进行聚(dA)加尾并且使用10nM的聚(dT)反向引物(ILPdTPo)在封闭ddATP核苷酸(dATP/ddATP比1/50)存在(C)或不存在(NC)的情况下获得的DNA文库进行3%琼脂糖凝胶电泳后的电泳图。注意,使用相同浓度的反向引物在可控的聚(dA)加尾后实现显著更高的文库产量。B:在封闭3d-ATP核苷酸(ATP/3d-ATP比1/30)存在(C)或不存在(NC)的情况下,1ng的cel-miR-39 RNA模板的聚(A)加尾后获得的DNA文库在进行3%琼脂糖凝胶电泳后获得的电泳图。注意,ATP与RNA模板的比(1mM ATP与1ng 22nt模板)为次优的。注意,通过可控的加尾可实现显著更高的文库产量并且不存在更大副产物的污点。
发明详述
在下面详细描述本发明之前,应理解,本发明不限于本文描述的特定方法、方案和试剂,因为这些可以变化。还应理解,本文所使用的术语仅仅是为了描述特定实施方案,并不旨在限制本发明的范围,本发明的范围将仅由所附权利要求所限定。除非另有定义,否则本文使用的所有技术术语和科学术语具有与本领域普通技术人员通常理解的相同的含义。
在本说明书的整个文本中引用了若干文件。无论是在上文还是下文中,本文引用的每个文件(包括所有专利、专利申请、科学出版物、制造商的说明书、用法指导等)通过引用整体并入本文。本文中的任何内容都不应被解释为承认本发明没有权利由于在先发明而早于这样的公开。本文引用的一些文件的特征在于“通过引用并入”。在这些并入的参考文献的定义或教导与本说明书中所述的定义或教导之间存在冲突的情况下,本说明书的文本优先。
在下文中,将描述本发明的元件。这些元件用具体实施方案列出,然而,应理解,它们可以以任何方式和任何数量组合以产生另外的实施方案。多种描述的实施例和优选实施方案不应被解释为将本发明仅限于明确描述的实施方案。该描述应被理解为支持并涵盖将明确描述的实施方案与任何数量的所公开和/或优选的元件组合的实施方案。此外,除非上下文另有说明,否则本申请中所有描述的元件的任何排列和组合应被认为通过本申请的说明书被公开。
定义
在下文中,提供了本说明书中经常使用的一些术语的定义。这些术语在其使用的每个实例中和说明书的其余部分中将具有相应的限定含义和优选含义。
如在本说明书和所附权利要求中所使用的,除非内容另有明确说明,否则没有数量词修饰的名词表示一个/种和/或更多个/种。
如在本说明书中使用的术语“核酸”包括对所有已知形式的生命所必需的多聚或寡聚的大分子或大的生物分子。包括DNA(脱氧核糖核酸)和RNA(核糖核酸)的核酸是由称为核苷酸的单体形成的。大多数天然存在的DNA分子由两个互补的生物聚合物链组成,这两个互补的生物聚合物链彼此缠绕以形成双螺旋。DNA链也称为由核苷酸组成的多核苷酸。每个核苷酸由含氮核碱基和称为脱氧核糖或核糖的单糖以及磷酸基团构成。天然存在的核碱基包括鸟嘌呤(G)、腺嘌呤(A)、胸腺嘧啶(T)、尿嘧啶(U)或胞嘧啶(C)。核苷酸通过一个核苷酸的糖和下一个核苷酸的磷酸之间的共价键彼此连接成链,产生交替的糖-磷酸骨架。如果糖是脱氧核糖,则聚合物是DNA。如果糖是核糖,则聚合物是RNA。通常,通过单个核苷酸单体之间的磷酸二酯键形成多核苷酸。在本发明的上下文中,术语“核酸”包括但不限于核糖核酸(RNA)、脱氧核糖核酸(DNA)及其混合物,例如,RNA-DNA杂交体(在一条链内)以及cDNA、基因组DNA、重组DNA、cRNA和mRNA。核酸可以由完整基因或其部分组成,核酸也可以是miRNA、siRNA或piRNA。miRNA是短的核糖核酸(RNA)分子,其平均为22个核苷酸长,但可以更长,并且其在所有真核细胞(即植物、动物和一些病毒)中发现,其在基因表达的转录和转录后调控中起作用。miRNA是与靶信使RNA转录物(mRNA)上的互补序列结合的转录后调控因子,通常导致翻译抑制和基因沉默。小干扰RNA(siRNA)(有时称为短干扰RNA或沉默RNA)是长度在20-25个核苷酸之间的短核糖核酸(RNA分子)。它们参与RNA干扰(RNAi)途径,其中它们干扰特定基因的表达。piRNA也是短RNA,其通常包含26-31个核苷酸并且从它们所结合的所谓的piwi蛋白获得它们的名称。核酸也可以是人工核酸。人工核酸包括聚酰胺或肽核酸(PNA)、吗啉代和锁核酸(LNA)以及乙二醇核酸(glycol nucleic acid,GNA)和苏糖核酸(TNA)。这些中的每一种通过改变分子的骨架与天然存在的DNA或RNA有区别。
本说明书中使用的术语“单链核酸”(ss核酸)是指仅由一条多核苷酸链组成的核酸。相比之下,“双链核酸”(ds核酸)由两条多核苷酸链组成,其中大部分核苷酸根据碱基配对规则(在DNA的情况下,A与T而C与G配对,在RNA的情况下A与U而C与G配对,在RNA/DNA杂交体的情况下A与U、T与A或C与G配对)配对,氢键结合两条分开的多核苷酸链的含氮碱基以形成双链核酸。双链也容许错配。如果位于相对链中相同位置处的两个核苷酸不遵循碱基配对规则,则在双链内发生错配。在给定双链内容忍的错配数由双链的长度、碱基组成、温度和缓冲液条件(例如,盐浓度)决定。这些参数如何影响双链形成是本领域熟知的。
在本说明书的上下文中使用的术语“摆动碱基”或“简并碱基”是指合成DNA或RNA寡核苷酸内其中可能存在多于一种碱基的特定核苷酸位置。“摆动碱基”或“简并碱基”是dA、dT、dG、dC、dU、A、T、G、C或U以所有可能摩尔比的组合。常用的“摆动碱基”或“简并碱基”是连续的简并(摆动)DNA碱基序列,优选地选自N、V、H、D、B和J,其中N是并入来自dA、dT、dC和dG等摩尔混合物的核苷酸的产物,即,其代表dA、dT、dC和dG中的任一种;B是并入来自dT、dC和dG等摩尔混合物的核苷酸的产物,即,其代表dT、dC和dG中的任一种;D是并入来自dA、dT和dG等摩尔混合物的核苷酸的产物,即,其代表dA、dT和dG中的任一种;H是并入来自dA、dT和dC等摩尔混合物的核苷酸的产物,即,其代表dA、dT和dC中的任一种;V是并入来自dA、dC和dG等摩尔混合物的核苷酸的产物,即,其代表dA、dC和dG中的任一种,J是并入来自(0-100%dA)比(0-100%dG)比(0-100%dC)比(0-100%dT)比(0-100%dU)比(0-100%rA)比(0-100%rG)比(0-100%rC)比(0-100%rT)比(0-100%rU)的混合物的核苷酸的产物。因此,在一个位置包含摆动碱基的寡核苷酸将包含来自相应指定混合物的一个特定核苷酸。另一方面,寡核苷酸混合物将包含不同的寡核苷酸,其在相应位置所含相应混合物包含的所有核苷酸。包含不同核苷酸的寡核苷酸的比例由给定位置处并入的核苷酸的各自比例确定。通过序列ANG来说明这点,序列ANG是四种不同寡核苷酸(即,AAG、ACG、AGG和ATG)等摩尔混合物的缩写。因此,如果指示引物或寡核苷酸包含摆动碱基,这意味着引物或寡核苷酸混合物在该位置处存在包含不同的核苷酸。
术语“样品”是指旨在表示整个组织、器官或个体的组织、器官或个体的一部分或一片,通常比该组织、器官或个体小。在分析后,样品提供关于组织状态或器官或个体的健康或疾病状态的信息。样品的实例包括但不限于流体样品,例如血液、血清、血浆、滑液、淋巴液、脑脊液、脑膜液、腺体液、细针抽吸物、脊髓液和其他体液(尿液、唾液)。样品的另一些实例包括细胞培养物或组织培养物。另外的实例还包括液体和固体活检样品或固体样品例如组织提取物。样品可包括化石、来自灭绝生物体的残余物、植物、果实、动物、微生物、细菌、病毒、真菌或由其来源的细胞。
本说明书中使用的“连续的核苷酸”是指由彼此连续的不间断的核苷酸构成的序列。
本说明书中使用的术语“脱碱基核苷酸”是指可通过与一个核苷酸的3’末端和另一个核苷酸的5’末端形成磷酸二酯键而连接两个核苷酸的化合物,其缺乏能够与任何天然存在的核苷酸碱基配对的结构(即嘧啶或嘌呤衍生物),并且跨越侧翼核苷酸的5’-OH和3’-OH之间的距离为天然存在的核苷酸的5’-OH和3’-OH之间距离的至少90%。优选地,该距离为天然存在的核苷酸的5’-OH和3’-OH之间距离的至少91%、92%、93%、94%、95%、96%、97%、98%、99%或100%。“脱碱基核苷酸”充当所谓的“占位符(place holder)”来替代天然存在的核苷酸。本领域技术人员应理解,占位符应通过与添加天然存在的核苷酸进行延伸相似的长度来延伸核苷酸链。因此,脱碱基核苷酸允许在前面和后面的核苷酸与三个连续的核苷酸形成Watson-Crick碱基对,其中第一个和最后一个碱基与前面和后面的核苷酸配对。本领域技术人员还理解,提及3’-OH和5’-OH是指在不存在脱碱基核苷酸时将存在于前面核苷酸的糖骨架的3’-位置的化学基团和后面核苷酸的5’OH。如果存在脱碱基核苷酸,优选其通过磷酸二酯键与前面和后面的核苷酸连接。在DNA中,通过糖苷键水解成核苷酸碱基仅在该位置留下糖-磷酸骨架而产生脱碱基位点。在细胞中,在自发的脱嘌呤/脱嘧啶事件之后、通过UV电离辐射或作为碱基切除修复中间体发生脱碱基位点的形成。因为这样的位点是脆弱的,它们易于遭受单链/双链断裂,并且如果不通过碱基切除修复机制进行修复,脱碱基损伤通常在复制期间通过跨损伤合成(translesion synthesis)导致突变。在损伤对面并入的特定碱基根据生物体和环境条件而变化。通常使用的合成脱碱基核苷酸包括称为dSpacer(1,2-双脱氧核糖)的脱碱基呋喃,其是四氢呋喃衍生物,其中亚甲基占据2-脱氧核糖的1位。dSpacer通常用于模拟寡核苷酸中的脱碱基位点。另一些可用的脱碱基核苷酸包括rSpacer、Spacer 18、Spacer 9、Spacer C3、Spacer C12。
术语“杂交”是指在根据核碱基的组分和核苷酸的长度所确定的特定温度条件下单链核酸(优选序列已知的寡核苷酸)与序列部分或完全互补的单核苷酸的连接。“杂交”也可理解为是指检测特定核酸序列的过程。根据标准杂交技术,可以将编码待检测序列的互补序列的核酸序列用作杂交探针。“原位杂交”使用标记的互补核酸分子,例如,DNA或RNA链(即,探针)来定位样品(例如,组织的一部分或切片)(原位)中特定的核酸分子,例如DNA或RNA序列。杂交条件是本领域技术人员已知的,并且可以在例如Current Protocols in Molecular Biology,John Wiley&Sons,NY,6.3.1-6.3.6、1991中找到。术语“中度杂交条件”用于本发明上下文中是指在30℃下在2X氯化钠/柠檬酸钠(SSC)中杂交,然后在50℃下在1X SSC,0.1%SDS中洗涤。“高度严格条件”是在45℃下在6X氯化钠/柠檬酸钠(SSC)中杂交,然后在65℃下在0.2X SSC,0.1%SDS中洗涤。
在本说明书中使用的“互补”是指通过非共价键与靶核酸的全部或一个区域碱基配对的核苷酸序列。在规范的Watson-Crick碱基配对中,DNA中腺嘌呤(A)与胸腺嘧啶形成碱基对,鸟嘌呤与胞嘧啶也是如此。在RNA中,胸腺嘧啶被尿嘧啶替代。因此,A与T互补,G与C互补。在RNA中,A与U互补,反之亦然。通常,互补是指至少部分互补的核苷酸序列。术语互补还可包括完全互补的双链体,使得一条链中的每个核苷酸与另一条链相应位置中的每个核苷酸互补。在某些情况下,核苷酸可以与靶标部分互补,其中并非所有的核苷酸都与靶核酸所有相应位置中的每个核苷酸互补。例如,引物可以与靶核酸完全(即100%)互补,或者引物和靶核酸可共享一定程度的不够完全的互补性(即70%、75%、80%85%、90%、95%、99%)。
在本说明书中使用的“互补DNA”(cDNA)是在通过酶(例如逆转录酶和DNA聚合酶等)催化的反应中由RNA模板合成的DNA。cDNA通常用于在原核生物中克隆真核基因。cDNA也通过逆转录病毒(例如HIV-1、HIV-2或猿猴免疫缺陷病毒)天然产生,然后整合到宿主的基因组中,在其中产生原病毒(provirus)。术语cDNA通常也用于生物信息学背景中以指代mRNA转录物序列,表达为DNA碱基(GCAT)而不是RNA碱基(GCAU)。“互补RNA”(cRNA)被理解为与给定RNA模板互补的RNA链。
如本说明书所使用的术语“模板依赖性DNA或RNA聚合酶”是指包含能够使用模板核酸链并合成与模板链互补的第二核酸链的催化活性的酶。这些酶需要用作合成链的基础的模板。优选的实例是“逆转录酶”(RT),其是指也称为RNA依赖性DNA聚合酶并且通常用于从RNA模板产生互补DNA的酶,该过程称为逆转录。在第一步中酶的催化活性将单链基因组RNA转化为RNA/DNA杂交体,在第二步中转化为双链DNA。RT的来源是逆转录病毒,例如,需要RT用于其复制的人免疫缺陷病毒(HIV)。RT活性也与染色体末端(端粒酶)和一些移动遗传元件(转座子)的复制相关。通常,RT包含两个顺序的生化活性,RNA依赖性DNA聚合酶和DNA聚合酶,其一起工作以进行转录。除了转录功能,逆转录病毒RT具有对于复制所必需的属于RNA酶H家族的结构域。优选地,使用具有RNA酶H活性的RT。在实验室中RT用于分子克隆、RNA测序、聚合酶链式反应和基因组分析。已经显示RT具有模板转换活性,这意味着它能够从一个模板转换到另一个模板。特别适用于本发明的方法、试剂盒和用途的RT包括但不限于:来自人免疫缺陷病毒1型的HIV-1逆转录酶(PDB 1HMV)、来自莫洛尼鼠白血病病毒的M-MLV逆转录酶、来自禽成髓细胞瘤病毒的AMV逆转录酶和端粒酶。RT可包含可从NEB获得的MMLV逆转录酶、可从Invitrogen获得的Superscript II或Superscript III逆转录酶、可从Applied Biosystems获得的Multiscribe逆转录酶、可从Clontech获得的SMART MMLV逆转录酶或SMARTScribe逆转录酶。端粒酶是在许多真核生物(包括人)中发现的逆转录酶的另一个实例,其携带其自身RNA模板;该RNA用作DNA复制的模板,并且其可以用于本发明的上下文中。
术语“模板独立的DNA/RNA聚合酶”是指催化将核苷酸添加到DNA和/或RNA分子的3’端的酶。与大多数DNA和/或RNA聚合酶不同,这些聚合酶不需要模板用作合成相应链的基础的。这样的酶的优选实例是DNA/RNA连接酶、末端转移酶和聚(A、U或C)-聚合酶。这些酶的优选底物是双链核酸的3’突出端或单链核酸的3’端,但它们也可以添加核苷酸以使3’端钝化或凹入。对于这些酶中一些,特别是对于末端转移酶,钴是必需的辅因子,然而该酶还在体外施用Mg和Mn后催化反应。在本发明上下文中使用的末端转移酶的优选实例是也称为DNA核苷酸外切转移酶(DNA nucleotidylexotransferase,DNTT)的末端脱氧核苷酸转移酶(TdT)或聚-(N)-聚合酶,其中N表示A、G或U。聚(N)-聚合酶在本发明的上下文中是优选的酶,并且包含聚-(A)-聚合酶,其是能够将聚A尾添加到单链核酸的一类酶。天然地,聚-(A)加尾反应发生在初级转录物RNA的3’端。聚-(A)尾由多个腺苷单磷酸组成,其为仅由腺嘌呤碱基组成的段。天然存在的聚(A)加尾产生用于翻译的成熟mRNA。聚-A-聚合酶可以使用胞嘧啶作为底物产生聚-(C)尾。此外,可使用具有功能上等同的聚-(U)-聚合酶和聚-(G)-聚合酶,但要分别使用尿嘧啶、腺嘌呤和鸟嘌呤进行加尾反应。例如,聚-(U)-聚合酶可用于催化向RNA的3’端模板独立地添加来自UTP的UMP或来自ATP的AMP,因此可用于聚A或聚U加尾。“DNA连接酶”是模板非依赖性聚合酶的另一个优选实例,并且是指特定类型的酶,一种通过催化一个DNA末端的3’-羟基与另一个的5’-磷酰基之间形成磷酸二酯键而促进DNA链连接在一起的连接酶。RNA也可以类似地连接。辅因子通常参与反应,其通常是ATP或NAD+。DNA连接酶可使用单核苷酸、二、三或n-核苷酸来产生由单、二、三、n-核苷酸组成的尾,其中“n”优选为4至100个核苷酸。
在本发明的上下文中,优选将已知序列的寡核苷酸连接到单链DNA的3’-羟基末端。类似地,RNA连接酶是催化在一个RNA或DNA末端的3’-羟基与一个RNA或DNA的5’-磷酰基之间形成一个或更多个磷酸二酯键的特定类型的酶。在本发明的上下文中使用的优选的RNA连接酶是T4 RNA连接酶或T7 RNA连接酶,其通过形成3’→5’磷酸二酯键催化5’磷酰基封端的核酸供体与3’羟基封端的核酸受体的连接,将ATP水解为AMP和PPi。RNA连接酶可使用二核苷焦磷酸作为底物来产生单核苷酸的尾部,并且还可使用二、三、n-核苷酸来产生由二、三、n-核苷酸组成的尾部。
本说明书中使用的术语“固定化”是指能够将核酸固定在表面上的任何方法。除了基因递送装置之外,表面固定化的DNA需要开发DNA芯片和阵列、DNA传感器或包括微流体的其他感测装置。所有这些基于DNA的系统的应用范围广泛,主要见于医学领域中,在DNA测序中也使用该装置,此外其用于食品和环境或法医分析。根据不同的表面,开发和优化了多种固定化技术(例如通过物理吸附、共价、亲和结合和基质包埋),已描述其用于碳质材料(例如,碳纳米管)、二氧化硅和硅表面、金表面,以及最近复杂的生物相容性表面(例如,聚合物凝胶)。
“聚合酶链式反应”(PCR)是分子生物学中用于跨过几个数量级扩增一段DNA的单个或几个拷贝,产生数千到数百万拷贝的特定DNA序列的生物化学技术。几乎所有的PCR应用都使用热稳定的DNA聚合酶,例如Taq聚合酶(最初从细菌栖热水生菌(Thermus aquaticus)中分离的酶)。该DNA聚合酶通过使用单链DNA作为模板和启动DNA合成所需的DNA寡核苷酸(也称为DNA引物从DNA结构单元(building-blocks)、核苷酸中酶促地装配新的DNA链。绝大多数PCR方法使用热循环,即通过限定的一系列温度步骤交替地加热和冷却PCR样品。基本的PCR设置需要几种组分和试剂。这些组分包括含有待扩增的DNA区域(靶标)的DNA模板、与DNA靶标的有义链和反义链各自的3’端互补的两个引物、Taq聚合酶或最适温度为约70℃的另一种DNA聚合酶、脱氧核苷三磷酸(dNTP)、DNA聚合酶由其合成新DNA链的结构单元、缓冲溶液、为DNA聚合酶的最佳活性和稳定性提供合适的化学环境、二价阳离子、镁或锰离子或一价阳离子钾离子;通常使用Mg2+,但Mn2+可用于PCR介导的DNA诱变,因为较高的Mn2+浓度增加DNA合成期间的错误率。上述方法可以包括核酸标记。本领域技术人员已知允许标记DNA、RNA或寡核苷酸的一系列技术。这些包括例如Nick翻译标记、随机引发的DNA标记、DNA探针的PCR标记和寡核苷酸3’/5’末端标记、RNA探针的转录标记、寡核苷酸3’/5’末端标记和寡核苷酸加尾。PCR可用于本发明方法的某些优选实施方案中,优选在合成双链核酸之后使用。
在本说明书中使用的术语“序列测定”是指用于确定DNA或RNA分子内的核苷酸的精确顺序的多种方法,换句话说,确定DNA链中的四种碱基-腺嘌呤、鸟嘌呤、胞嘧啶和胸腺嘧啶,或在RNA的情况下尿嘧啶而不是胸腺嘧啶的顺序。DNA测序可以用于测定单个基因、更大的遗传区域(即基因或操纵子的簇)、全染色体或整个基因组的序列。测序可以提供从动物、植物、细菌、古菌或几乎任何其他遗传信息来源的细胞分离的DNA或RNA中单个核苷酸的顺序。
本说明书中使用的术语“阵列”是指核酸微阵列(如果DNA被固定化,通常也称为DNA芯片或生物芯片)是在固体表面上各自包含相同或不同的核酸的有序排列的点。优选地,每个点仅包含相同的核酸分子。所述点可以呈任何形状,优选圆形或正方形。这种微阵列用于同时测量大量基因的表达水平或对基因组的多个区域进行基因分型。每个点通常含有皮摩尔(10-12皮摩尔)的特定序列的DNA,称为探针(或报告子或寡核苷酸)。这些可以是用于在高严格条件下与cDNA或cRNA(也称为反义RNA)样品(称为靶标)杂交的基因或其他DNA元件的短片段。探针-靶标杂交通常通过检测荧光团标记、银标记或化学发光标记的靶标来检测和定量以确定靶标中核酸序列的相对丰度。合成所述探针,然后通过表面改造经由化学基质(通过环氧基-硅烷、氨基-硅烷、赖氨酸、聚丙烯酰胺或其他)的共价键连接到固体表面。固体表面可以是玻璃或硅芯片。DNA微阵列可用于测量表达水平的变化以检测单核苷酸多态性(SNP)或进行基因分型或靶向重测序。
实施方案
在下面的段落中,更详细地限定了本发明的不同方面。除非明确指示相反,否则如此限定的各个方面可以与任何其他方面或多个方面组合。特别地,指示为优选或有利的任何特征可以与指示为优选或有利的任何其他特征组合。
在产生本发明的工作中,出人意料地显示,可以以快速方式将单链核酸合成为具有限定的3’和5’末端的双链核酸,其中获得的双链核酸即时可通过当前的下一代测序技术进行测序,而不需要本发明中所述的方法之外的任何额外的步骤。
基于这些结果,本发明在第一方面提供了用于从包含单链核酸的样品合成具有限定的3’和5’端核苷酸序列的双链核酸的方法,所述方法包括以下步骤:
a)提供包含单链核酸或双链核酸的样品,任选地使所述双链核酸变性;
b)向单链核酸或双链核酸的3’-末端添加至少5个连续的核苷酸,
c)使与所添加核苷酸序列互补的引发寡核苷酸杂交,并用模板依赖性DNA或RNA聚合酶合成cDNA或cRNA以产生双链核酸,
d)使模板转换寡核苷酸与所述双链核酸杂交,以及
e)使cDNA或cRNA链的3’末端延伸以合成双链核酸,其中核酸的一条链包含引发寡核苷酸,以及与单链核酸以及模板转换寡核苷酸互补的cDNA或cRNA。
本发明方法的目的之一是将已知的核苷酸序列(在本发明的上下文中也称为限定序列)添加到未知序列的单链核酸或双链核酸3’和5’末端二者。这些添加的核苷酸序列允许与作为本发明方法的产物的双链核酸具有相同和/或互补序列的寡核苷酸特异性退火,从而允许双链核酸的许多后续操作,包括捕获、扩增、延伸等。优选地,每个3’末端和5’末端“限定序列”彼此不杂交,并且也不可能在选择用于对作为本发明方法的产物的双链核酸进行后续操作的条件下与样品中存在的任何核苷酸杂交。
在本发明第一方面的优选实施方案中,样品是从液体或固体活检样品获得的或由其来源,更优选血液样品、血浆样品、血清样品、体液样品、唾液样品、尿样品、精液样品、来自胸膜腔的流体法样品、来自腹膜腔的流体的样品、脑脊液的样品、来自上皮表面的涂片、痰样品、粪便样品、射精样品、眼泪样品、汗液样品、淋巴液样品、支气管灌洗液样品、胸腔积液样品、脑膜液样品、腺液样品、细针抽吸样品、微切割细胞、乳头抽吸液样品、脊髓液样品、结膜液样品、阴道液样品、十二指肠液样品、胰液样品或胆汁样品。在另一个优选的实施方案中,所述样品是法医用样品或考古样品。更优选地,所述样品是从化石、灭绝生物体的残余物、植物、果实和动物、微生物、细菌、病毒获得的。在另一个更优选的实施方案中,所述样品是从哺乳动物,更优选人对象获得的。在另一个优选的实施方案中,样品来自患有病症的人对象。更优选地,所述样品包含人静脉血,甚至更优选人血浆。在另一个优选的实施方案中,包含单链核酸或双链核酸的所述样品,优选人血液、血清样品或血浆样品,其直接用于本发明的方法,而不需要将核酸从患者获得样品中分离的在先步骤。当单链核酸或双链核酸是DNA时,这是优选的实施方案。更优选地,在样品直接用于本发明的方法的情况下,所述样品是用能够切割蛋白质中肽键的酶(优选蛋白酶,特别是蛋白酶K)处理并在合适的温度下孵育适当时间的样品。优选地,通过不对患者造成实质性健康风险的方法提供样品,例如,通过从外周静脉或动脉抽出血液。步骤a)中使用的样品可包含单链和/或双链核酸。如果样品包含双链DNA,优选在步骤a)之前进行变性步骤。这样的步骤可以包含热或化学变性。
在本发明第一方面的优选实施方案中,单链核酸或双链核酸是DNA或RNA。DNA或RNA可以是片段化的或亚硫酸氢盐转化的RNA或DNA。在一个更优选的实施方案中,包含在样品中的RNA或DNA的平均长度为5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、43、44、45、46、47、48、49、50、60、70、80、90、100、110、120、130、140、150、160、170、180、190、200、210、220、230、240、250、260、270、280、290、300、310、320、330、340、350、360、370、380、390、400、410、420、430、440、450、460、470、480、490、500、510、520、530、540、550、560、570、580、590或600个核苷酸。更优选地,所述单链核酸是RNA,甚至更优选地,所述单链核酸是miRNA、小RNA或piRNA。在另一个优选的实施方案中,所述RNA天然不包含连续的一段聚腺苷,优选至少30个聚腺苷。在另一个优选的实施方案中,所述单链核酸是DNA。
由于本发明方法的灵敏性,需要在步骤a)中提供的单链核酸或双链核酸的量可以非常低,并且仍然可以导致产生双链核酸。因此,在一个优选的实施方案中,步骤a)中提供的样品的DNA和/或RNA的浓度小于1μg/μl,优选小于0.1μg/μl,更优选小于0.01μg/μl,更优选小于1ng/μl,更优选小于0.1ng/μl,甚至更优选小于0.01ng/μl,更优选小于1pg/μl,甚至更优选小于0.1pg/μl,更优选小于0.01pg/μl,最优选小于1fg/μl。样品中的总DNA和/或RNA也可以非常低,优选为5pg。优选地,如果本发明第一方面的步骤a)中提供的核酸是小RNA,则可以使用5pg/μl,如果在所述步骤a)中提供的核酸是DNA,则可以使用5pg或者如果在所述步骤a)中提供的核酸是miRNA或siRNA,则可使用1pg/μl至5ng/μl。
该方法的步骤b)需要向单链核酸的3’-端添加至少5个连续的核苷酸。这段连续的核苷酸用于允许引发寡核苷酸的随后杂交的目的。其可以充当在本发明的方法中引入的3’末端限定序列。因此,引发寡核苷酸和连续的核苷酸必须包含彼此互补的序列。如果添加已知序列的连续的核苷酸,例如通过添加已知序列的引物或通过添加连续的一段已知单核苷酸或二核苷酸,则可以达到这个目的。不需要将这段核苷酸立即添加到单链核酸的3’端,只要其包含在所添加的连续的核苷酸段中即可。本发明第一方面的另一个优选实施方案包括向单链核酸的3’端添加相同的连续核苷酸。优选地,添加选自A、T、G、C或U的相同的连续核苷酸。优选地,相同的连续核苷酸的数目范围为10至500个连续核苷酸,即10、11、12、13、14、15、16、17、18、19、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、110、120、130、140、150、160、170、180、190、200、210、220、230、240、250、260、270、280、290、300、310、320、330、340、350、360、370、380、390、400、410、420、430、440、450、460、470、480、490或500个。更优选地,连续的相同核苷酸的数目为10至100个连续相同核苷酸,更优选15至50个连续的相同核苷酸,更优选20至40个连续的相同核苷酸或30至100个连续的相同核苷酸,即10、15、20、25、30、40、50、60、70、80、90或100。因此,优选较短的连续核苷酸段。在3’末端的有限突出端导致:(1)在本发明方法的步骤c)中添加的引发寡核苷酸在相同浓度下成比例地引发更高的逆转录的能力;(2)允许精确计算在本发明方法的步骤c)中添加的引发寡核苷酸的最佳量,当引发寡核苷酸直接地与TSO相互作用时导致“空”DNA副产物的较低发生率(3)因为在离模板的3’-末端的远端位点引发逆转录,所以含有大于30个核苷酸的多核苷酸段的DNA产物的发生率较低。优点(1)、(2)和(3)导致方法的灵敏度具有统计学显著的增加,并允许由较低浓度的模板合成DNA。此外,当产生文库时,较短的连续核苷酸段提供生成更好的(例如,更复杂)的文库的额外优势。
在另一个优选的实施方案中,相同的连续核苷酸包含选自AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TG、TC或TU的连续二核苷酸。在另一个优选的实施方案中,添加相同的连续三、四或五核苷酸。为了仅添加一种类型的核苷酸,优选在反应步骤b)中添加的核苷酸包含、基本上仅包含一个待添加的特定类型的核苷酸结构单元或仅由其组成,例如,仅有A、G、C或T。然而,可以设想,在步骤b)中使用的核苷酸结构单元不是完全同质的(homogenous),而是还包含其他核苷酸结构单元。在这种情况下,不同的核苷酸结构单元将以反映其在反应混合物中的相应浓度的随机方式添加。因此,在本发明方法的一个实施方案中,期望将其他核苷酸的浓度保持在最小以确保形成连续段的预期核苷酸序列。然而,本发明的方法不排除使用结构单元的混合物的实施方案,只要大部分添加的核苷酸包含已知序列的至少10个连续核苷酸即可。
存在不同的方式以限制在本领域技术人员已知的加尾反应中添加的核苷酸的数量。一个优选的实施方案是使用并入的次优浓度的核苷酸或二核苷酸。次优浓度是核苷酸或二核苷酸的摩尔浓度,其低于模板独立的DNA和RNA聚合酶的供应商/生产商推荐的核苷酸或二核苷酸的摩尔浓度;并且在这种情况下模板独立的DNA和RNA聚合酶合成短于1000nt的多核苷酸尾部。在其中模板独立的DNA和RNA聚合酶用于加尾反应的情况下,本领域技术人员可以对于各个酶确定相应反应混合物中的核苷酸或二核苷酸的浓度,其在给定时间内达到添加的核苷酸或者二核苷酸的最大数目,即最大酶持续合成能力(processivity)的浓度。然后将该浓度视为该酶在给定的反应条件(例如缓冲液、pH、温度等)下的最适浓度。核苷酸/二核苷酸的“次优浓度”是比最优核苷酸浓度低至少10倍,更优选低100倍的浓度。优选地,次优浓度导致酶持续合成能力降低,即在给定时间段内添加的核苷酸/二核苷酸的数目比在最优核苷酸浓度下添加的核苷酸/二核苷酸的数目低至少10倍,更优选低100倍。优选地,次优浓度在以下范围内:对于10-20分钟在聚(A)聚合酶反应缓冲液(50mM Tris-HCl,250mM NaCl,10mM MgCl2 pH 7.9,25℃)中大肠杆菌聚(A)聚合酶介导的反应为0.1mM-0.01 mM ATP;对于10-20分钟在MMLV逆转录酶反应缓冲液(50mM Tris-HCl,75mM KCl,3mM MgCl2,10mM DTT pH8.3,25℃)大肠杆菌聚(A)聚合酶介导的反应为0.001mM-0.0001mM ATP;对于10-20分钟在MMLV逆转录酶反应缓冲液(50mM Tris-HCl,75mM KCl,3mM MgCl2,10mM DTT pH 8.3,25℃)中酵母聚(A)聚合酶介导的反应为0.1mM-0.01mM ATP;对于10-30分钟末端转移酶反应缓冲液(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,pH7.9,25℃)或MMLV逆转录酶反应缓冲液(50mM Tris-HCl,75mM KCl,3mM MgCl2,10mM DTT,pH8.3,25℃)中末端转移酶介导的反应为0.1mM-0.01mM的dATP。最优浓度是核苷酸或二核苷酸的摩尔浓度,在该浓度下模板独立的DNA和RNA聚合酶向DNA和RNA模板添加至少30nt但不超过1000nt的多核苷酸尾。在其中模板独立的DNA和RNA聚合酶用于加尾反应的情况下,本领域技术人员可以对各个酶确定在给定时间内导致添加最佳数目的核苷酸或者二核苷酸之相应反应混合物中的核苷酸或二核苷酸的浓度。然后将该浓度视为在给定的反应条件(例如缓冲液、pH、温度等)下该酶的最适浓度。核苷酸/二核苷酸的“次优浓度”是比最优核苷酸浓度至少高10倍,更优选高100倍的浓度。优选最适浓度导致酶持续合成能力降低,即在给定时间段内添加的核苷酸/二核苷酸的数量比在次优核苷酸浓度下添加的核苷酸/二核苷酸的数量低至少10倍,更优选低100倍。优选地,最适浓度在以下范围内:对于10-20分钟在聚(A)聚合酶反应缓冲液(50mM Tris-HCl,250mM NaCl,10mM MgCl2pH 7.9,25℃)中大肠杆菌聚(A)聚合酶介导的反应为0.1mM-0.01mM ATP;对于10-20分钟在MMLV逆转录酶反应缓冲液(50mM Tris-HCl,75mM KCl,3mM MgCl2,10mM DTT pH 8.3,25℃)中大肠杆菌聚(A)聚合酶介导的反应为0.001mM-0.0001mM ATP;对于10-20分钟在MMLV逆转录酶反应缓冲液(50mM Tris-HCl,75mM KCl,3mM MgCl2,10mM DTT pH8.3,25℃)中酵母聚(A)聚合酶介导的反应为0.1mM-0.01mM ATP;对于10-30分钟在末端转移酶反应缓冲液(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,pH 7.9,25℃)或MMLV逆转录酶反应缓冲液(50mM Tris-HCl,75mM KCl,3mM MgCl2,10mM DTT,pH 8.3,25℃)中末端转移酶介导的反应中为0.1mM-0.01mM dATP。
在另一个优选的实施方案中,通过使用封闭核苷酸或二核苷酸实现这点。封闭核苷酸或二核苷酸是这样的核苷酸或二核苷酸:其一旦添加,防止添加其他核苷酸或二核苷酸。通常通过将下一个核苷酸添加到位于核糖或脱氧核糖的3’位置的羟基来延伸寡核苷酸。如果核糖或脱氧核糖的3’位置被封闭,则不能加入其他核苷酸或二核苷酸。因此,封闭核苷酸的核糖或脱氧核糖或二核苷酸的3’-末端核苷酸不允许添加其他核苷酸或二核苷酸。优选的封闭核苷酸是3d-ATP、3-Me-ATP和ddATP。更优选地,使用ddATP或3d-ATP。如果使用封闭核苷酸和非封闭核苷酸的混合物,则将第一封闭核苷酸并入到生长的寡核苷酸链中是随机事件,并且在并入给定数量的非封闭的核苷酸后并入第一封闭核苷酸的可能性取决于反应混合物中存在的封闭和非封闭核苷酸的比例。因此,反应混合物中这些封闭核苷酸或二核苷酸的浓度低于非封闭核苷酸或二核苷酸的浓度。封闭核苷酸或二核苷酸的相对量越低,延伸将进行得越长。由于并入第一封闭寡核苷酸是随机事件,因此在加尾反应中添加的寡核苷酸的长度将在给定范围内变化。优选地,封闭与非封闭核苷酸或二核苷酸的浓度比在1∶1至1∶1000之间。通常使用的浓度范围为0.1至0.001mM,即0.09、0.08、0.07、0.06、0.05、0.04、0.03、0.02、0.01、0.009、0.008、0.007、0.006、0.005、0.004、0.003、0.002、0.001nM。最优选地,对于酵母聚(A)聚合酶,以相对于ATP浓度为1至30的比例使用3d-ATP,而对于大肠杆菌聚(A)聚合酶以相对于ATP浓度为1至1.7的比例使用3d-ATP,得到平均大小为30nt的延伸产物。最优选地,对于末端转移酶以相对于dATP的浓度为1至30的比例使用ddATP以获得平均大小为30nt的延伸产物,优选地选择条件以使添加平均不超过50个核苷酸,优选不超过40,更优选不超过35,更优选不超过30,优选不超过25,最优选不超过20。
在其中需要一段短的相同连续的核苷酸的那些实施方案中,优选通过提供混合物或核糖或脱氧核糖核苷酸和链终止核苷酸来实现这点。如果需要10个连续核苷酸的长度,则链终止核苷酸和核糖或脱氧核糖核苷酸的1至10种混合物将平均导致这样的长度。因此,技术人员知道如何产生平均具有如上所述长度且优选在30至100个核苷酸范围内的连续的核苷酸段。优选的链终止核苷酸是双脱氧核苷酸。
在另一个优选的实施方案中,连续相同的核苷酸包含至少两个核糖核苷酸或脱氧核糖核苷酸的混合物。
在多核苷酸加尾反应中包含一些量的一个另外的核苷酸可具有有益效果,这是由于多核苷酸尾部不再是同质的,同时仍然具有类似的与引发寡核苷酸的结合效率。同时,非同质多核苷酸尾可有利于使用Illumina平台进行配对末端测序(pair-end sequencing),因为同质核苷酸测序非常容易出错。在优选的实例中,期望产生包含非同质核苷酸的混合物,因为将该混合物添加到本发明方法的步骤a)中提供的单链核酸或双链核酸而得到的多核苷酸尾对于在完成步骤e)之后使产生的核酸使用例如Illumina平台进行配对末端测序进行序列测定方法是有益的,因为使用同聚核苷酸可能发生不期望的干扰。
优选地,在单链DNA的情况下使用A、T、G或C,在单链RNA的情况下使用U或A。
在本发明第一方面的另一个实施方案中,通过模板独立的DNA和RNA聚合酶进行步骤b)中相同核苷酸的添加。优选地,这些蛋白质是末端转移酶、DNA或RNA连接酶或聚N聚合酶,其中N选自A、G或U。具有末端转移酶活性的酶能够将核糖核苷酸或脱氧核糖核苷酸或其多聚体添加到核酸的3’-OH末端,而不需要互补模板链。具有这种活性的优选的酶选自:末端转移酶、聚-(A)-聚合酶、聚-(U)-聚合酶和聚-(G)-聚合酶。RNA连接酶或DNA连接酶可添加单核苷酸、二核苷酸、三核苷酸或寡核苷酸,优选添加单核苷酸、二核苷酸、三核苷酸。优选的连接酶是T4RNA连接酶或T7RNA连接酶。所述连接酶可以有效地对在末端的3’-端核苷酸含有2’-O-甲基的RNA模板进行加尾。优选当添加单核苷酸时,RNA连接酶使用焦磷酸二核苷酸作为底物。
步骤c)包括使引发寡核苷酸与先前添加的核苷酸序列杂交。该步骤优选包括升高温度以使得在引发寡核苷酸和添加的连续核苷酸之间形成碱基对。除了能够与添加的连续核苷酸杂交的序列外,引发寡核苷酸还包含另外的限定序列,优选5’-末端,其可以用于与另一个寡核苷酸特异性杂交,例如,用于PCR扩增的寡核苷酸。该部分优选长度为5至100个核苷酸。优选地,其在3’端还包含所谓的钩(hook)结构。所述钩优选是与能够与添加的连续核苷酸杂交之核苷酸不同的核苷酸,并且用于将引发寡核苷酸直接定位到步骤b)中添加的连续核苷酸的5’-末端或其附近的目的。优选地,在本发明的方法中使用的引发寡核苷酸包含以下序列元件:
3’-Wm-X-Yn-Z1o-Qt-Z2s-5‘
其中
W在每种情况下独立地选自:dA、dG、dC、dT和dU;
X选自:dA、dG、dC、dT、dU、rA、rG、rC、rT和rU;
Y是至少10个核苷酸长度的多核苷酸,其中所述序列的80%或更多由选自以下的相同的核苷酸或二核苷酸构成:dA、dG、dC、dT、dU、rA、rG、rC、rT、rU、AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TC、TG、TU、AA、CC、GG、TT、UU、UA、UC、UG和UT,其中所述序列的另外20%或更少由不同于主要核苷酸或二核苷酸并且也选自以下的核苷酸或二核苷酸构成:dA、dG、dC、dT、dU、rA、rG、rC、rT、rU、AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TC、TG、TU、AA、CC、GG、TT、UU、UA、UC、UG和/或UT,前提条件是X不同于构成Y大部分的核苷酸或二核苷酸;
Q是连续的简并(摆动)DNA碱基的序列,优选地选自N、V、H、D、B和J,其中N是并入来自dA、dT、dC和dG等摩尔混合物的核苷酸的产物;B是并入来自dT、dC和dG等摩尔混合物的核苷酸的产物;D是并入来自dA、dT和dG等摩尔混合物的核苷酸的产物;H是并入来自dA、dT和dC等摩尔混合物的核苷酸的产物;V是并入来自dA、dC和dG等摩尔混合物的核苷酸的产物,J是并入来自(0-100%dA)比(0-100%dG)比(0-100%dC)比(0-100%dT)比(0-100%dU)比(0-100%rA)比(0-100%rG)比(0-100%rC)比(0-100%rT)比(0-100%rU)的混合物的核苷酸的产物;
Z1是限定序列的至少5个核苷酸长度的多核苷酸,其中所述序列不同于Wm-X-Yn,优选所述序列也不同于Qt-Z2s;
Z2是限定序列的至少5个核苷酸长度的多核苷酸,其中所述序列不同于Wm-X-Yn-Z1o-Qt;
m是0至6的整数,即0、1、2、3、4、5或6;
如果Y选自dA、dG、dC、dT、dU、rA、rG、rC、rT和rU,则n是10至100的整数,如果Y选自AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TC、TG、TU、AA、CC、GG、TT、UU、UA、UC、UG和UT,则n是5至50的整数;
o是0或1;
s是0或1;和
t是0至6的整数,即0、1、2、3、4、5或6。
Y是能够与添加的连续核酸杂交的引发寡核苷酸部分。因此,优选其与添加的核酸具有至少90%的序列互补性。因此,优选其具有对应于所添加的连续核苷酸长度的长度,更优选地长度为10至100个核苷酸,即10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95或100个核苷酸。本发明人已经发现,短Y提高了序列精确度。然而,为了进行杂交,优选在严格条件下,优选Y具有11至50,更优选12至40,更优选13至30,最优选14至20的长度。
本发明人已经发现,低数目的不相同的核苷酸和/或二核苷酸的存在提高了测序精确度。因此,优选Y的序列由选自以下的至少80%的相同核苷酸和/或二核苷酸构成:dA、dG、dC、dT、dU、rA、rG、rC、rT、rU、AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TC、TG、TU、AA、CC、GG、TT、UU、UA、UC、UG和UT,其中另外20%或更少由不同于主要核苷酸和/或二核苷酸并且也选自以下的核苷酸或二核苷酸构成:dA、dG、dC、dT、dU、rA、rG、rC、rT、rU、AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TC、TG、TU、AA、CC、GG、TT、UU、UA、UC、UG和UT。在优选的实施方案中,主要核苷酸是A和/或T。在另一个优选的实施方案中,核苷酸是二核苷酸,优选AA、TT、AT或TA。在另一个优选的实施方案中,少数核苷酸是C和/或G。在另一个优选的实施方案中,核苷酸是二核苷酸,优选CC、GG、CG和/或GC。在优选的实施方案中,Y的序列的80%至99%是由相同核苷酸和/或二核苷酸构成,更优选85%至95%(本领域技术人员清楚,在这种情况下,“n”必须至少为20),更优选88%至92%,最优选约90%。因此,在一个示例性优选实施方案中,Y可以包含9个T核苷酸和一个G或C核苷酸或14个T和一个G或C。
在Y包含一个或两个不同核苷酸的情况下,优选这个(这些)核苷酸位于Y的中间或接近中间(即在1至4个碱基内)。
在本发明第二方面的另一个优选实施方案中,优选Y是仅由T组成的连续核苷酸段并且n的范围为10至60、即50、45、40、35、34、33、32、31、30、29、28、27、26、25、24、23、22、21、20、19、18、17、16、15、14、13、12、11或10,更优选为11至50,更优选12至40,更优选13至30,最优选14至20。更优选n为30、20、16或15。最优选n为20或16。在该优选的实施方案的替选中,Y包含一个或两个不同的核苷酸,进一步优选G或C。
在一个替选的优选实施方案中,Y的序列是除了1或2个G和/或C残基之外仅由T组成的连续的核苷酸段。
Z1是引发寡核苷酸的一部分,其在合成双链核酸分子之后使用以进行另一寡核苷酸的序列特异性杂交。因此,Z1优选是添加至包含在样品中的核酸的3’末端的限定序列。Z1的长度为至少5个核苷酸,更优选在5至50个核苷酸的范围内,更优选在10至30个核苷酸的范围内。选择长度以使引物可在随后的PCR扩增反应中与Z1特异性杂交。在优选的实施方案中,Z1的核酸序列选自:SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8、SEQ ID NO:9、SEQ ID NO:10、SEQ ID NO:11、SEQ ID NO:12、SEQ ID NO:13、SEQ ID NO:14、SEQ ID NO:15和SEQ ID NO:16。
优选地,Z1不同于Z2。
Z2是引发寡核苷酸的一部分,其在合成双链核酸分子之后使用以进行另一寡核苷酸的序列特异性杂交。因此,Z2优选是添加到包含在样品中的核酸的3’-末端的限定序列。Z2的长度为至少5个核苷酸,更优选在5至50个核苷酸的范围内,更优选在10至30个核苷酸的范围内。选择长度以使引物可在随后的PCR扩增反应中与Z1特异性杂交。在优选的实施方案中,Z2的核酸序列选自:SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8、SEQ ID NO:9、SEQ ID NO:10、SEQ ID NO:11、SEQ ID NO:12、SEQ ID NO:13、SEQ ID NO:14、SEQ ID NO:15和SEQ ID NO:16或相应的序列。
优选地,Z2不同于Z1。
在引物中(即在Z1和Z2之间)包含1至6个,更优选2至4个,即1、2、3、4、5或6个连续摆动碱基将允许在文库中分辨PCR重复。优选地,Q是连续的简并(摆动)DNA碱基的序列,优选在每种情况下独立地选自N、V、H、D、B和J,其中N是并入来自dA、dT、dC和dG等摩尔混合物的核苷酸的产物;B是并入来自dT、dC和dG等摩尔混合物的核苷酸的产物;D是并入来自dA、dT和dG等摩尔混合物的核苷酸的产物;H是并入来自dA、dT和dC等摩尔混合物的核苷酸的产物;V是并入来自dA、dC和dG等摩尔混合物的核苷酸的产物,J是并入来自(0-100%dA)比(0-100%dG)比(0-100%dC)比(0-100%dT)比(0-100%dU)比(0-100%rA)比(0-100%rG)比(0-100%rC)比(0-100%rT)比(0-100%rU)的混合物的核苷酸的产物。优选将连续的摆动碱基包含在引发寡核苷酸中,因为其有助于在所产生的DNA文库中分辨PCR重复。最优选Q位于Z1和Z2之间并且为N。优选地,Q为N,t为至少2,更优选为4。
在另一个优选的实施方案中,t和s的和为0,例如,Z2和Q不存在。
特别优选的引发寡核苷酸的实例是具有根据SEQ ID NO:17、SEQ ID NO:18、SEQ ID NO:19和SEQ ID NO:20的核苷酸序列的核苷酸。
一旦引发寡核苷酸退火,其3’末端通过模板依赖性DNA或RNA聚合酶(优选还具有末端转移酶活性的DNA或RNA聚合酶)延伸。这样的酶的优选实例是逆转录酶(reverse transcriptase,RT),特别是MMLV RT。一旦达到模板的末端,模板依赖性DNA或RNA聚合酶使用其末端转移酶活性以不依赖于模板的形式添加额外的核苷酸。因此,步骤c)的产物是在新合成的链的3’-末端具有突出端的双链核酸(DNA/DNA、RNA/RNA或DNA/RNA)。优选地,该突出端的长度为至少1个核苷酸,优选至少3个核苷酸。优选地,这些核苷酸相同。它们优选选自:dA、dC、dG、dT、rA、rC、rG和rU,最优选地选自dC。因此,特别优选的突出端由三个胞嘧啶核苷酸的连续段组成。
在步骤d)中,模板转换寡核苷酸(template switching oligonucleotide,TSO)与步骤c)的产物杂交,其允许模板依赖性DNA或RNA聚合酶(优选RT)将限定序列添加到包含在样品中的单链核酸或双链核酸的5’末端。这通过进一步延伸在步骤c)中合成的核酸链的3’末端来实现这点。术语“模板转换寡核苷酸”指聚合酶活性从初始模板(例如通过本发明样品提供的单链核酸)切换至的寡核苷酸模板。在本发明的一个实施方案中,模板转换寡核苷酸是DNA/RNA杂交寡核苷酸,其被模板依赖性DNA或RNA聚合酶(优选RT,优选MMLV RT)用来在酶(优选MMLV RT)到达模板核酸的5’-端并通过其末端转移酶活性将核苷酸添加到合成的cDNA或cRNA链的3’-端之后继续进行逆转录,即,不依赖于模板的。TSO的3’-端与通过模板依赖性DNA或RNA聚合酶的末端转移酶活性添加的核苷酸杂交,有效地延伸模板DNA或RNA的5’-端,从而使模板依赖性DNA或RNA聚合酶(优选RT,更优选MMLV RT)也逆转录TSO的剩余5’-部分,其包含将被添加到模板核酸的5’-末端的限定序列。如上文关于引发寡核苷酸所述的,这种限定序列不会与引发寡核苷酸序列或其互补序列杂交,并且优选也不会与样品中所含的核酸中存在的序列杂交。优选地,其不会在双链核酸(其是本发明方法的产物)的后续操作(特别是PCR或序列测定)中通常采用的条件下杂交。技术人员熟知如何选择可用作TSO的限定序列的合适序列。此外,TSO在其3’末端包含一个或更多个核苷酸,优选与步骤c)中通过RT酶添加的核苷酸互补的核糖核苷酸。优选地,TSO在其3’-端包含1至10个,即1、2、3、4、5、6、7、8、9或10个,优选3个连续的核苷酸,优选核糖核苷酸。优选地,如果添加两个或更多个核苷酸,则这些核苷酸是相同的。
在一个优选的实施方案中,在本发明的方法中使用的TSO表示为以下序列元件
5’-Xp-Y-Qt-Zq-Ar-3’
其中
X是选自氨基、生物素、甘油、胆固醇、地高辛、氟残基或核苷酸衍生物的化学基团,所述核苷酸衍生物包括脱碱基核苷酸、双脱氧核糖核苷酸、3’-脱氧核苷酸、2’-脱氧肌苷、2’-脱氧尿苷;
Y是已知的寡核苷酸序列;
Q是连续的简并(摆动)DNA碱基的序列,优选选自:N、V、H、D、B和J,其中N是并入来自dA、dT、dC和dG等摩尔混合物的核苷酸的产物;B是并入来自dT、dC和dG等摩尔混合物的核苷酸的产物;D是并入来自dA、dT和dG等摩尔混合物的核苷酸的产物;H是并入来自dA、dT和dC等摩尔混合物的核苷酸的产物;V是并入来自dA、dC和dG等摩尔混合物的核苷酸的产物,J是并入来自(0-100%dA)比(0-100%dG)比(0-100%dC)比(0-100%dT)比(0-100%dU)比(0-100%rA)比(0-100%rG)比(0-100%rC)比(0-100%rT)比(0-100%rU)的混合物的核苷酸的产物;
Z是选自AMP、CMP、GMP、TMP和UMP的核糖核苷酸,
A是选自氨基、生物素、甘油、胆固醇、地高辛、磷酸/盐/酯、氟残基或核苷酸衍生物的化学基团,所述核苷酸衍生物包括脱碱基核苷酸、双脱氧核糖核苷酸、3’-脱氧核苷酸、2’-脱氧肌苷、2’-脱氧尿苷;
t是0至6的整数,即0、1、2、3、4、5或6;
p是0至10的整数,即0、1、2、3、4、5、6、7、8、9或10;
q是至少为1的整数;和
r是0至10的整数,即0、1、2、3、4、5、6、7、8、9或10。
本领域技术人员应理解,在其中包含摆动碱基的情况下,权利要求实际上是指在摆动碱基处序列存在差异的TSO的混合物,其中一种核苷酸相对于另一种核苷酸的相对丰度由相应的用于合成TSO中该核苷酸位置的核苷酸混合物中的核苷酸的摩尔比确定。
向TSO的5’-末端添加大的化学基团(例如生物素、几种脱碱基核苷酸、荧光染料等)降低了第二模板转换事件的可能性,并且因而降低了含有两个或更多个拷贝的5’-末端序列的DNA产物的发生率。优选X是生物素。
Y是已知序列,也称为限定序列,因而在步骤a)的核酸的5’-端添加核苷酸序列,随后添加到本发明方法中产生的双链核酸中,其可以是单独或与添加到步骤b)中单链核酸或双链核酸的3’-端的限定核酸序列一起用于随后的步骤中,例如,扩增、检测或修饰从本发明方法的步骤e)得到的双链核酸。因此,优选Y具有足够的长度以允许寡核苷酸(例如具有15至50个核苷酸长度,更优选20至40个核苷酸的寡核苷酸)特异性杂交。优选地,其序列不同于步骤a)的单链核酸或双链核酸中发现的任何序列,也不同于步骤b)中添加至3’的任何序列。在优选的实施方案中,Y选自:SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8、SEQ ID NO:9、SEQ ID NO:10、SEQ ID NO:11、SEQ ID NO:12、SEQ ID NO:13、SEQ ID NO:14、SEQ ID NO:15和SEQ ID NO:16或相应的序列。
在反向引物中包含1至6个,更优选2至4个,即1、2、3、4、5或6个连续的摆动碱基将有助于在文库中分辨PCR重复。因此,在一个优选的实施方案中,Q是N、V、H、D、B或J,其中J为包含以下的混合物:(0-100%dA)比(0-100%dA)dG比(0-100%dA)dC比(0-100%dA)dT比(0-100%dA)dU比(0-100%dA)rA比(0-100%dA)rG比(0-100%dA)rC比(0-100%dA)rT比(0-100%dA)rU。优选将连续的摆动碱基包含在引发寡核苷酸中,因为其有助于在所产生的DNA文库中分辨PCR重复。最优选Q位于Z1和Z2之间并且为N。优选地,Q为N,t为至少2,更优选为4。
连续的摆动碱基的添加将有助于分辨所产生的文库中的PCR重复。优选地,Q为N,t为至少2,更优选为4。
向TSO的3’-末端的3’-OH基团添加化学“封闭”基团(例如磷酸/盐/酯、生物素、甲基、荧光染料等)防止TSO的多核苷酸加尾,如果同时进行多核苷酸加尾和逆转录二者,则TSO的多核苷酸加尾将发生。此外,向TSO的3’末端添加化学“封闭”基团将不再需要在RT反应之前的加尾反应中使用热失活模板非依赖性DNA或RNA聚合酶或连接酶。最后,向TSO添加化学“封闭”基团可以减少对于在5’端携带rG核苷酸的模板的偏向,当在RNA模板上使用3’-OH未封闭的TSO时会观察到这种现象。优选A选自氨基、生物素、甘油、胆固醇、地高辛、磷酸/盐/酯、氟残基或包括脱碱基核苷酸、双脱氧核糖核苷酸、3’-脱氧核苷酸、2’-脱氧肌苷、2’-脱氧尿苷的核苷酸衍生物。更优选地,A是选自脱碱基呋喃、rSpacer、Spacer 18、Spacer 9、Spacer C3或Spacer C12的脱碱基核苷酸。甚至更优选地,A包含多于一个脱碱基位点,并且是脱碱基呋喃,即三个连续的脱碱基呋喃。
本发明的步骤c)包括引发寡核苷酸的杂交和用合适的酶(例如逆转录酶)合成cDNA或cRNA以产生双链核酸。在一个优选的实施方案中,用末端脱氧核苷酸转移酶(步骤b))进行加尾反应并用逆转录酶进行杂交反应(步骤c))。更优选地,所用的逆转录酶同时具有聚合酶活性和末端转移酶活性,因此,所述酶可用于进行本发明方法的步骤b)以及步骤c)。甚至更优选地,所述逆转录酶选自,例如可从NEB获得的MMLV RT,例如可从Invitrogen获得的Superscript II RT或Superscript III RT,例如可从Applied Biosystems获得的Multiscribe RT,例如可从Clontech获得的SMART MMLV RT或SMARTScribe RT。在一个甚至更优选的实施方案中,使用M-MLV SuperScribe II RT或SmartScribe RT。优选选择具有聚合酶活性(即,可基于模板核酸合成互补核酸)和末端转移酶活性(即,当到达单链核酸的5’末端时,在没有模板的情况下能够添加额外的核糖核苷酸和/或脱氧核糖核苷酸)二者的聚合酶。优选地,它们能够向单链核酸的5’末端引入1个或更多个,优选2至20个,即2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20个额外的核糖核苷酸和/或脱氧核糖核苷酸杂交,从而使模板转换寡核苷酸与核酸链的3’末端之间杂交。优选逆转录酶主要包含同质核苷酸段,优选同质三核苷酸段,其随后促进逆转录酶从模板核酸到模板转换寡核苷酸的杂交。更优选地,添加三种dCTP或rCTP。
在本发明的另一个实施方案中,通过根据本发明方法的步骤e)的cDNA或cRNA的3’末端的延伸来合成双链核酸需要酶活性。TSO与本发明方法的步骤c)中产生的双链核酸的添加的同质三核苷酸的杂交允许使用TSO作为新模板延伸合成的核酸链。优选地,通过逆转录酶,更优选通过MLLV逆转录酶进行反应。在另一个优选的实施方案中,所用的逆转录酶能够转换至包含DNA/RNA和/或DNA/DNA双链核酸的模板。
通过本发明的方法合成的核酸可以在下游应用中进行进一步分析,即深度测序、基因分型或克隆。
在本发明的一个实施方案中,优选通过物理吸附、共价结合、亲和结合或基质包埋将双链核酸固定到表面上。更优选地,将本发明的核酸固定到微芯片、微阵列表面、二氧化硅基支持物、下一代测序平台特异性固体支持物上。
本发明的方法还可包括使用合成的双链核酸作为PCR扩增的模板的步骤。根据一个实施方案,本发明的方法还包括使合成的双链核酸或由其来源的单链经受扩增条件。这样的条件可包括添加被配置为扩增合成的双链核酸的全部或期望部分的正向或反向引物、dNTP和适于有效扩增的聚合酶,优选热稳定聚合酶。进行扩增的初始步骤可包括双链合成核酸的变性,并使合成的核酸可用于引物结合。合成的双链核酸优选包含引发寡核苷酸序列的至少一部分、所提供的单链核酸的互补链以及TSO的至少一部分。这些关于两条合成的核酸链的信息能够提供与各自序列互补的寡核苷酸以产生更大量的合成的双链核酸。在一个优选的实施方案中,本发明的方法包括使至少一种能够至少与步骤c)的引发寡核苷酸的一部分或步骤d)的模板转换寡核苷酸杂交的寡核苷酸与步骤e)中合成的双链核酸杂交。优选地,一个引物与引发寡核苷酸互补,另一个引物与模板转换寡核苷酸互补。引物浓度可在200-300nM的浓度范围内使用,即210、220、230、240、250、260、270、280、290、300nM。
可以在下游应用中进一步分析本发明方法的步骤f)的扩增产物,即深度测序、基因分型或克隆。在本发明的一个实施方案中,优选通过物理吸附、共价结合、亲和结合或基质包埋将扩增产物固定到表面上。
通过扩增合成的双链核酸,可以产生大量能够实现多种下游操作技术的核酸。由于合成的核酸具有限定的3’末端和5’末端,使得能够在本发明的方法所提供的单链核酸内测定目的序列。因此,在一个优选的实施方案中,本发明的方法还包括确定单链核酸序列的至少一部分的步骤。优选地,确定单链核酸的完整序列。
本发明的第二方面提供了包含以下序列元件的引发寡核苷酸:
3’-Wm-X-Yn-Z1o-Qt-Z2s-5‘
其中
W在每种情况下独立地选自:dA、dG、dC、dT和dU;
X选自:dA、dG、dC、dT、dU、rA、rG、rC、rT和rU;
Y是至少10个核苷酸长度的多核苷酸,其中所述序列的80%或更多由选自以下的相同的核苷酸或二核苷酸构成:dA、dG、dC、dT、dU、rA、rG、rC、rT、rU、AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TC、TG、TU、AA、CC、GG、TT、UU、UA、UC、UG和UT,其中所述序列的另外20%或更少由不同于主要核苷酸或二核苷酸并且也选自以下的核苷酸或二核苷酸构成:dA、dG、dC、dT、dU、rA、rG、rC、rT、rU、AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TC、TG、TU、AA、CC、GG、TT、UU、UA、UC、UG和/或UT,前提条件是X不同于构成Y大部分的核苷酸或二核苷酸;
Q是连续的简并(摆动)DNA碱基的序列,优选地选自:N、V、H、D、B和J,其中N是并入来自dA、dT、dC和dG等摩尔混合物的核苷酸的产物,即为dA、dT、dC或dG;B是并入来自dT、dC和dG等摩尔混合物的核苷酸的产物,即为dT、dC或dG;D是并入来自dA、dT和dG等摩尔混合物的核苷酸的产物,即为dA、dT或dG;H是并入来自dA、dT和dC等摩尔混合物的核苷酸的产物,即为dA、dT或dC;V是并入来自dA、dC和dG等摩尔混合物的核苷酸的产物,即为dA、dC或dG,J是并入来自(0-100%dA)比(0-100%dG)比(0-100%dC)比(0-100%dT)比(0-100%dU)比(0-100%rA)比(0-100%rG)比(0-100%rC)比(0-100%rT)比(0-100%rU)的混合物的核苷酸的产物;
Z1是限定序列的至少5个核苷酸长度的多核苷酸,其中所述序列不同于Wm-X-Yn,优选所述序列也不同于Qt-Z2s;
Z2是限定序列的至少5个核苷酸长度的多核苷酸,其中所述序列不同于Wm-X-Yn-Z1o-Qt;
m是0至6的整数,即0、1、2、3、4、5或6;
如果Y选自dA、dG、dC、dT、dU、rA、rG、rC、rT和rU,则n是10至100的整数,如果Y选自AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TC、TG、TU、AA、CC、GG、TT、UU、UA、UC、UG和UT,则n是5至50的整数;
o是0或1;
s是0或1;和
t是0至6的整数,即0、1、2、3、4、5或6。
Y是能够与添加的连续核酸杂交的引发寡核苷酸的一部分。因此,优选其与添加的核酸具有至少90%的序列互补性。因此,其优选具有对应于所添加的连续核苷酸的长度的长度,更优选地具有10至100个核苷酸的长度,即10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95或100个核苷酸。本发明人已经发现,短Y提高了序列精确度。然而,为了进行杂交,优选在严格条件下,优选Y具有11至50,更优选12至40,更优选13至30,最优选14至20的长度。
本发明人已经发现,低数目的不相同的核苷酸和/或二核苷酸的存在提高了测序精确度。因此优选Y的序列由选自以下的至少80%的相同核苷酸或二核苷酸构成:dA、dG、dC、dT、dU、rA、rG、rC、rT、rU、AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TC、TG、TU、AA、CC、GG、TT、UU、UA、UC、UG和UT,其中另外20%或更少由不同于主要核苷酸和/或二核苷酸并且也选自以下的核苷酸和/或二核苷酸构成:dA、dG、dC、dT、dU、rA、rG、rC、rT、rU、AC、AG、AT、AU、CA、CG、CT、CU、GA、GC、GT、GU、TA、TC、TG、TU、AA、CC、GG、TT、UU、UA、UC、UG和UT。在一个优选的实施方案中,主要核苷酸是A和/或T。在另一个优选的实施方案中,核苷酸是二核苷酸,优选AA、TT、AT或TA。在另一个优选的实施方案中,次要核苷酸C和/或G。在另一个优选的实施方案中,核苷酸是二核苷酸,优选CC、GG、CG和/或GC。在优选的实施方案中,Y的序列的80%至99%由相同的核苷酸和/或二核苷酸组成,更优选85%至95%(本领域技术人员清楚,在这种情况下,“n”必须至少为20),更优选88%至92%,最优选约90%。因此,在一个示例性的优选实施方案中,Y可包含9个T核苷酸和一个G或C核苷酸或者14个T和一个G或C。
在其中Y包含一个或两个不同核苷酸的情况下,优选这个(这些)核苷酸位于Y的中间或接近中间(即在1至4个碱基内)。
在本发明第二方面的另一个优选实施方案中,优选Y是仅由T组成的连续核苷酸段并且n的范围为10至60、即50、45、40、35、34、33、32、31、30、29、28、27、26、25、24、23、22、21、20、19、18、17、16、15、14、13、12、11或10,更优选11至50,更优选12至40,更优选13至30,最优选14至20。更优选n为30、20、16或15。最优选n为20或16。在该优选实施方案的替选中,Y包含一个或两个不同的核苷酸,还优选G或C。
在一个替选的优选实施方案中,Y的序列是除了1或2个G和/或C残基之外仅由T组成的连续核苷酸段。
Z1是引发寡核苷酸的一部分,其在合成双链核酸分子之后使用以进行另一寡核苷酸的序列特异性杂交。因此,Z1优选是添加到包含在样品中的核酸的3’末端的限定序列。Z1的长度为至少5个核苷酸,更优选在5至50个核苷酸的范围内,更优选在10至30个核苷酸的范围内。选择长度以使引物可在随后的PCR扩增反应中与Z1特异性杂交。在一个优选的实施方案中,Z1的核酸序列选自:SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8、SEQ ID NO:9、SEQ ID NO:10、SEQ ID NO:11、SEQ ID NO:12、SEQ ID NO:13、SEQ ID NO:14、SEQ ID NO:15和SEQ ID NO:16。
优选地,Z1不同于Z2。
Z2是引发寡核苷酸的一部分,其在合成双链核酸分子之后使用以进行另一寡核苷酸的序列特异性杂交。因此,Z2优选是添加到包含在样品中的核酸的3’-末端的限定序列。Z2的长度为至少5个核苷酸,更优选在5至50个核苷酸的范围内,更优选在10至30个核苷酸的范围内。选择长度以使得引物可在随后的PCR扩增反应中与Z1特异性杂交。在一个优选的实施方案中,Z2的核酸序列选自:SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8、SEQ ID NO:9、SEQ ID NO:10、SEQ ID NO:11、SEQ ID NO:12、SEQ ID NO:13、SEQ ID NO:14、SEQ ID NO:15和SEQ ID NO:16或相应的序列。
优选地,Z2不同于Z1。
在引物中(即,在Z1和Z2之间)包含1至6个,更优选2至4个,即1、2、3、4、5或6个连续的摆动碱基将允许在文库中分辨PCR重复。优选地,Q是连续的简并(摆动)DNA碱基的序列,优选在每种情况下独立地选自:N、V、H、D、B和J,其中N是并入来自dA、dT、dC和dG等摩尔混合物的核苷酸的产物;B是并入来自dT、dC和dG等摩尔混合物的核苷酸的产物;D是并入来自dA、dT和dG等摩尔混合物的核苷酸的产物;H是并入来自dA、dT和dC等摩尔混合物的核苷酸的产物;V是并入来自dA、dC和dG等摩尔混合物的核苷酸的产物,J是并入来自(0-100%dA)比(0-100%dG)比(0-100%dC)比(0-100%dT)比(0-100%dU)比(0-100%rA)比(0-100%rG)比(0-100%rC)比(0-100%rT)比(0-100%rU)的混合物的核苷酸的产物。优选将连续的摆动碱基包含在引发寡核苷酸中,因为其有助于在所产生的DNA文库中分辨PCR重复。最优选Q位于Z1和Z2之间并且为N。优选地,Q为N,t为至少2,更优选为4。
在另一个优选的实施方案中,t和s的和为0,例如,Z2和Q不存在。
特别优选的引发寡核苷酸的实例是具有根据SEQ ID NO:17、SEQ ID NO:18、SEQ ID NO:19和SEQ ID NO:20的核苷酸序列的核苷酸。
在第三方面,本发明提供了包含以下序列元件的模板转换寡核苷酸
5’-Xp-Y-Qt-Zq-Ar-3’
其中
X是选自氨基、生物素、甘油、胆固醇、地高辛、氟残基或核苷酸衍生物的化学基团,所述核苷酸衍生物包括脱碱基核苷酸、双脱氧核糖核苷酸、3’-脱氧核苷酸、2’-脱氧肌苷和2’-脱氧尿苷,优选生物素;
Y是已知(限定)的寡核苷酸序列;
Q是连续的简并(摆动)DNA碱基的序列,优选选自:N、V、H、D、B和J,其中N是并入来自dA、dT、dC和dG等摩尔混合物的核苷酸的产物;B是并入来自dT、dC和dG等摩尔混合物的核苷酸的产物;D是并入来自dA、dT和dG等摩尔混合物的核苷酸的产物;H是并入来自dA、dT和dC等摩尔混合物的核苷酸的产物;V是并入来自dA、dC和dG等摩尔混合物的核苷酸的产物,J是并入来自(0-100%dA)比(0-100%dG)比(0-100%dC)比(0-100%dT)比(0-100%dU)比(0-100%rA)比(0-100%rG)比(0-100%rC)比(0-100%rT)比(0-100%rU)的混合物的核苷酸的产物;
Z是选自AMP、CMP、GMP、TMP和UMP的核糖核苷酸,优选GMP,
A是选自氨基、生物素、甘油、胆固醇、地高辛、磷酸/盐/酯、氟残基或核苷酸衍生物的化学基团,所述核苷酸衍生物包括脱碱基核苷酸、双脱氧核糖核苷酸、3’-脱氧核苷酸、2’-脱氧肌苷和2’-脱氧尿苷;
p是0至10的整数,即1、2、3、4、5、6、7、8、9或10;更优选1或2,最优选1,
q是至少为1的整数;优选1至10,即,1、2、3、4、5、6、7、8、9或10,最优选3,
r是0至10的整数,即0、1、2、3、4、5、6、7、8、9或10,优选0或1,最优选0,并且
t是0至6的整数,即0、1、2、3、4、5或6。
向TSO的5’-端添加大体积的化学基团(例如生物素、几个脱碱基位点、荧光染料等)降低了第二模板转换事件的可能性,并因此降低了含有两个或更多个拷贝的5’-端序列的DNA产物的发生率。优选X是生物素。
Y是也称为限定序列的已知序列,从而在步骤a)的核酸的5’-端添加核苷酸序列,随后添加到本发明方法中产生的双链核酸中,其可以是单独或与在步骤b)中添加到单链核酸或双链核酸的3’-末端的限定核酸序列一起用于随后的步骤中,从而例如,扩增、检测或修饰从本发明方法的步骤e)得到的双链核酸。因此,优选Y具有足够的长度以使例如具有15至50个核苷酸(更优选20至40个核苷酸)的寡核苷酸特异性杂交。优选地,其序列不同于步骤a)的单链核酸或双链核酸中发现的任何序列,也不同于步骤b)中添加至3’的任何序列。在优选的实施方案中,Y选自:SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3、SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:6、SEQ ID NO:7、SEQ ID NO:8、SEQ ID NO:9、SEQ ID NO:10、SEQ ID NO:11、SEQ ID NO:12、SEQ ID NO:13、SEQ IDNO:14、SEQ ID NO:15和SEQ ID NO:16或相应的序列。
在另一个优选的实施方案中,Q是连续的简并(摆动)DNA碱基序列,优选选自:N、V、H、D、B和J,其中N是来自并入dA、dT、dC和dG等摩尔混合物的核苷酸的产物;B是并入来自dT、dC和dG等摩尔混合物的核苷酸的产物;D是并入来自dA、dT和dG等摩尔混合物的核苷酸的产物;H是并入来自dA、dT和dC等摩尔混合物的核苷酸的产物;V是并入来自dA、dC和dG等摩尔混合物的核苷酸的产物,J是并入来自(0-100%dA)比(0-100%dA)dG比(0-100%dA)dC比(0-100%dA)dT比(0-100%dA)dU比(0-100%dA)rA比(0-100%dA)rG比(0-100%dA)rC比(0-100%dA)rT比(0-100%dA)rU的混合物的核苷酸的的产物。
A具有如上在本发明的第一方面的上下文中所述的功能。优选地,A选自:氨基、生物素、甘油、胆固醇、地高辛、磷酸/盐/酯、氟残基或者包括脱碱基核苷酸、双脱氧核糖核苷酸、3’-脱氧核苷酸、2’-脱氧肌苷、2’-脱氧尿苷的核苷酸衍生物。更优选地,A为选自:脱碱基呋喃、rSpacer、Spacer 18、Spacer 9、Spacer C3或Spacer C12的脱碱基核苷酸。甚至更优选地,A包含一个以上的脱碱基位点,即三个连续的脱碱基呋喃。
在第四方面,本发明提供了包含本发明第二方面的引发寡核苷酸的核酸。优选地,核酸含有所使用的引发寡核苷酸的序列。
在本发明的第五方面提供了试剂盒,所述试剂盒提供本发明的第一方面的方法的性能。试剂盒可包含进行本发明每个方法步骤a)至f)所必需的试剂。试剂盒可包括例如一种或更多种关于方法步骤a)至f)的主题描述的任何反应混合物组分。例如,试剂盒可包含聚合酶(例如,能够模板转换的聚合酶、热稳定聚合酶或其组合)、引发寡核苷酸、模板转换寡核苷酸、dNTP、盐、酶的合适辅因子、核酸酶抑制剂(例如RNA酶抑制剂或DNA酶抑制剂)、用于促进富含GC序列的扩增或复制的一种或更多种添加剂(例如甜菜碱、二甲亚砜、乙二醇或1、2-丙二醇或其组合、一种或更多种去稳定剂(例如,二硫苏糖醇),能够产生具有3’突出端的双链核酸的酶(例如限制性内切核酸酶、末端转移酶或其组合)和封闭核苷酸,优选3d-NTP、3-Me-NTP和ddNTP或任何其他所需的试剂盒组分,例如管、珠、微流体芯片等。在本发明试剂盒的优选实施方案中,本发明试剂盒包括能够将核苷酸添加到单链核酸的3-端的试剂,优选酶,更优选聚A聚合酶或末端转移酶。优选试剂盒还包含引发寡核苷酸和模板转换寡核苷酸以及任选地能够切割蛋白质中肽键的酶,更优选地,该酶是内肽酶或外肽酶,最优选蛋白酶K。在该方面的另一个优选实施方案中,试剂盒可提供进行序列测定方法所需的试剂。更优选地,试剂盒提供的试剂提供用于下一代测序的工具,例如使用捕获探针的靶标富集。
在第六方面,本发明提供了包含至少一种本发明第四方面的核酸的阵列。优选地,阵列允许所述核酸序列的序列测定。更优选地,所述阵列可用于测量表达水平的变化、检测单核苷酸多态性(SNP)或用于基因分型或靶向重测序或提供用于深度测序的工具。
大规模平行测序(MPS)技术在例如个体化医学的若干研究领域中开辟了进入新领域的途径。期望提供在特定细胞类型、组织或器官中在任何特定时间存在的核酸分子的序列和频率。例如,计数由单个基因编码的mRNA的数目(所谓的转录组)提供了蛋白质编码潜力的指示,蛋白质编码潜力是表型的主要贡献者。在第七方面,本发明提供了通过本发明的方法合成的双链核酸或由其来源的单链核酸的用途。在一个优选的实施方案中,通过本发明的方法合成的核酸可以用于测序或表达分析、克隆、标记、用于鉴定基因或特定核苷酸序列。优选地,所述用途包括在以下方面的用途:个性化医疗;治疗监测;人或动物疾病的预测、预后、早期检测或法医学;病毒、细菌、真菌、动物或植物或其来源之细胞的核酸序列的分析,优选用于植物的表征;果实育种检查;植物、种子或果实的疾病检测。
实施例
实施例1:RNA和DNA样品
使用合成cel-miR-39(Sigma-Aldrich),来自线虫(C.elegans)的22nt微小RNA作为小RNA测序对照的输入。使用序列与cel-miR-39等同的合成22nt DNA(Sigma-Aldrich)作为DNA测序对照的输入。从来自两个自愿健康供体(DI,女性和DII,男性)血液样品的血浆级分中分离循环DNA。从两个自愿的女性健康供体(RI和RII)的血浆中分离循环RNA。该样品收集经海德堡医学院伦理委员会批准。将从人血浆分离的循环DNA和RNA、来自U2OS细胞的亚硫酸氢盐转化的DNA和来自U2OS细胞的Mg2+分级的聚A富集的总RNA用作cDNA文库制备和随后的Illumina MiSeq测序的输入。
实施例2:用于cDNA合成的寡核苷酸
在图2-5中提供了在本工作中使用的所有引物的序列。在该方法的开发期间测试了几种不同结构的模板转换寡核苷酸(TSO)。
实施例3:第一链cDNA合成和模板转换
将合成的小RNA或DNA在水中稀释以达到1ng/μl和5pg/μl的浓度,并用作合成第一链cDNA的起始材料。生成随时可测序的DNA文库的优化方案如下。使用大肠杆菌聚(A)聚合酶(New England Biolabs)在含有10单位重组RNAse抑制剂(Clontech)和0.1mM ATP的1×PAP缓冲液中在37℃下将RNA聚腺苷酸化10分钟,并通过在65℃加热20分钟终止。在37℃下,使用末端脱氧核苷酸转移酶(New England Biolabs)在1×TdT缓冲液和0.1mM dATP中对DNA进行30分钟聚(dA)加尾,并在70℃下热灭活10分钟。在聚(dA)加尾之前,通过在95℃加热5分钟将循环DNA和亚硫酸氢盐转化的DNA样品变性并在冰上快速冷却。在一些实验中,在聚(A/dA)加尾之前,将RNA和DNA模板在1×PAP/TdT缓冲液中用T4多核苷酸激酶(New England Biolabs)预处理10分钟。对于逆转录,将1μl的聚(A)加尾的RNA或聚(dA)加尾的DNA与2.5μl含有20%DMSO的1×第一链RT缓冲液和1μl单碱基锚定的Illumina聚(dT)引物混合(对于1ng的RNA或DNA,终浓度为0.1μM,对于5pg的RNA或DNA,终浓度为0.001μM)。将整个溶液在72℃下孵育2分钟,然后42℃下冷却1分钟。在下一步中,将含有2μl 5×第一链RT缓冲液(Clontech)、1μl dNTP(各10mM)、1μl SmartScribe RT聚合酶(Clontech)、0.25μl DTT(100mM)和0.25μl重组RNAse抑制剂(Clontech)的主混合物(master mix)添加到DNA(RNA)/引物溶液中,并在42℃下孵育15分钟。接下来,将1μl的10μM 5’-生物素封闭的模板转换寡核苷酸(TSO)添加到RT反应中,并在42℃下再温育15分钟。通过在70℃下加热10分钟终止RT反应。在100μl的总体积中,使用1μl或10μl的RT反应进行cDNA扩增。使用终浓度为250nM的cDNA扩增引物在2×Taq聚合酶主混合物(Qiagen)中进行cDNA的扩增(图2A)。使用Qiaquick PCR纯化试剂盒(Qiagen)对扩增的cDNA进行柱纯化,并通过GATC GmbH(Konstanz,Germany)的Sanger自动测序进行测序。对于下一代测序,使用PureLink Gel Extraction试剂盒(Life Technologies)从4%琼脂糖凝胶中另外纯化DNA片段,并用Agilent Bioanalyser高灵敏度DNA芯片进行分析。
实施例4:深度测序
Illumina MiSeq平台用于对通过上述方法制备的DNA文库进行测序。使用由Illumina标准测序引物和3’-端GGG三核苷酸组成的定制测序引物进行Illumina MiSeq测序以成功解决进行簇(cluster)鉴定所需的前几个碱基的必需复杂度的问题。定制的聚(T)测序引物可用于在相反方向进行测序,使得能够产生配对的末端测序数据。将DNA文库稀释至5nM的浓度,用0.2N NaOH变性5分钟,并进一步稀释至11pM之后立即装载到MiSeq盒中。使用MiSeq Reagent试剂盒(50个循环)进行77个循环的MiSeq运行。
- 还没有人留言评论。精彩留言会获得点赞!