特异于黏结蛋白聚糖-1的人源化单克隆抗体的制作方法
本发明的实施方式涉及免疫学、生物技术和医学,特别地涉及基于单克隆抗体的抗肿瘤药物的领域,并且可以在用于治疗肿瘤学疾病的医学中使用。
背景技术:
肿瘤学疾病是心血管疾病之后的第二最常见死亡原因[http://www.who.int/healthinfo/EN_WHS2012_Full.pdf]。根据不同来源,在过去10年中,被诊断患有癌症的人的数目增加了15%。在俄罗斯联邦,每年登记超过490,000例新患者,2.5×106例癌症携带者处于医生的护理下,并且每年超过290,000例癌症患者(cancer-stricken)死于不同的癌症形式。出于该原因,安全、有效和负担得起的抗肿瘤药物的研发和创造是必需的。
一种类型的抗肿瘤药物涉及生物技术合成的产品——单克隆抗体(MAb)。当前有数种药物在使用中,在它们中存在表皮生长因子受体、血管内皮生长因子的MAb,其被证明为对肿瘤细胞活性具有作用并且对不同组织的正常细胞的机能具备不充分的影响[Zhukov N.V.,Tjulandin S.A.Targeted therapy in the treatment of solid tumors:practice contradicts theory/Biochemistry(Mosc).2008 May;73(5):605-18]。
在世界上,基于单克隆抗体的大约10种抗肿瘤药物在当前被注册并且生产,特别是利妥昔单抗(rituximab)(CD20受体的MAb)、曲妥单抗(trastuzumab)(HER2neu受体是靶标)、贝伐单抗(bevacizumab)(VEGF)、西妥昔单抗(cetuximab)和帕尼单抗(panitumumab)(EGFR)。当前,不存在靶向表面抗原黏结蛋白聚糖-1(CD138)的注册的药物。
黏结蛋白聚糖-1蛋白(CD138)[Wijdenes J.,Dore J.M.,Clement C.,Vermot-Desroches C.(2003)."CD138".J.Biol.Regul.Homeost.Agents 16(2):152–5]是利用单克隆抗体进行抗肿瘤疗法的有希望的靶标:已经证明该分子在肿瘤细胞活性中发挥重要作用并且揭示了其对多种组织的正常细胞的机能具有不充分的影响[Guo P.et al.Expression of legumain correlates with prognosis and metastasis in gastric carcinoma//PloS One.2013.Vol.8,№9.P.e73090]。
该分子提供了细胞-细胞和细胞-基质相互作用、黏附和迁移。CD138的过表达在大多数(大约90%)的各种肿瘤类型和其它上皮性恶性肿瘤的细胞中揭示,所述肿瘤类型包括乳腺癌、结肠癌、胃癌、前列腺癌[Rousseau et al.EJNMMI Research 2011,Bayer-Garner I.B.,Sanderson R.D.,Dhodapkar M.V.et al.Syndecan-1(CD138)immunoreactivity in bone marrow biopsies of multiple myeloma:shed syndecan-1 accumulates in fibrotic regions.Mod Pathol 2001;14:1052—8]。也描述了这样的现象为黏结蛋白聚糖-1自髓样细胞的细胞表面损失和其在基质中——一般来说在纤维化区域中——累积[Baikov V.V.Difficulties in morphological diagnostics of multiple myeloma.Moscow,Oncohematology 2`2007,p.p.10-15]。揭示了在黏结蛋白聚糖-1的损失下,髓样细胞经历TRAIL-诱导的凋亡[Wu Y.H.,Yang C.Y.,Chien W.L.,Lin K.I.,Lai M.Z.Removal of syndecan-1promotes TRAIL-induced apoptosis in myeloma cells.J Immunol.2012 Mar 15;188(6):2914-21.Epub 2012 Feb 3]。黏结蛋白聚糖-1与肿瘤细胞的侵入性生长和转移性倾向在功能上相关。就恶性肿瘤疗法而言,CD138的活性与肿瘤细胞的这类性质相关联,其对现有疗法几乎不应答。
揭示了肿瘤细胞表面上CD138以可以被抗体识别的形式的定位[Wu B.et al.Blastocystis legumain is localized on the cell surface,and specific inhibition of its activity implicates a pro-survival role for the enzyme//J.Biol.Chem.2010.Vol.285,№3.P.1790–1798]。而且,存在揭示使用CD138作为抗原接种疫苗的效力的数据[Bae J.,Tai Y.T.,Anderson K.C.,Munshi N.C.2011]。
在当前使用黏结蛋白聚糖-1的鼠科抗体—В-В4(IgG1)[Wijdenes J.,Vooijs W.C.,Clement C.et al.A plasmacyte selective monoclonal antibody(B-B4)recognizes syndecan-1.Br.J.Haematol 1996;94:318—23]、B-B2(IgG2b)以及嵌合抗体[Baikov V.V.2007,Kovrigina A.M.,Probatova N.A.Differential diagnostics of non-Hodgkin's B-cell`s lymphoma.Oncohematology.2`2007,p.6]—MI15(IgG1κ)—和它们与标记物的缀合物[ClinicalTrials.gov identifier:NCT01296204,Gattei V.,Godeas C.,Degan M.,Rossi F.M.,Aldinucci D.,Pinto A.Characterization of anti-CD138 monoclonal antibodies as tools for investigatingthe molecular polymorphism of syndecan-1 in human lymphoma cells.Br J Haematol.1999 Jan;104(1):152-62]。这些化合物被用于研究或诊断学的目的,抗体仅执行靶向功能[Baikov V.V.2007,Kovrigina A.M.,Probatova N.A.,2007]。通过效应器分子执行细胞毒功能,这些效应器分子主要地与抗体缀合[WO2009080832(A1)、WO2009080830(A1)、WO2010128087(A2)]。由于抗体的恒定结构域(CH、CL)中的差别,鼠科和兔MAb被人免疫系统识别为异物,并且针对它们的免疫应答被引发。出于在人中使用的目的,嵌合抗体正在被研发,其具备人恒定结构域(CH、CL)和鼠科可变结构域(VH、VL)。该修饰使得制造MAb更安全。亚类IgG4的CD138的嵌合单克隆抗体是已知的[WO2009080829(A1)],其被本发明的作者视为原型。但是,该MAb提供了仅靶向与其缀合的细胞毒素剂(DM4)。
许多发明是已知的,其中提及了CD138的抗体,但是没有给出这些抗体的结构。人CD138的抗体已知具有糖基化的修饰,借助于使用表达编码(1,4)-N-乙酰葡糖胺转移酶(acetylglucosaminiltransferase)III(GnT III)的至少一种核酸和编码人抗-CD138抗体的至少一种转染的核酸的细胞获得,但是没有给出这种抗体的氨基酸和/或核苷酸序列,没有表征这种抗体的结构[RU2321630C2]。发明的变体是已知的,其中抗-CD138抗体与抗-Trop-2抗体和化学治疗剂的缀合物或粘蛋白的抗体或其抗原结合片段和放射性核素的缀合物被共施用用于治疗胰腺癌[US2014044640(A1)]。已知下列的缀合物:结合至CD138的抗体,和抗-CD74抗体[US2014056917A1],和SN38分子[US2014058067(A1)],包括其片段,作为抗体双特异性结构的一部分[US2014086832(A1)]。还已知如此组合物,其包含能够结合至浆细胞的锚定区和结合至特异性浆细胞抗体的位点——其结合至锚定区,能够结合至黏结蛋白聚糖-1的抗体可以是设计的一部分[WO2014037519(A2)]。
当前使用黏结蛋白聚糖-1的重组抗体(OC-46F2),其由于人抗体对人黑素瘤细胞的体外噬菌体展示文库选择(ETH-2-Gold)和随后在哺乳动物细胞中表达获得的基因而产生[Orecchia P,Conte R,Balza E,Petretto A,Mauri P,Mingari MC,Carnemolla B.A novel human anti-syndecan-1 antibody inhibits vascular maturation and tumour growth in melanoma.Eur J Cancer.2013 May;49(8):2022-33.doi:10.1016/j.ejca.2012.12.019.Epub 2013 Jan 24]。已经揭示了该抗体抑制人黑素瘤实验模型(在小鼠上)中血管成熟和肿瘤生长。也已经证明了其在人卵巢癌模型中是治疗上有效的。
OC-46F2代表单链可变片段(scFv)——由经由短连接体肽连接的重(VH)和轻(VL-λ)免疫球蛋白链的可变片段组成的融合蛋白。
该化合物不包含恒定抗体片段——其使与抗体形成的应用相关联的足够的免疫应答复杂化,分子的可变片段仅提供了与抗原的接合,确定了由作者揭示的阻遏效应。但是,额外的活性化合物,和可能地,缀合物的生产在该情况下对于肿瘤消除是必需的。
以这种方式,当前描述的CD138的鼠科抗体由于它们的高免疫原性不适合在人中使用。它们仅被用于实验室目的。嵌合MAb不具备任何独立的治疗效果——它们仅被应用为靶向剂——并且也可以是免疫原性的。患者对特定MAb的个体反应应当被排除。此外,经由抗体靶向的活性剂,或其降解产物可以成为人类有机体的应激因子,这是由于它们的结构、衰变能力、衰变周期和其降解的化合物的特性。黏结蛋白聚糖-1的天然人单克隆抗体的精确结构尚未建立。
考虑到黏结蛋白聚糖-1在肿瘤的侵入性生长和转移性倾向中的功能性作用,在目前生成更有效和安全的抗体是关键的任务。
该任务通过本发明解决,本发明不具备类似物的劣势。
应用特异于CD138的本抗体的技术结果至少在于在肿瘤疗法中使用的MAb——以及CD138——的谱扩展,其使得在对类似物的特应性或弱耐受性下提供治疗。
技术结果是CD138的抗体的效力的增加。揭示的技术结果通过获得独立抗肿瘤活性实现——其由于使用由作者计算和创建的提出的IgG4同种型的抗体,由通过发明人获得的抗体链的描述序列的具体组合,以及通过对抗原的增加亲和力代表——也由于本抗体的使用、也由于抗体的人源化:由于人抗体框架的使用,更精确地定位高变区是可能的,其增加表位和互补位的一致性,并且因此增加亲和力。
独立抗肿瘤活性在本发明的实施方式之一中通过如下事实实现:介导高抗体-和补体-依赖性细胞毒性的IgG3链的片段被插入IgG4抗体的重链的恒定片段,结果是这样的抗体在结合至CD138之后具有增加的细胞毒效应。当使用本发明的该实施方式时,所述技术结果也通过抗体半衰期的增加实现,所述抗体半衰期的增加通过在重链的恒定部分的C末端处引入氨基酸置换实现。这使得实现更长的效果,使用较低剂量,进行更少的抗体施用,其也可以使得降低治疗费用。
应用CD138的本抗体的技术结果也在于抗癌药物的安全性的增加。指出的技术结果通过降低免疫原性实现,其由于抗体的人源化并且也由于如下事实:活性剂是单克隆抗体分子——蛋白质,其后来降解为氨基酸,即,如果被应用,在某一时间内活性剂(非蛋白质化合物)或其降解产物的未清除(nonclearance)的任何后果被排除,因此观察到抗肿瘤药物对人类有机体的应激效应的降低。
技术结果也在于效力的增加、生产的简化和固定化(fastening),其使得降低价格,这通过在短时间内在哺乳动物细胞中获得较高表达率的抗体——由于编码序列的密码子优化,以及由于在轻和重链的N末端处插入信号分泌序列——实现。
技术实现要素:
本发明的目标是创建有效的和安全的通用抗癌药物,其生产是有效的、短时间的和简单的。该任务利用特异于CD138的给定单克隆抗体解决,该单克隆抗体适合于肿瘤疗法并且具有对于抗原(CD138)的高亲和力,具有单独的抗癌活性和低免疫原性,活性成分恰好是单克隆抗体的分子,起源于蛋白质,其可以在哺乳动物细胞中在短时间内以高的量产生。在一个实施方式中,该问题被解决,因为提出的特异于黏结蛋白聚糖-1的单克隆抗体具有较高的细胞毒性和长半衰期。
所获得的抗体的这些性质通过在实施例中给出的研究结果确认并且是由于通过使用发明人计算和创建的抗体链、它们的具体组合和编码序列的结构表达的其结构。
特异于IgG4同种型的黏结蛋白聚糖-1的单克隆抗体被提出,其重链由氨基酸序列SEQ ID NO:1表征,轻链由氨基酸序列SEQ ID NO:7表征,或者重链由氨基酸序列SEQ ID NO:5表征,轻链由氨基酸序列SEQ ID NO:3或SEQ ID NO:7表征,抗体被用作肿瘤疾病的疗法的自作用物质。而且,特异于IgG4同种型的黏结蛋白聚糖-1的单克隆抗体被提出,在其重链的恒定片段中,IgG3区被包含,以及在C末端处的氨基酸置换,以增加半衰期,重链由氨基酸序列SEQ ID NO:9表征,轻链-κ并且由氨基酸序列SEQ ID NO:7表征,或重链由氨基酸序列SEQ ID NO:11表征,轻链-SEQ ID NO:3或SEQ ID NO:7,抗体被用作肿瘤疾病的疗法的自作用物质。而且,提供了编码特异于黏结蛋白聚糖-1单克隆抗体——其由氨基酸序列SEQ ID NO:5或SEQ ID NO:7或SEQ ID NO:9或SEQ ID NO:11表示——的链的多核苷酸,密码子被优化以便在生产细胞中表达。对于在哺乳动物细胞中的表达,每种多核苷酸进一步包括在从生产细胞分泌之后切割的N末端处编码信号分泌序列的片段,密码子被优化以便在哺乳动物细胞中表达,并且由SEQ ID NO:6或SEQ ID NO:8或SEQ ID NO:10或SEQ ID NO:12表征。
附图说明
在图1、4、7中给出了Kaplan-Meier存活曲线。
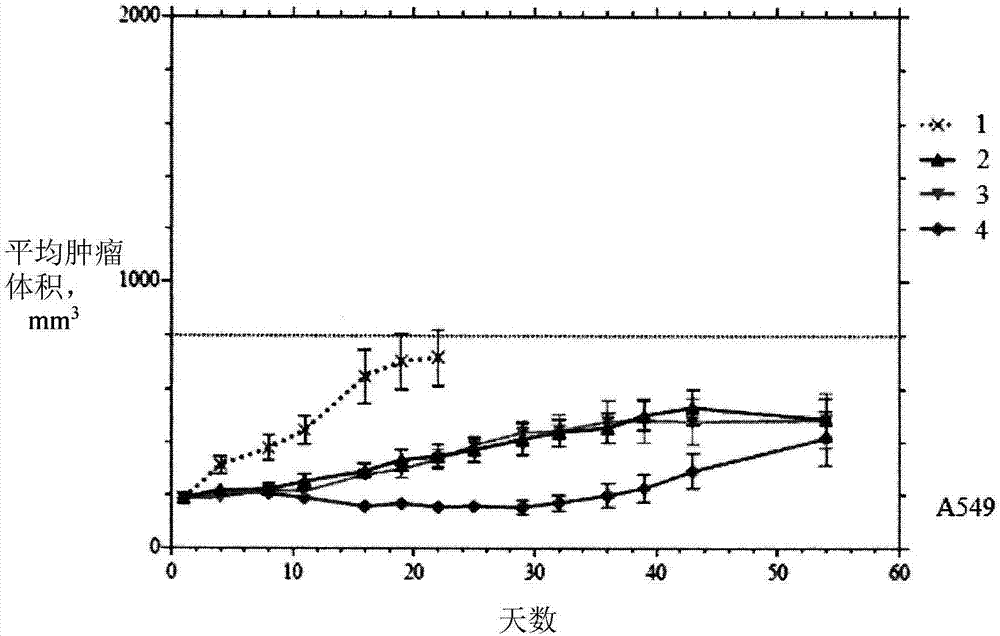
在图2、5、8中给出了从第一天按组的平均肿瘤生长±SEM。
在图3、6、9中给出了从第一天的组平均体重改变BW——为百分数——±SEM。
在所有的图中:1-对照,4-紫杉醇,在图1-3中,对于A549:2-Mab4、3-Mab6,在图4-6中,对于Colo 205:2-Mab2、3-Mab3,在图7-9中,对于PC3,2-Mab1、3-Mab5。
实现本发明的实施例
实施例1.黏结蛋白聚糖-1的Mab的生产
1.1.黏结蛋白聚糖-1的生产
编码黏结蛋白聚糖-1的基因以两个步骤经由化学发酵合成[Young L,Dong Q.,Two step total gene synthesis method.Nucleic Acid Research:32,e59,2004]进行合成。将获得的基因在载体pET151/D-TOPO中克隆,然后利用其转化大肠杆菌BL21(DE3)Star菌株的细胞。
进行生产菌株的发酵和重组蛋白提取。黏结蛋白聚糖-1经由金属螯合色谱纯化。
重组蛋白具有98%的纯度并且被用于获得生产黏结蛋白聚糖-1的鼠科单克隆抗体的杂交瘤,并且用于测试获得的单克隆抗体。
1.2.利用黏结蛋白聚糖-1免疫Balb/C小鼠
进行Balb/C小鼠的免疫。纯化的重组黏结蛋白聚糖-1蛋白被用作抗原。在初次免疫期间,将具有完全弗氏佐剂(CFA)的50μg抗原皮下注射入小鼠。在接种后28天,分析对注射的抗原的免疫应答的水平,经由酶联免疫吸附测定(ELISA)评估血清中的特异性抗体的效价。具有最高水平免疫应答的动物再次皮下接受含有不完全弗氏佐剂(IFA)的30μg抗原,并且二次免疫应答的水平在注射后21天评估。之后,在体细胞杂交之前4-5天,腹腔内注射在生理盐溶液(NSS)中的30μg抗原。
1.3.生产合成特异于黏结蛋白聚糖-1的单克隆抗体的杂交瘤
作为融合配偶体,以2:1的比率使用免疫小鼠的脾细胞——其对黏结蛋白聚糖-1蛋白具有大约1:30000的血清抗体效价——和鼠科骨髓瘤细胞SP2/0–Ag14(ATCC,CRL-1581)。借助于聚乙二醇溶液(Sigma)根据标准方法进行杂交。经由在IMDM培养基(Iscove’s Modified Dulbecco Medium,Sigma)中培养进行稳定的杂交细胞选择,该培养基含有10%FCI血清(HyClone)和NAT(Gibco)。经由酶联免疫吸附测定(ELISA)进行分泌特异于期望抗原的抗体的杂交细胞克隆的选择。作为初次筛选的结果,选择生产黏结蛋白聚糖-1的单克隆抗体的10种杂交细胞克隆。在五次克隆组之后,获得4种稳定的生产克隆。从每个细胞系分离出编码黏结蛋白聚糖-1的抗体的重和轻链的mRNA。
1.4.设计黏结蛋白聚糖-1的人源化抗体
根据制造商的方案使用“TRI Reagent”试剂盒(Sigma,USA)从杂交细胞的稳定克隆——其生产黏结蛋白聚糖-1的单克隆抗体——分离RNA。每(5-10)·106个细胞使用1ml裂解液“TRI Reagent”。利用RevertFirst Strand cDNA Synthesis Kit(Fermentas,Lithuania)进行cDNA合成。
使用5’简并的引物——用于对未知VH和VL区退火——和合成的cDNA作为基质通过PCR方法进行编码鼠科抗体的可变片段的基因的扩增。通过PCR利用高度精确的热稳定性DNA聚合酶Pfx进行待克隆的DNA片段的扩增。使用Fast Ligation Kit,Fermentas将获得的PCR产物克隆入pGMT-easy载体,并且根据Sanger方法测序。发现杂交瘤1和杂交瘤2合成不同的MAb,其被用于获得本发明的单克隆抗体。
测序结果被用于获得人源化单克隆抗体。
通过将检测到的(借助于计算机算法对获得的核苷酸序列评估的)负责与抗原互补的鼠科抗体的可变片段的高变区(CDR)转移至人可变片段进行抗体人源化;根据抗体之间结构类似性的数据库分析和生物信息学建模的结果在适合的框架区之间定位CDR。所获得的人源化抗体具备母体鼠科抗体的特异性,而且还具有较高亲和力,这是因为由于框架区引起的CDR的更适合的三维位置。
下列程序被用于分子图形学:Insight II;Accelrys,CA。经由WAM(http://antibody.bath.ac.uk)、SWISS-MODEL(http://www.expasy.org)、INSIGHT-HOMOLOGY(Accelrys)、COMPOSER(Tripos,MO)和GCG Wisconsin Package进行鼠科供体抗体与人受体抗体之间的构象同源性的建模。经由Kabat和Chothia数据库注释和索引鼠科抗体可变片段的序列。
通过由Chothia[Chothia C,Lesk AM.Canonical structures for the hypervariable regions of immunoglobulins.J Mol Biol.1987 Aug 20;196(4):901-17]研发的索引考虑关于可变片段的结构的信息。但是,抗体的可变片段中的氨基酸残基不被该索引考虑。关于用于索引和注释上面提及的可变片段的数据,应用Kabat和Chothia改良的算法—Abhinandan KR和Martin AC[Abhinandan KR and Martin AC.Analysis and Prediction of VH/VL Packing in Antibodies,Protein Engineering Design and Selection.2010,Abhinandan KR,Martin AC.Analysis and improvements to Kabat and structurally correct numbering of antibody variable domains.Mol Immunol.2008 Aug;45(14):3832-9]。在索引期间,不仅来自Kabat的多个抗体序列比对的校准数据和考虑FR结构的Chothia的结构性CDR数据被考虑,而且考虑在供体和受体抗体中折叠的VH/VL角度。对于自动注释,使用具有交互式网站界面的程序:SeqTest(AbCheck)http://www.bioinf.org.uk/abs/seqtest.html,Abnum http://www.bioinf.org.uk/abs/abnum/,经由Kabat数据库http://www.kabatdatabase.com/index.html的本地版本,和程序KabatMan http://www.bioinf.org.uk/abs/simkab.html,以及IMGT http://imgt.cines.fr/,以及借助于经由MUSCULE http://www.ebi.ac.uk/Tools/muscle/index.html由抗体序列的多可变片段拟合的校准数据,和程序包FASTA http://fasta.bioch.virginia.edu/fasta_www2/fasta_down.shtml——其结构已经于2012年在PDB中呈现,以及通过由本发明的作者开发的用于自动化数据分析的数种Perl脚本,进行手动校准和验证。VH/VL角度基于由Abhinandan[Abhinandan K.R.,2010]提供的算法进行计算和预测。使用Modeller和Swiss-Model进行与蛋白质的分子结构建模相关的所有必要的计算。
用于抗体的人源化的下个步骤是用于转移的人抗体的受体可变片段的选择。人受体抗体的正确选择确保抗体的几乎100%成功人源化,该抗体具有对于与抗原的高强度结合足够的Kd值。通过分子建模的方法和上面提及的途径,构建揭示的黏结蛋白聚糖-1的鼠科单克隆抗体的可变片段的结构模型。使用获得的3D模型,评估人受体抗原的最同源的(尤其考虑到关键位置)序列,而仅具有H>1的“人性(humanity)”系数的抗体被应用(其可以潜在地降低HAHA应答)。基于获得的模型,评估抗体的重和轻(κ)链的可变片段的氨基酸序列。
1.5.生产黏结蛋白聚糖-1的单克隆抗体
将重链的恒定和计算的可变片段的氨基酸序列接合至一个氨基酸序列(SEQ ID NO:5–分别地对于杂交瘤1)。将恒定和计算的可变κ轻链片段的序列接合成单一氨基酸序列(SEQ ID NO:7–分别地对于杂交瘤2)。
另外地,为获得的杂交瘤2构建嵌合重链和为杂交瘤1构建轻链。连接重链的鼠科可变和人恒定片段的氨基酸序列(SEQ ID NO:1–分别地对于杂交瘤2)。也连接κ轻链的鼠科可变和人恒定片段的氨基酸序列(SEQ ID NO:3–分别地对于杂交瘤1)。
将获得的氨基酸序列转换至核酸序列,进一步,将片段加入至编码在由生产细胞分泌之后切割的信号分泌序列的N末端,并且使用网站http://www.encorbio.com/protocols/Codon.htm上的程序进行密码子优化以便增加在哺乳动物细胞(CHO)中这些抗体的产生。
结果,获得编码黏结蛋白聚糖-1的单克隆抗体的链(SEQ ID NO:1、SEQ ID NO:3、SEQ ID NO:5、SEQ ID NO:7)的最终版本的核苷酸序列(SEQ ID NO:2、SEQ ID NO:4、SEQ ID NO:6、SEQ ID NO:8),其然后使用化学合成进行合成。
再者,获得被修饰以执行增加的活性的抗体。对于此IgG3,将在所有同种型中具有最高补体系统活化率以及对吞噬细胞的最高Fc受体结合亲和力的片段插入IgG4重链恒定片段中。出于增加抗体半衰期的目的,将氨基酸置换也插入IgG4恒定片段的C末端区中。
将估计的重链可变和恒定片段的序列连接至一个序列(SEQ ID NO:9–分别地对于杂交瘤1)。
重链的这种变体也基于嵌合重链——其基于由杂交瘤2获得的鼠科嵌合重链创建——接收,结果是将重链的鼠科可变和计算的人恒定片段的氨基酸序列连接成一个氨基酸序列(SEQ ID NO:11)。
核苷酸序列基于蛋白质的氨基酸序列计算,另外地,引入N末端上编码在由生产细胞分泌时释放的分泌序列的片段,并且出于增加在哺乳动物细胞(CHO)中本抗体生产的目的,借助于来自互联网http://www.encorbio.com/protocols/Codon.htm的程序还进行密码子优化。
结果,获得编码具有IgG4-IgG3转变(SEQ ID NO:9、SEQ ID NO:11)的黏结蛋白聚糖-1的单克隆抗体的重链的核苷酸序列(SEQ ID NO:10、SEQ ID NO:12)的最终版本。化学地合成获得的核苷酸序列。将合成的片段在质粒载体pUC57中克隆进行扩增,并且然后出于哺乳动物细胞转染的目的在载体pcDNA3.1+中再克隆。
然后,创建黏结蛋白聚糖-1的单克隆抗体的生产细胞。本发明人已经进行了原始决定以创建抗体的生产者,其不仅衍生自杂交瘤1和2,而且由计算的重和轻链的组合创建。
感受态哺乳动物细胞(CHO)的转染通过两种创建的质粒DNA进行,每种质粒DNA分别携带具有分泌序列的被密码子优化以便在哺乳动物细胞中表达的编码抗体的重或轻链的多核苷酸。
通过磷酸钙沉淀方法进行用产生的质粒的哺乳动物细胞转染。
将哺乳动物细胞(CHO)以5×104个细胞/sm2的密度接种入12孔板(Costar,USA)。第二天,出于同步细胞分裂的目的更换培养基。三个小时后,将磷酸钙沉淀的质粒DNA加入细胞。为了制备沉淀物,将250μl溶液——其包含在250mM CaCl2中的50μg DNA——与250μl溶液(1.64%NaCl、1.13%HEPES рН7.12和0.04%Na2HPO4)缓慢地混合。在37℃、5%CO2下培育24小时之后,将培养基改变为类似培养基,其另外地包含2种抗生素:80μg/ml博来霉素(zeocin)和2μg/ml杀稻瘟霉素S用于选择克隆——包含两种转化的质粒,并且,因此,合成全长单克隆抗体。在含有活细胞的孔中进行选择持续20天;更换培养基(其中先前的培养基不被丢弃,而是被用于经由ELISA测量抗体分泌)。一天后,从孔底部分离细胞,并且分析转化基因的表达。在流式细胞仪EPICS XL Beckman Coulter(Beckman Coulter,USA)上进行转染效力的分析。
借助于标准固相ELISA分析获得的CHO细胞系的稳定转染瘤的培养基中单克隆抗体的水平。
作为7种克隆的结果,获得并累积稳定的CHO转染瘤用于抗体的冷冻保存和中试生产。基于SEQ ID NO:1和SEQ ID NO:7(在下文中-Mab2),和SEQ ID NO:5和SEQ ID NO:3(在下文中-Mab1),获得的合成黏结蛋白聚糖-1的抗体的CHO转染瘤的生产力为大约550μg/107个细胞/天。基于SEQ ID NO:1和SEQ ID NO:3(在下文中-Mab3),和SEQ ID NO:5和SEQ ID NO:7(在下文中-Mab4),创建的合成黏结蛋白聚糖-1的抗体的CHO转染瘤的生产力为大约650μg/107个细胞/天,基于SEQ ID NO:11和SEQ ID NO:3(在下文中-Mab7),和SEQ ID NO:11和SEQ ID NO:7(在下文中-Mab6),创建的合成黏结蛋白聚糖-1的抗体的CHO转染瘤的生产力大约650μg/107个细胞/天。基于SEQ ID NO:9和SEQ ID NO:7(在下文中-Mab5),创建的合成黏结蛋白聚糖-1的抗体的CHO转染瘤的生产力为大约700μg/107个细胞/天。
本发明的单克隆抗体可以使用其它哺乳动物细胞例如HEK293、COS获得。
1.6.培养生产黏结蛋白聚糖-1的单克隆抗体的细胞
使用生物反应器Bplus和高压灭菌的IMDM培养基进行生产细胞的培育,该培养基补充有45g DFBS(0.5%)和25.8g(100mmol)的七水硫酸锌(ZnSO4×7H2O)/9升培养基。操作模式设定为:温度37℃,pH 6.9-7.2,50%的空气饱和的氧浓度。在本模式达到之后,进行生物反应器的接种,在无菌条件下引入种子材料。培养进行3天。
在完成培育之后,通过具有1.2微米孔径的无菌囊式过滤器(capsule)《Sartopure》(《Sartorius》,Germany)以1L/min的速率过滤培养液。使用Viva Flow System 200(《Sartorius》,Germany)利用50kDa过滤器浓缩澄清液。进行浓缩直到获得200mL的总体积。
1.7.纯化获得的黏结蛋白聚糖-1的单克隆抗体
在两个阶段中使用无菌溶液实施色谱纯化。在第一阶段中,BioLogic DuoFlow Pathfinder(Bio-Rad)系统与自动馏分收集器BioFract和半制备型色谱柱YMC TriArt,250х4,6mm,C18吸附剂一起使用。在开始工作之前,以手动模式通过色谱泵以2ml/min的速率利用200ml缓冲液(1kg注射用水和1g三氟乙酸)平衡柱。
将200ml体积的制备材料以0.5mL/min的速度通过泵进入色谱仪。利用缓冲液(2kg乙腈、2g三氟乙酸)以0.5mL/分钟的速度进行洗脱。在260nm的最大吸光度下收集馏分。馏分的体积为大约500mL。
在260nm的最大吸光度下收集馏分。馏分的体积为大约500mL。
使用凝胶色谱柱BioSil SEC 125-5,300х7,8mm进行第二纯化步骤。利用0.02M PBS缓冲液初步地平衡柱。将获得的材料以0.5ml/min的速率通过色谱泵引入色谱仪。利用缓冲液(0.6M NaCl溶液)以0.1至0.6M的浓度梯度进行洗脱。收集在A280nm下吸光度不少于3.4吸光度单位的馏分。在小瓶中收集馏分。所得到的溶液的体积为大约1升,其中抗体的浓度为2-4mg/1ml。
获得的抗体的Kd通过ELISA使用Scatchard方程测量。
对于由氨基酸序列SEQ ID NO:5和SEQ ID NO:3表征的抗体(Mab1),Kd=8.5*10-9。对于由氨基酸序列SEQ ID NO:1和SEQ ID NO:7表征的抗体(Mab2),Kd=7.8*10-9。对于由氨基酸序列SEQ ID NO:1和SEQ ID NO:3表征的抗体(Mab3),Kd=7,0*10-9,SEQ ID NO:5和SEQ ID NO:7(Mab4)-6,7*10-9。对于由氨基酸序列SEQ ID NO:11和SEQ ID NO:3表征的抗体(Mab7),Kd=6,0*10-9,SEQ ID NO:11和SEQ ID NO:7(Mab6)-6,9*10-9。对于由氨基酸序列SEQ ID NO:9和SEQ ID NO:7表征的抗体(Mab5),Kd=5.0*10-9。
因而,创建的抗体具备对于有效抗原结合足够的亲和力。
实施例2.黏结蛋白聚糖-1的单克隆抗体的抗肿瘤效果的研究
在BALB/c裸小鼠中使用人肿瘤的异种移植模型进行生成抗体的抗肿瘤活性的研究。在每个肿瘤模型中,黏结蛋白聚糖-1的单克隆抗体的二-三种类型被研究。
小鼠
使用雌性无胸腺BALB/c裸小鼠进行研究。给动物任意进食NIH 31改进的和照射的实验室和水。使小鼠居住在20–22℃和40–60%湿度的12小时光周期中。
使用下式计算肿瘤体积:w2*l/2,其中w=以mm为单位的肿瘤的宽度并且l=长度。肿瘤重量在假设1mg等于1mm3的肿瘤体积的情况下进行评估。
治疗剂和其施用的方法
将研究中的抗体置于2.5mg/mL母液中并且在4℃下避光储存。给药溶液以0.2mL/动物的固定体积递送0.5mg/动物的剂量。将给药溶液在4℃下避光储存。
紫杉醇(Lot CP2N10007)购买为干燥粉末(Fort Worth,TX)。制备在50%乙醇:50%氢化蓖麻油EL中的紫杉醇母液(30mg/mL)并且在室温下避光储存。在给药的每一天,将紫杉醇母液的等分试样利用在水中的5%葡萄糖(D5W)稀释以得到在媒介中的3.0mg/mL紫杉醇给药溶液,该媒介由5%乙醇:5%氢化蓖麻油EL:90%D5W组成。给药溶液以10mL/kg的给药体积递送30mg/kg的剂量。
PBS(“媒介”)被用于给药媒介对照组。
每周两次腹腔内给药媒介和抗体持续四周。每隔一天一次静脉内递送紫杉醇持续总共五次剂量。组1接受媒介并且充当肿瘤移入和进展的基准组,以及肿瘤生长延迟分析(TGD)的对照。
研究结果的评估
当动物的肿瘤到达体积端点时处死每只动物。每只小鼠的到达端点时间(TTE)利用下式计算:(log10(端点体积)–b)/m,其中b是截距,m是通过对数变换肿瘤生长数据集的线性回归获得的线的斜率。数据集由超出研究端点体积的第一观察值和就在获得端点体积之前的三个连续观察值组成。没有到达端点的任何动物在研究结束时被处死并且分配等于研究的最后一天的TTE值。在其中对数变换计算的TTE在到达端点之前的那天之前或者超过到达肿瘤体积端点的那天的情况下,进行线性插值以近似TTE。被测定为已经死于治疗相关(TR)原因的任何动物被分配等于死亡那天的TTE值。死于非治疗相关(NTR)原因的任何动物从分析中被排除。
治疗结果根据肿瘤生长延迟(TGD)评估,其被限定为与对照组相比治疗组的中值TTE的增加,TGD=T–C,以天数表达,或者为对照组的中值TTE的百分比,%TGD=(Т-С)*100/С,其中T–治疗组的中值TTE,С–对照组的中值TTE。
毒性
频繁地观察小鼠的健康状况和任何不利的TR副作用的明显迹象。监测每种方案的个体BW减轻,并且处死其重量超过可接受BW减轻的极限的任何动物。如果组平均BW恢复,则在那个组中重新开始给药,但是以较低的剂量或较不频繁的给药安排。可接受的毒性被限定为在研究期间少于20%的组平均BW减轻,和在十个治疗的动物中不超过一个TR或10%死亡。导致更强毒性的任何给药方案被视为最大耐受剂量(MTD)。如果死亡可归因于治疗副作用,如通过临床征兆和/或验尸证明的,则其被归类为TR,或者如果由于在给药时期期间或在最后剂量的14天内的未知原因,则也可以被归类为TR。如果证明了死亡与肿瘤模型相关,而不是治疗相关的,则死亡被归类为NTR。
统计学和图形化分析
Windows的Prism 6.05(GraphPad)被用于统计学和图形化分析。基于TTE值通过Kaplan-Meier方法分析存活。秩和检验(Mantel-Cox)和Gehan-Breslow-Wilcoxon测试基于TTE值测定两个组的总存活经历(存活曲线)之间的区别的显著性。Kaplan-Meier图(plot)和统计学测试共享相同数据集,并且排除被记录为NTR死亡的任何动物。双尾统计学分析不被调节用于多重比较,并且在P=0.05下进行。
因为统计学测试是显著性的测试并且不提供给组之间的区别大小的估计,显著性的所有水平被描述为显著的或不显著的。
在相同组中出现两例TR死亡之后截断肿瘤生长曲线。随着研究过程的组平均BW改变用曲线图表示为从第1天的百分比改变±SEM。在组中超过一半的可评估小鼠退出研究之后,截断肿瘤生长和BW改变曲线。
2.1.使用A549细胞系研究黏结蛋白聚糖-1的人源化单克隆抗体(Mab4、Mab6)的效力
在研究的第1天时,小鼠为11周龄并且具有18.4至25.6g的BW范围。
异种移植开始于在Kaighn’s改良的Ham’s F12培养基中培养的A549人非小细胞肺癌细胞,该培养基包含10%胎牛血清、100单位/mL青霉素G、100μg/mL硫酸链霉素、2mM谷氨酰胺、1mM丙酮酸钠、和25μg/mL庆大霉素。在37℃下,在5%CO2和95%空气的气氛中,在湿润的保温箱中,在组织培养瓶中培养细胞。
用于移植的A549肿瘤细胞在对数生长期期间收获并且以5×107个细胞/mL的浓度在磷酸盐缓冲盐水(PBS)中的50%Matrigel基质(BD Biosciences)中重悬。在每只测试小鼠的右胁中皮下注射1×107个A549细胞(0.2mL细胞悬浮液),并且随着平均尺寸接近150至220mm3的目标范围,监测肿瘤生长。使用卡尺在二维中测量肿瘤,并且计算体积。
在肿瘤细胞移植后24天,在研究的第1天时,将动物分为4个组(n=10/组),其中个体肿瘤体积为126至221mm3,并且组平均肿瘤体积为185-186mm3。在研究的首个45天内和另外地在第54天,利用卡尺每周两次测量肿瘤。
研究端点为800mm3的肿瘤体积或在第54天,以先到者为准。
研究的结果在图1-3中示出。
2.2.使用Colo205细胞系研究黏结蛋白聚糖-1的单克隆抗体(Mab2、Mab3)的效力
在研究的第1天时,小鼠为9周龄,并且具有17.8至23.8g的BW范围。
异种移植开始于在RPMI 1640培养基中培养的人结肠直肠腺癌细胞(Colo 205),该培养基包含10%胎牛血清、2mM谷氨酰胺、1mM丙酮酸钠、10mM HEPES、0.075%碳酸氢钠、100单位/mL青霉素G、100μg/mL硫酸链霉素和25μg/mL庆大霉素。在37℃下,在5%CO2和95%空气的气氛中,在湿润的保温箱中,在组织培养瓶中培养细胞。
用于移植的Colo 205肿瘤细胞在对数生长期期间收获并且以5×106个细胞/mL的浓度在磷酸盐缓冲盐水(PBS)中的50%Matrigel基质(BD Biosciences)中重悬。在每只测试小鼠的右胁中皮下注射1×106个Colo 205细胞(0.2mL细胞悬浮液),并且随着平均尺寸接近100至150mm3的目标范围,监测肿瘤生长。使用卡尺在二维中测量肿瘤,并且计算体积。
在肿瘤细胞移植后的10天中,在研究的第1天时,将动物分为4个组(n=10/组),其中个体肿瘤体积为88至162mm3,并且组平均肿瘤体积为123-127mm3。在研究的首个60天内和另外地在第65和75天,利用卡尺每周两次测量肿瘤。
研究端点为1500mm3的肿瘤体积或在第75天,以先到者为准。
研究的结果在图4-6中示出。
在紫杉醇组中,在研究的第11天时揭示TR死亡。
2.3.使用PC3细胞系研究黏结蛋白聚糖-1的人源化单克隆抗体(Mab1、Mab5)的效力
在研究的第1天时,小鼠为11周龄,并且具有19.1至26.4g的BW范围。
异种移植开始于雄激素非依赖性PC3肿瘤细胞系,其衍生自转移至骨骼的人前列腺癌,并且展示低分化腺癌的形态学。用于本研究的肿瘤通过在雌性裸小鼠中连续移入来维持。为了开始肿瘤生长,将1mm3片段皮下植入每只测试小鼠的右胁中。随着它们的平均体积接近期望的100–150mm3范围,在二维中用卡尺测量肿瘤以监测肿瘤生长。
在肿瘤片段移植后26天,在研究的第1天时,将小鼠分为4个组(n=10/组),其中个体肿瘤体积为63–196mm3,并且组平均肿瘤体积为119–120mm3。在研究的首个45天内和另外地在第53天,利用卡尺每周两次测量肿瘤。
研究端点为1500mm3的肿瘤体积或在第53天,以先到者为准。
研究的结果在图7-9中示出。
与对照组相比,在所有调查的参数方面,分析的抗体(Mab4和Mab6、Mab2和Mab3、Mab1和Mab5)已经证明了统计学上显著的效力,其比得上紫杉醇的效力,并且还没有副作用,这也意味着这些药剂的安全性。Mab7分析已经揭示了与Mab6的那些比率类似的比率。
特异于黏结蛋白聚糖-1的人源化单克隆抗体
序列表
<110>
I.V.杜克浩林夫,A.I.奥尔洛夫,M.B.巴拉宗斯克依
<120>
特异于黏结蛋白聚糖-1的人源化单克隆抗体
<130>
<150> <151><160>
RU 2015129656
2015-07-20 12
<210>
1
<211>
449
<212>
PRT
<213> <220><223>
人工序列
衍生自杂交瘤2的CD138的嵌合IgG4 Mab的重链
<400>
1
Gln Val Gln Leu Gln Gln Ser Gly Ser Glu Leu Met Met Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Thr Gly Tyr Thr Phe Ser Asn Tyr
20 25 30
Trp Ile Glu Trp Val Lys Gln Arg Pro Gly His Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Leu Pro Gly Thr Gly Arg Thr Ile Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Phe Thr Ala Asp Ile Ser Ser Asn Thr Val Gln
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Asp Tyr Tyr Gly Asn Phe Tyr Tyr Ala Met Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr
210 215 220
Gly Pro Pro Cys Pro Ser Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp
260 265 270
Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
Lys
<210>
2
<211>
1431
<212>
DNA
<213><220><223>
人工序列
编码SEQ ID NO: 1的核苷酸序列
<400>
2
atgggcgtgc acgagtgccc cgcctggctg tggctgctcc tcagtctgct gagcctgccc 60
ctgggcctgc ccgtgctggg ccaggtgcag ctgcagcaga gcggcagcga gctgatgatg 120
cccggcgcca gcgtgaagat cagctgcaag gccaccggct acaccttcag caactactgg 180
atcgagtggg tgaagcagcg ccccggccac ggcctggagt ggatcggcga gatcctgccc 240
ggcaccggcc gcaccatcta caacgagaag ttcaagggca aggccacctt caccgccgac 300
atcagcagca acaccgtgca gatgcagctg agcagcctga ccagcgagga cagcgccgtg 360
tactactgcg cccgccgcga ctactacggc aacttctact acgccatgga ctactggggc 420
cagggcacca gcgtgaccgt gagcagcgcc agcaccaagg gccccagcgt gttccccctg 480
gccccctgca gccgcagcac cagcgagagc accgccgccc tgggctgcct ggtgaaggac 540
tacttccccg agcccgtgac cgtgagctgg aacagcggcg ccctgaccag cggcgtgcac 600
accttccccg ccgtgctgca gagcagcggc ctgtacagcc tgagcagcgt ggtgaccgtg 660
cccagcagca gcctgggcac caagacctac acctgcaacg tggaccacaa gcccagcaac 720
accaaggtgg acaagcgcgt ggagagcaag tacggccccc cctgccccag ctgccccgcc 780
cccgagttcc tgggcggccc cagcgtgttc ctgttccccc ccaagcccaa ggacaccctg 840
atgatcagcc gcacccctga agtgacctgc gtggtggtgg acgtgagcca ggaggacccc 900
gaggtgcagt tcaactggta cgtggacggc gtggaggtgc acaacgccaa gaccaagccc 960
cgcgaggagc agttcaacag cacctaccgc gtggtgagcg tgctgaccgt gctgcaccag 1020
gactggctga acggcaagga gtacaagtgc aaggtgagca acaagggcct gcccagcagc 1080
atcgagaaga ccatcagcaa ggccaagggc cagccccgcg agccccaggt gtacaccctg 1140
ccccccagcc aggaggagat gaccaagaac caggtgagcc tgacctgcct ggtgaagggc 1200
ttctacccca gcgacatcgc cgtggagtgg gagagcaacg gccagcccga gaacaactac 1260
aagaccaccc cccccgtgct ggacagcgac ggcagcttct tcctgtacag ccgcctgacc 1320
gtggacaaga gccgctggca ggagggcaac gtgttcagct gcagcgtgat gcacgaggcc 1380
ctgcacaacc actacaccca gaagagcctc agtctgagcc tgggcaagta a 1431
<210>
3
<211>
214
<212>
PRT
<213>
人工序列
<220><223><400>
衍生自杂交瘤1的CD138的嵌合Mab的轻链
3
Asp Ile Gln Met Thr Gln Ser Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Asn Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Asp Gly Thr Val Glu Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Thr Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Leu Glu Pro
65 70 75 80
Glu Asp Ile Gly Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210>
4
<211>
726
<212>
DNA
<213>
人工序列
<220><223><400>
编码SEQ ID NO: 3的核苷酸序列
4
atgggcgtgc acgagtgccc cgcctggctg tggctgctcc tcagtctgct gagcctgccc 60
ctgggcctgc ccgtgctggg cgacatccag atgacccaga gcaccagcag cctgagcgca 120
agtctgggcg accgcgtgac catcagctgc agcgccagcc agggcatcaa caactacctg 180
aactggtacc agcagaagcc cgacggcacc gtggagctgc tgatctacta caccagcacc 240
ctgcagagcg gcgtgcccag ccgcttcagt ggcagtggaa gcggcaccga ctacagcctg 300
accatcagca acctggagcc cgaggacatc ggcacctact actgccagca gtacagcaag 360
ctgccccgca ccttcggcgg cggcaccaag ctggagatca agcgcaccgt ggccgccccc 420
agcgtgttca tcttcccccc cagcgacgag cagctgaaga gcggcaccgc cagcgtggtg 480
tgcctgctga acaacttcta cccccgcgag gccaaggtgc agtggaaggt ggacaacgcc 540
ctgcagagcg gcaacagcca ggagagcgtg accgagcagg acagcaagga cagcacctac 600
agcctcagta gcaccctgac cctgagcaag gccgactacg agaagcacaa ggtgtacgcc 660
tgcgaggtga cccaccaggg cctgagcagc cccgtgacca agagcttcaa ccgcggcgag 720
tgctaa 726
<210>
5
<211>
449
<212>
PRT
<213>
人工序列
<220><223>
<400>
衍生自杂交瘤1的CD138的人源化IgG4 Mab的重链
5
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Ser Asn Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Leu Pro Gly Thr Gly Arg Thr Ser Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Asp Tyr Tyr Gly Asn Phe Tyr Tyr Ala Met Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr
210 215 220
Gly Pro Pro Cys Pro Ser Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp
260 265 270
Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
Lys
<210>
6
<211>
1431
<212>
DNA
<213>
人工序列
<220><223><400>
编码SEQ ID NO: 5的核苷酸序列
6
atgggcgtgc acgagtgccc cgcctggctg tggctgctcc tcagtctgct gagcctgccc 60
ctgggcctgc ccgtgctggg ccaggtgcag ctggtgcaga gcggcgccga ggtgaagaag 120
cccggcgcca gcgtgaaggt gagctgcaag gccagcggct acaccttcag caactactgg 180
atgcactggg tgcgccaggc ccccggccag ggcctggagt ggatgggcat catcctgccc 240
ggcaccggcc gcaccagcta cgcccagaag ttccagggcc gcgtgaccat gacccgcgac 300
acaagtacta gcaccgtgta catggagctg agcagcctgc gcagcgagga caccgccgtg 360
tactactgcg cccgccgcga ctactacggc aacttctact acgccatgga ctactgggga 420
caaggcacca gcgtgaccgt gagcagcgcc agcaccaagg gccccagcgt gttccccctg 480
gccccctgca gccgcagcac cagcgagagc accgccgccc tgggctgcct ggtgaaggac 540
tacttccccg agcccgtgac cgtgagctgg aacagcggcg ccctgaccag cggcgtgcac 600
accttccccg ccgtgctgca gagcagcggc ctgtacagcc tgagcagcgt ggtgaccgtg 660
cccagcagca gcctgggcac caagacctac acctgcaacg tggaccacaa gcccagcaac 720
accaaggtgg acaagcgcgt ggagagcaag tacggccccc cctgccccag ctgccccgcc 780
cccgagttcc tgggcggccc cagcgtgttc ctgttccccc ccaagcccaa ggacaccctg 840
atgatcagcc gcacccctga agtgacctgc gtggtggtgg acgtgagcca ggaggacccc 900
gaggtgcaat ttaactggta cgtggacggc gtggaggtgc acaacgccaa gaccaaacca 960
cgtgaggagc agttcaacag cacctaccgc gtggtgagcg tgctgaccgt gctgcaccag 1020
gactggctga acggcaagga gtacaagtgc aaggtgagca acaagggcct gcccagcagc 1080
atcgagaaga ccatcagcaa ggccaagggc cagccccgcg agccccaggt gtacaccctg 1140
ccccccagcc aggaggagat gaccaagaac caggtgagcc tgacctgcct ggtgaagggc 1200
ttctacccca gcgacatcgc cgtggagtgg gagagcaacg gccagcccga gaacaactac 1260
aagaccaccc cccccgtgct ggacagcgac ggcagcttct tcctgtacag ccgcctgacc 1320
gtggacaaga gccgctggca ggagggcaac gtgttcagct gcagcgtgat gcacgaggcc 1380
ctgcacaacc actacaccca gaagagcctt agtctgagcc tgggcaagta a 1431
<210>
7
<211>
214
<212>
PRT
<213>
人工序列
<220><223><400>
衍生自杂交瘤2的CD138的人源化Mab的轻链
7
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Asn Asn Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Val Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Thr Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210>
8
<211>
726
<212>
DNA
<213>
人工序列
<220><223><400>
编码SEQ ID NO: 7的核苷酸序列
8
atgggcgtgc acgagtgccc cgcctggctg tggctgctcc tcagtctgct gagcctgccc 60
ctgggcctgc ccgtgctggg cgacatccag atgacccaga gccccagtag tctgagcgct 120
agtgtcggcg accgcgtgac catcacctgc cgcgccagcc agggcatcaa caactacctg 180
gcctggtacc agcagaagcc cggcaaggtg cccaagctgc tgatctacta caccagcacc 240
ctgcagagcg gcgtgcccag ccgcttcagt ggaagcggaa gcggtactga cttcaccctg 300
accatcagca gcctgcagcc cgaggacgtg gccacctact actgccagca gtacagcaag 360
ctgccccgca ccttcggcgg cggcaccaag ctggagatca agcgcaccgt ggccgccccc 420
agcgtgttca tcttcccccc cagcgacgag cagctgaaga gcggcaccgc cagcgtggtg 480
tgcctgctga acaacttcta cccccgcgag gccaaggtgc agtggaaggt ggacaacgcc 540
ctgcagagcg gcaacagcca ggagagcgtg accgagcagg acagcaagga cagcacctac 600
agcctcagta gcaccctgac cctgagcaag gccgactacg agaagcacaa ggtgtacgcc 660
tgcgaggtga cccaccaggg cctgagcagc cccgtgacca agagcttcaa ccgcggcgag 720
tgctaa 726
<210>
9
<211>
449
<212>
PRT
<213>
人工序列
<220><223>
<400>
衍生自杂交瘤1的CD138的人源化IgG4-IgG3 Mab的重链
9
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Ser Asn Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ile Ile Leu Pro Gly Thr Gly Arg Thr Ser Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Asp Tyr Tyr Gly Asn Phe Tyr Tyr Ala Met Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr
210 215 220
Gly Pro Pro Cys Pro Ser Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp
260 265 270
Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
Lys
<210>
10
<211>
1431
<212>
DNA
<213>
人工序列
<220><223><400>
编码SEQ ID NO: 9的核苷酸序列
10
atgggcgtgc acgagtgccc cgcctggctg tggctgctcc tcagtctgct gagcctgccc 60
ctgggcctgc ccgtgctggg ccaggtgcag ctggtgcaga gcggcgccga ggtgaagaag 120
cccggcgcca gcgtgaaggt gagctgcaag gccagcggct acaccttcag caactactgg 180
atgcactggg tgcgccaggc ccccggccag ggcctggagt ggatgggcat catcctgccc 240
ggcaccggcc gcaccagcta cgcccagaag ttccagggcc gcgtgaccat gacccgcgac 300
acaagtacta gcaccgtgta catggagctg agcagcctgc gcagcgagga caccgccgtg 360
tactactgcg cccgccgcga ctactacggc aacttctact acgccatgga ctactgggga 420
caaggcacca gcgtgaccgt gagcagcgcc agcaccaagg gccccagcgt gttccccctg 480
gccccctgca gccgcagcac cagcgagagc accgccgccc tgggctgcct ggtgaaggac 540
tacttccccg agcccgtgac cgtgagctgg aacagcggcg ccctgaccag cggcgtgcac 600
accttccccg ccgtgctgca gagcagcggc ctgtacagcc tgagcagcgt ggtgaccgtg 660
cccagcagca gcctgggcac caagacctac acctgcaacg tggaccacaa gcccagcaac 720
accaaggtgg acaagcgcgt ggagagcaag tacggccccc cctgccccag ctgccccgcc 780
cccgagctgc tgggcggccc cagcgtgttc ctgttccccc ccaagcccaa ggacaccctg 840
atgatcagcc gcacccctga agtgacctgc gtggtggtgg acgtgagcca ggaggacccc 900
gaggtgcagt tcaactggta cgtggacggc gtggaggtgc acaacgccaa gaccaagccc 960
cgcgaggagc agtacaacag cacctaccgc gtggtgagcg tgctgaccgt gctgcaccag 1020
gactggctga acggcaagga gtacaagtgc aaggtgagca acaaggccct gcccgcacct 1080
atcgagaaga ccatcagcaa ggccaagggc cagccccgcg agccccaggt gtacaccctg 1140
ccccccagcc aggaggagat gaccaagaac caggtgagcc tgacctgcct ggtgaagggc 1200
ttctacccca gcgacatcgc cgtggagtgg gagagcaacg gccagcccga gaacaactac 1260
aagaccaccc cccccgtgct ggacagcgac ggcagcttct tcctgtacag ccgcctgacc 1320
gtggacaaga gccgctggca ggagggcaac gtgttcagct gcagcgtgat gcacgaggcc 1380
ctgcacaacc actacaccca gaagagcctc agtctgagcc tgggcaagta a 1431
<210>
11
<211>
449
<212>
PRT
<213>
人工序列
<220><223>
<400>
衍生自杂交瘤2的CD138的嵌合IgG4-IgG3 Mab的重链
11
Gln Val Gln Leu Gln Gln Ser Gly Ser Glu Leu Met Met Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Thr Gly Tyr Thr Phe Ser Asn Tyr
20 25 30
Trp Ile Glu Trp Val Lys Gln Arg Pro Gly His Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Leu Pro Gly Thr Gly Arg Thr Ile Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Phe Thr Ala Asp Ile Ser Ser Asn Thr Val Gln
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Asp Tyr Tyr Gly Asn Phe Tyr Tyr Ala Met Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Ser Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro
115 120 125
Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr
130 135 140
Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr
145 150 155 160
Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro
165 170 175
Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr
180 185 190
Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp
195 200 205
His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr
210 215 220
Gly Pro Pro Cys Pro Ser Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
225 230 235 240
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
245 250 255
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp
260 265 270
Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
275 280 285
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
290 295 300
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
305 310 315 320
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
325 330 335
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
340 345 350
Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr
355 360 365
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
370 375 380
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
385 390 395 400
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys
405 410 415
Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu
420 425 430
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440 445
Lys
<210>
12
<211>
1431
<212>
DNA
<213>
人工序列
<220><223><400>
编码SEQ ID NO: 11的核苷酸序列
12
atgggcgtgc acgagtgccc cgcctggctg tggctgctcc tcagtctgct gagcctgccc 60
ctgggcctgc ccgtgctggg ccaggtgcag ctgcagcaga gcggcagcga gctgatgatg 120
cccggcgcca gcgtgaagat cagctgcaag gccaccggct acaccttcag caactactgg 180
atcgagtggg tgaagcagcg ccccggccac ggcctggagt ggatcggcga gatcctgccc 240
ggcaccggcc gcaccatcta caacgagaag ttcaagggca aggccacctt caccgccgac 300
atcagcagca acaccgtgca gatgcagctg agcagcctga ccagcgagga cagcgccgtg 360
tactactgcg cccgccgcga ctactacggc aacttctact acgccatgga ctactggggc 420
cagggcacca gcgtgaccgt gagcagcgcc agcaccaagg gccccagcgt gttccccctg 480
gccccctgca gccgcagcac cagcgagagc accgccgccc tgggctgcct ggtgaaggac 540
tacttccccg agcccgtgac cgtgagctgg aacagcggcg ccctgaccag cggcgtgcac 600
accttccccg ccgtgctgca gagcagcggc ctgtacagcc tgagcagcgt ggtgaccgtg 660
cccagcagca gcctgggcac caagacctac acctgcaacg tggaccacaa gcccagcaac 720
accaaggtgg acaagcgcgt ggagagcaag tacggccccc cctgccccag ctgccccgcc 780
cccgagctgc tgggcggccc cagcgtgttc ctgttccccc ccaagcccaa ggacaccctg 840
atgatcagcc gcacccctga agtgacctgc gtggtggtgg acgtgagcca ggaggacccc 900
gaggtgcagt tcaactggta cgtggacggc gtggaggtgc acaacgccaa gaccaagccc 960
cgcgaggagc agtacaacag cacctaccgc gtggtgagcg tgctgaccgt gctgcaccag 1020
gactggctga acggcaagga gtacaagtgc aaggtgagca acaaggccct gcccgcacct 1080
atcgagaaga ccatcagcaa ggccaagggc cagccccgcg agccccaggt gtacaccctg 1140
ccccccagcc aggaggagat gaccaagaac caggtgagcc tgacctgcct ggtgaagggc 1200
ttctacccca gcgacatcgc cgtggagtgg gagagcaacg gccagcccga gaacaactac 1260
aagaccaccc cccccgtgct ggacagcgac ggcagcttct tcctgtacag ccgcctgacc 1320
gtggacaaga gccgctggca ggagggcaac gtgttcagct gcagcgtgat gcacgaggcc 1380
ctgcacaacc actacaccca gaagagcctc agtctgagcc tgggcaagta a 1431
2
- 还没有人留言评论。精彩留言会获得点赞!