稳定表达细胞色素P4502C9*8和*27的人源化细胞模型及其构建方法和应用与流程
本发明属于生物领域,涉及一种稳定表达细胞色素p4502c9(cyp2c9)基因449位单碱基突变体的人源化细胞模型及其构建方法和应用。
背景技术:
细胞色素p450(cyps)催化人体内绝大多数的药物和毒物的代谢清除,是重要的药物一相代谢酶。cyp2c9隶属于cyp2c亚族,参与了超过15%临床药物的代谢清除,其底物包括s-华法林、苯妥英、格列甲嗪和甲苯磺丁脲等[1]。cyp2c9具有高度的基因多态性,这些基因多态性对多种药物的代谢速率及相关不良反应起到了决定性的作用[2]。故研究cyp2c9基因多态性对临床用药安全、药物不良反应及指导合理用药具有重要的意义。
cyp2c9最常见的等位基因为cyp2c9*1,该型在所有人群中出现频率最高,并被认为是野生型。非裔美国人中cyp2c9在499位常见的单碱基突变为cyp2c9*8(449g>a),而在亚洲人中该位点常见突变为cyp2c9*27(499g>t),在蛋白序列上cyp2c9蛋白上150位精氨酸分别突变为赖氨酸和组氨酸[3,4]。值得注意的是,cyp2c9*8和cyp2c9*27对底物催化速率的变化表现出了不同的选择性[5,6]。这两种突变均导致cyp2c9的底物甲苯磺丁脲、氯沙坦和格列美脲的代谢清除速率降低。cyp2c9*8代谢华法林、双氯芬酸和氟西汀的速率与cyp2c9*1相比均下降,而cyp2c9*27催化双氯芬酸和氟西汀与野生型并无显著差异。此外cyp2c9*8代谢清除苯妥英速率降低,而*27却导致了代谢清除速率的显著上升。
但人肝组织来源受限,表达cyp2c9*8和cyp2c9*27的组织来源更稀少,采用人源化细胞稳定表达上述两个突变体是研究的首选策略。由于cyps为膜蛋白,大肠杆菌表达cyps的体系除了蛋白的转录后修饰存在问题外,表达获得的产物需与脂质重构。另外现有报道的真核表达cyp2c9*8和cyp2c9*27的模型为杆状病毒感染昆虫细胞模型[5,7],但仍存在转录后修饰与人存在差异这一问题,该体系也无法实现稳定表达。目前尚无稳定表达cyp2c9*8和cyp2c9*27的人源化体系。
现有报道的稳定表达cyp家族的中cyp1a1、cyp1a2、cyp2a6、cyp2b6、cyp2e1和cyp3a4的体系采用电穿孔技术结合g418药物筛选[8],该体系需要额外电穿孔仪器且对细胞有损伤,另外采用g418药物筛选需首先摸索药物浓度,而且筛选所需时间较长。此外在构建cyp2c19的稳定表达体系中,使用了lipofectaminetm2000转染hepg2细胞结合g418筛选的策略[9],除了存在筛选周期长这一问题外,lipofectaminetm2000转染hepg2细胞存在效率低这一问题,对筛选的成功率也有较大影响。
技术实现要素:
本发明的目的是提供一种稳定表达细胞色素p4502c9(cyp2c9)449位单碱基突变体的人源化细胞模型及其构建方法和应用。
本发明所述的稳定表达细胞色素p4502c9(cyp2c9)449位单碱基突变体的人源化细胞模型,是通过以下方法构建获得:将cyp2c9*8cdna或cyp2c9*27cdna重组至migr1质粒,获得migrg1-cyp2c9star8或migr1-cyp2c9star27,将上述质粒与gag-pol和vsvg共转染至293t细胞从培养基上清中获得病毒;该病毒感染293t细胞,通过单克隆筛选获得稳定表达cyp2c9*8或cyp2c9*27的人源化细胞株。
本发明同时公开了所述稳定表达细胞色素p4502c9(cyp2c9)449位单碱基突变体的人源化细胞模型的构建方法,其中所述cyp2c9*8cdna或cyp2c9*27cdna通过以下方法得到:以手术切除的人肝组织为材料提取总rna,并扩增cyp2c9的cdna,正义和反义引物序列如seqinno:1,2所示;采用含有499位g>a的正义和反义引物,序列如seqinno:3,4所示,分别与cyp2c9的反义和正义引物组合,利用cyp2c9的cdna为模板进行pcr扩增,所得的产物纯化后再进行pcr反应,获得的产物即为cyp2c9*8的cdna;或者是采用序列如seqinno:5,6的含有499位g>t的正义和反义引物序列替代g>a的引物,重复上述步骤,获得cyp2c9*27的cdna。
本发明还公开了所述的稳定表达细胞色素p4502c9(cyp2c9)449位单碱基突变体的人源化细胞模型在cyp2c9代谢能力预测中的应用。例如在评价cyp2c9*8或cyp2c9*27突变体存在下肝脏对cyp2c9底物的处置情况中的应用。
该应用具体是:从稳定表达细胞色素p4502c9(cyp2c9)449位单碱基突变体的人源化细胞模型中提取微粒体后与cyp2c9底物及辅因子共同孵育,通过评价底物代谢的动力学参数,来用于评价cyp2c9*8或cyp2c9*27突变体存在下肝脏对cyp2c9底物的处置情况。本发明所述的一种稳定表达细胞色素p4502c9(cyp2c9)449位单碱基突变体的人源化细胞模型的构建方法,
本发明采用慢病毒感染结合绿色荧光筛选的方法,有效的提高了效率并缩短了筛选周期。此外,在构建cyp2c9*8和cyp2c9*27两个突变体时,通过引物设计有效提高了特异性和pcr效率。本发明建立的人源化表达cyp2c9*8和cyp2c9*27细胞模型,对于两种突变体的功能和催化机制研究是一个有效的模型;可以提取cyp2c9*8和cyp2c9*27稳定表达的单克隆细胞中的微粒体,与底物和辅因子共孵育,判断底物的代谢情况,对药物相互作用进行预测。本发明设计合理,重复性和特异性好。
附图说明
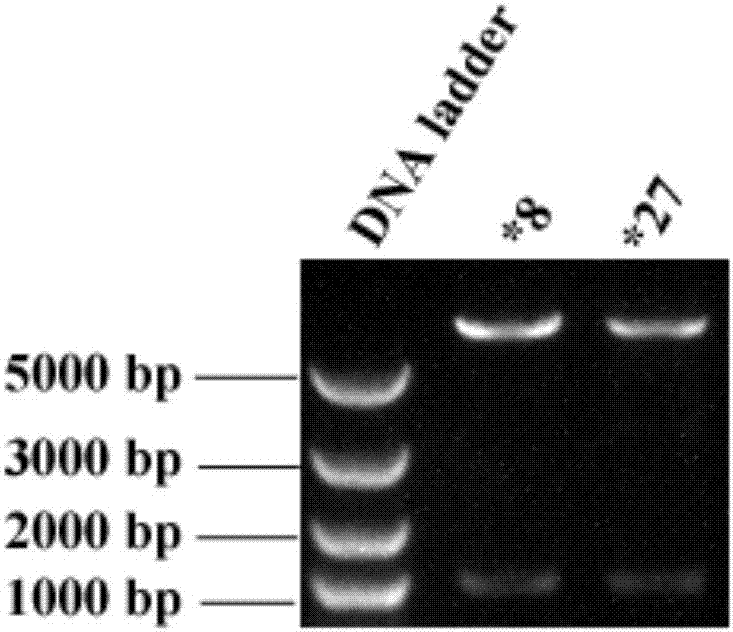
图1是cyp2c9*8和cyp2c9*27表达序列的电泳图。
图2是质粒migr1-2c9star8和migr1-2c9star27双酶切结果。
图3是质粒migr1-2c9star8和migr1-2c9star27的部分测序结果。
图4是293t-2c9star8和293t-2c9star17的细胞荧光。
图5是293t-2c9star8和293t-2c9star17细胞中cyp2c9*8和*27的mrna水平。
图6是293t-2c9star8和293t-2c9star17细胞微粒体中的p450含量。
图7是对cyp2c9底物的代谢活性。
具体实施方式
本发明结合附图和实施例作进一步说明:
实施例1cyp2c9*8和cyp2c9*27表达载体的构建
1.cyp2c9cdna序列的扩增和突变位点的引入
设计带限制性内切酶酶切位点的人cyp2c9特异引物上下游引物序列,扩增cyp2c9编码区,引物序列如下:
seqidno:1ccgctcgaggagatggattctcttgtggtc
seqidno:2ccggaattctcagacaggaatgaagca
获得上下游分别引入限制性内切酶xhoi和ecori酶切位点的cyp2c9编码区。设计含有449位g>a的正义和反义引物,引物序列如下:
seqinno:3aggcagtgggcttcctcttga
seqinno:4tgttcaagaggaagcccactg
将上述含有449位g>a的正义和反义引物分别与带限制性内切酶酶切位点的人cyp2c9特异引物上下游引物(seqidno:1和2)组合,以上下游分别引入限制性内切酶xhoi和ecori酶切位点的cyp2c9编码区为模板进行扩增,获得两段pcr产物,并进行pcr产物纯化。将上述纯化的两段产物组合进行pcr反应,获得含有限制性内切酶酶切位点的cyp2c9*8的编码序列。
设计含有449位g>t突变的正义和反义引物,引物序列如下:
seqinno:5ctcctccacaaggcagaggg
seqinno:6ggaagccctctgccttgtgga
使用这两个替代449位g>a的引物,重复上述pcr反应,获得含有限制性内切酶酶切位点的cyp2c9*27的编码序列。
电泳鉴定扩增获得序列分子量,该分子量与预期上下游分别引入限制性内切酶xhoi和ecori酶切位点cyp2c9*8和cyp2c9*27的编码序列分子量一致(见图1)。
2.cyp2c9*8和cyp2c9*27序列的表达质粒的构建。
采用xhoi和ecori限制性内切酶分别切割migr1质粒(addgene,plasmid#27490)及引入限制性内切酶酶切位点的cyp2c9*8和cyp2c9*27的编码序列后,活得带粘末端的酶切产物。通过t4dna连接酶将质粒酶切产物与cyp2c9*8或cyp2c9*27带粘末端的酶切产物连接,转化至感受态dh5α大肠杆菌,挑取单克隆并对目标质粒进行双酶切和测序鉴定(见图2和图3)。成功构建表达cyp2c9*8和cyp2c9*27序列的表达质粒,分别命名为migr1-2c9star8和migr1-2c9star27。
实施例2稳定表达cyp2c9*8和cyp2c9*27的293t细胞株的构建。
1.293t细胞转染。
293t细胞培养于rpim1640培养基(含10%胎牛血清、100ku/l青和100mg/链霉素)至对数生长期,于3×105/孔的密度接种于6孔板后培养24h,gag-pol(addgene,plasmid#14887),vsv-g(addgene,plasmid#8454)和cyp2c9的499位突变体的表达质粒以分别0.6μg、0.6μg和1.8μg的含量,使用lipofectamine2000转染至293细胞,5h后更换为新鲜培养基。24h后收集培养基上清,采用0.45μm滤膜过滤,获得含慢病毒的培养基。
2.293t细胞感染
293t细胞(3×105/孔)接种于6孔板后培养24h,更换培养基为上一步获得的含病毒的培养基,继续培养72h后,更换培养基为rpim1640培养基(含10%胎牛血清、100ku/l青和100mg/链霉素)。
3.单克隆筛选
将上述细胞消化后,稀释至6/ml,接种于100mm细胞培养皿(5ml),培养72h。于荧光显微镜下观察,挑取荧光强度高的克隆至24孔板中。每个突变体各选取十个克隆,培养192h后,于荧光显微镜下观察,分别选取表达两个突变体重荧光强度最强组传代,细胞传代30代后绿色荧光蛋白仍稳定表达,细胞命名为293t-2c9star8和293t-2c9star27(图4),并对cyp2c9*8和cyp2c9*27进行检测。
实施例3稳定表达cyp2c9*8和cyp2c9*27的293t细胞株内cyp2c9表达与活性检测。
1.胞内cyp2c9表达水平的检测:
提取293t-2c9star8和293t-2c9star27胞内的总rna,逆转录后,采用荧光实时定量pcr方法,检测cyp2c9在胞内的表达水平。与空质粒对照组(ctrl)比较,293t-2c9star8和293t-2c9star27胞内的mrna水平明显上调(图5)。
2.293t-2c9star8和293t-2c9star27细胞微粒体的提取及cyps含量检测。
超声破碎细胞后,微粒体悬液于9000×g离心20min,收集上清并于100,000×g离心1h,获得沉淀重悬于0.1m磷酸缓冲液(ph7.4)并稀释至0.5mg/ml。各取3ml,加入两比色杯中(双光束)紫外分光光度计500-400nm扫描,获得基线。各杯中加入连二亚硫酸钠数mg。迅速向测定管内充co30-60秒,稳定5min后,再次500-400nm扫描,得到还原型cyps的od值(图6)。利用如下公式计算
3.采用cyp2c9的特异性底物双氯芬酸对提取自293t-2c9star8和293t-2c9star27的微粒体中的cyp2c9的活性进行评价。结果表明,与空质粒组(ctrl)比较,表达cyp2c9*8和cyp2c9*27的293t细胞内提取的微粒体均有催化双氯芬酸为4-羟基双氯芬酸的活性(图7)。
本发明的参考文献:
[1]miners,j.o.andd.j.birkett,cytochromep4502c9:anenzymeofmajorimportanceinhumandrugmetabolism.brjclinpharmacol,1998.45(6):p.525-38.
[2]franco,v.ande.perucca,cyp2c9polymorphismsandphenytoinmetabolism:implicationsforadverseeffects.expertopindrugmetabtoxicol,2015.11(8):p.1269-79.
[3]maekawa,k.,etal.,fournoveldefectiveallelesandcomprehensivehaplotypeanalysisofcyp2c9injapanese.pharmacogenetgenomics,2006.16(7):p.497-514.
[4]dai,d.p.,etal.,cyp2c9polymorphismanalysisinhanchinesepopulations:buildingthelargestallelefrequencydatabase.pharmacogenomicsj,2014.14(1):p.85-92.
[5]chen,l.g.,etal.,invitrometabolismofphenytoinin36cyp2c9variantsfoundinthechinesepopulation.chembiolinteract,2016.
[6]ji,y.,etal.,invitroassessmentof39cyp2c9variantsfoundinthechinesepopulationonthemetabolismofthemodelsubstratefluoxetineandasummaryoftheireffectsonothersubstrates.jclinpharmther,2015.40(3):p.320-7.
[7]wei,l.,etal.,polymorphicvariantsofcyp2c9:mechanismsinvolvedinreducedcatalyticactivity.molpharmacol,2007.72:p.1280-8.
[8]余应年等,人细胞色素p450系列转基因细胞株.中国,95120603.6[p].1997-6-18.
[9]陈旺等,cyp2c19基因多态性真核表达载体的构建及稳定转染细胞系的建立.中国临床药理学与治疗学,2012.17(3):p.263-8.
sequencelisting
<110>扬州大学
<120>稳定表达细胞色素p4502c9*8和*27的人源化细胞模型及其构建方法和应用
<130>
<160>6
<170>patentinversion3.3
<210>1
<211>30
<212>dna
<213>人工序列
<400>1
ccgctcgaggagatggattctcttgtggtc30
<210>2
<211>27
<212>dna
<213>人工序列
<400>2
ccggaattctcagacaggaatgaagca27
<210>3
<211>21
<212>dna
<213>人工序列
<400>3
aggcagtgggcttcctcttga21
<210>4
<211>21
<212>dna
<213>人工序列
<400>4
tgttcaagaggaagcccactg21
<210>5
<211>20
<212>dna
<213>人工序列
<400>5
ctcctccacaaggcagaggg20
<210>6
<211>21
<212>dna
<213>人工序列
<400>6
ggaagccctctgccttgtgga21
- 还没有人留言评论。精彩留言会获得点赞!