一种Ammecr1和Ammecr1L重组真核表达载体及其构建方法和应用与流程
本发明属于基因工程领域,特别涉及一种ammecr1和ammecr1l重组真核表达载体及其构建方法和应用,尤其涉及两个古老且保守的基因家族成员ammecr1和ammecr1l重组真核表达载体及其构建方法和其应用。
背景技术:
ammecr1和ammecr1l(alportsyndrome,mentalretardation,midfacehypoplasia,elliptosischrosomalregiongene)是x-连锁邻近基因缺陷综合征(contiguousgenedeletionsyndrome)amme关键区域的基因之一,在人类染色体xq22.3区域编码。ammecr1和ammecr1l是一个及其古老而且非常保守的基因,从古细菌、细菌、酵母、线虫、果蝇、文昌鱼、斑马鱼以及小鼠和人类中,这一蛋白都有很高的同源性,尤其是c端区域中的“lrgcig”区域在原核生物(古细菌和细菌)和真核生物中完全一致。目前的研究表明,amme区域内编码ⅳ型胶原α-5链基因col4a5点突变或基因内删除将引起血管性球性肾炎。然而带有不包含col4a5基因但含有包括ammecr1在内的9个基因的x染色体删除的患者,仍表现中等智力障碍(moderateintellectualdisability),神经性听力损失(sensorineuralhearingloss),面部发育不全(facialdysmorphism),幽门狭窄(pyloricstenosis)以及肠梗阻(intestinalobstruction)。
ammecr1的组织分布一般比较广泛,但还能在一些特殊细胞或条件下表达、不表达甚至被删除。例如,在兔白内障手术后水状液(aqueoushumor,ah)样品中以及在养殖于含乙炔雌二醇(ethinylestradiol)水体达14天的鱼类精巢组织中均有表达;但在鼠滋养层干细胞k4gfp中,ammecr1不表达;而在智力障碍者的外周血白细胞及人类不同恶性程度的眼色素层黑色素瘤(uvealmelanoma)细胞,ammecr1是染色体删除的。如果ammecr1酵母(s.pombe)同源物spac688.03c删除、酵母细胞对紫外线中等敏感,因此,ammecr1可能和dna的修复有关。
以上研究成果均提示ammecr1和ammecr1l基因编码的蛋白可能在最核心的生命活动中发挥最基本的生理功能,也有可能与dna转录、修复或者翻译等生命活动密切相关。然而,至目前为止,尚未有研究人员成功克隆人类ammecr1(nm_015365)和ammecr1l(nm_031445c)基因编码区全长序列,并构建这两个基因的真核重组表达载体。因此,目前基于这两个基因编码的蛋白在人类疾病中的功能研究还无法深入进行,仅处于理论推测阶段。
技术实现要素:
本发明的目的是在世界上首次提供一种ammecr1和ammecr1l重组真核表达载体及其构建方法和应用,所述ammecr1和ammecr1l为两个古老而且极其保守的基因家族成员,其构建方法简单易行,成功率高,且为该基因编码的蛋白在肿瘤和炎症等疾病中的功能研究奠定了基础。
为此,本发明技术方案如下:
第一方面,本发明提供一种基于gv141的重组真核表达载体,所述重组真核表达载体为将ammecr1和ammecr1l基因克隆表达到真核表达载体gv141上。
本发明中,ammecr1和ammecr1l是两个古老且保守的基因家族成员,发明人经过大量试验发现,将ammecr1和ammecr1l基因克隆,并连接至gv141真核载体,成功实现ammecr1和ammecr1l基因的重组克隆,且制备得到的载体可以用于各类细胞系中构建稳定表达此基因的细胞株,能够实现将ammecr1和ammecr1l基因在各类细胞系中持续稳定表达或者诱导表达。
优选地,所述ammecr1基因的核苷酸序列如seqidno.1所示,具体如下:atggcggcgggttgctgcggggtgaagaagcagaaactgtccagttcgcccccctctggctcgggtggcggtggtggcgcctcctcctcctcccactgcagcggagagagccagtgccgagctggggagctgggactaggaggcgccggtacgcggctcaacgggctgggaggtctaaccggaggaggtagcggcagcggctgtaccctctctcccccccagggctgcggcggcggcggcggggggatcgccctgtcgccacctccgagctgcggagtggggaccctactttctaccccggccgccgccacctcttcctcaccctcctcatcgtccgccgcctcgtcctcatcgccgggctcccggaagatggtggtgtcagcagagatgtgctgcttttgcttcgatgtgctctactgtcacctgtatggataccagcagccccggaccccccgattcaccaacgagccctacccactgtttgtaacatggaagattggtcgagacaaaagattacgtggatgcataggtactttttctgccatgaatttgcattcaggactcagggagtacacacttaccagtgcccttaaagatagccgttttcccccaatgacaagggatgagctgccacggcttttctgctcagtgtctctgctcactaactttgaagatgtctgtgattatttggactgggaggtgggtgtacatggcattagaatagaattcatcaatgaaaaaggatcaaaacgcaccgccacctacctaccggaggttgcaaaggagcaaggatgggaccatatacagaccatagactccttattgaggaaaggaggatacaaagctccgattactaatgaattcaggaaaaccataaaactgaccaggtatcgtagtgaaaagatgaccctgagctatgctgaataccttgctcatcgccagcatcatcatttccaaaatggcattgggcatccccttccgccatacaaccattattcctacccttatgatgtcccagactatgcttcggtaccaagcttaagtgactacaaggatgacgatgacaaggattacaaagacgacgatgataaggactataaggatgatgacgacaaatctagatagttaaaccgctgatcagcctcgactgtgccttctagttgccagccatct.
优选地,所述ammecr1l基因的核苷酸序列如seqidno.2所示,具体如下:
atgggaaaaagacgttgtgttcctccactcgagcccaagttggcagcaggctgttgtggggtcaagaagcccaaattatctggaagtggaacgcacagtcacgggaatcagtccacaactgtccccggctctagttcaggacctcttcaaaaccaccagcatgtggacagcagcagtggacgggagaatgtgtcagacttaactctgggacctggaaactctcccatcacacgaatgaatcccgcatcgggagcgctgagccctcttccccggcctaatggaactgccaacaccactaagaatctggtggtgactgcagagatgtgctgctactgcttcgacgtactctactgtcacctctatggcttcccacagccacgacttcctagattcaccaatgacccctatccgctctttgtgacgtggaagacagggcgggacaagcggcttcgtggctgcattgggaccttctcagccatgaatcttcattcaggactcagggaatacacgttaaccagtgcacttaaggacagccgatttccccccctgacccgagaggagctgcctaaacttttctgctctgtctccctccttactaactttgaggatgccagtgattacctggactgggaggtaggggtccatgggattcgaattgaattcattaatgaaaaaggtgtcaaacgcacagccacatatttacctgaggttgctaaggaacaagactgggatcagatccagacaatagactccttgctcaggaaaggtggctttaaagctccaattaccagtgaattcagaaaaacgatcaaactcaccaggtaccgaagtgagaaggtgacaatcagttacgcagagtatattgcttcccgacagcactgtttccagaacggcactcttcatgccccgcccctctacaatcattactcc.
优选地,所述重组真核表达载体的元件顺序为:cmv-egfp-mcs-3flag-sv40-neomycin。
第二方面,本发明提供如第一方面所述的真核表达载体的构建方法,所述方法包括以下步骤:
制备阳性克隆t-ammecr1/ammecr1l,将阳性克隆t-ammecr1/ammecr1l与真核表达载体gv141连接后,得到人类ammecr1和ammecr1l基因真核表达载体gv141-ammecr1/ammecr1l的重组质粒。
根据本发明,所述制备阳性克隆t-ammecr1/ammecr1l为以人类cdna文库为模板进行pcr扩增,获得ammecr1和ammecr1l基因后克隆到t载体上,获得阳性克隆t-ammecr1/ammecr1l。
优选地,所述pcr扩增所用的引物如seqidno.3-4所示,具体如下:
seqidno.3所示的上游引物:5’-acgggccctctagactcgagcgccaccatggcggcgggttgctgcggggtgaag-3’;
seqidno.4所示的下游引物:5’-agtcacttaagcttggtaccgaagcatagtctgggacatcataagg-3’;
以上引物含交换配对碱基、酶切位点,并含有目的基因5’端部分序列用于pcr钓取目的基因。
优选地,将阳性克隆t-ammecr1l和/或ammecr1连接到真核表达载体gv141的xhoi和kpni位点。
优选地,所述克隆为将获得的ammecr1和/或ammecr1l基因置于琼脂糖凝胶电泳、检测后于紫外仪下切割目的片段并使用凝胶回收试剂盒回收,回收产物克隆到pgem-teasy载体上。
优选地,所述制备阳性克隆t-ammecr1/ammecr1l为全基因合成ncbi中人类的ammecr1/ammecr1l序列,获得ammecr1和/ammecr1l基因后,分别克隆到t载体上,获得阳性克隆t-ammecr1/ammecr1l。
本发明中,所述全基因合成为用常规方法进行,比如利用自动合成仪采用全片段酶促连接法或酶促填充法等,在此不做特特殊限定。
优选地,所述人类ammecr1基因的序列如seqidno.1所示;
优选地,所述人类ammecr1l基因的序列如seqidno.2所示;
优选地,分别在所述seqidno.1和所述seqidno.2的5’端人工合成xhoi酶切位点,3’端人工合成kpni酶切位点。
本发明中,所述将阳性克隆t-ammecr1/ammecr1l与真核表达载体gv141连接,具体为:将阳性克隆t-ammecr1/ammecr1l与真核表达载体gv141分别经限制性内切酶xhoi和kpni双酶切,然后进行连接,并转化至大肠杆菌dh5α感受态细胞,通过抗性基因序列筛选,将阳性克隆采用菌落pcr测序鉴定,获得人类ammecr1和ammecr1l基因真核表达载体gv141-ammecr1/ammecr1l的重组质粒;
优选地,所述抗性基因序列为包含抗新霉素(neomycin)基因和抗氨苄霉素(ampicillin)的序列。
第三方面,本发明提供一种宿主细胞,其特征在于,包括如第一方面所述的重组真核表达载体;
优选地,所述宿主细胞为293t、hela或u251中的任意一种或至少两种的组合,优选为293t细胞。
第四方面,本发明提供一种如第一方面所述的两个基因的重组真核表达载体,可广泛用于研究x-连锁邻近基因缺陷综合症或者其它神经系统相关疾病的分子机制。
第五方面,本发明提供了两个如第一方面所述的重组真核表达载体在基于ammecr1和ammecr1l基因编码蛋白的靶点药物筛选方面的应用;
优选地,所述药物为抗病毒药物。
本发明中,发明人在世界上首次发现该基因具有促进vsv等病毒复制的特点,所述载体能作为后续抗病毒药物筛选研究的重要工具。
与现有技术相比,本发明至少具有以下有益效果:
(1)本发明在世界上首次成功构建人类ammecr1和ammecr1l基因重组真核表达载体,采用特异的真核表达载体,选择恰当的酶切位点,使得成功构建的重组载体可以用于构建稳定持续表达的细胞株,从而实现基于该重组载体的ammecr1和ammecr1l基因在各类细胞系中持续稳定表达或者诱导表达;
(2)本发明构建的重组真核表达载体为将来研究该基因在肿瘤、炎症以及神经系统和其它病毒性疾病中的作用机制提供了一个便利工具;
(3)本发明在世界上首次发现该基因具有促进vsv等病毒复制的特点,故该基因有可能为抗病毒药物筛选的重要靶点,为后续基于该基因在抗病毒药物筛选中的功能研究提供了基础依据。
附图说明
图1为目的基因片段的体外扩增的琼脂糖凝胶电泳图,其中,marker自上而下依次为5kb、3kb、2kb、1.5kb、1kb、750bp、500bp、250bp和100bp;
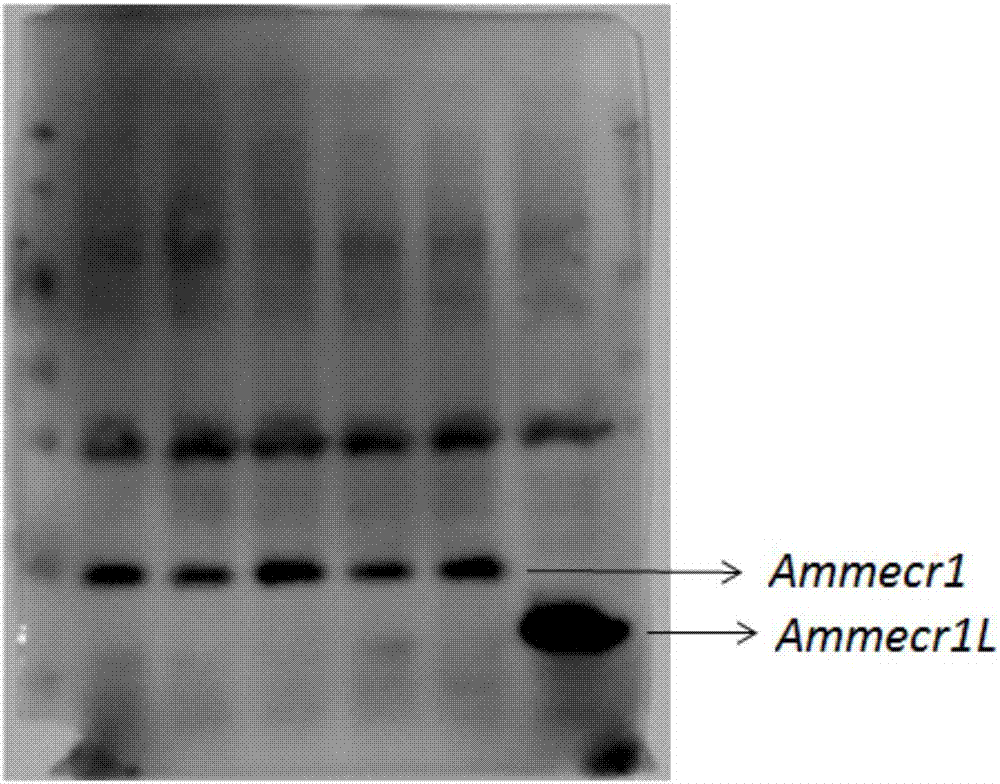
图2为目的基因片段的免疫印迹结果图,其中,marker自上而下依次为170kda、130kda、100kda、70kda、55kda、40kda、35kda、25kda、15kda和10kda。
具体实施方式
下面结合附图及具体实施例对本发明做进一步的说明,但下述实施例绝非对本发明有任何限制。
实施例1目的基因片段的体外扩增及纯化
将人类cdna文库作为模板,采用pcr扩增技术,获得ammecr1和/或ammecr1l基因,根据人类cdna文库的ammecr1和/或ammecr1l基因序列设计引物对,同时在两条引物5'端分别加上xhoi和kpni内切酶的酶切位点:
seqidno.3所示的上游引物:
5’-acgggccctctagactcgagcgccaccatggcggcgggttgctgcggggtgaag-3’;
seqidno.4所示的下游引物:
5’-agtcacttaagcttggtaccgaagcatagtctgggacatcataagg-3’;
pcr扩增反应体系如下:
其中,一组以水为样本的阴性对照。
反应条件如下:
将ammecr1和/或ammecr1l基因置于1.5%琼脂糖凝胶电泳,于紫外仪下切割目的片段并使用凝胶回收试剂盒回收,具体操作方法按照试剂盒中的操作步骤进行,得到纯化pcr产,结果如图1所示,pcr产物为1075bp。
实施例2目的基因片段的体外化学合成
参照ncbi数据库中人类ammecr1(nm_015365)和ammecr1l(nm_031445c)的核苷酸序列,利用自动合成仪合成seqidno.1和seqidno.2的序列,且分别在seqidno.1和seqidno.2的5’端人工合成xhoi酶切位点,3’端人工合成kpni酶切位点。
实施例3重组质粒的构建
(1)将纯化pcr产物与pgem-teasy载体(购自promega公司)分别进行酶切和连接,酶切反应体系如下:
连接反应体系如下:
(2)取100μldh5α感受态细胞加入5μl的步骤(1)获得的连接产物中,混匀后在冰上放置30min,42℃热激90s,立即冰浴2min,加入400μl无抗生素的lb液体培养基,37℃缓慢振荡(150~200r/min)培养1h,离心(<4000g)后弃300μl上清液,吹匀后吸取剩下lb涂于已提前涂有iptg(isopropylthio-β-d-galactoside,异丙基硫代-β-d-半乳糖苷)和x-gal的琼脂平板(含有浓度为100mg/l的amp+)上,37℃培养过夜。
实施例4重组质粒的鉴定
(1)挑取琼脂平板上长出来的形态正常的白色单菌落,在无菌台上接种于1ml含100mg/lamp+的lb液体培养基中,37℃振荡(300r/min)培养过夜(7~9h),吸取1μl过夜培养的菌液作为pcr扩增的模板,挑选单克隆进行pcr检测,pcr反应体系为20μl,其中含有14.7μl的ddh2o,上下游引物各0.4μl,2μl的10×buffer,0.5μl的mgcl2,0.8μl的浓度为2.5mm的dntps,0.2μl的pfu聚合酶,1μl的菌液模板。pcr仪进行的反应循环条件为:95℃5min预变性,95℃30s变性,61℃30s进行退火,然后72℃延伸30s,共进行30个循环,最后72℃延伸5min。进行dna测序,获得阳性克隆进行测序,确定测序结果正确后(测序结果如seqidno.1所示),从测序正确的阳性克隆中提取dna,并命名为t-ammecr1/ammecr1l;
(2)将步骤(1)所提的dna采用限制性内切酶xhoi和kpni进行酶切鉴定,具体的酶切反应体系与实施例2相同;酶切产物在1.5%琼脂糖凝胶电泳检测,在紫外灯下拍照,酶切结果和预计片段大小相同的即为阳性重组质粒;
(3)采用限制性内切酶xhoi和kpni双酶切步骤(2)中获得的阳性重组质粒,回收目的片段,再与同样双酶切的改造后的gv141空载体连接,构建gv141-ammecr1/ammecr1l融合表达载体,具体的连接反应体系与实施例2相同;然后通过测序验证序列的正确性,与基因序列比对结果表明,与插入的序列一致,符合预期要求,证明真核表达载体构建成功。
采用lipo3000转染试剂,在人类293t中过表达构建的两个重组质粒载体,分别采用flag和myc标签抗体检测所述构建的两个ammecr1和ammecr1l两个重组质粒载体,结果如图2所示,可以看出,ammecr1和ammecr1l两个重组质粒的蛋白大小分别为42kda和38kda,能够在gv141真核表达载体上稳定表达。
综上所述,选用gv141真核表达载体将ammecr1和ammecr1l基因克隆,且制备得到的载体可以用于各类细胞系中构建稳定表达此基因的细胞株,能够实现将ammecr1和ammecr1l基因在各类细胞系中持续稳定表达或者诱导表达。在本发明中,ammecr1和ammecr1l基因与gv141真核表达载体特异性的结合能达到良好的表达效果。
申请人声明,本发明通过上述实施例来说明本发明的详细方法,但本发明并不局限于上述详细方法,即不意味着本发明必须依赖上述详细方法才能实施。所属技术领域的技术人员应该明了,对本发明的任何改进,对本发明产品各原料的等效替换及辅助成分的添加、具体方式的选择等,均落在本发明的保护范围和公开范围之内。
序列表
<110>苏州大学附属儿童医院
<120>一种ammecr1和ammecr1l重组真核表达载体及其构建方法和应用
<130>2017
<160>4
<170>siposequencelisting1.0
<210>1
<211>1173
<212>dna
<213>人工合成序列()
<400>1
atggcggcgggttgctgcggggtgaagaagcagaaactgtccagttcgcccccctctggc60
tcgggtggcggtggtggcgcctcctcctcctcccactgcagcggagagagccagtgccga120
gctggggagctgggactaggaggcgccggtacgcggctcaacgggctgggaggtctaacc180
ggaggaggtagcggcagcggctgtaccctctctcccccccagggctgcggcggcggcggc240
ggggggatcgccctgtcgccacctccgagctgcggagtggggaccctactttctaccccg300
gccgccgccacctcttcctcaccctcctcatcgtccgccgcctcgtcctcatcgccgggc360
tcccggaagatggtggtgtcagcagagatgtgctgcttttgcttcgatgtgctctactgt420
cacctgtatggataccagcagccccggaccccccgattcaccaacgagccctacccactg480
tttgtaacatggaagattggtcgagacaaaagattacgtggatgcataggtactttttct540
gccatgaatttgcattcaggactcagggagtacacacttaccagtgcccttaaagatagc600
cgttttcccccaatgacaagggatgagctgccacggcttttctgctcagtgtctctgctc660
actaactttgaagatgtctgtgattatttggactgggaggtgggtgtacatggcattaga720
atagaattcatcaatgaaaaaggatcaaaacgcaccgccacctacctaccggaggttgca780
aaggagcaaggatgggaccatatacagaccatagactccttattgaggaaaggaggatac840
aaagctccgattactaatgaattcaggaaaaccataaaactgaccaggtatcgtagtgaa900
aagatgaccctgagctatgctgaataccttgctcatcgccagcatcatcatttccaaaat960
ggcattgggcatccccttccgccatacaaccattattcctacccttatgatgtcccagac1020
tatgcttcggtaccaagcttaagtgactacaaggatgacgatgacaaggattacaaagac1080
gacgatgataaggactataaggatgatgacgacaaatctagatagttaaaccgctgatca1140
gcctcgactgtgccttctagttgccagccatct1173
<210>2
<211>930
<212>dna
<213>人工合成序列()
<400>2
atgggaaaaagacgttgtgttcctccactcgagcccaagttggcagcaggctgttgtggg60
gtcaagaagcccaaattatctggaagtggaacgcacagtcacgggaatcagtccacaact120
gtccccggctctagttcaggacctcttcaaaaccaccagcatgtggacagcagcagtgga180
cgggagaatgtgtcagacttaactctgggacctggaaactctcccatcacacgaatgaat240
cccgcatcgggagcgctgagccctcttccccggcctaatggaactgccaacaccactaag300
aatctggtggtgactgcagagatgtgctgctactgcttcgacgtactctactgtcacctc360
tatggcttcccacagccacgacttcctagattcaccaatgacccctatccgctctttgtg420
acgtggaagacagggcgggacaagcggcttcgtggctgcattgggaccttctcagccatg480
aatcttcattcaggactcagggaatacacgttaaccagtgcacttaaggacagccgattt540
ccccccctgacccgagaggagctgcctaaacttttctgctctgtctccctccttactaac600
tttgaggatgccagtgattacctggactgggaggtaggggtccatgggattcgaattgaa660
ttcattaatgaaaaaggtgtcaaacgcacagccacatatttacctgaggttgctaaggaa720
caagactgggatcagatccagacaatagactccttgctcaggaaaggtggctttaaagct780
ccaattaccagtgaattcagaaaaacgatcaaactcaccaggtaccgaagtgagaaggtg840
acaatcagttacgcagagtatattgcttcccgacagcactgtttccagaacggcactctt900
catgccccgcccctctacaatcattactcc930
<210>3
<211>54
<212>dna
<213>人工合成序列()
<400>3
acgggccctctagactcgagcgccaccatggcggcgggttgctgcggggtgaag54
<210>4
<211>46
<212>dna
<213>人工合成序列()
<400>4
agtcacttaagcttggtaccgaagcatagtctgggacatcataagg46
- 还没有人留言评论。精彩留言会获得点赞!