分子标志物在胃癌诊治中的应用的制作方法
本发明属于生物医药领域,涉及分子标志物在胃癌诊治中的应用,具体的所述分子标志物为ENSG00000228742。
背景技术:
胃癌是消化道最常见的恶性肿瘤之一,尽管近年来在世界范围内胃癌的发病率和死亡率有所下降,但仍分别居恶性肿瘤的第2位和第3位,胃癌的诊断与治疗仍是肿瘤学家共同关注的研究热点。中国是胃癌的高发国家,我国胃癌的发病率和死亡率长期位居世界前列。胃癌可分为早期胃癌(early gastric cancer,EGC)和进展期胃癌(advanced gastric cancer,AGC),其中早期胃癌指局限于粘膜层和粘膜下层的胃癌。早期胃癌预后良好,手术率低于5%~10%,5年生存率达90%以上,而进展期胃癌患者5年生存率尚不足20%,因此胃癌的早期诊断、早期治疗对改善患者预后、降低死亡率具有重要作用。
目前,国家肿瘤性疾病的控制策略已经从被动的治疗转向主动的预防和早期识别,对于胃癌而言,重点在于癌前病变的发现和高危人群的识别,同时提高胃镜对早期胃癌及癌前病变的检出率。而我国胃癌的早诊率与先进国家存在较大差距,总体胃癌早诊率低于10%,绝大多数胃癌患者确诊时已处于进展期,治疗花费巨大,预后不佳,为国家卫生事业带来较大负担,函需得到改善。
胃癌早诊的难点在于早期胃癌患者多不具有特异性临床症状与体征,可能仅表现为非特异性上腹不适,而常用的CEA,CA19-9等肿瘤标志物对早期胃癌诊断的敏感性和特异性均较低。因此寻找新的生物学靶标用于胃癌的癌变监测和干预,成为胃癌防治亟待解决的问题。
lncRNA是一类内源性、片段长度大于200个核昔酸、缺少完整特异的开放阅读框而无编码蛋白质能力的RNA分子,多数由RNA聚合酶II转录并经可变剪切生成。lncRNA与肿瘤关系密切,在肝癌、乳腺癌、白血病和结肠癌等多种肿瘤中发现有lncRNA的表达和调节异常。HEIR,HOTAIR,H19和ANRIL等多种lncRNA具有原癌基因或者促进肿瘤转移的功能,而MEG3和PTCSC3等lncRNA则具有抑癌基因功能,上述事实表明lncRNA在肿瘤发生、发展过程中均具有重要作用。寻找与胃癌发生发展相关的lncRNA,对于胃癌的防治及机制研究都具有重要的意义。
技术实现要素:
为了弥补现有技术的不足,本发明的目的在于提供一种可用于胃癌诊治的分子标志物,本发明所提供的分子标志物为一种lncRNA,该标志物在胃癌患者中表达上调,可作为潜在的分子靶标用于胃癌的诊断和治疗。
为了实现上述目的,本发明采用如下技术方案:
本发明提供了ENSG00000228742基因的用途,用于制备预防或治疗胃癌的药物组合物。
进一步,所述药物组合物包括ENSG00000228742的下调剂。其中,所述的下调剂能在基因水平上下调ENSG00000228742基因的表达;所述ENSG00000228742的下调剂选自:以ENSG0000018480基因或其转录本为靶序列、且能够抑制ENSG0000018480基因表达或基因转录的干扰分子,包括:shRNA(小发夹RNA)、小干扰RNA(siRNA)、dsRNA、微小RNA、反义核酸,或能表达或形成所述的shRNA、小干扰RNA、微小RNA、反义核酸的构建物。
进一步,所述的下调剂选自下组序列的siRNA:SEQ ID NO.8、SEQ ID NO.9。
本发明提供了一种用于预防或治疗胃癌的ENSG00000228742的下调剂,所述下调剂为siRNA。
本发明提供了一种用于预防或治疗胃癌的药物组合物,所述药物组合物含有:
上面所述的ENSG00000228742的下调剂;和
药学上可接受的载体。
本发明提供了一种ENSG00000228742基因的用途,用于筛选预防或治疗胃癌的潜在物质。
本发明提供了一种筛选预防或治疗胃癌的潜在物质的方法,所述方法包括:
用候选物质处理表达或含有ENSG00000228742基因的体系;和
检测所述体系中ENSG00000228742基因的表达;
其中,若所述候选物质可降低ENSG00000228742基因的表达或活性(优选显著降低,如低20%以上,较佳的低50%以上,更佳的低80%以上),则表明该候选物质是预防或治疗胃癌的潜在物质。
进一步,所述的体系包括(但不限于):细胞体系、亚细胞体系、溶液体系、组织体系、器官体系或动物体系。
本发明提供了一种ENSG00000228742基因的用途,用于制备诊断胃癌的产品。
进一步,所述产品包括芯片、制剂、或试剂盒。
进一步,所述芯片包括特异性识别ENSG00000228742的探针;所述试剂盒包括特异性扩增ENSG00000228742的引物或特异性识别ENSG00000228742的探针或芯片。
其中,所述芯片可用于检测包括ENSG00000228742基因在内的多个基因(例如,与胃癌相关的多个基因)的表达水平;所述试剂盒可用于检测包括ENSG00000228742基因在内的多个基因(例如,与胃癌相关的多个基因)的表达水平。
本发明的优点和有益效果:
本发明首次发现了ENSG00000228742的差异表达与胃癌的发生发展相关,通过检测受试者样本中ENSG00000228742的表达,可以判断受试者是否患有胃癌,从而指导临床医师给受试者提供预防方案或者治疗方案。
本发明发现了一种胃癌的新的分子标志物-ENSG00000228742,利用分子标志物来预防或治疗胃癌,更为敏感、特异。
附图说明
图1是利用QPCR检测ENSG00000228742基因在胃癌组织中的表达情况图;
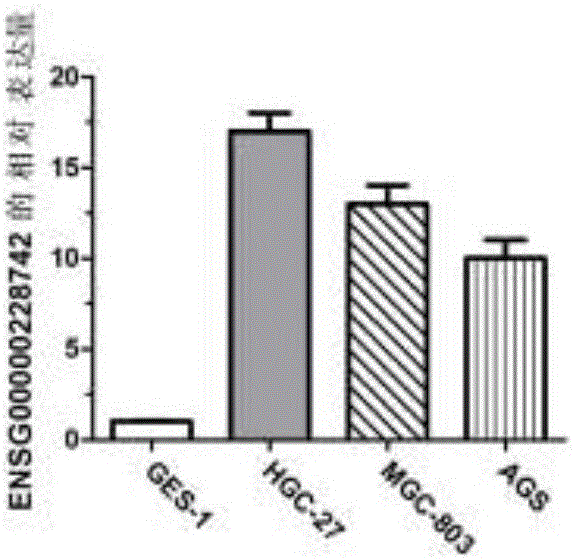
图2是利用QPCR检测ENSG00000228742在胃癌细胞中的表达情况图;
图3是利用QPCR检测ENSG00000228742基因沉默对胃癌细胞中该基因表达水平的影响图;
图4是用MTS法检测ENSG00000228742基因对胃癌细胞增殖的影响图。
具体的实施方式
本发明经过广泛而深入的研究,通过lncRNA芯片筛选得到与胃癌相关的lncRNA,首次发现了胃癌中ENSG00000228742呈现特异性高表达。实验证明,通过特异降低ENSG00000228742的表达水平,能够有效地抑制胃癌细胞的增殖,提示检测ENSG00000228742基因的表达水平可成为胃癌早期诊断的辅助诊断指标之一,干扰ENSG00000228742基因表达可成为胃癌治疗的新途径。
分子标志物
术语“分子标志物”是其在组织或细胞中的表达水平与正常或健康细胞或组织的表达水平相比发生改变的任何基因。
本领域技术人员将认识到,本发明的实用性并不局限于对本发明的标志物基因的任何特定变体的基因表达进行定量。作为非限制性的实例,标志物基因可具有SEQ ID NO.1指定的核苷酸序列。在一些实施方案中,其具有与所列的序列至少85%相同或相似的cDNA序列诸如上述所列的序列至少 90%、91%、92%、93%、94%、95%、96%、97%、98%或至少 99%相同或相似的cDNA序列。
本发明可以利用本领域内已知的任何方法测定基因表达。本领域技术人员应当理解,测定基因表达的手段不是本发明的重要方面。可以在转录水平上检测生物标志物的表达水平。
在一些实施方案中,在转录水平上检测生物标志物的表达水平。利用核酸杂交技术进行具体DNA和RNA测量的多种方法是本领域技术人员已知的。一些方法涉及电泳分离(例如,用于检测DNA的Southern印迹和用于检测RNA的Northern印迹),但是也可以在不利用电泳分离的情况下进行DNA和RNA的测量(例如,通过斑点印迹)。基因组DNA(例如,来自人)的Southern印迹可用于筛选限制性片段长度多态性(RFLP),以检测影响本发明多肽的遗传病症的存在。可以检测所有形式的RNA。
药物组合物
基于本发明人的发现,本发明提供了一种ENSG00000228742基因的用途,用于制备预防或治疗胃癌的药物组合物。其中所述药物组合物包括有效量的ENSG00000228742的下调剂,和/或与所述促进剂配伍的其他药类以及药学上可接受的载体和/或辅料。
如本发明所用,ENSG00000228742的下调剂包括(但不限于)抑制剂、阻断剂、核酸抑制物等,只要能在基因水平上下调ENSG00000228742基因的表达水平即可。
作为本发明的一种优选方式,所述ENSG00000228742的下调剂是一种ENSG00000228742特异性的小干扰RNA。所述的“小干扰RNA”是指一种短片段双链RNA分子,能够以同源互补序列的mRNA为靶目标降解特定的mRNA,这个过程就是RNA干扰(RNA interference)过程。小干扰RNA可以制备成双链核酸的形式,它含有一个正义链和一个反义链,这两条链仅在杂交的条件下形成双链。一个双链RNA复合物可以由相互分离的正义链和反义链来制备。因此,举例来讲,互补的正义链和反义链是化学合成的,其后可通过退火杂交,产生合成的双链RNA复合物。
在筛选有效的siRNA序列时,本发明人通过大量的比对分析,从而找出最佳的有效片段。本发明人设计合成了多种siRNA序列,并将它们分别通过转染试剂转染胃癌细胞系进行验证,结果检测出2种干扰效果较好的干扰分子,它们分别具有SEQ ID NO.8、SEQ IDNO.9所示的序列,进一步地在细胞水平实验,结果证明对于细胞实验而言抑制效率非常高。
本发明的核酸抑制物如siRNA可以化学合成,也可以通过一个重组核酸结构里的表达盒转录成单链RNA之后进行制备。siRNA等核酸抑制物,可通过采用适当的转染试剂被输送到细胞内,或还可采用本领域已知的多种技术被输送到细胞内。
作为本发明的一种可选方式,所述的ENSG00000228742的下调剂也可以是一种“小发夹RNA”,其是能够形成发夹结构的非编码小RNA分子,小发夹RNA能够通过RNA干扰途径来抑制基因的表达。如上述,shRNA可以由编码需要的转录物的双链DNA模板来表达。编码需要的转录物的双链DNA模板被插进一个载体,例如质粒或病毒载体,然后在体外或体内连接到一个启动子进行表达。shRNA在真核细胞内DICER酶的作用下,可被切割成小干扰RNA分子,从而进入RNAi途径。“shRNA表达载体”是指一些本领域常规用于构建shRNA结构的质粒,通常该质粒上存在“间隔序列”以及位于“间隔序列”两边的多克隆位点或供替换序列,从而人们可以将shRNA(或类似物)相应的DNA序列通过正向和反向的方式插入多克隆位点或替换其上的供替换序列,该DNA序列转录后的RNA可形成shRNA(Short Hairpin)结构。所述的“shRNA表达载体”目前已经完全可以通过商购的途径购买获得,例如一些病毒载体。
基因表达载体可以是本领域已知的各种载体,如市售的载体、包括质粒、粘粒、噬菌体、病毒等。表达载体向宿主细胞中的导入可以使用电穿孔法、磷酸钙法、脂质体法、DEAE葡聚糖法、显微注射、病毒感染、脂质体转染、与细胞膜透过性肽的结合等周知的方法。
本领域的技术人员可以利用熟知的方法于构建本发明所需的表达载体。这些方法包括体外重组DNA技术、DNA合成技术、体内重组技术等。所述的表达载体优选地包含一个或多个选择性标记基因,以提供用于选择转化的宿主细胞的表型性状,如卡拉霉素、庆大霉素、潮霉素、氨苄青霉素抗性。
本发明中,术语“宿主细胞”包括原核细胞和真核细胞。常用的原核宿主细胞的例子包括大肠杆菌、枯草杆菌等。常用的真核宿主细胞包括酵母细胞、昆虫细胞和哺乳动物细胞。较佳地,该宿主细胞是真核细胞,如CHO细胞、COS细胞等。
术语“有效量”是指可对人和/或动物产生功能或活性的且可被人和/或动物所接受的量。“药学上可接受的载体”指用于治疗剂给药的载体,包括各种赋形剂和稀释剂。该术语指这样一些药剂载体:它们本身并不是必要的活性成分,且施用后没有过分的毒性。合适的载体是本领域普通技术人员所熟知的。在组合物中药学上可接受的载体可含有液体,如水、盐水、缓冲液。另外,这些载体中还可能存在辅助性的物质,如填充剂、润滑剂、助流剂、润湿剂或乳化剂、pH缓冲物质等。所述的载体中还可以含有细胞转染试剂。
本发明中,可以采用本领域熟知的多种方法来将所述的促进剂或其转录基因、或其药物组合物给药于哺乳动物。包括但不限于:皮下注射、肌肉注射、经皮给予、局部给予、植入、缓释给予等;优选的,所述给药方式是非肠道给予的。
优选的,可采用基因治疗的手段进行。比如,可直接将ENSG00000228742的下调剂通过诸如注射等方法给药于受试者;或者,可通过一定的途径将携带ENSG00000228742下调剂的表达单位(比如表达载体或病毒等,或siRNA或shRNA)递送到靶点上,具体情况需视所述的下调剂的类型而定,这些均是本领域技术人员所熟知的。
本发明所述的ENSG00000228742的下调剂的有效量可随给药的模式和待治疗的疾病的严重程度等而变化。优选的有效量的选择可以由本领域普通技术人员根据各种因素来确定(例如通过临床试验)。所述的因素包括但不限于:所述的ENSG00000228742的下调剂的药代动力学参数例如生物利用率、代谢、半衰期等;患者所要治疗的疾病的严重程度、患者的体重、患者的免疫状况、给药的途径等。例如,由治疗状况的迫切要求,可每天给予若干次分开的剂量,或将剂量按比例地减少。
药物筛选
本发明提供了ENSG00000228742在筛选人胃癌诊治药物中的用途。即:用候选物质处理表达ENSG00000228742的体系;和检测所述体系中ENSG00000228742的表达或活性;若所述候选物质可下调ENSG00000228742的表达或活性,则表明该候选物质是抑制胃癌的潜在物质。所述的表达ENSG00000228742的体系例如可以是细胞(或细胞培养物)体系,所述的细胞可以是内源性表达ENSG00000228742的细胞;或可以是重组表达ENSG00000228742的细胞。所述的表达ENSG00000228742的体系还可以是亚细胞体系、溶液体系、组织体系、器官体系或动物体系(如动物模型,优选非人哺乳动物的动物模型,如鼠、兔、羊、猴等))等。
检测测试组的体系中ENSG00000228742基因的表达,并与对照组比较,其中所述的对照组是不添加所述候选物质的表达或含有ENSG00000228742基因的体系;如果测试组中ENSG00000228742基因的表达在统计学上低于对照组,就表明该物质是预防或治疗胃癌的潜在物质。
芯片
本发明的所述的lncRNA芯片包括:固相载体;以及有序固定在所述固相载体上的寡核苷酸探针,所述的寡核苷酸探针特异性地对应于ENSG00000228742所示的部分或全部序列。
具体地,可根据本发明所述的lncRNA,设计出适合的探针,固定在固相载体上,形成“寡核苷酸阵列”。所述的“寡核苷酸阵列”是指具有可寻址位置(即以区别性的,可访问的地址为特征的位置)的阵列,每个可寻址位置均含有一个与其相连的特征性寡核苷酸。根据需要,可将寡核苷酸阵列分成多个亚阵。
术语“探针”指能与另一分子的特定序列或亚序列或其它部分结合的分子。除非另有指出,术语“探针”通常指能通过互补碱基配对与另一多核苷酸(往往称为“靶多核苷酸”)结合的多核苷酸探针。根据杂交条件的严格性,探针能和与该探针缺乏完全序列互补性的靶多核苷酸结合。探针可作直接或间接的标记,其范围包括引物。杂交方式,包括,但不限于:溶液相、固相、混合相或原位杂交测定法。
术语“互补的”或“互补性”用于指代通过碱基配对原则相关的多核苷酸(即,核苷酸的序列)。例如,序列“5'-A-G-T-3'”与序列“3'-T-C-A-5'”互补。互补性可以是“部分的”,其中只有一些核酸的碱基根据碱基配对原则匹配。或者,也可在核酸之间存在“完全”或“总”互补性。核酸链之间的互补程度对于核酸链之间的杂交效率和强度具有显著的影响。这在扩增反应以及依赖核酸之间的结合的检测方法中尤其重要。
术语“严格性”用于指代进行核酸杂交所处的条件:温度、离子强度和其他化合物(诸如有机溶剂)的存在。在“低严格条件”下,所关注的核酸序列将与其精确互补序列、具有单个碱基错配的序列、密切相关的序列(例如,具有90%或更高同源性的序列)以及只有部分同源性的序列(例如,具有50-90%同源性的序列)杂交。在“中等严格性条件”下,所关注的核酸序列将只与其精确互补序列、具有单个碱基错配的序列和密切相关的序列(例如,90%或更高同源性)杂交。在“高严格性条件”下,所关注的核酸序列将只与其精确互补序列和(取决于诸如温度的条件)具有单个碱基错配的序列杂交。换句话讲,在高严格性条件下,可升高温度以排除与具有单个碱基错配的序列杂交。
本发明中针对ENSG00000228742基因的寡核苷酸探针可以是DNA、RNA、DNA-RNA嵌合体、PNA或其它衍生物。所述探针的长度没有限制,只要完成特异性杂交、与目的核苷酸序列特异性结合,任何长度都可以。所述探针的长度可短至25、20、15、13或10个碱基长度。同样,所述探针的长度可长至60、80、100、150、300个碱基对或更长,甚至整个基因。由于不同的探针长度对杂交效率、信号特异性有不同的影响,所述探针的长度通常至少是14个碱基对,最长一般不超过30个碱基对,与目的核苷酸序列互补的长度以15-25个碱基对最佳。所述探针自身互补序列最好少于4个碱基对,以免影响杂交效率。
本发明中所述固相载体可采用基因芯片领域的各种常用材料,例如但不限于尼龙膜,经活性基团(如醛基、氨基等)修饰的玻片或硅片、未修饰的玻片、塑料片等。
所述的ENSG00000228742芯片的制备可采用本领域已知的生物芯片的常规制造方法。例如,如果固相载体采用的是修饰玻片或硅片,探针的5’端含有氨基修饰的聚dT串,可将寡核苷酸探针配制成溶液,然后采用点样仪将其点在修饰玻片或硅片上,排列成预定的序列或阵列,然后通过放置过夜来固定,就可得到本发明的lncRNA芯片。
试剂盒
本发明提供了一种试剂盒,所述试剂盒可用于检测ENSG00000228742的表达。
优选的,所述的制剂或试剂盒中还含有用于标记RNA样品的标记物,以及与所述标记物相对应的底物。此外,所述的试剂盒中还可包括用于提取RNA、PCR、杂交、显色等所需的各种试剂,包括但不限于:抽提液、扩增液、杂交液、酶、对照液、显色液、洗液等。此外,所述的试剂盒中还包括使用说明书和/或芯片图像分析软件。
在本发明中的药物还可以以单独的组合物或与主要的活性成分不同的剂量形式单独给予其它治疗性化合物。主要成分的部分剂量可以与其它治疗性化合物同时给药,而其它剂量可以单独给药。在治疗过程中,可以根据症状的严重程度、复发的频率和治疗方案的生理应答,调整本发明药物组合物的剂量。
本发明的药物还可与其他治疗胃癌的药物联用,其他治疗性化合物可以与主要的活性成分同时给药,甚至在同一组合物中同时给药。
术语“样本”以其最广泛的含义使用。在一种含义中,意在包括从任何来源获得的标本或培养物,以及生物和环境样本。生物样本可获自动物(包括人)并涵盖液体、固体、组织和气体。生物样本包括血液制品,诸如血浆、血清等。然而,此类样本不应解释为限制适用于本发明的样本类型。
下面结合附图和实施例对本发明作进一步详细的说明。以下实施例仅用于说明本发明而不用于限制本发明的范围。实施例中未注明具体条件的实验方法,通常按照常规条件,例如Sambrook等人,分子克隆:实验室手册(New York:Cold Spring HarborLaboratory Press,1989)中所述的条件,或按照制造厂商所建议的条件。
实施例1筛选与胃癌相关的基因标志物
1、样品收集
分别收集8例胃癌癌旁组织和胃癌组织样本全部病例在手术前均未接收化疗和放疗,所有的患者均已知情同意,并取得均通过组织伦理委员会的同意。
2、RNA样品的制备(利用E.Z.N.A.kit进行操作)
1)从-80℃超低温冰箱中取出临床标本,置于冰上解冻。称取约20mg组织放置于2mL离心管中,置于冰上加入1mL Trizol。使用手持式自动均浆机将组织充分匀浆至无固体,室温静置10min。
2)13000rpm、4℃离心10min。
3)用移液器小心地吸取上清液转移至干净的RNase-Free的l.5mL离心管中。
4)加入0.2mL的二氯甲烷,用旋涡混合器震荡15s,室温静置10min。
5)3000rpm、4℃离心10min。
6)小心地用移液器吸取水相并转移至1.5mL RNase-free的离心管中。
7)加入与步骤6)中等体积的异丙醇,用旋涡混合器震荡4s以沉淀总RNA,室温静置30min。
8)13000rpm在4℃下离心10min,弃上清。加入75%的酒精1mL,再次混匀。13000rpm在4℃下离心10min,弃上清。
9)置于室温下干燥10min,加入12μL RNase-Free水溶解RNA并放置于冰上备用。
3、总RNA定量与纯度分析
使用Bio-Red紫外分光光度计测定总RNA在280nm和260nm处的光密度值。RNA的量按1OD260nm-40μg RNA来计算,当OD260/OD280的值在1.8~2.0时认为总RNA的纯度是可靠的,可用于下一步的实验。
4、lncRNA表达芯片分析
利用Arraystar公司的Arraystar Human 1ncRNA Array检测胃癌组织和癌旁组织中lncRNA表达谱的差异。Arraystar 1ncRNA芯片设计探针为60nt长度的寡核苷酸,这些长寡核苷酸探针在高度严格的杂交条件下可以得到高灵敏度及特异性的理想实验结果。针对每条序列都设计了多条探针,增加了信号的可靠度。
5、数据分析
利用Agilent GeneSpring软件对芯片结果进行分析,筛选表达量具有显著性差异(标准为该lncRNA在癌与癌旁的表达量相差2倍以上,而且p<0.05)的lncRNA。
6、结果
结果显示,ENSG00000228742在胃癌组织中的表达量显著高于癌旁组织中的表达量。
实施例2QPCR测序验证ENSG00000228742基因的差异表达
1、对ENSG00000228742基因差异表达进行大样本QPCR验证。按照实施例1中的样本收集方式选择胃癌癌旁组织和胃癌组织各50例。
2、RNA提取步骤如实施例1所述。
3、逆转录
1)反应体系:
RNA模板1μl,随机引物1μl,双蒸水加至12μl,混匀,低转速离心,65℃5min,然后放在冰上冷却。
继续在12μl反应液中加入下列成分:
5×反应缓冲液4μl,RNA酶抑制剂(20U/μl)1μl,10mM dNTP混合液 2μl,AMV反转录酶(200U/μl)1μl;充分混匀并进行离心处理;
2)逆转录反应条件
25℃5min,42℃60min,70℃5min,4℃保温60min。
3)聚合酶链反应
引物设计:
根据Genebank中ENSG00000228742基因和GAPDH基因的序列设计QPCR扩增引物,由上海生物工程有限公司合成。具体引物序列如下:
ENSG00000228742基因:
正向引物为5’-CTCTTCAGCACAGAATCAG-3’(SEQ ID NO.2);
反向引物为5’-ACTACAACCTACTCAATTACATT-3’(SEQ ID NO.3)。
GAPDH基因:
正向引物为5’-AATCCCATCACCATCTTCCAG-3’(SEQ ID NO.4);
反向引物为5’-GAGCCCCAGCCTTCTCCAT-3’(SEQ ID NO.5)。
配制PCR反应体系:
2×qPCR混合液 12.5μl,基因引物2.0μl,反转录产物2.5μl,ddH2O 8.0μl。
PCR反应条件:95℃10min,(95℃15s,60℃60s)×40个循环,60℃5min延伸反应。。以SYBR Green作为荧光标记物,在Light Cycler荧光定量PCR仪上进行PCR反应,通过融解曲线分析和电泳确定目的条带,ΔΔCT法进行相对定量。
5、统计学方法
实验都是按照重复3次来完成的,结果数据都是以平均值±标准差的方式来表示,采用SPSS18.0统计软件来进行统计分析的,癌与癌旁组织的配对比较采用t检验,认为当P<0.05时具有统计学意义。
6、结果
结果如图1所示,与胃癌癌旁组织相比,ENSG00000228742在胃癌组织中表达上调,差异具有统计学意义(P<0.05),同芯片检测结果一致。
实施例3ENSG00000228742在胃癌细胞中的表达情况
1、细胞培养
人永生化胃粘膜上皮细胞系GES-1、人胃癌细胞系HGC-27、MGC-803、AGS(均购自广州莱德尔生物科技有限公司)在含10%胎牛血清和1%P/S的RPMI1640培养基于37℃、5%CO2、相对湿度为90%的培养箱中培养。2-3天换液1次,使用0.25%含EDTA的胰蛋白酶常规消化传代,取处于对数生长期的细胞用于实验。
2、RNA的提取
弃去完全培养基,用PBS清洗2次后用胰酶消化细胞,制成细胞悬液加入2mL离心管中,1200rpm离心8min,弃上清后加入1mL Trizol用移液器反复吹打15次以上,使细胞充分裂解。其余的操作步骤同实施例1。
3、逆转录
具体步骤同实施例2.
4、统计学方法
实验都是按照重复3次来完成的,结果数据都是以平均值±标准差的方式来表示,采用SPSS18.0统计软件来进行统计分析的,两者之间的差异采用t检验,认为当P<0.05时具有统计学意义。
5、结果
结果如图2所示,与胃粘膜上皮细胞相比,ENSG00000228742基因在胃癌细胞HGC-27、MGC-803、AGS中表达均上调,差异具有统计学意义(P<0.05),同RNA-sep结果一致。
实施例4ENSG00000228742基因的沉默
1、细胞培养步骤同实施例3。
2、siRNA的设计
阴性对照siRNA序列(siRNA-NC):
正义链为5’-UUCUCCGAACGUGUCACGU-3’(SEQ ID NO.6)
反义链为5’-ACGUGACACGUUCGGAGAA-3’(SEQ ID NO.7)
siRNA-1:
正义链为5’-AAAUGGUUUAUAGUACAAGAU-3’(SEQ ID NO.8)
反义链为5’-CUUGUACUAUAAACCAUUUGU-3’(SEQ ID NO.9)
siRNA-2:
正义链为5’-UUUAGACUCCCAUUUGGAGAG-3’(SEQ ID NO.10)
反义链为5’-CUCCAAAUGGGAGUCUAAAGG-3’(SEQ ID NO.11)
将细胞按4×104/孔接种到六孔细胞培养板中,在37℃、5%CO2培养箱中细胞培养24h,在无双抗、含10%FBS的DMEM培养基中,转染按照脂质体转染试剂2000(购自于Invitrogen公司)的说明书转染。
将实验分为三组:对照组(HGC-27)、阴性对照组(siRNA-NC)和实验组(siRNA1、siRNA2),其中阴性对照组siRNA与ENSG00000228742基因的序列无同源性,浓度为20nM/孔,同时分别进行转染。
3、QPCR检测ENSG00000228742基因的转录水平
3.1细胞总RNA的提取步骤同实施例3。
3.2逆转录步骤同实施例2。
3.3 QPCR扩增步骤同实施例2。
4、统计学方法
实验都是按照重复3次来完成的,结果数据都是以平均值±标准差的方式来表示,采用SPSS18.0统计软件来进行统计分析的,ENSG00000228742基因实验组与对照组之间的差异采用t检验,认为当P<0.05时具有统计学意义。
5、结果
结果如图3显示,与非转染组、转染siRNA-NC组相比,实验组能够显著降低ENSG00000228742基因的表达,差异具有统计学意义(P<0.05)。
实施例5ENSG00000228742基因对胃癌细胞增殖的影响
采用MTS实验检测ENSG00000228742基因对胃癌细胞增殖能力影响。
1、细胞培养与转染步骤同实施例4。
2、各组处理的细胞经胰酶消化后重悬细胞、计数,调整细胞浓度为l×105/ml按100μL/孔的密度接种于96孔板,即每孔细胞数为1×104个。
3、待细胞到达相应的检测时间点(0d、24h、48h、72h、96h)后,按10μL/孔加入CelITiter96AQ单溶液细胞增殖检测(MTS)试剂,微量振荡器振荡1~2min;置于5%CO2、37℃的细胞培养箱中孵育4h。
4、酶标仪读板,在490nm波长测定其吸光度(A)值。
5、统计学分析
实验都是按照重复3次来完成的,采用SPSS18.0统计软件来进行统计分析,两者之间的差异采用t检验,认为当P<0.05时具有统计学意义。
6、结果
结果如图4所示,与对照相比,实验组在转染siRNA-1后,细胞的增殖明显受到了抑制,差异具有统计学意义(P<0.05),说明ENSG00000228742具有促进细胞增殖的作用。
上述实施例的说明只是用于理解本发明的方法及其核心思想。应当指出,对于本领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也将落入本发明权利要求的保护范围内。
SEQUENCE LISTING
<110> 泰山医学院
<120> 分子标志物在胃癌诊治中的应用
<160> 11
<170> PatentIn version 3.5
<210> 1
<211> 3049
<212> DNA
<213> 人源
<400> 1
gaaatttggg tgcagacagg cacacaggga gaacaccatg tcaacacgaa ggcagaagtt 60
ggagtgatga gtctacaagc caaggattgc cagcaattca tcagaggcca ggacagcagc 120
ctggggcagc cccctacatg gtaccaactc catcaacacc ttgatctcag acttccaacc 180
tccagaactg tccagccctc catgaatgag gaacttcctg gggccactag tgcatgctgc 240
agctcacaca gtcaactcca tccacacctc cacaaacagc tgccctttgg ccactactca 300
ggcgtaagga cacacccagc agggtatgcc ctctggaggt cagaccaggg aagaagccct 360
tgcacagtca ggagccagct cagcacctgt gatgctgaat tctatgtggc aacttgactg 420
gacgcaggtg ctcggattaa acctgatttc tgggtatgtc tgtgagggta tttccagagg 480
agattagaat ttgaatccgt ggattggcaa agttggtgtc tgccccagtg tgggtggtca 540
ccatctactc tcctgagggc ctgaagagaa caaaaggcaa aggaaggagg aattcgccct 600
taacttgctt gccgcctgcc tgcttgagca gagacatttc atcacatctt ctctggccct 660
cgactgagat tcacaccatt ggcttccctg gttctcaggc attttgactt ggactgaact 720
acaccattgg ctttcctggg ctccagcttg cacatagcag attgtgggat ttctcagcct 780
ctattattac aggcgccagt tcttcaaaat caacctctct ctctctgtct ctctctctct 840
ccctagatca cagtctggaa gtctgctcac agtctcaagg ttggcatatc ccctagagcc 900
cccagactcc tcatcccatg gagaccaaca tggccagggg agggccagag cagggccttc 960
taaatcacag accccagggc aggagcccct ccggtctgga tctaaggatg gtattttcaa 1020
caattcctaa atttttatcc taggctctcc aaatgggagt ctaaaggtct caaaacatgg 1080
tccagaagaa gtatgcaaaa atgtaaattc ctaggcccca acccagacct atgaatcaga 1140
tgatctgtat gggggttcaa ggaatctata ttattaaaca atcttcctaa atgacttgta 1200
ttcatactaa agcttgagaa ttgctatcaa acagctagaa gttggagtga agggtcctgc 1260
ctttcccatg aaattcatca actctatgcc ctcaaaagct gggctcttgg atgagctgct 1320
ctccattcta gagacattac cagctaggta gcctgctggt cctcaggaag ttaagcccag 1380
actcttcagc acagaatcag ataaacactg attacattgt actctacagt tctgagaaca 1440
ccattactta attcccggca agttgcaatg taattgagta ggttgtagtt ttttgggttt 1500
ggggtttttt tgttttttaa atatatcagg cgtagttagc cagcttccta gaaacaccat 1560
gatctcttgg tgaaaattcc agaaatatgc atcacttcct aattaaagta gggaattttt 1620
aaaaattatt aaaccacatg ctttctaatt cctattgccc tttcttttca cccaccattc 1680
agcagtcagc agacactttc tgggtacaac agggtaggac catccaggca gaacaaaagc 1740
cattgatcat gaactacaga ggagagtttg gtaaatggac accagaaacc atggcctaca 1800
ggggcctggt tttctcccat ctaaatacta actaggccca acgctagttg ggcttagctt 1860
cctagatcag atgaaattgg gcacatttag ggttgggggt atggctctct attgtaagta 1920
gcaagagttt gagagaagaa aaaagggatt ttcttttttt tttcttttaa attttagagc 1980
attaacttta aacatcaaga tccaaacccc aaggattcag agaatcttgt actataaacc 2040
atttgtatta gtcagggttc tccagagaaa cagaacccat aggaggtata gagatagaga 2100
aatatggaat tggctcccat gattatggag gctgagaagt ccctcaatct gctgtctgtg 2160
agctggagac ctaggaaagc ttagctggtg gtacaaacca gcccaagtgc aaaggcccaa 2220
gaactaagag caccattgtc agagagcagg aaaagacaga tgtcccagct caaaaagaga 2280
gagcaaattc accttccttc caccatttta ttccgtcctg ttccattcct caacaggttg 2340
gatgatgagg gagatcttta tccatctcaa gttttttgtg caaatatgga atacaaatga 2400
aaaatactta aagcacatca tcattgattt ccaacttaga ctagtttaac ttcccttttt 2460
cttctatcct gtcagttcct tgagggatcc tctctccttg ttcatctctg catctctagt 2520
aattagcaca gtgccaggca catggtaata tggctaaaac agtggattat tggtctccaa 2580
cataattaag cccatccaaa agaaaaacca acctcataaa tctgctttgc aaagttcata 2640
aacaatggat atgctatgtc tcaaaggtgc tggccaaaaa aatttaagaa cttgggaatt 2700
atgtgttatt ttgtttgttt ttttcaccaa gcctactttt ctgtcacaag agcccatatc 2760
aacaacacac ccatgtatgt ccttcttttt atctactttt ctccatgaag tttgtcacca 2820
tcaactgtta aaactgtaaa gatttgatca gctaaataag tggtctttga actaattcct 2880
ctcgtacttc ctaaaggaac tttgaaaaac tatgtatccc cttgcacatt ttcaagcaga 2940
cacctaagat ttttcatcat aaatttgaat aacttcaaaa tatgtactta ttagcatatt 3000
gtaaatattg atttttaaat aaaatatatc acactttgta tccaatgaa 3049
<210> 2
<211> 19
<212> DNA
<213> 人工序列
<400> 2
ctcttcagca cagaatcag 19
<210> 3
<211> 23
<212> DNA
<213> 人工序列
<400> 3
actacaacct actcaattac att 23
<210> 4
<211> 21
<212> DNA
<213> 人工序列
<400> 4
aatcccatca ccatcttcca g 21
<210> 5
<211> 19
<212> DNA
<213> 人工序列
<400> 5
gagccccagc cttctccat 19
<210> 6
<211> 19
<212> RNA
<213> 人工序列
<400> 6
uucuccgaac gugucacgu 19
<210> 7
<211> 19
<212> RNA
<213> 人工序列
<400> 7
acgugacacg uucggagaa 19
<210> 8
<211> 21
<212> RNA
<213> 人工序列
<400> 8
aaaugguuua uaguacaaga u 21
<210> 9
<211> 21
<212> RNA
<213> 人工序列
<400> 9
cuuguacuau aaaccauuug u 21
<210> 10
<211> 21
<212> RNA
<213> 人工序列
<400> 10
uuuagacucc cauuuggaga g 21
<210> 11
<211> 21
<212> RNA
<213> 人工序列
<400> 11
cuccaaaugg gagucuaaag g 21
- 还没有人留言评论。精彩留言会获得点赞!