靶向PD-1或PD-L1且靶向VEGF家族的双靶向融合蛋白及其用途的制作方法
本发明总体上涉及医药生物技术领域。具体地,本发明涉及靶向程序性死亡蛋白-1(programmeddeath-1(pd-1))或程序性死亡蛋白配体1(programmeddeath-1ligand(pd-l1))、且靶向血管内皮细胞生长因子(vascularendothelialcellgrowthfactor(vegf))家族这两者的双靶向融合蛋白、编码所述双靶向融合蛋白的多核苷酸、包含所述多核苷酸的载体、包含所述多核苷酸或载体的宿主细胞、以及所述双靶向融合蛋白在个体中治疗、预防和/或诊断与pd-1或pd-l1活性和vegf家族活性相关的疾病中的用途。
背景技术:
免疫检查点(immunecheckpoint)是免疫系统中存在的一类抑制性信号分子,通过调节外周组织中免疫反应的持续性和强度避免组织损伤,并参与维持对于自身抗原的耐受(pardolldm.,theblockadeofimmunecheckpointsincancerimmunotherapy.natrevcancer,2012,12(4):252-264)。研究发现,肿瘤细胞能够逃避体内免疫系统而失控增殖的原因之一是利用了免疫检查点的抑制性信号通路,由此抑制了t淋巴细胞活性,使得t淋巴细胞不能有效发挥对肿瘤的杀伤效应(yaos,zhuy和chenl.,advancesintargetingcellsurfacesignalingmoleculesforimmunemodulation.natrevdrugdiscov,2013,12(2):130-146)。
程序性死亡蛋白-1(pd-1)是一种重要的免疫检查点蛋白,目前也是肿瘤免疫治疗的一个重要靶标。pd-1在1992年首次被发现,对其基因的克隆和表达表明pd-1活化后能够诱导t细胞程序性死亡。在活化的t细胞、b细胞和髓样细胞上均发现存在pd-1蛋白。pd-1还诱导性地表达于巨噬细胞、树突状细胞以及单核细胞。在静息的淋巴细胞表面无pd-1表达。
pd-1是一种55kdai型跨膜蛋白,其胞浆区含有一个免疫受体酪氨酸抑制基序,与cd28和ctla-4具有同源性。已鉴定到pd-1的两种细胞表面糖蛋白配体,分别为程序性死亡蛋白配体1(pd-l1)和程序性死亡蛋白配体2(pd-l2)。已经在许多癌细胞上发现了pd-1的配体表达,包括人肺癌、卵巢癌、结肠癌和多种骨髓瘤。另外,在各类上皮癌、血液癌和其他恶性肿瘤细胞表面上高表达pd-1的配体。在肿瘤患者中,pd-1的配体如pd-l1的表达经常与癌的预后不良相关(iwaiy等人,involvementofpd-l1ontumorcellsintheescapefromhostimmunesystemandtumorimmunotherapybypd-l1blockade,pnas,2002,99(19):12293-7)。
pd-1与pd-1的配体的结合对于调节t淋巴细胞活性和维持外周免疫耐受发挥重要作用。pd-1与pd-1的配体结合后可导致t细胞凋亡、免疫无应答、t细胞“耗竭”和分泌il-10等。因此,pd-1发挥限制t细胞活化、抑制t细胞增殖和提高对抗原的耐受性的功能。活化的淋巴细胞表面pd-1的表达上调能够导致对获得性或者固有的免疫反应的抑制,由此导致了(包括t淋巴细胞在内的)肿瘤浸润性淋巴细胞虽然具有肿瘤抗原特异性,但由于肿瘤细胞上pd-1的配体与肿瘤浸润性淋巴细胞上的pd-1结合产生了抑制肿瘤浸润性淋巴细胞活化的信号,从而肿瘤细胞能够逃避免疫系统对肿瘤细胞的杀伤。
研究表明,这些表达pd-1的肿瘤浸润性淋巴细胞是功能障碍型淋巴细胞,所述淋巴细胞的生物学功能可以通过阻断pd-1与pd-1的配体结合的抗体恢复。目前,抑制pd-1与pd-1的配体结合的抗体主要包括抗pd-1单克隆抗体和抗pd-l1单克隆抗体,但也有针对pd-l2的产品。
当前,研究比较成熟的抗pd-1抗体有百时美施贵宝(bms)公司的纳武单抗(nivolumab)和默克(merck)公司的派姆单抗(pembrolizumab)。纳武单抗(商品名
虽然抗pd-1抗体、抗pd-l1抗体对肿瘤具有治疗效果,但它们平均的治疗有效率仅为20%左右,肺癌的五年生存率仅16%。仍有相当一部分的肿瘤患者对使用抗pd-1抗体、抗pd-l1抗体的治疗无应答。因此,如何提高肿瘤治疗的有效性仍是目前肿瘤治疗领域迫切需要解决的一个难题。
另一方面,肿瘤血管形成(angiogenesis)也是肿瘤快速生长的一个重要原因(ferraran和alitalok,clinicalapplicationsofangiogenicgrowthfactorsandtheirinhibitors,natmed.,1999;5(12):1359-64)。在肿瘤的表面和深处,到处都可以见到粗细不等的血管,生命的营养物质和氧气通过这些血管被运送至肿瘤组织。肿瘤血管形成是一个相当复杂的过程,受多种因子的正负调控。在这多种因子中,血管内皮细胞生长因子家族是一类作用最强的正性调控因子,发挥着刺激新生血管形成的功能。正常组织内血管内皮细胞生长因子和血管内皮细胞生长抑制因子同时存在,且保持相对平衡,这种平衡使得人体血管可以正常地生成和分化。但是,在肿瘤生长过程中,vegf家族分子数量激增,与血管生成抑制因子之间的调节失衡,由此,极大地促进了血管内皮细胞的分裂增殖和迁移、提高了血管通透性、抑制肿瘤细胞凋亡,为肿瘤的生长和转移提供了良好的微环境。
vegf家族包含六种密切相关的多肽,分别是高度保守的同源二聚体糖蛋白,有六个亚型:vegf-a、-b、-c、-d、-e、和胎盘生长因子(placentalgrowthfactor(plgf)),分子量从35至44kda不等。vegf-a(包括其剪接物如vegf165)的表达与一些实体瘤的微血管密度具有相关性,并且组织中vegf-a的浓度与乳腺癌、肺癌、前列腺癌和结肠癌等实体瘤的预后有关。每个vegf家族成员的生物学活性通过细胞表面vegf受体(vegfr)家族中的一种或多种介导,所述vegfr家族包括vegfr1(也称为flt-1)、vegfr2(也称为kdr、flk-1)、vegfr3(也称为flt-4)等,其中vegfr1、vegfr2与血管的生成关系密切,vegf-c/d/vegfr3则与淋巴管生成密切相关。vegf家族的主要生物学功能包括:(1)选择性促进血管内皮细胞有丝分裂,刺激内皮细胞增殖并促进血管形成;(2)提高血管尤其是微小血管的通透性,使血浆大分子外渗沉积在血管外的基质中,为肿瘤细胞的生长和新生毛细血管网的建立提供营养;(3)促进肿瘤的增殖和转移,所述肿瘤的增殖和转移依赖vegf家族使血管内皮细胞分泌胶原酶和纤溶酶原,借以降解血管基底膜,同时,肿瘤组织内部新形成的微血管基膜不完善,这种性质使肿瘤易于进入血循环;(4)其他作用:vegf家族可诱导上皮细胞出现间隙及开窗现象,可活化上皮细胞的胞质小泡及细胞器;vegf家族直接刺激内皮细胞释放蛋白水解酶,降解基质,释放更多的vegf家族分子,加速肿瘤的发展,细胞外蛋白酶又可激活细胞外基质的结合性和vegf家族的释放;vegf家族通过增加血管通透性使血浆蛋白(包括纤维蛋白原)释放,形成纤维素网络,为肿瘤生长、发展和转移提供了良好的基质;(5)vegf家族抑制机体的免疫反应,促进恶性肿瘤的浸润与转移(lapeyre-prosta等人,immunomodulatoryactivityofvegfincancer,intrevcellmolbiol.2017;330:295-342)。
在vegf家族中,胎盘生长因子(plgf)的40%氨基酸序列和vegf-a同源,参与病理状态下的新生血管和侧支血管的形成。plgf的生物学功能是通过特异结合其受体vegfr1/flt-1来激活的。vegfr1/flt-1具有很强的生物学活性,结合其配体后可介导内皮细胞与基质细胞的作用,也影响内皮细胞的分化成熟。plgf能促进早孕时滋养细胞增殖与分化,可诱导内皮细胞增殖、迁移,抗内皮细胞凋亡,并能增加血管的通透性,能增强低浓度vegf的生物学活性,是参与多种肿瘤血管生成的重要的促血管生长因子。过度的plgf表达导致肿瘤生长的增加和血管的存活。在原发肿瘤中观察到plgf在所有血管丰富的肿瘤中表达,而血管少的肿瘤只部分表达plgf。因此,plgf可用来解释脑部肿瘤血管新生的机制,而通过抑制plgf的生物学活性可以达到抑制肿瘤生长的目的。
临床研究显示利用单克隆抗体或可溶性vegfr能够阻断vegf家族与其受体的结合,阻碍vegf家族信号通路的传导也是目前治疗肿瘤的方法之一。基因泰克(genentech)公司研发的贝伐单抗(bevacizumab,商品名avastin)是一种重组的人鼠嵌合抗vegf抗体,可通过阻断vegf-a与vegfr的结合,使vegfr无法活化,由此发挥抗血管生成的作用。贝伐单抗目前用于一线治疗转移性结直肠癌,将来有可能用于转移性肺癌、乳癌、胰脏癌、肾脏癌等疾病的治疗。贝伐单抗也是开发较为成功的抗体药物之一。sanofi-aventis公司和regeneron公司研制的阿柏西普(aflibercept)是一种vegf-trap,其是将vegfr1胞外第2个结构域和vegfr2胞外第3个结构域与人igg1恒定区融合获得的一种融合蛋白,能通过抑制血管生成而对一部分肿瘤患者发挥抗肿瘤作用。
仍有大部分的肿瘤患者对目前可用的抗pd-1抗体、抗pd-l1抗体、抗vegf抗体或vegf-trap的单独治疗无反应。
鉴于免疫检查点蛋白pd-1、pd-l1在调节免疫应答中的重要性,以及vegf家族在肿瘤微环境中抑制抗肿瘤免疫和促进肿瘤血管形成的作用,本领域仍需要治疗肿瘤的备选疗法。优选地,这类备选疗法能够既靶向免疫抑制性蛋白pd-1或pd-l1,又靶向具有免疫抑制作用和促血管生成作用的vegf家族分子,从而导致免疫系统的激活和肿瘤血管的消退,从而对靶向pd-1或pd-l1的单一治疗无反应或者靶向vegf家族的单一治疗无反应的患者显示功效。这类备选疗法的一个方案是共施用靶向pd-1或pd-l1和靶向vegf家族分子的两种不同的生物制品。共施用需要注射两个独立的产品或单次注射两种不同蛋白的联合制剂。尽管两次注射允许给药量和给药时间的灵活性,但是它造成了患者不便依从和疼痛。另外,尽管联合制剂可能提供在给药量方面的某种灵活性,但它通常难以找到在溶液中允许两种蛋白的化学和物理稳定性的配制条件,原因在于两种蛋白的分子特征不同。另外,共施用和联合制剂两种不同药物的疗法可能增加患者和/或付款人的额外花费。因此,仍需要治疗肿瘤的备选疗法,并且优选地这类备选疗法包含靶向pd-1或pd-l1且靶向vegf家族的双靶向融合蛋白。
本发明提供了靶向pd-1或pd-l1且靶向vegf家族的双靶向新型融合蛋白,其能够抑制对pd-1途径或对pd-l1途径和对vegf家族信号传导途径的激活,并用于在个体中治疗、预防和/或诊断与pd-1、pd-l1活性和vegf家族活性相关的疾病。
发明概述
本发明公开了一种新型的靶向pd-1或pd-l1且靶向vegf家族的双靶向融合蛋白、编码所述双靶向融合蛋白的多核苷酸、包含所述多核苷酸的载体、包含所述多核苷酸或载体的宿主细胞、以及所述双靶向融合蛋白在个体中治疗、预防和/或诊断与pd-1、pd-l1活性和vegf家族活性相关的疾病中的用途。
因此,在一个方面,本发明提供了靶向pd-1或pd-l1且靶向vegf家族的双靶向融合蛋白,所述双靶向融合蛋白抑制pd-1与其配体的结合或抑制pd-l1与其受体的结合、且抑制vegf家族的信号传导途径,其包含(i)抗pd-1抗体或者抗pd-l1抗体;和(ii)与所述抗pd-1抗体或者抗pd-l1抗体有效连接的至少两个抑制vegf家族的结构域(vegfsfamiliyinhibitingdomain,下文中缩写为vid)。
在一个实施方案中,本发明的双靶向融合蛋白包含(i)抗pd-1抗体或者抗pd-l1抗体;和(ii)在所述抗pd-1抗体或者抗pd-l1抗体的两条重链中的每一重链的c端有效连接的一个vid,任选地,所述(i)和所述(ii)通过肽接头有效连接,由此,两个相同或者不同的vid各自在它们的n端氨基酸处与所述抗pd-1抗体或者抗pd-l1抗体的重链之一的c端氨基酸融合,任选地通过肽接头融合,优选地,所述vid包含vegf家族的受体的胞外结构域的一部分。
所述双靶向融合蛋白中包含的抗pd-1抗体可以是任何抗pd-1抗体,只要是能够抑制或减少pd-1与其配体结合的抗体即可,包括现有技术中已知的抗pd-1抗体和将来研发出的抗pd-1抗体。在一个实施方案中,所述抗pd-1抗体包含选自seqidno:1/2、3/4、5/6、7/8、9/10、11/12、13/14、15/16、17/18、19/20、21/22、23/24、和120/121的成对重链可变区序列/轻链可变区序列中所含的全部重链cdr与轻链cdr,优选地,所述抗pd-1抗体包含选自seqidno:1/2、3/4、5/6、7/8、9/10、11/12、13/14、15/16、17/18、19/20、21/22、23/24、和120/121的成对重链可变区序列/轻链可变区序列,或与所述成对重链可变区序列/轻链可变区序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列;更优选地,所述抗pd-1抗体包含选自纳武单抗、pidilizumab和派姆单抗的抗pd-1抗体的重链可变区和轻链可变区,特别地,所述抗pd-1抗体选自纳武单抗、pidilizumab和派姆单抗。
所述双靶向融合蛋白中包含的抗pd-l1抗体可以是任何抗pd-l1抗体,只要是能够抑制或减少pd-l1与其受体结合(例如与pd-1或cd80(b7-1)或与这两者结合)的抗体即可,包括现有技术中已知的抗pd-l1抗体和将来研发出的抗pd-l1抗体。在一个实施方案中,本发明融合蛋白中的抗pd-l1抗体包含选自seqidno:25/26、27/28和29/30的成对重链可变区序列/轻链可变区序列中所含的全部重链cdr与轻链cdr。优选地,所述抗pd-l1抗体包含选自seqidno:25/26、27/28和29/30的成对重链可变区序列/轻链可变区序列,或与所述成对重链可变区序列/轻链可变区序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列;更优选地,所述抗pd-l1抗体选自atezolizumab、avelumab和durvalumab。
在一个实施方案中,所述抗pd-1抗体或抗pd-l1抗体是igg类抗体,特别地是igg1亚类、igg2亚类、igg4亚类抗体。在一个优选的实施方案中,包含于本发明融合蛋白中的所述抗pd-1抗体或抗pd-l1抗体是igg4亚类抗体,特别地是人igg4亚类抗体。在一个实施方案中,所述igg4亚类抗体在fc区中第s228位置(eu编号)处包含氨基酸置换,特别是氨基酸置换s228p。seqidno:33中显示了示例性igg1亚类抗pd-1抗体的重链恒定区氨基酸序列。seqidno:34中显示了示例性igg2亚类抗pd-1抗体的重链恒定区氨基酸序列。seqidno:35中显示了示例性igg4亚类抗pd-1抗体的重链恒定区氨基酸序列。
在一个实施方案中,所述抗pd-1抗体或抗pd-l1抗体包含完全抗体的可变区和恒定区。本发明的双靶向融合蛋白中的抗体轻链恒定区型别可以是κ型或λ型,优选地是κ型。seqidno:31中显示了示例性抗pd-1抗体的κ型轻链恒定区氨基酸序列。seqidno:32中显示了示例性抗pd-1抗体的λ型轻链恒定区氨基酸序列。
所述双靶向融合蛋白中包含的vid包含vegf家族的受体的胞外结构域的一部分。在一个实施方案中,所述vid包含vegfr1的免疫球蛋白(ig)样结构域2(domain2,缩写为d2)和vegfr2的ig样结构域3(domain3,缩写为d3)。在一个具体实施方案中,所述vegfr1-d2/vegfr2-d3具有seqidno:63所示的氨基酸序列,或与seqidno:63的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多同一性的氨基酸序列。在一个实施方案中,所述vid包含vegfr1-d2以及vegfr2-d3和vegfr2的ig样结构域4(domain4,缩写为d4)。在一个具体实施方案中,所述vegfr1-d2/vegfr2-d3-d4具有seqidno:64所示的氨基酸序列,或与seqidno:64的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多同一性的氨基酸序列。在一个实施方案中,所述vid包含vegfr1-d2。在一个具体实施方案中,所述vegfr1-d2具有seqidno:65所示的氨基酸序列,或与seqidno:65的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多同一性的氨基酸序列。
在一个实施方案中,在所述抗pd-1抗体或抗pd-l1抗体的重链的c端连接所述vid的肽接头包含一个或多个氨基酸,优选地包含选自seqidno:36-62的肽接头。
在一个具体实施方案中,所述融合蛋白包含seqidno:73的抗pd-1抗体轻链亚基和seqidno:75的抗pd-1抗体重链-vid融合亚基,下文中称为融合蛋白by24.3。在一个具体实施方案中,所述融合蛋白包含seqidno:77的抗pd-1抗体轻链亚基和seqidno:79的抗pd-1抗体重链-vid融合亚基,下文中称为融合蛋白by24.7。在一个具体实施方案中,所述融合蛋白包含seqidno:81的抗pd-1抗体轻链亚基和seqidno:83的抗pd-1抗体重链-vid融合亚基,下文中称为融合蛋白by24.4。在一个具体实施方案中,所述融合蛋白包含seqidno:85的抗pd-1抗体轻链亚基和seqidno:87的抗pd-1抗体重链-vid融合亚基,下文中称为融合蛋白by24.5。在一个具体实施方案中,所述融合蛋白包含seqidno:89的抗pd-1抗体轻链亚基和seqidno:91的抗pd-1抗体重链-vid融合亚基,下文中称为融合蛋白by24.6。在一个具体实施方案中,所述融合蛋白包含seqidno:93的抗pd-1抗体轻链亚基和seqidno:95的抗pd-1抗体重链-vid融合亚基,下文中称为融合蛋白by24.8。在一个具体实施方案中,所述融合蛋白包含seqidno:97的抗pd-1抗体轻链亚基和seqidno:99的抗pd-1抗体重链-vid融合亚基,下文中称为融合蛋白by24.9。在一个具体实施方案中,所述融合蛋白包含seqidno:101的抗pd-1抗体轻链亚基和seqidno:103的抗pd-1抗体重链-vid融合亚基,下文中称为融合蛋白by24.10。在一个具体实施方案中,所述融合蛋白包含seqidno:105的抗pd-1抗体轻链亚基和seqidno:107的抗pd-1抗体重链-vid融合亚基,下文中称为融合蛋白by24.11。在一个具体实施方案中,所述融合蛋白包含seqidno:109的抗pd-1抗体轻链亚基和seqidno:111的抗pd-1抗体重链-vid融合亚基,下文中称为融合蛋白by24.12。在一个具体实施方案中,所述融合蛋白包含seqidno:113的抗pd-1抗体轻链亚基和seqidno:115的抗pd-1抗体重链-vid融合亚基,下文中称为融合蛋白by24.13。在一个具体实施方案中,所述融合蛋白包含seqidno:117的抗pd-1抗体轻链亚基和seqidno:119的抗pd-1抗体重链-vid融合亚基,下文中称为融合蛋白by24.14。
在一个具体实施方案中,所述融合蛋白包含(i)一个选自atezolizumab、avelumab和durvalumab的抗pd-l1抗体和(ii)在所述抗pd-l1抗体的两条重链中的每一重链的c端有效连接的一个vid分子。
在一个实施方案中,所述融合蛋白特异性地靶向pd-1或pd-l1和vegf家族分子,抑制由pd-1或pd-l1和vegf家族分子介导的信号传导。本发明的融合蛋白不仅在n端能高亲和性结合pd-1或pd-l1,而且在c端也能高亲和性地结合多种vegf因子。本发明所设计的融合蛋白的结构充分保证了该融合蛋白与两类靶标结合的合适物理空间距离,这种结构的融合蛋白与pd-1或pd-l1和vegf家族分子中的一种分子特异性结合后不影响该融合蛋白与pd-1或pd-l1和vegf家族分子中另一种分子的特异性结合。
本发明还提供了编码本发明融合蛋白的多核苷酸、包含编码本发明融合蛋白的多核苷酸的载体,优选地表达载体,最优选地具有双表达盒的谷氨酰胺合成酶表达载体。在另一个方面,本发明提供了包含本发明多核苷酸或载体的宿主细胞。本发明也提供了一种用于产生本发明融合蛋白的方法,包括步骤(i)在适于表达本发明融合蛋白的条件下培养本发明的宿主细胞,和(ii)回收本发明的融合蛋白。
在一个方面,本发明提供了一种包含本发明融合蛋白的诊断试剂盒和药物组合物。进一步地,还提供了本发明的融合蛋白、诊断试剂盒或药物组合物的用途,用于治疗、预防和/或诊断与pd-1或pd-l1活性和vegf家族活性相关的疾病,特别地用于治疗、预防和/或诊断癌性疾病(例如,实体瘤和软组织瘤),最特别地用于治疗、预防和/或诊断黑素瘤、乳腺癌、结肠癌、食管癌、胃肠道间质肿瘤(gist)、肾癌(例如,肾细胞癌)、肝癌、非小细胞肺癌(nsclc)、卵巢癌、胰腺癌、前列腺癌、头颈部肿瘤、胃癌、血液学恶性病(例如,淋巴瘤)。
除非另外限定,否则本文中所用的全部技术与科学术语具有如本发明所属领域的普通技术人员通常理解的相同含义。本文所提及的全部出版物、专利申请、专利和其他参考文献通过引用的方式完整地并入。此外,本文中所述的材料、方法和例子仅是说明性的并且不意在是限制性的。本发明的其他特征、目的和优点将从本说明书及附图并且从后附的权利要求书中显而易见。
附图简述
结合以下附图一起阅读时,将更好地理解以下详细描述的本发明的优选实施方案。出于说明本发明的目的,图中显示了目前优选的实施方案。然而,应当理解本发明不限于图中所示实施方案的精确安排和手段。
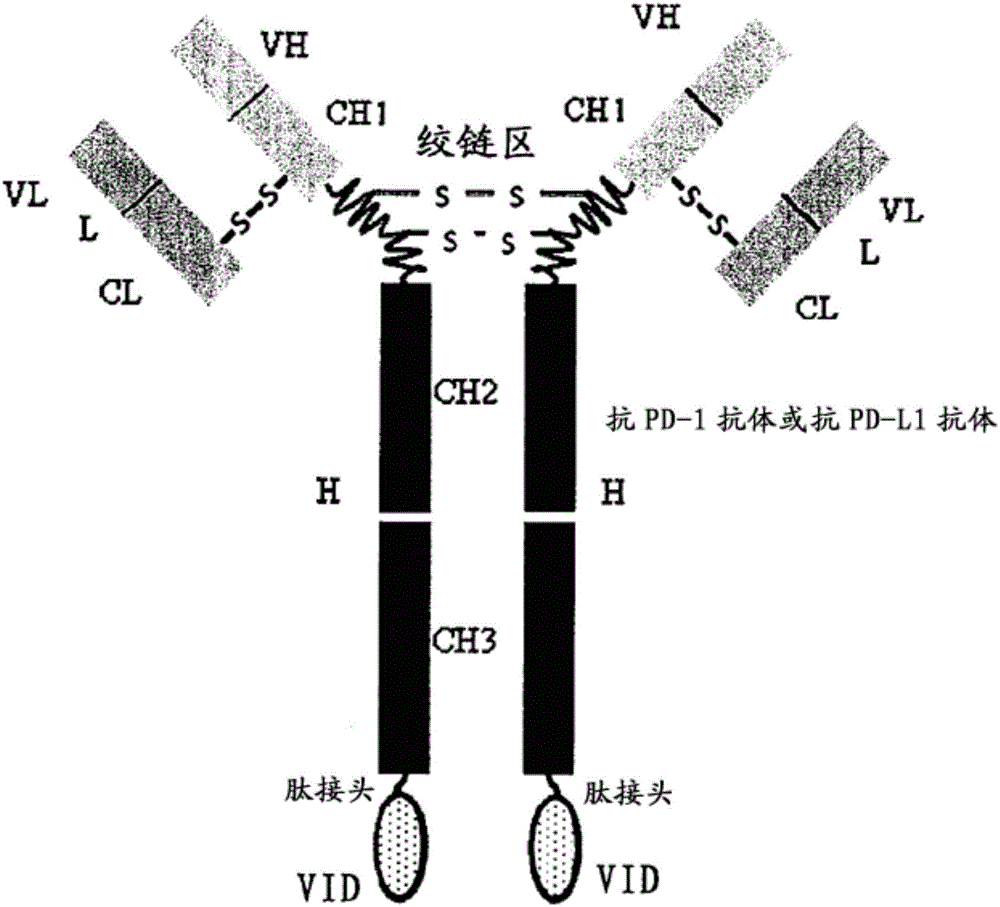
图1:例示了本发明的靶向pd-1或pd-l1且靶向vegf家族的双靶向融合蛋白的结构示意图。
图2:显示了实施例2中制备并纯化的本发明融合蛋白在还原剂(5mm1,4-二硫苏糖醇)存在下通过sds-page并用考马斯蓝染色后的结果。图2a中的泳道1:蛋白分子量标准标志物;泳道2:融合蛋白by24.3;泳道3:融合蛋白by24.4;泳道4:融合蛋白by24.5;泳道5:融合蛋白by24.6;泳道6:融合蛋白by24.8;泳道7:融合蛋白by24.9;泳道8:融合蛋白by24.10;泳道9:融合蛋白by24.11;图2b中的泳道1:蛋白分子量标准标志物;泳道2:融合蛋白by24.12;泳道3:融合蛋白by24.13;泳道4:融合蛋白by24.14;泳道5:抗体by18.1;泳道6:蛋白301-8;泳道7:融合蛋白by24.7。
图3:显示了本发明的融合蛋白by24.3、抗体by18.1和蛋白301-8对实验动物体重的影响。
图4:显示了将本发明的融合蛋白by24.3与抗体by18.1和蛋白301-8的体内抗肿瘤作用进行比较的示意图。
发明详述
本发明提供了阻断免疫检查点pd-1途径或pd-l1途径和vegf家族信号传导途径的融合蛋白和药物组合物。本发明还提供了用于产生该融合蛋白的方法,以及该融合蛋白在个体中治疗、预防和/或诊断与pd-1或pd-l1活性和vegf家族活性相关的疾病中的用途。
除非下文中另外定义,否则本说明书中的术语如本领域通常所用那样使用。
i.定义
术语“约”在与数字数值联合使用时意为涵盖具有比指定数字数值小5%的下限和比指定数字数值大5%的上限的范围内的数字数值。
如本文中所用,术语“包含”或“包括”意指包括所述的要素、整数或步骤,但是不排除任意其他要素、整数或步骤。
“pd-1途径”是指任何通过与pd-1结合而引发的细胞内信号传导途径,包括但不限于pd-1与pd-l1结合而引发的细胞内信号传导途径、或pd-1与pd-l2结合而引发的细胞内信号传导途径、或者pd-1与pd-l1和pd-l2这两者结合而引发的细胞内信号传导途径。
“pd-l1途径”是指任何通过与pd-l1结合而引发的细胞内信号传导途径,包括但不限于pd-l1与pd-1结合而引发的细胞内信号传导途径、或pd-l1与cd80(b7-1)结合而引发的细胞内信号传导途径、或者pd-l1与pd-1和cd80(b7-1)这两者结合而引发的细胞内信号传导途径。
如本文所用,术语“特异性结合”意指对抗原或目的分子的结合具有选择性并且可以与不想要的或非特异的相互作用区别。所述特异性结合可以通过酶联免疫吸附测定(elisa)或本领域技术人员熟悉的其他技术,例如表面等离子体共振(spr)技术(在biacore仪上分析)(liljeblad等人,analysisofagalacto-igginrheumatoidarthritisusingsurfaceplasmonresonance,glycoj.,2000,17,323-329)测量。
“亲和力”或“结合亲和力”指反映结合对子的成员之间相互作用的固有结合亲和力。分子x对其配偶物y的亲和力可以通常由解离常数(kd)代表,解离常数是解离速率常数和缔合速率常数(分别是koff和kon)的比例。亲和力可以由本领域已知的常见方法测量。用于测量亲和力的一个具体方法是表面等离子体共振法(spr)。
术语“抗体”在本文中以最广意义使用并且包括但不限于单克隆抗体、多克隆抗体、多特异性抗体(例如,双特异性抗体)、只要它们显示出所需的抗原结合活性即可。抗体可以是完整抗体分子,也可以是完整抗体分子的功能性片段,包括但不限于例如fab、f(ab')2。抗体的恒定区可以经改变(例如经突变)以修饰抗体特性(例如,以增加或减少以下一个或多个特性:抗体糖基化、半胱氨酸残基数目、效应细胞功能或补体功能)。
术语“全抗体”、“全长抗体”、“完全抗体”和“完整抗体”在本文中可互换地用来指这样的抗体,所述抗体具有基本上与天然抗体结构相似的结构。
术语“抗体重链”指在抗体分子中存在的两种类型多肽链中的较大者,其在正常情况下决定抗体所属的类别。
术语“抗体轻链”指在抗体分子中存在的两种类型多肽链中的较小者。κ轻链和λ轻链指两个主要的抗体轻链同种型。
氨基酸序列的“同一性百分数(%)”是指将候选序列与本说明书中所示的具体氨基酸序列进行比对并且如有必要的话为达到最大序列同一性百分数而引入空位后,并且不考虑任何保守置换作为序列同一性的一部分时,候选序列中与本说明书中所示的具体氨基酸序列的氨基酸残基相同的氨基酸残基百分数。
术语“有效连接”意指指定的各组分处于一种允许它们以预期的方式起作用的关系。
“信号序列”是连接至蛋白质的n-端部分的氨基酸的序列,其促进蛋白质分泌至细胞外。细胞外蛋白质的成熟形式没有信号序列,其在分泌过程期间被切除。
术语“n端”指n端的最末氨基酸,术语“c端”指c端的最末氨基酸。
术语“融合”指将两个或多个组分由肽键直接连接或借助一个或多个肽接头有效连接。
如本文所用,术语“融合蛋白”指包含抗体轻链亚基和抗体重链-vid融合亚基的融合多肽分子,其中抗体轻链亚基是融合蛋白中存在的多肽链中的较小者,抗体重链-vid融合亚基是融合蛋白中存在的多肽链中的较大者。
术语“宿主细胞”指已经向其中引入外源多核苷酸的细胞,包括这类细胞的子代。宿主细胞包括“转化体”和“转化的细胞”,这包括原代转化的细胞和从其衍生的子代。宿主细胞是可以用来产生本发明融合蛋白的任何类型的细胞系统。宿主细胞包括培养的细胞,也包括转基因动物、转基因植物或培养的植物组织或动物组织内部的细胞。
术语“个体”或“受试者”可互换地使用,是指哺乳动物。哺乳动物包括但不限于驯化动物(例如,奶牛、绵羊、猫、犬和马)、灵长类(例如,人和非人灵长类如猴)、兔和啮齿类(例如,小鼠和大鼠)。特别地,个体是人。
术语“治疗”指意欲改变正在接受治疗的个体中疾病之天然过程的临床介入。想要的治疗效果包括但不限于防止疾病出现或复发、减轻症状、减小疾病的任何直接或间接病理学后果、防止转移、降低病情进展速率、改善或缓和疾病状态,以及缓解或改善预后。在一些实施方案中,本发明的融合蛋白用来延缓疾病发展或用来减慢疾病的进展。
术语“抗肿瘤作用”指可以通过多种手段展示的生物学效果,包括但不限于例如,肿瘤体积减少、肿瘤细胞数目减少、肿瘤细胞增殖减少或肿瘤细胞存活减少。术语“肿瘤”和“癌症”在本文中互换地使用,涵盖实体瘤和液体肿瘤。
ii.融合蛋白
本发明提供了靶向pd-1或pd-l1且靶向vegf家族的双靶向融合蛋白,其包含(i)抗pd-1抗体或者抗pd-l1抗体;和(ii)与所述抗pd-1抗体或者抗pd-l1抗体有效连接的至少两个vid,其中融合蛋白的这两种组分彼此通过肽键直接或经肽接头连接。另外,融合蛋白中的组分(i)抗pd-1抗体或抗pd-l1抗体的各条肽链可以例如通过二硫键连接。
在一些实施方案中,本发明的融合蛋白是由二硫键键合的两条抗体轻链亚基和两条抗体重链-vid融合亚基组成的异四聚体糖蛋白。从n端至c端,每条抗体重链-vid融合亚基具有一个抗体重链,随后是一个vid,其中抗体重链和vid由肽键直接连接或借助一个或多个肽接头连接。
本发明的融合蛋白阻断免疫检查点pd-1途径或pd-l1途径且抑制vegf家族信号传导途径。该融合蛋白阻断的免疫检查点pd-1途径是pd-1与其配体结合所介导的信号传导途径。该融合蛋白阻断的pd-l1途径是pd-l1与其受体结合所介导的信号传导途径。该融合蛋白抑制的vegf家族信号传导途径是由vegf-a、-b、-c、-d、-e和plgf与vegf家族的受体(例如vegfr1、vegfr2和vegfr3)结合所介导的信号传导途径。
在一些实施方案中,本发明的融合蛋白以10-8m或更小、例如以10-9m至10-12m的解离常数(kd)与pd-1或pd-l1结合;且以10-8m或更小、例如以10-9m至10-12m的解离常数(kd)与vegf家族特异性结合。
-抗pd-1抗体或抗pd-l1抗体
本发明融合蛋白中包含的抗pd-1抗体或抗pd-l1抗体是由二硫键键合的两条轻链和两条重链组成的异四聚体糖蛋白。
在一个实施方案中,从n端至c端,每条抗pd-1抗体或抗pd-l1抗体的重链具有一个可变区(vh),也称作可变重链域或重链可变结构域,随后是三个恒定结构域(ch1、ch2和ch3),也称作重链恒定区。类似地,从n端至c端,每条抗pd-1抗体或抗pd-l1抗体的轻链具有一个可变区(vl),也称作可变轻链域或轻链可变结构域,随后一个恒定轻链(cl)结构域,也称作轻链恒定区。抗pd-1抗体或抗pd-l1抗体基本上由借助抗pd-1抗体或抗pd-l1抗体的铰链区连接的两个fab分子和一个fc结构域组成。
本发明融合蛋白中包含的抗pd-1抗体或抗pd-l1抗体能够以高的亲和力,例如以10-8m或更小、优选地以10-9m至10-12m的kd,分别与pd-1或pd-l1特异性结合,并由此阻断pd-1与配体pd-l1/pd-l2结合所介导的信号传导途径或阻断pd-l1与受体pd-1/cd80(b7-1)结合所介导的信号传导途径。
本文在下表1a中提供了本发明融合蛋白中包含的抗pd-1抗体的成对重链可变区(vh)和轻链可变区(vl)的例子。另外,本文在下表1b中提供了本发明融合蛋白中包含的抗pd-l1抗体的成对重链可变区(vh)和轻链可变区(vl)的例子。在一些实施方案中,本发明融合蛋白中的抗pd-1抗体或抗pd-l1抗体分别包含与表1a或表1b中所示的氨基酸序列基本上同一的序列,例如,与表1a或表1b所示的成对重链可变区序列/轻链可变区序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列。
表1a.融合蛋白中的抗pd-1抗体的重链可变区和轻链可变区序列的例子
表1b.融合蛋白中的抗pd-l1抗体的重链可变区和轻链可变区序列的例子
在一个实施方案中,本发明融合蛋白中的抗pd-1抗体包含选自seqidno:1/2、3/4、5/6、7/8、9/10、11/12、13/14、15/16、17/18、19/20、21/22、23/24、和120/121的成对重链可变区序列/轻链可变区序列中所含的全部重链cdr与轻链cdr。在一个实施方案中,本发明融合蛋白中的抗pd-l1抗体包含选自seqidno:25/26、27/28和29/30的成对重链可变区序列/轻链可变区序列中所含的全部重链cdr与轻链cdr。用于鉴定重链可变区与轻链可变区的氨基酸序列中的cdr的方法及技术为本领域中已知的,且可用于鉴定本文公开的特定重链可变区及/或轻链可变区的氨基酸序列中的cdr。可用于鉴定cdr边界的示例性公知技术包括例如kabat界定法、chothia界定法以及abm界定法。参见,例如kabat,sequencesofproteinsofimmunologicalinterest,nationalinstitutesofhealth,bethesda,md.(1991);al-lazikani等人,standardconformationsforthecanonicalstructuresofimmunoglobulins.,j.mol.biol.273:927-948(1997);以及martinac等人,modelingantibodyhypervariableloops:acombinedalgorithm,proc.natl.acad.sci.usa86:9268-9272(1989)。
本发明融合蛋白中的抗pd-1抗体或抗pd-l1抗体可以基于其轻链恒定区的氨基酸序列而划分为κ型或λ型,优选为κ型。
本文在下表2中提供了本发明融合蛋白中的抗pd-1抗体轻链恒定区的氨基酸序列的例子。
表2.融合蛋白中的抗pd1抗体轻链恒定区序列的例子
本发明融合蛋白中的抗pd-1抗体或抗pd-l1抗体基于其重链恒定区的氨基酸序列优选地是igg类抗体,特别地是igg1亚类、igg2亚类、igg4亚类抗体,更特别地是igg4亚类抗体。优选地,所述igg4亚类抗pd-1抗体或抗pd-l1抗体在fc区中第s228位置处包含防止发生臂交换(arm-exchange)的氨基酸置换,特别地是氨基酸置换s228p。
本文在下表3中提供了本发明融合蛋白中的抗pd-1抗体重链恒定区的氨基酸序列的例子。
表3.融合蛋白中的抗pd1抗体重链恒定区序列的例子
-抑制vegf家族的结构域(vid)
本发明融合蛋白中的“抑制vegf家族的结构域(vid)”包含vegfr的胞外结构域的一部分。vegfr受体是位于细胞表面的一种酪氨酸激酶受体,其胞外区由7个免疫球蛋白(ig)样结构域组成。例如,人vegfr1包含编号为1、2、3、4、5、6和7的七个ig样结构域,ig样结构域1在胞外结构域的n端,ig样结构域7在胞外结构域的c端。除非本文另外指出,否则ig样结构域从vegfr蛋白的n端至c端顺序编号。在一些实施方案中,vid包含选自vegfr1、vegfr2和vegfr3的一种或多种vegfr的至少一个ig样结构域。在一些方面,vid包含vegfr的至少1、2、3、4、5、6个但不超过7个ig样结构域。在另一方面,vid包含vegfr的1至7、1至6、1至5、1至4、1至3或1至2个ig样结构域。
本文还考虑了包含两种或多种vegfr的至少一个ig样结构域的vid。在一些实施方案中,vid包含来自两种或多种选自vegfr1、vegfr2和vegfr3的vegfr的至少一个ig样结构域。本文考虑了包含每种vegfr的七个ig样结构域的任意组合的vid。例如,vid可以包含vegfr1(例如人vegfr1)的ig样结构域2和vegfr2(例如人vegfr2)的ig样结构域3。在另一实施方案中,vid可以包含vegfr1(例如人vegfr1)的ig样结构域1-3、vegfr1(例如人vegfr1)的ig样结构域2-3、vegfr2(例如人vegfr2)的ig样结构域1-3、vegfr1(例如人vegfr1)的ig样结构域2和vegfr2(例如人vegfr2)的ig样结构域3-4,或vegfr1(例如人vegfr1)的ig样结构域2和vegfr3(例如人vegfr3)的ig样结构域3。这些ig样结构域和其他可以用作vid的部分的ig样结构域的更详细描述见美国专利号7531173;yudc等,solublevascularendothelialgrowthfactordecoyreceptorfp3exertspotentantiangiogeniceffects,mol.ther.,2012,20(3):938-947和holash,j.等,vegf-trap:avegfblockerwithpotentantitumoreffects,pnas,2002,99(17):11393-11398,全部文献在此以其整体引入作为参考。在一些实施方案中,vid具有任一选自表4中seqidno:63-65所示的氨基酸序列或与seqidno:63-65所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多同一性的氨基酸序列。
表4融合蛋白中的vid氨基酸序列的例子
本发明融合蛋白中包含的vid能够以高的亲和力,例如以10-8m或更小、优选地以10-9m至10-12m的kd,与vegf家族特异性结合,并由此抑制vegf家族与细胞表面vegfr的结合和随后的信号传导。
-肽接头
本发明融合蛋白中在抗pd-1抗体或抗pd-l1抗体的重链c端和vidn端任选包含的“肽接头”是一个或多个氨基酸、一般约2-20个氨基酸的肽。本领域已知或本文中描述了肽接头。
在一些实施方案中,所述肽接头包含至少5个氨基酸,优选地包含选自akttpkleegefsear(seqidno:36);akttpkleegefsearv(seqidno:37);akttpklgg(seqidno:38);sakttpklgg(seqidno:39);sakttp(seqidno:40);radaap(seqidno:41);radaaptvs(seqidno:42);radaaaaggpgs(seqidno:43);radaaaa(seqidno:44);sakttpkleegefsearv(seqidno:45);adaap(seqidno:46);daaptvsifpp(seqidno:47);tvaap(seqidno:48);tvaapsvfifpp(seqidno:49);qpkaap(seqidno:50);qpkaapsvtlfpp(seqidno:51);akttpp(seqidno:52);akttppsvtplap(seqidno:53);akttap(seqidno:54);akttapsvyplap(seqidno:55);astkgp(seqidno:56);astkgpsvfplap(seqidno:57);ggggsggggsggggs(seqidno:58);genkveyapalmals(seqidno:59);gpakeltplkeakvs(seqidno:60);gheaaavmqvqypas(seqidno:61);和ggggsggggsggggsa(seqidno:62)的肽接头。
iii.本发明的双靶向融合蛋白的生产和纯化
本发明的双靶向融合蛋白可以例如通过固态肽合成(例如merrifield固相合成)或重组生产获得。为了重组生产,将编码所述双靶向融合蛋白的抗体轻链亚基的多核苷酸和/或编码所述双靶向融合蛋白的抗体重链-vid融合亚基的多核苷酸分离并插入一个或多个载体中以便进一步在宿主细胞中克隆和/或表达。使用常规方法,可以轻易地分离所述多核苷酸并将其测序。在一个实施方案中,提供了包含本发明的一种或多种多核苷酸的载体,优选地表达载体。
可以使用本领域技术人员熟知的方法来构建表达载体。表达载体包括但不限于病毒、质粒、粘粒、λ噬菌体或酵母人工染色体(yac)。在一个优选的实施方案中,使用了具有双表达盒的谷氨酰胺合成酶高效表达载体。
一旦已经制备了用于表达的包含本发明的一种或多种多核苷酸的表达载体,则可以将表达载体转染或引入适宜的宿主细胞中。多种技术可以用来实现这个目的,例如,原生质体融合、磷酸钙沉淀、电穿孔、逆转录病毒的转导、病毒转染、基因枪、基于脂质体的转染或其他常规技术。
在一个实施方案中,提供了包含一种或多种本发明多核苷酸的宿主细胞。在一些实施方案中,提供了包含本发明表达载体的宿主细胞。如本文所用,术语“宿主细胞”指可以工程化以产生本发明的双靶向融合蛋白的任何种类的细胞系统。适于复制和支持本发明的双靶向融合蛋白表达的宿主细胞是本领域熟知的。根据需要,这类细胞可以用特定表达载体转染或转导,并且可以培育大量含有载体的细胞用于接种大规模发酵器以获得足够量的本发明双靶向融合蛋白用于临床应用。合适的宿主细胞包括原核微生物,如大肠杆菌,真核微生物如丝状真菌或酵母,或各种真核细胞,如中国仓鼠卵巢细胞(cho)、昆虫细胞等。可以使用适于悬浮培养的哺乳动物细胞系。有用的哺乳动物宿主细胞系的例子包括sv40转化的猴肾cv1系(cos-7);人胚肾系(293或293f细胞)、幼仓鼠肾细胞(bhk)、猴肾细胞(cv1)、非洲绿猴肾细胞(vero-76)、人宫颈癌细胞(hela)、犬肾细胞(mdck)、布法罗大鼠肝脏细胞(brl3a)、人肺细胞(w138)、人肝脏细胞(hepg2)、cho细胞、骨髓瘤细胞系如yo、ns0、p3x63和sp2/0等。适于产生蛋白质的哺乳动物宿主细胞系的综述参见例如yazaki和wu,methodsinmolecularbiology,第248卷(b.k.c.lo编著,humanapress,totowa,nj),第255-268页(2003)。
本领域已知在这些宿主细胞系统中表达外源基因的标准技术。在一个实施方案中,提供了产生本发明的双靶向融合蛋白的方法,其中所述方法包括在适于表达所述双靶向融合蛋白的条件下培养如本文中提供的宿主细胞,所述宿主细胞包含编码所述双靶向融合蛋白的多核苷酸,并且从宿主细胞(或宿主细胞培养基)回收所述双靶向融合蛋白。
如本文所述制备的双靶向融合蛋白可以通过已知的现有技术如高效液相色谱、离子交换层析、凝胶电泳、亲和层析、大小排阻层析等纯化。用来纯化特定蛋白质的实际条件还取决于如净电荷、疏水性、亲水性等因素,并且这些对本领域技术人员是显而易见的。
可以通过多种熟知分析方法中的任一种方法确定本发明的双靶向融合蛋白的纯度,所述熟知分析方法包括凝胶电泳、高效液相色谱等。可以通过本领域已知的多种测定法,鉴定、筛选或表征本文提供的双靶向融合蛋白的物理/化学特性和/或生物学活性。
iv.药物组合物和试剂盒
在另一个方面,本发明提供了组合物,例如,药物组合物,所述组合物包含与可药用载体配制在一起的本文所述的双靶向融合蛋白。如本文所用,“可药用载体”包括生理上相容的任何和全部溶剂、分散介质、等渗剂和吸收延迟剂等。本发明的药物组合物适于静脉内、肌内、皮下、肠胃外、直肠、脊髓或表皮施用(例如,通过注射或输注)。
本发明的组合物可以处于多种形式。这些形式例如包括液体、半固体和固体剂型,如液态溶液剂(例如,可注射用溶液剂和可输注溶液剂)、分散体剂或混悬剂、脂质体剂和栓剂。优选的形式取决于预期的施用模式和治疗用途。常见的优选组合物处于可注射用溶液剂或可输注溶液剂形式。优选的施用模式是肠胃外(例如,静脉内、皮下、腹腔(i.p.)、肌内)注射。在一个优选实施方案中,通过静脉内输注或注射施用双靶向融合蛋白。在另一个优选实施方案中,通过肌内、腹腔或皮下注射施用双靶向融合蛋白。
如本文所用的短语“肠胃外施用“和“肠胃外方式施用”意指除了肠施用和局部施用之外的施用模式,通常通过注射施用,并且包括但不限于静脉内、肌内、动脉内、皮内、腹腔、经气管、皮下注射和输注。
治疗性组合物一般应当是无菌的并且在制造和储存条件下稳定。可以将组合物配制为溶液、微乳液、分散体、脂质体或冻干形式。可以通过将活性化合物(即双靶向融合蛋白)以要求的量加入适宜的溶剂中,随后过滤消毒,制备无菌可注射溶液剂。通常,通过将所述活性化合物并入无菌溶媒中来制备分散体,所述无菌溶媒含有基础分散介质和其他成分。可以使用包衣剂如卵磷脂等。在分散体的情况下,可以通过使用表面活性剂来维持溶液剂的适宜流动性。可以通过在组合物中包含延迟吸收的物质例如单硬脂酸盐和明胶而引起可注射组合物的延长吸收。
在某些实施方案中,可以口服施用本发明的双靶向融合蛋白,例如随惰性稀释剂或可食用载体一起经口施用。本发明的双靶向融合蛋白也可以封闭在硬壳或软壳明胶胶囊中、压缩成片剂或直接掺入受试者的膳食中。对于口服治疗施用,所述化合物可以随赋形剂一起掺入并且以可摄取的片剂、颊用片剂、锭剂(troche)、胶囊剂、酏剂、混悬剂、糖浆剂、糯米纸囊剂(wafer)等形式使用。为了通过非肠胃外施用方法施用本发明的双靶向融合蛋白,可能需要将所述双靶向融合蛋白与防止其失活的材料包衣或随这种材料共施用。还可以用本领域已知的医疗装置施用治疗组合物。
本发明的药物组合物可以包含“治疗有效量”或“预防有效量”的本发明所述双靶向融合蛋白。“治疗有效量”指以需要的剂量并持续需要的时间段,有效实现所需治疗结果的量。可以根据多种因素如疾病状态、个体的年龄、性别和重量等变动治疗有效量。治疗有效量是任何有毒或有害作用不及治疗有益作用的量。相对于未治疗的受试者,“治疗有效量”优选地抑制可度量参数(例如肿瘤生长率)至少约20%、更优选地至少约40%、甚至更优选地至少约60%和仍更优选地至少约80%。可以在预示人肿瘤中的功效的动物模型系统中评价本发明的双靶向融合蛋白抑制可度量参数(例如,肿瘤体积)的能力。
“预防有效量”指以需要的剂量并持续需要的时间段,有效实现所需预防结果的量。通常,由于预防性剂量在受试者中在疾病较早阶段之前或在疾病较早阶段使用,故预防有效量小于治疗有效量。
包含本文所述双靶向融合蛋白的试剂盒也处于本发明的范围内。试剂盒可以包含一个或多个其他要素,例如包括:使用说明书;其他试剂,例如标记物或用于偶联的试剂;可药用载体;和用于施用至受试者的装置或其他材料。
v.双靶向融合蛋白的用途
本文公开的双靶向融合蛋白具有体外和体内诊断用途以及治疗性和预防性用途。例如,可以将这些分子施用至体外或离体的培养细胞或施用至受试者,例如,人类受试者,以治疗、预防和/或诊断多种与pd-1活性、pd-l1活性和vegf家族活性相关的疾病,例如癌症。
在一个方面,本发明提供了体外或体内检测生物样品,例如血清、精液或尿或组织活检样品(例如,来自过度增生性或癌性病灶)中存在pd-1或pd-l1和vegf家族分子的诊断方法。该诊断方法包括:(i)在允许相互作用发生的条件下使样品(和任选地,对照样品)与如本文所述的双靶向融合蛋白接触或向受试者施用所述双靶向融合蛋白和(ii)检测所述双靶向融合蛋白和样品(和任选地,对照样品)之间复合物的形成。复合物的形成表示存在pd-1或pd-l1和vegf家族分子,并且可以显示本文所述治疗和/或预防的适用性或需求。
在一些实施方案中,在治疗之前,例如,在起始治疗之前或在治疗间隔后的某次治疗之前检测pd-1或pd-l1和vegf家族分子。可以使用的检测方法包括免疫组织化学、免疫细胞化学、facs、elisa测定、pcr-技术(例如,rt-pcr)或体内成像技术。一般地,体内和体外检测方法中所用的双靶向融合蛋白直接或间接地用可检测物质标记以促进检测结合的或未结合的结合物。合适的可检测物质包括多种生物学活性酶、辅基、荧光物质、发光物质、顺磁(例如,核磁共振活性)物质和放射性物质。
在一些实施方案中,体内确定pd-1或pd-l1和vegf家族分子的水平和/或分布,例如,以非侵入方式确定(例如,通过使用合适的成像技术(例如,正电子发射断层摄影术(pet)扫描)检测可检测物标记的本发明双靶向融合蛋白。在一个实施方案中,例如,通过检测用pet试剂(例如,18f-氟脱氧葡萄糖(fdg))以可检测方式标记的本发明双靶向融合蛋白,体内测定pd-1或pd-l1和vegf家族分子的水平和/或分布。
在一个实施方案中,本发明提供了包含本文所述双靶向融合蛋白和使用说明书的诊断试剂盒。
在另一个方面,本发明涉及使用双靶向融合蛋白体内用来治疗或预防需要在受试者中增强免疫应答并减少血管形成的疾病,从而抑制或减少相关疾病如癌性肿瘤的生长或出现、转移或复发。可以单独使用双靶向融合蛋白以抑制癌性肿瘤的生长或者预防其出现。备选地,双靶向融合蛋白可以与其他癌症治疗剂/预防剂组合施用。当本发明的双靶向融合蛋白与一种或多种其他药物组合施用时,这种组合可以按任何顺序施用或者同时施用。
因此,在一个实施方案中,本发明提供一种抑制受试者中肿瘤细胞生长的方法,所述方法包括向受试者施用治疗有效量的本文所述的双靶向融合蛋白。在另一个实施方案中,本发明提供一种防止受试者中肿瘤细胞出现或者转移或者复发的方法,所述方法包括向受试者施用预防有效量的本文所述的双靶向融合蛋白。
在一些实施方案中,用双靶向融合蛋白治疗和/或预防的癌包括但不限于实体瘤、血液学癌(例如,白血病、淋巴瘤、骨髓瘤,例如,多发性骨髓瘤)及转移性病灶。在一个实施方案中,癌是实体瘤。实体瘤的例子包括恶性肿瘤,例如,多个器官系统的肉瘤和癌,如侵袭肺、乳房、卵巢、淋巴样、胃肠道的(例如,结肠)、肛门、生殖器和生殖泌尿道(例如,肾、膀胱上皮、膀胱细胞、前列腺)、咽、cns(例如,脑、神经的或神经胶质细胞)、头和颈、皮肤(例如,黑素瘤)、鼻咽(例如,分化或未分化的转移性或局部复发性鼻咽癌)和胰的那些癌、以及腺癌,包括恶性肿瘤,如结肠癌、直肠癌、肾细胞癌、肝癌、非小细胞肺癌、小肠癌和食道癌。癌症可以处于早期、中期或晚期或是转移性癌。
在一些实施方案中,癌选自黑素瘤、乳腺癌、结肠癌、食管癌、胃肠道间质肿瘤(gist)、肾癌(例如,肾细胞癌)、肝癌、非小细胞肺癌(nsclc)、卵巢癌、胰腺癌、前列腺癌、头颈部肿瘤、胃癌、血液学恶性病(例如,淋巴瘤)。
描述以下实施例以辅助对本发明的理解。不意在且不应当以任何方式将实施例解释成限制本发明的保护范围。
实施例
实施例1、包含目的基因的谷氨酰胺合成酶高效表达载体的构建
(1)作为对照的抗pd1抗体by18.1的编码核苷酸的合成及表达载体的构建
根据internationalnonproprietaryname(inn)数据库中编号为9623的纳武单抗的氨基酸序列数据,优化为适合在中国仓鼠卵巢癌细胞(cho)中表达的下述核苷酸序列,并委托上海捷瑞生物工程有限公司合成该核苷酸序列。所述核苷酸序列表达后产生的抗pd1抗体在本文中表示为抗体by18.1。
抗pd1抗体by18.1的轻链(by18.1l)核苷酸序列(seqidno:66):
ctcgaggccaccatggagaccgacacactcctcctgtgggtgctgctgctgtgggtgcctggctccactggcgagattgtgctgacacagtcccccgctactctgagcctgagccctggcgagagggctacactgtcttgcagagcttctcagtccgtgtcttcttacctcgcttggtatcagcagaagcccggccaggctccaagactgctgatctatgacgcttctaaccgcgctacaggcattcctgctaggttcagcggcagcggctctggcaccgacttcacactcacaattagctctcttgaacctgaggacttcgccgtgtactactgccagcagtctagcaactggcctagaacattcggccagggcactaaggtggagattaagagaaccgtggccgcccccagcgtgttcatcttccctcccagcgacgagcagctgaagtctggcaccgccagcgtggtgtgcctgctgaacaacttctacccccgcgaggccaaggtgcagtggaaggtggacaacgccctgcagagcggcaacagccaggagagcgtgaccgagcaggactccaaggacagcacctacagcctgagcagcaccctgaccctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccaccagggactgtctagccccgtgaccaagagcttcaaccggggcgagtgctaagaattc
抗pd1抗体by18.1的轻链(by18.1l)氨基酸序列(seqidno:67):
metdtlllwvlllwvpgstgeivltqspatlslspgeratlscrasqsvssylawyqqkpgqaprlliydasnratgiparfsgsgsgtdftltisslepedfavyycqqssnwprtfgqgtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
抗pd1抗体by18.1的重链(by18.1h)核苷酸序列(seqidno:68):
tctagagccaccatggagaccgacaccctgctgctgtgggtgctgctcctgtgggtgcctggctccacaggccaggtgcagctcgtggagtccggcggcggcgtggtgcagcccggcagatccctcagactggactgcaaggcatccggcattacattctctaactctggaatgcactgggtgagacaggctcctggcaagggcctggaatgggtggccgtgatttggtacgacggctctaagagatactacgctgactccgtgaagggccggttcacaattagcagagacaactccaagaacactctgttcctccagatgaacagcctgagagccgaggacaccgctgtgtactactgcgccaccaacgacgactactggggccagggcaccctcgtgacagtgtcttccgcctccaccaagggcccttccgtgttccctctggccccttgctcccgctccacctccgagtccaccgccgccctgggctgcctggtgaaggactacttccctgagcctgtgaccgtgtcctggaactccggcgccctgacctccggcgtgcacaccttccctgccgtgctgcagtcctccggcctgtactccctgtcctccgtggtgaccgtgccttcctcctccctgggcaccaagacctacacctgcaacgtggaccacaagccttccaacaccaaggtggacaagcgcgtggagtccaagtacggccctccttgccctccttgccctgcccctgagttcctgggcggcccttccgtgttcctgttccctcctaagcctaaggacaccctgatgatctcccgcacccctgaggtgacctgcgtggtggtggacgtgtcccaggaggaccctgaggtgcagttcaactggtacgtggacggcgtggaggtgcacaacgccaagaccaagcctcgcgaggagcagttcaactccacctaccgcgtggtgtccgtgctgaccgtgctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtgtccaacaagggcctgccttcctccatcgagaagaccatctccaaggccaagggccagcctcgcgagcctcaggtgtacaccctgcctccttcccaggaggagatgaccaagaaccaggtgtccctgacctgcctggtgaagggcttctacccttccgacatcgccgtggagtgggagtccaacggccagcctgagaacaactacaagaccacccctcctgtgctggactccgacggctccttcttcctgtactcccgcctgaccgtggacaagtcccgctggcaggagggcaacgtgttctcctgctccgtgatgcacgaggccctgcacaaccactacacccagaagtccctgtccctgtccctgggcaagtaagtcgac
抗pd1抗体by18.1的重链(by18.1h)氨基酸序列(seqidno:69):
metdtlllwvlllwvpgstgqvqlvesgggvvqpgrslrldckasgitfsnsgmhwvrqapgkglewvaviwydgskryyadsvkgrftisrdnskntlflqmnslraedtavyycatnddywgqgtlvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcppcpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslgk
其中带下划线部分“metdtlllwvlllwvpgstg”为信号肽序列。
上海捷瑞生物工程有限公司合成了上述by18.1l编码核苷酸序列和by18.1h编码核苷酸序列。分别将by18.1l编码核苷酸用xhoi-ecori双酶切,将具有双表达盒的谷氨酰胺合成酶高效表达载体(专利授权号:cn104195173b,获自北京比洋生物技术有限公司)用xhoi-ecori双酶切,再通过连接酶将经xhoi-ecori双酶切的by18.1l编码核苷酸连接入经xhoi-ecori双酶切的具有双表达盒的谷氨酰胺合成酶高效表达载体,获得已导入了by18.1l编码核苷酸的具有双表达盒的谷氨酰胺合成酶高效表达载体;然后,分别将by18.1h编码核苷酸用xbai-sali双酶切,将已导入了by18.1l编码核苷酸的具有双表达盒的谷氨酰胺合成酶高效表达载体用xbai-sali双酶切,再通过连接酶将经xbai-sali双酶切的by18.1h编码核苷酸连接入经xbai-sali双酶切的已导入了by18.1l编码核苷酸的具有双表达盒的谷氨酰胺合成酶高效表达载体,由此获得了已导入by18.1l编码核苷酸和by18.1h编码核苷酸的具有双表达盒的谷氨酰胺合成酶高效表达载体,经测序验证正确后表达,获得抗pd1抗体by18.1。
备选地,也可以将by18.1l编码核苷酸连接入已导入了by18.1h编码核苷酸的具有双表达盒的谷氨酰胺合成酶高效表达载体,表达并获得抗体by18.1。
(2)作为对照的蛋白301-8编码核苷酸的合成及表达载体构建
根据internationalnonproprietaryname(inn)数据库中编号为8739的阿柏西普(aflibercept)的氨基酸序列数据,优化为适合在中国仓鼠卵巢癌细胞(cho)中表达的下述核苷酸序列,并委托上海捷瑞生物工程有限公司合成该核苷酸序列。所述核苷酸序列表达后产生的蛋白产物在本文中表示为蛋白301-8。
蛋白301-8的编码核苷酸序列(seqidno:70):
aagcttgccaccatggagaccgacaccctgctgctctgggtgctgctgctctgggtgcccggctccaccggatccgacaccggccgccctttcgtggagatgtactccgagatccctgagatcatccacatgaccgagggccgcgagctggtgatcccttgccgcgtgacctcccctaacatcaccgtgaccctgaagaagttccctctggacaccctgatccctgacggcaagcgcatcatctgggactcccgcaagggcttcatcatctccaacgccacctacaaggagatcggcctgctgacctgcgaggccaccgtgaacggccacctgtacaagaccaactacctgacccaccgccagaccaacaccatcatcgacgtggtgctgtccccttcccacggcatcgagctgtccgtgggcgagaagctggtgctgaactgcaccgcccgcaccgagctgaacgtgggcatcgacttcaactgggagtacccttcctccaagcaccagcacaagaagctggtgaaccgcgacctgaagacccagtccggctccgagatgaagaagttcctgtccaccctgaccatcgacggcgtgacccgctccgaccagggcctgtacacctgcgccgcctcctccggcctgatgaccaagaagaactccaccttcgtgcgcgtgcacgagaaggataagacccatacatgtcccccatgccccgctccagaactgctgggcggaccttccgtgtttctgttcccacccaaaccaaaggacacactgatgatcagcagaacccctgaggtgacttgcgtggtcgtggacgtgagccatgaggaccccgaggtgaagttcaactggtatgtggatggcgtggaagtgcataatgccaagacaaaacctagggaagagcagtacaacagcacctacagggtggtgagcgtgctgaccgtgctgcaccaggattggctgaacggcaaggaatacaagtgcaaggtgtccaataaggctctgcctgcacctatcgagaagaccatcagcaaagccaagggccaacccagagagcctcaagtctacaccctgcccccaagcagggatgagctgaccaaaaatcaagtgagcctgacatgcctggtcaaaggcttctaccctagcgacatcgccgtggagtgggagagcaatggccagcctgagaacaactacaagaccactccccccgtcctggatagcgacggcagcttcttcctgtactccaaactgacagtcgataaaagcaggtggcagcaaggcaatgtctttagctgtagcgtgatgcacgaggccctgcataaccactacactcaaaagtccctgtccctgagccccgga
蛋白301-8的氨基酸序列(seqidno:71):
metdtlllwvlllwvpgstgsdtgrpfvemyseipeiihmtegrelvipcrvtspnitvtlkkfpldtlipdgkriiwdsrkgfiisnatykeiglltceatvnghlyktnylthrqtntiidvvlspshgielsvgeklvlnctartelnvgidfnweypsskhqhkklvnrdlktqsgsemkkflstltidgvtrsdqglytcaassglmtkknstfvrvhekdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsrdeltknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspg
分别将蛋白301-8的编码核苷酸序列用xhoi-ecori双酶切,将具有双表达盒的谷氨酰胺合成酶高效表达载体(专利授权号:cn104195173b,获自北京比洋生物技术有限公司)用xhoi-ecori双酶切,再通过连接酶将经xhoi-ecori双酶切的蛋白301-8编码核苷酸连接入经xhoi-ecori双酶切的具有双表达盒的谷氨酰胺合成酶高效表达载体,获得已导入了蛋白301-8的编码核苷酸序列的具有双表达盒的谷氨酰胺合成酶高效表达载体。经测序验证正确后用于表达,所表达的蛋白命名为蛋白301-8。蛋白301-8的氨基酸序列与现有技术中公开的阿柏西普的氨基酸序列相同。
(3)pd-1和vegf家族的双靶向融合蛋白编码核苷酸的合成及表达载体的构建
根据表1a中抗pd-1抗体的重链可变区和轻链可变区序列、表2中抗体的轻链恒定区序列、表3中抗体的重链恒定区序列、表4中的vid序列、以及seqidno:36-62的肽接头序列,优化为适合在中国仓鼠卵巢癌细胞(cho)中表达的核苷酸序列,并委托上海捷瑞生物工程有限公司合成如下seqidno:72-118中偶数编号所示的多核苷酸序列。
融合蛋白by24.3(κ,igg4)的轻链亚基(by24.3l)核苷酸序列(seqidno:72):
ctcgaggccaccatggagaccgacacactcctcctgtgggtgctgctgctgtgggtgcctggctccactggcgagattgtgctgacacagtcccccgctactctgagcctgagccctggcgagagggctacactgtcttgcagagcttctcagtccgtgtcttcttacctcgcttggtatcagcagaagcccggccaggctccaagactgctgatctatgacgcttctaaccgcgctacaggcattcctgctaggttcagcggcagcggctctggcaccgacttcacactcacaattagctctcttgaacctgaggacttcgccgtgtactactgccagcagtctagcaactggcctagaacattcggccagggcactaaggtggagattaagagaaccgtggccgcccccagcgtgttcatcttccctcccagcgacgagcagctgaagtctggcaccgccagcgtggtgtgcctgctgaacaacttctacccccgcgaggccaaggtgcagtggaaggtggacaacgccctgcagagcggcaacagccaggagagcgtgaccgagcaggactccaaggacagcacctacagcctgagcagcaccctgaccctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccaccagggactgtctagccccgtgaccaagagcttcaaccggggcgagtgctaagaattc
融合蛋白by24.3(κ,igg4)的轻链亚基(by24.3l)氨基酸序列(seqidno:73):metdtlllwvlllwvpgstgeivltqspatlslspgeratlscrasqsvssylawyqqkpgqaprlliydasnratgiparfsgsgsgtdftltisslepedfavyycqqssnwprtfgqgtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
融合蛋白by24.3(κ,igg4)的重链-vid融合亚基(by24.3h)核苷酸序列(seqidno:74):
tctagagccaccatggagaccgacaccctgctgctgtgggtgctgctcctgtgggtgcctggctccacaggccaggtgcagctcgtggagtccggcggcggcgtggtgcagcccggcagatccctcagactggactgcaaggcatccggcattacattctctaactctggaatgcactgggtgagacaggctcctggcaagggcctggaatgggtggccgtgatttggtacgacggctctaagagatactacgctgactccgtgaagggccggttcacaattagcagagacaactccaagaacactctgttcctccagatgaacagcctgagagccgaggacaccgctgtgtactactgcgccaccaacgacgactactggggccagggcaccctcgtgacagtgtcttccgcctccaccaagggcccttccgtgttccctctggccccttgctcccgctccacctccgagtccaccgccgccctgggctgcctggtgaaggactacttccctgagcctgtgaccgtgtcctggaactccggcgccctgacctccggcgtgcacaccttccctgccgtgctgcagtcctccggcctgtactccctgtcctccgtggtgaccgtgccttcctcctccctgggcaccaagacctacacctgcaacgtggaccacaagccttccaacaccaaggtggacaagcgcgtggagtccaagtacggccctccttgccctccttgccctgcccctgagttcctgggcggcccttccgtgttcctgttccctcctaagcctaaggacaccctgatgatctcccgcacccctgaggtgacctgcgtggtggtggacgtgtcccaggaggaccctgaggtgcagttcaactggtacgtggacggcgtggaggtgcacaacgccaagaccaagcctcgcgaggagcagttcaactccacctaccgcgtggtgtccgtgctgaccgtgctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtgtccaacaagggcctgccttcctccatcgagaagaccatctccaaggccaagggccagcctcgcgagcctcaggtgtacaccctgcctccttcccaggaggagatgaccaagaaccaggtgtccctgacctgcctggtgaagggcttctacccttccgacatcgccgtggagtgggagtccaacggccagcctgagaacaactacaagaccacccctcctgtgctggactccgacggctccttcttcctgtactcccgcctgaccgtggacaagtcccgctggcaggagggcaacgtgttctcctgctccgtgatgcacgaggccctgcacaaccactacacccagaagtccctgtccctgtccctgggcggcggaggatctggcggcggaggcagtggaggcggcggaagcgcttccgacaccggccgccctttcgtggagatgtactccgagatccctgagatcatccacatgaccgagggccgcgagctggtgatcccttgccgcgtgacctcccctaacatcaccgtgaccctgaagaagttccctctggacaccctgatccctgacggcaagcgcatcatctgggactcccgcaagggcttcatcatctccaacgccacctacaaggagatcggcctgctgacctgcgaggccaccgtgaacggccacctgtacaagaccaactacctgacccaccgccagaccaacaccatcatcgacgtggtgctgtccccttcccacggcatcgagctgtccgtgggcgagaagctggtgctgaactgcaccgcccgcaccgagctgaacgtgggcatcgacttcaactgggagtacccttcctccaagcaccagcacaagaagctggtgaaccgcgacctgaagacccagtccggctccgagatgaagaagttcctgtccaccctgaccatcgacggcgtgacccgctccgaccagggcctgtacacctgcgccgcctcctccggcctgatgaccaagaagaactccaccttcgtgcgcgtgcacgagaagtaagtcgac
融合蛋白by24.3(κ,igg4)的重链-vid融合亚基(by24.3h)氨基酸序列(seqidno:75):
metdtlllwvlllwvpgstgqvqlvesgggvvqpgrslrldckasgitfsnsgmhwvrqapgkglewvaviwydgskryyadsvkgrftisrdnskntlflqmnslraedtavyycatnddywgqgtlvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcppcpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslggggsggggsggggsasdtgrpfvemyseipeiihmtegrelvipcrvtspnitvtlkkfpldtlipdgkriiwdsrkgfiisnatykeiglltceatvnghlyktnylthrqtntiidvvlspshgielsvgeklvlnctartelnvgidfnweypsskhqhkklvnrdlktqsgsemkkflstltidgvtrsdqglytcaassglmtkknstfvrvhek
融合蛋白by24.7(κ,igg2)的轻链亚基(by24.7l)核苷酸序列(seqidno:76):
ctcgaggccaccatggagaccgacacactcctcctgtgggtgctgctgctgtgggtgcctggctccactggcgagatcaagcggaccgtggccgccccatccgtgttcattttcccaccttccgagattgtgctgacacagtcccccgctactctgagcctgagccctggcgagagggctacactgtcttgcagagcttccaagggcgtgagcacatccggctactcctacctccactggtatcagcagaagccaggccaggccccaagactgctgatatacctcgcttcttacttagagtctggcgtgcccgctcggttcagcggctccggctctggcaccgacttcaccctgacaatttctagcctggagcccgaggacttcgccgtgtactactgccagcactctagggacctgcctctcacattcggcggcggcactaaggtggagattaagagaaccgtggccgcccccagcgtgttcatcttccctcccagcgacgagcagctgaagtctggcaccgccagcgtggtgtgcctgctgaacaacttctacccccgcgaggccaaggtgcagtggaaggtggacaacgccctgcagagcggcaacagccaggagagcgtgaccgagcaggactccaaggacagcacctacagcctgagcagcaccctgaccctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccaccagggactgtctagccccgtgaccaagagcttcaaccggggcgagtgctaagaattc
融合蛋白by24.7(κ,igg2)的轻链亚基(by24.7l)氨基酸序列(seqidno:77):
metdtlllwvlllwvpgstgeivltqspatlslspgeratlscraskgvstsgysylhwyqqkpgqaprlliylasylesgvparfsgsgsgtdftltisslepedfavyycqhsrdlpltfgggtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
融合蛋白by24.7(κ,igg2)的重链-vid融合亚基(by24.7h)核苷酸序列(seqidno:78):
tctagagccaccatggagaccgacaccctgctgctgtgggtgctgctcctgtgggtgcctggctccacaggccaggtgcagctcgtgcagtctggcgtggaggtgaagaagcctggcgcctctgtgaaggtgtcttgcaaggcttccggctacactttcactaactactacatgtactgggtgagacaggctcccggccagggcctagagtggatgggcggcattaaccctagcaacggcggcacaaacttcaacgagaagttcaagaaccgcgtgaccctgaccacagactctagcacaacaactgcttacatggagctgaagtctctccagttcgacgacaccgctgtgtactactgcgctcggagggactacagattcgacatgggcttcgactactggggccagggcaccactgtgacagtgtctacagcctccaccaagggcccttccgtgttccctctggccccttgctcccgctccacctccgagtccaccgccgccctgggctgcctggtgaaggactacttccctgagcctgtgaccgtgtcctggaactccggcgccctgacctccggcgtgcacaccttccctgccgtgctgcagtcctccggcctgtactccctgtcctccgtggtgaccgtgccttcctccaacttcggcacccagacatacacatgcaacgtggaccacaagccttctaacacaaaggtggacaagaccgtggagcggaagtgctgcgtggagtgcccaccttgccccgctcctcctgtggccggcccttctgtgttcctgttcccacctaagccaaaggacacactcatgatcagcagaacccctgaggtgacctgcgtggtggtggacgtgagccacgaggaccccgaggtgcagttcaactggtatgtggacggcgtggaggtgcacaacgctaagaccaagcctagagaagaacagttcaacagcacattcagagtggtgtccgtgctcaccgtggtgcaccaggactggctgaacggcaaagagtacaagtgcaaggtgtccaacaagggcctgccagcccctatcgaaaaaacaatcagcaagaccaagggccagcctagagagcctcaggtgtacacactgcctccatctcgggaagaaatgacaaagaaccaggtgtccctcacatgcctcgtgaagggcttctacccatccgacatcgctgtggagtgggagtctaacggccagcccgagaacaactacaagaccacccctcctatgctcgactccgacggctctttcttcctgtactctaagctgaccgtggacaagtccagatggcagcagggcaacgtgttctcttgcagcgtgatgcacgaggctctccacaaccactacacccagaagtccctgagcctgtctccaggcggcggaggatctggcggcggaggcagtggaggcggcggaagcgcttccgacaccggccgccctttcgtggagatgtactccgagatccctgagatcatccacatgaccgagggccgcgagctggtgatcccttgccgcgtgacctcccctaacatcaccgtgaccctgaagaagttccctctggacaccctgatccctgacggcaagcgcatcatctgggactcccgcaagggcttcatcatctccaacgccacctacaaggagatcggcctgctgacctgcgaggccaccgtgaacggccacctgtacaagaccaactacctgacccaccgccagaccaacacctaagtcgac
融合蛋白by24.7(κ,igg2)的重链-vid融合亚基(by24.7h)氨基酸序列(seqidno:79):
metdtlllwvlllwvpgstgqvqlvqsgvevkkpgasvkvsckasgytftnyymywvrqapgqglewmgginpsnggtnfnekfknrvtlttdsstttaymelkslqfddtavyycarrdyrfdmgfdywgqgttvtvstastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssnfgtqtytcnvdhkpsntkvdktverkccvecppcpappvagpsvflfppkpkdtlmisrtpevtcvvvdvshedpevqfnwyvdgvevhnaktkpreeqfnstfrvvsvltvvhqdwlngkeykckvsnkglpapiektisktkgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppmldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspggggsggggsggggsasdtgrpfvemyseipeiihmtegrelvipcrvtspnitvtlkkfpldtlipdgkriiwdsrkgfiisnatykeiglltceatvnghlyktnylthrqtnt
融合蛋白by24.4(κ,igg4)的轻链亚基(by24.4l)核苷酸序列(seqidno:80):
ctcgaggccaccatggagaccgacacactcctcctgtgggtgctgctgctgtgggtgcctggctccactggcgagatcgtgctgacacagagtcctagttccctgagcgcatccgtcggcgatagggtgactatcacttgtagcgcacgcagtagcgtgtcttacatgcactggtttcagcagaagcccggcaaggcacccaagctgtggatctaccggaccagtaacctcgcctctggagtgccatccaggtttagtggctccggaagtggaacttcttactgcctcacaattaatagtctccagcccgaggattttgcaacatactactgtcagcagcggtctagctttcccctgacattcggcggaggcactaaggtggagattaagagaaccgtggccgcccccagcgtgttcatcttccctcccagcgacgagcagctgaagtctggcaccgccagcgtggtgtgcctgctgaacaacttctacccccgcgaggccaaggtgcagtggaaggtggacaacgccctgcagagcggcaacagccaggagagcgtgaccgagcaggactccaaggacagcacctacagcctgagcagcaccctgaccctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccaccagggactgtctagccccgtgaccaagagcttcaaccggggcgagtgctaagaattc
融合蛋白by24.4(κ,igg4)的轻链亚基(by24.4l)氨基酸序列(seqidno:81):metdtlllwvlllwvpgstgeivltqspsslsasvgdrvtitcsarssvsymhwfqqkpgkapklwiyrtsnlasgvpsrfsgsgsgtsycltinslqpedfatyycqqrssfpltfgggtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
融合蛋白by24.4(κ,igg4)的重链-vid融合亚基(by24.4h)核苷酸序列(seqidno:82):
tctagagccaccatggagaccgacaccctgctgctgtgggtgctgctcctgtgggtgcctggctccacaggccaggtgcagctggtccagagcggaagcgagcttaagaagcctggagcatctgtcaagattagttgtaaggcaagtggctacacatttaccaactacggaatgaattgggtgcgccaggcacccggacagggcctccagtggatgggatggatcaataccgatagcggcgagtctacatacgctgaggagtttaagggccggttcgtgttcagtctcgatacaagcgtgaacacagcttacctccaaatcacttctctgactgctgaggacaccggcatgtacttttgcgtccgcgtcggctacgacgcactcgattactggggacagggcaccctcgtgacagtgtcttccgcctccaccaagggcccttccgtgttccctctggccccttgctcccgctccacctccgagtccaccgccgccctgggctgcctggtgaaggactacttccctgagcctgtgaccgtgtcctggaactccggcgccctgacctccggcgtgcacaccttccctgccgtgctgcagtcctccggcctgtactccctgtcctccgtggtgaccgtgccttcctcctccctgggcaccaagacctacacctgcaacgtggaccacaagccttccaacaccaaggtggacaagcgcgtggagtccaagtacggccctccttgccctccttgccctgcccctgagttcctgggcggcccttccgtgttcctgttccctcctaagcctaaggacaccctgatgatctcccgcacccctgaggtgacctgcgtggtggtggacgtgtcccaggaggaccctgaggtgcagttcaactggtacgtggacggcgtggaggtgcacaacgccaagaccaagcctcgcgaggagcagttcaactccacctaccgcgtggtgtccgtgctgaccgtgctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtgtccaacaagggcctgccttcctccatcgagaagaccatctccaaggccaagggccagcctcgcgagcctcaggtgtacaccctgcctccttcccaggaggagatgaccaagaaccaggtgtccctgacctgcctggtgaagggcttctacccttccgacatcgccgtggagtgggagtccaacggccagcctgagaacaactacaagaccacccctcctgtgctggactccgacggctccttcttcctgtactcccgcctgaccgtggacaagtcccgctggcaggagggcaacgtgttctcctgctccgtgatgcacgaggccctgcacaaccactacacccagaagtccctgtccctgtccctgggcggcggaggatctggcggcggaggcagtggaggcggcggaagcgcttccgacaccggccgccctttcgtggagatgtactccgagatccctgagatcatccacatgaccgagggccgcgagctggtgatcccttgccgcgtgacctcccctaacatcaccgtgaccctgaagaagttccctctggacaccctgatccctgacggcaagcgcatcatctgggactcccgcaagggcttcatcatctccaacgccacctacaaggagatcggcctgctgacctgcgaggccaccgtgaacggccacctgtacaagaccaactacctgacccaccgccagaccaacaccatcatcgacgtggtgctgtccccttcccacggcatcgagctgtccgtgggcgagaagctggtgctgaactgcaccgcccgcaccgagctgaacgtgggcatcgacttcaactgggagtacccttcctccaagcaccagcacaagaagctggtgaaccgcgacctgaagacccagtccggctccgagatgaagaagttcctgtccaccctgaccatcgacggcgtgacccgctccgaccagggcctgtacacctgcgccgcctcctccggcctgatgaccaagaagaactccaccttcgtgcgcgtgcacgagaagtaagtcgac
融合蛋白by24.4(κ,igg4)的重链-vid融合亚基(by24.4h)氨基酸序列(seqidno:83):
metdtlllwvlllwvpgstgqvqlvqsgselkkpgasvkisckasgytftnygmnwvrqapgqglqwmgwintdsgestyaeefkgrfvfsldtsvntaylqitsltaedtgmyfcvrvgydaldywgqgtlvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcppcpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslggggsggggsggggsasdtgrpfvemyseipeiihmtegrelvipcrvtspnitvtlkkfpldtlipdgkriiwdsrkgfiisnatykeiglltceatvnghlyktnylthrqtntiidvvlspshgielsvgeklvlnctartelnvgidfnweypsskhqhkklvnrdlktqsgsemkkflstltidgvtrsdqglytcaassglmtkknstfvrvhek
融合蛋白by24.5(κ,igg4)的轻链亚基(by24.5l)核苷酸序列(seqidno:84):
ctcgaggccaccatggagaccgacacactcctcctgtgggtgctgctgctgtgggtgcctggctccactggcgacattcagatgacccagtctccaagctctctgagcgcttccgtgggcgaccgcgtgacaattacatgcctcgcatctcagaccattggcacctggctgacatggtatcagcagaagcctggcaaggcccctaagctgctgatttacaccgctacctccctcgccgacggcgtgccatctaggttctctggctccggctccggcacagacttcacactcactatttcttccctccagcccgaggacttcgccacatactactgccagcaggtgtactctatcccttggactttcggcggcggcactaaggtggagattaagagaaccgtggccgcccccagcgtgttcatcttccctcccagcgacgagcagctgaagtctggcaccgccagcgtggtgtgcctgctgaacaacttctacccccgcgaggccaaggtgcagtggaaggtggacaacgccctgcagagcggcaacagccaggagagcgtgaccgagcaggactccaaggacagcacctacagcctgagcagcaccctgaccctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccaccagggactgtctagccccgtgaccaagagcttcaaccggggcgagtgctaagaattc
融合蛋白by24.5(κ,igg4)的轻链亚基(by24.5l)氨基酸序列(seqidno:85):metdtlllwvlllwvpgstgdiqmtqspsslsasvgdrvtitclasqtigtwltwyqqkpgkapklliytatsladgvpsrfsgsgsgtdftltisslqpedfatyycqqvysipwtfgggtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
融合蛋白by24.5(κ,igg4)的重链-vid融合亚基(by24.5h)核苷酸序列(seqidno:86):
tctagagccaccatggagaccgacaccctgctgctgtgggtgctgctcctgtgggtgcctggctccacaggcgaggtccagctcgtcgagagtggaggcggcctcgtgcagcccggcggaagcctcagactgtcttgtgctgcatctggcttcactttctctagttacatgatgagttgggtgagacaggcaccaggaaagggattggagtgggtcgcaacaatcagtggcggaggagcaaacacatactaccccgatagcgtcaagggacggttcaccattagtcgcgataacgctaagaactccctgtaccttcagatgaatagtctccgcgctgaggataccgccgtgtactactgcgcacggcagctctactacttcgattactggggccagggcaccctcgtgacagtgtcttccgcctccaccaagggcccttccgtgttccctctggccccttgctcccgctccacctccgagtccaccgccgccctgggctgcctggtgaaggactacttccctgagcctgtgaccgtgtcctggaactccggcgccctgacctccggcgtgcacaccttccctgccgtgctgcagtcctccggcctgtactccctgtcctccgtggtgaccgtgccttcctcctccctgggcaccaagacctacacctgcaacgtggaccacaagccttccaacaccaaggtggacaagcgcgtggagtccaagtacggccctccttgccctccttgccctgcccctgagttcctgggcggcccttccgtgttcctgttccctcctaagcctaaggacaccctgatgatctcccgcacccctgaggtgacctgcgtggtggtggacgtgtcccaggaggaccctgaggtgcagttcaactggtacgtggacggcgtggaggtgcacaacgccaagaccaagcctcgcgaggagcagttcaactccacctaccgcgtggtgtccgtgctgaccgtgctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtgtccaacaagggcctgccttcctccatcgagaagaccatctccaaggccaagggccagcctcgcgagcctcaggtgtacaccctgcctccttcccaggaggagatgaccaagaaccaggtgtccctgacctgcctggtgaagggcttctacccttccgacatcgccgtggagtgggagtccaacggccagcctgagaacaactacaagaccacccctcctgtgctggactccgacggctccttcttcctgtactcccgcctgaccgtggacaagtcccgctggcaggagggcaacgtgttctcctgctccgtgatgcacgaggccctgcacaaccactacacccagaagtccctgtccctgtccctgggcggcggaggatctggcggcggaggcagtggaggcggcggaagcgcttccgacaccggccgccctttcgtggagatgtactccgagatccctgagatcatccacatgaccgagggccgcgagctggtgatcccttgccgcgtgacctcccctaacatcaccgtgaccctgaagaagttccctctggacaccctgatccctgacggcaagcgcatcatctgggactcccgcaagggcttcatcatctccaacgccacctacaaggagatcggcctgctgacctgcgaggccaccgtgaacggccacctgtacaagaccaactacctgacccaccgccagaccaacaccatcatcgacgtggtgctgtccccttcccacggcatcgagctgtccgtgggcgagaagctggtgctgaactgcaccgcccgcaccgagctgaacgtgggcatcgacttcaactgggagtacccttcctccaagcaccagcacaagaagctggtgaaccgcgacctgaagacccagtccggctccgagatgaagaagttcctgtccaccctgaccatcgacggcgtgacccgctccgaccagggcctgtacacctgcgccgcctcctccggcctgatgaccaagaagaactccaccttcgtgcgcgtgcacgagaagtaagtcgac
融合蛋白by24.5(κ,igg4)的重链-vid融合亚基(by24.5h)氨基酸序列(seqidno:87):
metdtlllwvlllwvpgstgevqlvesggglvqpggslrlscaasgftfssymmswvrqapgkglewvatisgggantyypdsvkgrftisrdnaknslylqmnslraedtavyycarqlyyfdywgqgtlvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcppcpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslggggsggggsggggsasdtgrpfvemyseipeiihmtegrelvipcrvtspnitvtlkkfpldtlipdgkriiwdsrkgfiisnatykeiglltceatvnghlyktnylthrqtntiidvvlspshgielsvgeklvlnctartelnvgidfnweypsskhqhkklvnrdlktqsgsemkkflstltidgvtrsdqglytcaassglmtkknstfvrvhek
融合蛋白by24.6(κ,igg2)的轻链亚基(by24.6l)核苷酸序列(seqidno:88):
ctcgaggccaccatggagaccgacacactcctcctgtgggtgctgctgctgtgggtgcctggctccactggcaatattcagatgacccagagtcctagtagcctgagcgcatccgtcggcgaccgcgtgaccattacatgtaaggccggacagaacgtgaataattacctcgcttggtatcagcagaagccaggcaaggctccaaaggtgctcatcttcaatgctaacagtctccagactggcgtcccttcccggtttagtggaagtggatctggcaccgatttcacactcactatcagttctttgcaacccgaggattttgccacatactactgtcagcagtacaatagctggacaactttcggcggaggaactaaggtggagattaagagaaccgtggccgcccccagcgtgttcatcttccctcccagcgacgagcagctgaagtctggcaccgccagcgtggtgtgcctgctgaacaacttctacccccgcgaggccaaggtgcagtggaaggtggacaacgccctgcagagcggcaacagccaggagagcgtgaccgagcaggactccaaggacagcacctacagcctgagcagcaccctgaccctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccaccagggactgtctagccccgtgaccaagagcttcaaccggggcgagtgctaagaattc
融合蛋白by24.6(κ,igg2)的轻链亚基(by24.6l)氨基酸序列(seqidno:89):metdtlllwvlllwvpgstgniqmtqspsslsasvgdrvtitckagqnvnnylawyqqkpgkapkvlifnanslqtgvpsrfsgsgsgtdftltisslqpedfatyycqqynswttfgggtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
融合蛋白by24.6(κ,igg2)的重链-vid融合亚基(by24.6h)核苷酸序列(seqidno:90):
tctagagccaccatggagaccgacaccctgctgctgtgggtgctgctcctgtgggtgcctggctccacaggccaggtcacactcaaggagtccggcccagctctcgtgaagcctacacagaccctcactctcacctgtacattcagcggatttagcctgagcacttctggaacatgcgtgtcttggattcggcagccacccggaaaggcactcgaatggctcgcaaccatctgttgggaggacagtaagggctacaatccatctctgaagtctaggctgacaattagtaaggacacctccaagaatcaggccgtgctgactatgactaatatggaccccgtcgataccgccacatactactgcgctagacgcgaggatagtggctacttttggtttccttactggggccagggaaccctcgtgacagtgtcttccgcctccaccaagggcccttccgtgttccctctggccccttgctcccgctccacctccgagtccaccgccgccctgggctgcctggtgaaggactacttccctgagcctgtgaccgtgtcctggaactccggcgccctgacctccggcgtgcacaccttccctgccgtgctgcagtcctccggcctgtactccctgtcctccgtggtgaccgtgccttcctcctccctgggcaccaagacctacacctgcaacgtggaccacaagccttccaacaccaaggtggacaagcgcgtggagtccaagtacggccctccttgccctccttgccctgcccctgagttcctgggcggcccttccgtgttcctgttccctcctaagcctaaggacaccctgatgatctcccgcacccctgaggtgacctgcgtggtggtggacgtgtcccaggaggaccctgaggtgcagttcaactggtacgtggacggcgtggaggtgcacaacgccaagaccaagcctcgcgaggagcagttcaactccacctaccgcgtggtgtccgtgctgaccgtgctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtgtccaacaagggcctgccttcctccatcgagaagaccatctccaaggccaagggccagcctcgcgagcctcaggtgtacaccctgcctccttcccaggaggagatgaccaagaaccaggtgtccctgacctgcctggtgaagggcttctacccttccgacatcgccgtggagtgggagtccaacggccagcctgagaacaactacaagaccacccctcctgtgctggactccgacggctccttcttcctgtactcccgcctgaccgtggacaagtcccgctggcaggagggcaacgtgttctcctgctccgtgatgcacgaggccctgcacaaccactacacccagaagtccctgtccctgtccctgggcggcggaggatctggcggcggaggcagtggaggcggcggaagcgcttccgacaccggccgccctttcgtggagatgtactccgagatccctgagatcatccacatgaccgagggccgcgagctggtgatcccttgccgcgtgacctcccctaacatcaccgtgaccctgaagaagttccctctggacaccctgatccctgacggcaagcgcatcatctgggactcccgcaagggcttcatcatctccaacgccacctacaaggagatcggcctgctgacctgcgaggccaccgtgaacggccacctgtacaagaccaactacctgacccaccgccagaccaacaccatcatcgacgtggtgctgtccccttcccacggcatcgagctgtccgtgggcgagaagctggtgctgaactgcaccgcccgcaccgagctgaacgtgggcatcgacttcaactgggagtacccttcctccaagcaccagcacaagaagctggtgaaccgcgacctgaagacccagtccggctccgagatgaagaagttcctgtccaccctgaccatcgacggcgtgacccgctccgaccagggcctgtacacctgcgccgcctcctccggcctgatgaccaagaagaactccaccttcgtgcgcgtgcacgagaagtaagtcgac
融合蛋白by24.6(κ,igg2)的重链-vid融合亚基(by24.6h)氨基酸序列(seqidno:91):
metdtlllwvlllwvpgstgqvtlkesgpalvkptqtltltctfsgfslstsgtcvswirqppgkalewlaticwedskgynpslksrltiskdtsknqavltmtnmdpvdtatyycarredsgyfwfpywgqgtlvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcppcpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslggggsggggsggggsasdtgrpfvemyseipeiihmtegrelvipcrvtspnitvtlkkfpldtlipdgkriiwdsrkgfiisnatykeiglltceatvnghlyktnylthrqtntiidvvlspshgielsvgeklvlnctartelnvgidfnweypsskhqhkklvnrdlktqsgsemkkflstltidgvtrsdqglytcaassglmtkknstfvrvhek
融合蛋白by24.8(κ,igg4)的轻链亚基(by24.8l)核苷酸序列(seqidno:92):
ctcgaggccaccatggagaccgacacactcctcctgtgggtgctgctgctgtgggtgcctggctccactggcgacatcgtgatgacccagagtcctgatagtctggccgtgtccctcggcgagcgcgcaacaatcaattgcaaggcatctcagtccgtttccaacgatgtcgcatggtatcagcagaagcctggacagccacctaagctgctcattaactacgccttccacagattcactggcgtgcccgatcggttttccggaagtggatacggaaccgactttacactgactattagttctctacaagctgaggacgtcgctgtgtactactgtcaccaggcttactctagcccatacacatttggaggcggcactaaggtggagattaagagaaccgtggccgcccccagcgtgttcatcttccctcccagcgacgagcagctgaagtctggcaccgccagcgtggtgtgcctgctgaacaacttctacccccgcgaggccaaggtgcagtggaaggtggacaacgccctgcagagcggcaacagccaggagagcgtgaccgagcaggactccaaggacagcacctacagcctgagcagcaccctgaccctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccaccagggactgtctagccccgtgaccaagagcttcaaccggggcgagtgctaagaattc
融合蛋白by24.8(κ,igg4)的轻链亚基(by24.8l)氨基酸序列(seqidno:93):
metdtlllwvlllwvpgstgdivmtqspdslavslgeratinckasqsvsndvawyqqkpgqppkllinyafhrftgvpdrfsgsgygtdftltisslqaedvavyychqaysspytfgggtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
融合蛋白by24.8(κ,igg4)的重链-vid融合亚基(by24.8h)核苷酸序列(seqidno:94):
tctagagccaccatggagaccgacaccctgctgctgtgggtgctgctcctgtgggtgcctggctccacaggccaggtccagctccaggagagcggacctggcctcgtgaagcctagcgagactctgtctctgacatgtacagtgtccggctttagcctcacttcttacggcgtgcactggattcgccagccacccggaaagggattggaatggctcggcgtcatttgggccggaggcagcactaactacaacccatctctcaagtctaggctcacaatcagcaaggataatagtaagagtcaggtgtccctgaagatgagttccgtcaccgctgccgataccgctgtgtactactgcgcacgcgcatacggcaattactggtacatcgacgtgtggggacagggcaccctcgtgacagtgtcttccgcctccaccaagggcccttccgtgttccctctggccccttgctcccgctccacctccgagtccaccgccgccctgggctgcctggtgaaggactacttccctgagcctgtgaccgtgtcctggaactccggcgccctgacctccggcgtgcacaccttccctgccgtgctgcagtcctccggcctgtactccctgtcctccgtggtgaccgtgccttcctcctccctgggcaccaagacctacacctgcaacgtggaccacaagccttccaacaccaaggtggacaagcgcgtggagtccaagtacggccctccttgccctccttgccctgcccctgagttcctgggcggcccttccgtgttcctgttccctcctaagcctaaggacaccctgatgatctcccgcacccctgaggtgacctgcgtggtggtggacgtgtcccaggaggaccctgaggtgcagttcaactggtacgtggacggcgtggaggtgcacaacgccaagaccaagcctcgcgaggagcagttcaactccacctaccgcgtggtgtccgtgctgaccgtgctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtgtccaacaagggcctgccttcctccatcgagaagaccatctccaaggccaagggccagcctcgcgagcctcaggtgtacaccctgcctccttcccaggaggagatgaccaagaaccaggtgtccctgacctgcctggtgaagggcttctacccttccgacatcgccgtggagtgggagtccaacggccagcctgagaacaactacaagaccacccctcctgtgctggactccgacggctccttcttcctgtactcccgcctgaccgtggacaagtcccgctggcaggagggcaacgtgttctcctgctccgtgatgcacgaggccctgcacaaccactacacccagaagtccctgtccctgtccctgggcggcggaggatctggcggcggaggcagtggaggcggcggaagcgcttccgacaccggccgccctttcgtggagatgtactccgagatccctgagatcatccacatgaccgagggccgcgagctggtgatcccttgccgcgtgacctcccctaacatcaccgtgaccctgaagaagttccctctggacaccctgatccctgacggcaagcgcatcatctgggactcccgcaagggcttcatcatctccaacgccacctacaaggagatcggcctgctgacctgcgaggccaccgtgaacggccacctgtacaagaccaactacctgacccaccgccagaccaacaccatcatcgacgtggtgctgtccccttcccacggcatcgagctgtccgtgggcgagaagctggtgctgaactgcaccgcccgcaccgagctgaacgtgggcatcgacttcaactgggagtacccttcctccaagcaccagcacaagaagctggtgaaccgcgacctgaagacccagtccggctccgagatgaagaagttcctgtccaccctgaccatcgacggcgtgacccgctccgaccagggcctgtacacctgcgccgcctcctccggcctgatgaccaagaagaactccaccttcgtgcgcgtgcacgagaagtaagtcgac
融合蛋白by24.8(κ,igg4)的重链-vid融合亚基(by24.8h)氨基酸序列(seqidno:95):
metdtlllwvlllwvpgstgqvqlqesgpglvkpsetlsltctvsgfsltsygvhwirqppgkglewlgviwaggstnynpslksrltiskdnsksqvslkmssvtaadtavyycaraygnywyidvwgqgtlvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcppcpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslggggsggggsggggsasdtgrpfvemyseipeiihmtegrelvipcrvtspnitvtlkkfpldtlipdgkriiwdsrkgfiisnatykeiglltceatvnghlyktnylthrqtntiidvvlspshgielsvgeklvlnctartelnvgidfnweypsskhqhkklvnrdlktqsgsemkkflstltidgvtrsdqglytcaassglmtkknstfvrvhek
融合蛋白by24.9(κ,igg4)的轻链亚基(by24.9l)核苷酸序列(seqidno:96):
ctcgaggccaccatggagaccgacacactcctcctgtgggtgctgctgctgtgggtgcctggctccactggcgatattcagatgacacagtccccaagttccctgagcgcctccgtcggagaccgggtcaccattacttgtcgcgcttctcagagcgtgagtaattacctcgattggtatcagcagaagccaggaaaggctcctaagctgctcatctacgacgcatccacccgcgcaacaggcgtgcctagccggtttagcggatctggaagtggcactgatttcacactcacaatctctagtctgcaacccgaggactttgctacatactactgtcagcagaacatgcagctgccactgacattcggccagggaactaaggtggagattaagagaaccgtggccgcccccagcgtgttcatcttccctcccagcgacgagcagctgaagtctggcaccgccagcgtggtgtgcctgctgaacaacttctacccccgcgaggccaaggtgcagtggaaggtggacaacgccctgcagagcggcaacagccaggagagcgtgaccgagcaggactccaaggacagcacctacagcctgagcagcaccctgaccctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccaccagggactgtctagccccgtgaccaagagcttcaaccggggcgagtgctaagaattc
融合蛋白by24.9(κ,igg4)的轻链亚基(by24.9l)氨基酸序列(seqidno:97):
metdtlllwvlllwvpgstgdiqmtqspsslsasvgdrvtitcrasqsvsnyldwyqqkpgkapklliydastratgvpsrfsgsgsgtdftltisslqpedfatyycqqnmqlpltfgqgtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
融合蛋白by24.9(κ,igg4)的重链-vid融合亚基(by24.9h)核苷酸序列(seqidno:98):
tctagagccaccatggagaccgacaccctgctgctgtgggtgctgctcctgtgggtgcctggctccacaggcgtgcagctcgtcgagtccggcggaggcgtggtccagccaggacgcagtctgcgcctggattgtaaggcaagcggcatcacctttagtaactacggtatgcactgggtgagacaggctcccggaaagggcctagaatgggtggccgtcatttggtacgactcttctaggaagtactacgccgatagtgtcaagggacggttcacaatctctcgcgataatagcaagaatacactgtttttgcaaatgaactccctcagagctgaggataccgctgtgtactactgcgcaaccaacaatgattactggggacagggcaccctcgtgacagtgtcttccgcctccaccaagggcccttccgtgttccctctggccccttgctcccgctccacctccgagtccaccgccgccctgggctgcctggtgaaggactacttccctgagcctgtgaccgtgtcctggaactccggcgccctgacctccggcgtgcacaccttccctgccgtgctgcagtcctccggcctgtactccctgtcctccgtggtgaccgtgccttcctcctccctgggcaccaagacctacacctgcaacgtggaccacaagccttccaacaccaaggtggacaagcgcgtggagtccaagtacggccctccttgccctccttgccctgcccctgagttcctgggcggcccttccgtgttcctgttccctcctaagcctaaggacaccctgatgatctcccgcacccctgaggtgacctgcgtggtggtggacgtgtcccaggaggaccctgaggtgcagttcaactggtacgtggacggcgtggaggtgcacaacgccaagaccaagcctcgcgaggagcagttcaactccacctaccgcgtggtgtccgtgctgaccgtgctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtgtccaacaagggcctgccttcctccatcgagaagaccatctccaaggccaagggccagcctcgcgagcctcaggtgtacaccctgcctccttcccaggaggagatgaccaagaaccaggtgtccctgacctgcctggtgaagggcttctacccttccgacatcgccgtggagtgggagtccaacggccagcctgagaacaactacaagaccacccctcctgtgctggactccgacggctccttcttcctgtactcccgcctgaccgtggacaagtcccgctggcaggagggcaacgtgttctcctgctccgtgatgcacgaggccctgcacaaccactacacccagaagtccctgtccctgtccctgggcggcggaggatctggcggcggaggcagtggaggcggcggaagcgcttccgacaccggccgccctttcgtggagatgtactccgagatccctgagatcatccacatgaccgagggccgcgagctggtgatcccttgccgcgtgacctcccctaacatcaccgtgaccctgaagaagttccctctggacaccctgatccctgacggcaagcgcatcatctgggactcccgcaagggcttcatcatctccaacgccacctacaaggagatcggcctgctgacctgcgaggccaccgtgaacggccacctgtacaagaccaactacctgacccaccgccagaccaacaccatcatcgacgtggtgctgtccccttcccacggcatcgagctgtccgtgggcgagaagctggtgctgaactgcaccgcccgcaccgagctgaacgtgggcatcgacttcaactgggagtacccttcctccaagcaccagcacaagaagctggtgaaccgcgacctgaagacccagtccggctccgagatgaagaagttcctgtccaccctgaccatcgacggcgtgacccgctccgaccagggcctgtacacctgcgccgcctcctccggcctgatgaccaagaagaactccaccttcgtgcgcgtgcacgagaagtaagtcgac
融合蛋白by24.9(κ,igg4)的重链-vid融合亚基(by24.9h)氨基酸序列(seqidno:99):
metdtlllwvlllwvpgstgvqlvesgggvvqpgrslrldckasgitfsnygmhwvrqapgkglewvaviwydssrkyyadsvkgrftisrdnskntlflqmnslraedtavyycatnndywgqgtlvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcppcpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslggggsggggsggggsasdtgrpfvemyseipeiihmtegrelvipcrvtspnitvtlkkfpldtlipdgkriiwdsrkgfiisnatykeiglltceatvnghlyktnylthrqtntiidvvlspshgielsvgeklvlnctartelnvgidfnweypsskhqhkklvnrdlktqsgsemkkflstltidgvtrsdqglytcaassglmtkknstfvrvhek
融合蛋白by24.10(κ,igg4)的轻链亚基(by24.10l)核苷酸序列(seqidno:100):
ctcgaggccaccatggagaccgacacactcctcctgtgggtgctgctgctgtgggtgcctggctccactggcctcagttacgtcctcacacagcctccatccgtgtctgtgagtcccggacagaccgcaagaatcacatgtagcggcgacgcactgcctaagcagtacgcttactggtatcagcagaagccaggacaggcacctgtgctggtgatctacaaggatagcgagcgcccaagtggcattcccgagagatttagtggctcttctagtggaacaaccgtcaccctgactatttccggcgtgcaggccgaggatgaggccgattactactgtcagtctgctgactctagcggaacatacgtcgtgtttggaggcggaactaaggtggagattaagagaaccgtggccgcccccagcgtgttcatcttccctcccagcgacgagcagctgaagtctggcaccgccagcgtggtgtgcctgctgaacaacttctacccccgcgaggccaaggtgcagtggaaggtggacaacgccctgcagagcggcaacagccaggagagcgtgaccgagcaggactccaaggacagcacctacagcctgagcagcaccctgaccctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccaccagggactgtctagccccgtgaccaagagcttcaaccggggcgagtgctaagaattc
融合蛋白by24.10(κ,igg4)的轻链亚基(by24.10l)氨基酸序列(seqidno:101):metdtlllwvlllwvpgstglsyvltqppsvsvspgqtaritcsgdalpkqyaywyqqkpgqapvlviykdserpsgiperfsgsssgttvtltisgvqaedeadyycqsadssgtyvvfgggtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
融合蛋白by24.10(κ,igg4)的重链-vid融合亚基(by24.10h)核苷酸序列(seqidno:102):
tctagagccaccatggagaccgacaccctgctgctgtgggtgctgctcctgtgggtgcctggctccacaggcgacctcgtgcagtccggcgccgaggtgaagaagcccggcgcatccgtcaaggtgtcttgcaaggcaagtggctacactttcaccagttacggaatcagttgggtcagacaggcacctggccagggcctggagtggatgggctggattagcgcttacaacggaaacaccaattacgctcagaagctccagggtcgggtgactatgacaaccgacacatctaccagcaccgcatacatggagctgcgtagtctgagatccgacgataccgccgtgtactactgtgctcgcggcagaggatactcctacggaattgatgcattcgatatttggggacagggaaccctcgtgacagtgtcttccgcctccaccaagggcccttccgtgttccctctggccccttgctcccgctccacctccgagtccaccgccgccctgggctgcctggtgaaggactacttccctgagcctgtgaccgtgtcctggaactccggcgccctgacctccggcgtgcacaccttccctgccgtgctgcagtcctccggcctgtactccctgtcctccgtggtgaccgtgccttcctcctccctgggcaccaagacctacacctgcaacgtggaccacaagccttccaacaccaaggtggacaagcgcgtggagtccaagtacggccctccttgccctccttgccctgcccctgagttcctgggcggcccttccgtgttcctgttccctcctaagcctaaggacaccctgatgatctcccgcacccctgaggtgacctgcgtggtggtggacgtgtcccaggaggaccctgaggtgcagttcaactggtacgtggacggcgtggaggtgcacaacgccaagaccaagcctcgcgaggagcagttcaactccacctaccgcgtggtgtccgtgctgaccgtgctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtgtccaacaagggcctgccttcctccatcgagaagaccatctccaaggccaagggccagcctcgcgagcctcaggtgtacaccctgcctccttcccaggaggagatgaccaagaaccaggtgtccctgacctgcctggtgaagggcttctacccttccgacatcgccgtggagtgggagtccaacggccagcctgagaacaactacaagaccacccctcctgtgctggactccgacggctccttcttcctgtactcccgcctgaccgtggacaagtcccgctggcaggagggcaacgtgttctcctgctccgtgatgcacgaggccctgcacaaccactacacccagaagtccctgtccctgtccctgggcggcggaggatctggcggcggaggcagtggaggcggcggaagcgcttccgacaccggccgccctttcgtggagatgtactccgagatccctgagatcatccacatgaccgagggccgcgagctggtgatcccttgccgcgtgacctcccctaacatcaccgtgaccctgaagaagttccctctggacaccctgatccctgacggcaagcgcatcatctgggactcccgcaagggcttcatcatctccaacgccacctacaaggagatcggcctgctgacctgcgaggccaccgtgaacggccacctgtacaagaccaactacctgacccaccgccagaccaacaccatcatcgacgtggtgctgtccccttcccacggcatcgagctgtccgtgggcgagaagctggtgctgaactgcaccgcccgcaccgagctgaacgtgggcatcgacttcaactgggagtacccttcctccaagcaccagcacaagaagctggtgaaccgcgacctgaagacccagtccggctccgagatgaagaagttcctgtccaccctgaccatcgacggcgtgacccgctccgaccagggcctgtacacctgcgccgcctcctccggcctgatgaccaagaagaactccaccttcgtgcgcgtgcacgagaagtaagtcgac
融合蛋白by24.10(κ,igg4)的重链-vid融合亚基(by24.10h)氨基酸序列(seqidno:103):
metdtlllwvlllwvpgstgdlvqsgaevkkpgasvkvsckasgytftsygiswvrqapgqglewmgwisayngntnyaqklqgrvtmttdtststaymelrslrsddtavyycargrgysygidafdiwgqgtlvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcppcpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslggggsggggsggggsasdtgrpfvemyseipeiihmtegrelvipcrvtspnitvtlkkfpldtlipdgkriiwdsrkgfiisnatykeiglltceatvnghlyktnylthrqtntiidvvlspshgielsvgeklvlnctartelnvgidfnweypsskhqhkklvnrdlktqsgsemkkflstltidgvtrsdqglytcaassglmtkknstfvrvhek
融合蛋白by24.11(κ,igg4)的轻链亚基(by24.11l)核苷酸序列(seqidno:104):
ctcgaggccaccatggagaccgacacactcctcctgtgggtgctgctgctgtgggtgcctggctccactggcgatgtcgtcatgacccagtcccctctgtctctgcccgtcacactgggacagcccgcatccattagttgtaggtctagccagagcattgtgcacagtaacggcaatacatacctggagtggtatcttcaaaagcctggccagtctcctcagctgctgatctacaaggtgagtaatcgctttagcggcgtgcctgatagattcagcggaagtggctccggaaccgacttcacactcaagatttctcgcgtggaggccgaggacgtcggcgtgtactactgttttcaggggagccacgtgccactcacctttggacagggcactaaggtggagattaagagaaccgtggccgcccccagcgtgttcatcttccctcccagcgacgagcagctgaagtctggcaccgccagcgtggtgtgcctgctgaacaacttctacccccgcgaggccaaggtgcagtggaaggtggacaacgccctgcagagcggcaacagccaggagagcgtgaccgagcaggactccaaggacagcacctacagcctgagcagcaccctgaccctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccaccagggactgtctagccccgtgaccaagagcttcaaccggggcgagtgctaagaattc
融合蛋白by24.11(κ,igg4)的轻链亚基(by24.11l)氨基酸序列(seqidno:105):
metdtlllwvlllwvpgstgdvvmtqsplslpvtlgqpasiscrssqsivhsngntylewylqkpgqspqlliykvsnrfsgvpdrfsgsgsgtdftlkisrveaedvgvyycfqgshvpltfgqgtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
融合蛋白by24.11(κ,igg4)的重链-vid融合亚基(by24.11h)核苷酸序列(seqidno:106):
tctagagccaccatggagaccgacaccctgctgctgtgggtgctgctcctgtgggtgcctggctccacaggccagggccagctcgtgcagagtggcgcagaggtgaagaagcccggagcatccgtcaaggtcagttgcaaggcctctggatacacctttaccgattacgagatgcactgggtgcggcaggctcctggacagggactcgaatggatgggcgtcattgagtccgagaccggcggaacagcttacaatcagaagtttcagggacgggtgacactcactgccgataagtcttctagcaccgcctacatggaactttcctctctgcgctcagaggataccgctgtgtactactgtacacgcgagggaatcacaactgtcgcaaccacatactactggtacttcgacgtgtggggccagggaaccctcgtgacagtgtcttccgcctccaccaagggcccttccgtgttccctctggccccttgctcccgctccacctccgagtccaccgccgccctgggctgcctggtgaaggactacttccctgagcctgtgaccgtgtcctggaactccggcgccctgacctccggcgtgcacaccttccctgccgtgctgcagtcctccggcctgtactccctgtcctccgtggtgaccgtgccttcctcctccctgggcaccaagacctacacctgcaacgtggaccacaagccttccaacaccaaggtggacaagcgcgtggagtccaagtacggccctccttgccctccttgccctgcccctgagttcctgggcggcccttccgtgttcctgttccctcctaagcctaaggacaccctgatgatctcccgcacccctgaggtgacctgcgtggtggtggacgtgtcccaggaggaccctgaggtgcagttcaactggtacgtggacggcgtggaggtgcacaacgccaagaccaagcctcgcgaggagcagttcaactccacctaccgcgtggtgtccgtgctgaccgtgctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtgtccaacaagggcctgccttcctccatcgagaagaccatctccaaggccaagggccagcctcgcgagcctcaggtgtacaccctgcctccttcccaggaggagatgaccaagaaccaggtgtccctgacctgcctggtgaagggcttctacccttccgacatcgccgtggagtgggagtccaacggccagcctgagaacaactacaagaccacccctcctgtgctggactccgacggctccttcttcctgtactcccgcctgaccgtggacaagtcccgctggcaggagggcaacgtgttctcctgctccgtgatgcacgaggccctgcacaaccactacacccagaagtccctgtccctgtccctgggcggcggaggatctggcggcggaggcagtggaggcggcggaagcgcttccgacaccggccgccctttcgtggagatgtactccgagatccctgagatcatccacatgaccgagggccgcgagctggtgatcccttgccgcgtgacctcccctaacatcaccgtgaccctgaagaagttccctctggacaccctgatccctgacggcaagcgcatcatctgggactcccgcaagggcttcatcatctccaacgccacctacaaggagatcggcctgctgacctgcgaggccaccgtgaacggccacctgtacaagaccaactacctgacccaccgccagaccaacaccatcatcgacgtggtgctgtccccttcccacggcatcgagctgtccgtgggcgagaagctggtgctgaactgcaccgcccgcaccgagctgaacgtgggcatcgacttcaactgggagtacccttcctccaagcaccagcacaagaagctggtgaaccgcgacctgaagacccagtccggctccgagatgaagaagttcctgtccaccctgaccatcgacggcgtgacccgctccgaccagggcctgtacacctgcgccgcctcctccggcctgatgaccaagaagaactccaccttcgtgcgcgtgcacgagaagtaagtcgac
融合蛋白by24.11(κ,igg4)的重链-vid融合亚基(by24.11h)氨基酸序列(seqidno:107):
metdtlllwvlllwvpgstgqgqlvqsgaevkkpgasvkvsckasgytftdyemhwvrqapgqglewmgviesetggtaynqkfqgrvtltadkssstaymelsslrsedtavyyctregittvattyywyfdvwgqgtlvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcppcpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslggggsggggsggggsasdtgrpfvemyseipeiihmtegrelvipcrvtspnitvtlkkfpldtlipdgkriiwdsrkgfiisnatykeiglltceatvnghlyktnylthrqtntiidvvlspshgielsvgeklvlnctartelnvgidfnweypsskhqhkklvnrdlktqsgsemkkflstltidgvtrsdqglytcaassglmtkknstfvrvhek
融合蛋白by24.12(κ,igg4)的轻链亚基(by24.12l)核苷酸序列(seqidno:108):
ctcgaggccaccatggagaccgacacactcctcctgtgggtgctgctgctgtgggtgcctggctccactggcgatattgtgctgacccagagtcccgcatctctcgccgtcagtcctggacagcgcgctactatcacttgcagggcttctgagagcgtcgataattacggcatttcctttatgaactggtatcagcagaagcctggccagcctccaaagctgctcatctacacctctagtaacaaggatacaggcgtgcccgcaagatttagcggctccggaagtggcaccgacttcacactcacaatcaaccctatggaggccgaggataccgccgtgtactactgtcagcagtctaaggaggtgccttggacattcggcggcggaactaaggtggagattaagagaaccgtggccgcccccagcgtgttcatcttccctcccagcgacgagcagctgaagtctggcaccgccagcgtggtgtgcctgctgaacaacttctacccccgcgaggccaaggtgcagtggaaggtggacaacgccctgcagagcggcaacagccaggagagcgtgaccgagcaggactccaaggacagcacctacagcctgagcagcaccctgaccctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccaccagggactgtctagccccgtgaccaagagcttcaaccggggcgagtgctaagaattc
融合蛋白by24.12(κ,igg4)的轻链亚基(by24.12l)氨基酸序列(seqidno:109):
metdtlllwvlllwvpgstgdivltqspaslavspgqratitcrasesvdnygisfmnwyqqkpgqppklliytssnkdtgvparfsgsgsgtdftltinpmeaedtavyycqqskevpwtfgggtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
融合蛋白by24.12(κ,igg4)的重链-vid融合亚基(by24.12h)核苷酸序列(seqidno:110):
tctagagccaccatggagaccgacaccctgctgctgtgggtgctgctcctgtgggtgcctggctccacaggcgaggtccagctcgtcgagtccggcggaggcctcgtgcagcccggcggatctctgagactcagttgtgccgctagtggctttacattttcttcctacggcatgtcttgggtgagacaggctcctggaaagggattagagtgggtcgcaactattagtggcggaggaagcgacacatactacgccgattccgtcaagggacggttcaccatcagtcgcgataactctaagaacacactgtacctacagatgaatagcctgagagcagaggataccgctgtgtactactgcgcacgccagctcaattacgcatggtttgcttactggggccagggcaccctcgtgacagtgtcttccgcctccaccaagggcccttccgtgttccctctggccccttgctcccgctccacctccgagtccaccgccgccctgggctgcctggtgaaggactacttccctgagcctgtgaccgtgtcctggaactccggcgccctgacctccggcgtgcacaccttccctgccgtgctgcagtcctccggcctgtactccctgtcctccgtggtgaccgtgccttcctcctccctgggcaccaagacctacacctgcaacgtggaccacaagccttccaacaccaaggtggacaagcgcgtggagtccaagtacggccctccttgccctccttgccctgcccctgagttcctgggcggcccttccgtgttcctgttccctcctaagcctaaggacaccctgatgatctcccgcacccctgaggtgacctgcgtggtggtggacgtgtcccaggaggaccctgaggtgcagttcaactggtacgtggacggcgtggaggtgcacaacgccaagaccaagcctcgcgaggagcagttcaactccacctaccgcgtggtgtccgtgctgaccgtgctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtgtccaacaagggcctgccttcctccatcgagaagaccatctccaaggccaagggccagcctcgcgagcctcaggtgtacaccctgcctccttcccaggaggagatgaccaagaaccaggtgtccctgacctgcctggtgaagggcttctacccttccgacatcgccgtggagtgggagtccaacggccagcctgagaacaactacaagaccacccctcctgtgctggactccgacggctccttcttcctgtactcccgcctgaccgtggacaagtcccgctggcaggagggcaacgtgttctcctgctccgtgatgcacgaggccctgcacaaccactacacccagaagtccctgtccctgtccctgggcggcggaggatctggcggcggaggcagtggaggcggcggaagcgcttccgacaccggccgccctttcgtggagatgtactccgagatccctgagatcatccacatgaccgagggccgcgagctggtgatcccttgccgcgtgacctcccctaacatcaccgtgaccctgaagaagttccctctggacaccctgatccctgacggcaagcgcatcatctgggactcccgcaagggcttcatcatctccaacgccacctacaaggagatcggcctgctgacctgcgaggccaccgtgaacggccacctgtacaagaccaactacctgacccaccgccagaccaacaccatcatcgacgtggtgctgtccccttcccacggcatcgagctgtccgtgggcgagaagctggtgctgaactgcaccgcccgcaccgagctgaacgtgggcatcgacttcaactgggagtacccttcctccaagcaccagcacaagaagctggtgaaccgcgacctgaagacccagtccggctccgagatgaagaagttcctgtccaccctgaccatcgacggcgtgacccgctccgaccagggcctgtacacctgcgccgcctcctccggcctgatgaccaagaagaactccaccttcgtgcgcgtgcacgagaagtaagtcgac
融合蛋白by24.12(κ,igg4)的重链-vid融合亚基(by24.12h)氨基酸序列(seqidno:111):
metdtlllwvlllwvpgstgevqlvesggglvqpggslrlscaasgftfssygmswvrqapgkglewvatisgggsdtyyadsvkgrftisrdnskntlylqmnslraedtavyycarqlnyawfaywgqgtlvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcppcpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslggggsggggsggggsasdtgrpfvemyseipeiihmtegrelvipcrvtspnitvtlkkfpldtlipdgkriiwdsrkgfiisnatykeiglltceatvnghlyktnylthrqtntiidvvlspshgielsvgeklvlnctartelnvgidfnweypsskhqhkklvnrdlktqsgsemkkflstltidgvtrsdqglytcaassglmtkknstfvrvhek
融合蛋白by24.13(κ,igg4)的轻链亚基(by24.13l)核苷酸序列(seqidno:112):
ctcgaggccaccatggagaccgacacactcctcctgtgggtgctgctgctgtgggtgcctggctccactggcgatattcagatgacccagagtccatctagcgtgtctgcttctgtgggcgatcgggtgacaatcacttgtcgcgcaagtcagggaattagtagttggctcgcatggtatcagcagaagcctggcaaggcacctaagctcctcattagcgccgcgtcatccctgcaatccggcgtgccatctaggtttagtggttccggaagcggaaccgactttacactcactatcagttctctccagcccgaggatttcgcaacatactactgtcagcaggccaaccacctgcctttcacatttggaggcggcacattcggcggcggaactaaggtggagattaagagaaccgtggccgcccccagcgtgttcatcttccctcccagcgacgagcagctgaagtctggcaccgccagcgtggtgtgcctgctgaacaacttctacccccgcgaggccaaggtgcagtggaaggtggacaacgccctgcagagcggcaacagccaggagagcgtgaccgagcaggactccaaggacagcacctacagcctgagcagcaccctgaccctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccaccagggactgtctagccccgtgaccaagagcttcaaccggggcgagtgctaagaattc
融合蛋白by24.13(κ,igg4)的轻链亚基(by24.13l)氨基酸序列(seqidno:113):
metdtlllwvlllwvpgstgdiqmtqspssvsasvgdrvtitcrasqgisswlawyqqkpgkapkllisaasslqsgvpsrfsgsgsgtdftltisslqpedfatyycqqanhlpftfgggtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
融合蛋白by24.13(κ,igg4)的重链-vid融合亚基(by24.13h)核苷酸序列(seqidno:114):
tctagagccaccatggagaccgacaccctgctgctgtgggtgctgctcctgtgggtgcctggctccacaggccaggtgcagctcgtccagtctggcgctgaggtcaagaagcctggatctagcgtgaaggtgtcttgtaaggcaagtggcggaaccttttctagttacgctattagttgggtgcggcaggctcccggccagggcctggagtggatgggactcatcattcctatgttcgataccgccggctacgcccagaagtttcagggacgggtcgcaatcaccgtagatgagagtacctccacagcatacatggagctgagtagtctcagatccgaggacactgccgtgtactactgtgctcgcgcagagcactctagcaccggaacatttgattactggggacagggcaccctcgtgacagtgtcttccgcctccaccaagggcccttccgtgttccctctggccccttgctcccgctccacctccgagtccaccgccgccctgggctgcctggtgaaggactacttccctgagcctgtgaccgtgtcctggaactccggcgccctgacctccggcgtgcacaccttccctgccgtgctgcagtcctccggcctgtactccctgtcctccgtggtgaccgtgccttcctcctccctgggcaccaagacctacacctgcaacgtggaccacaagccttccaacaccaaggtggacaagcgcgtggagtccaagtacggccctccttgccctccttgccctgcccctgagttcctgggcggcccttccgtgttcctgttccctcctaagcctaaggacaccctgatgatctcccgcacccctgaggtgacctgcgtggtggtggacgtgtcccaggaggaccctgaggtgcagttcaactggtacgtggacggcgtggaggtgcacaacgccaagaccaagcctcgcgaggagcagttcaactccacctaccgcgtggtgtccgtgctgaccgtgctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtgtccaacaagggcctgccttcctccatcgagaagaccatctccaaggccaagggccagcctcgcgagcctcaggtgtacaccctgcctccttcccaggaggagatgaccaagaaccaggtgtccctgacctgcctggtgaagggcttctacccttccgacatcgccgtggagtgggagtccaacggccagcctgagaacaactacaagaccacccctcctgtgctggactccgacggctccttcttcctgtactcccgcctgaccgtggacaagtcccgctggcaggagggcaacgtgttctcctgctccgtgatgcacgaggccctgcacaaccactacacccagaagtccctgtccctgtccctgggcggcggaggatctggcggcggaggcagtggaggcggcggaagcgcttccgacaccggccgccctttcgtggagatgtactccgagatccctgagatcatccacatgaccgagggccgcgagctggtgatcccttgccgcgtgacctcccctaacatcaccgtgaccctgaagaagttccctctggacaccctgatccctgacggcaagcgcatcatctgggactcccgcaagggcttcatcatctccaacgccacctacaaggagatcggcctgctgacctgcgaggccaccgtgaacggccacctgtacaagaccaactacctgacccaccgccagaccaacaccatcatcgacgtggtgctgtccccttcccacggcatcgagctgtccgtgggcgagaagctggtgctgaactgcaccgcccgcaccgagctgaacgtgggcatcgacttcaactgggagtacccttcctccaagcaccagcacaagaagctggtgaaccgcgacctgaagacccagtccggctccgagatgaagaagttcctgtccaccctgaccatcgacggcgtgacccgctccgaccagggcctgtacacctgcgccgcctcctccggcctgatgaccaagaagaactccaccttcgtgcgcgtgcacgagaagtaagtcgac
融合蛋白by24.13(κ,igg4)的重链-vid融合亚基(by24.13h)氨基酸序列(seqidno:115):
metdtlllwvlllwvpgstgqvqlvqsgaevkkpgssvkvsckasggtfssyaiswvrqapgqglewmgliipmfdtagyaqkfqgrvaitvdeststaymelsslrsedtavyycaraehsstgtfdywgqgtlvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcppcpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslggggsggggsggggsasdtgrpfvemyseipeiihmtegrelvipcrvtspnitvtlkkfpldtlipdgkriiwdsrkgfiisnatykeiglltceatvnghlyktnylthrqtntiidvvlspshgielsvgeklvlnctartelnvgidfnweypsskhqhkklvnrdlktqsgsemkkflstltidgvtrsdqglytcaassglmtkknstfvrvhek
融合蛋白by24.14(κ,igg4)的轻链亚基(by24.14l)核苷酸序列(seqidno:116):
ctcgaggccaccatggagaccgacacactcctcctgtgggtgctgctgctgtgggtgcctggctccactggccagagcgctctcactcagcctgcttccgtgtctggaagtcccggccagagtatcactatttcttgtacaggaacttcctccgacgtcggattttacaattacgtcagttggtatcagcagcaccccggaaaggcacctgaactaatgatctacgatgtgtctaaccgcccaagcggcgtgagcgataggttcagtggcagtaagagtggcaacaccgcatccctgaccattagtggattacaggccgaggacgaggctgattactactgttctagctacacaaatatctccacatgggtcttcggcggaggaacattcggcggcggaactaaggtggagattaagagaaccgtggccgcccccagcgtgttcatcttccctcccagcgacgagcagctgaagtctggcaccgccagcgtggtgtgcctgctgaacaacttctacccccgcgaggccaaggtgcagtggaaggtggacaacgccctgcagagcggcaacagccaggagagcgtgaccgagcaggactccaaggacagcacctacagcctgagcagcaccctgaccctgagcaaggccgactacgagaagcacaaggtgtacgcctgcgaggtgacccaccagggactgtctagccccgtgaccaagagcttcaaccggggcgagtgctaagaattc
融合蛋白by24.14(κ,igg4)的轻链亚基(by24.14l)氨基酸序列(seqidno:117):
metdtlllwvlllwvpgstgqsaltqpasvsgspgqsitisctgtssdvgfynyvswyqqhpgkapelmiydvsnrpsgvsdrfsgsksgntasltisglqaedeadyycssytnistwvfgggtkveikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
融合蛋白by24.14(κ,igg4)的重链-vid融合亚基(by24.14h)核苷酸序列(seqidno:118):
tctagagccaccatggagaccgacaccctgctgctgtgggtgctgctcctgtgggtgcctggctccacaggccagctccagcttcaggagagcggacccggcctggtcaagccatccgagactctcactctgacatgcaccgtgagtgctgattctatcagttccacaacttactactgggtgtggattaggcagcctcccggaaagggattagaatggatcggcagcatttcttacagtggctccacatactacaatcctagtctgaagtctcgcgtgaccgtgtccgtggatacatctaagaaccagtttagcctcaagctgaatagcgtcgccgcaacagataccgctctgtactactgcgcacgccacctcggctacaatggacgctatctgcccttcgattactggggccagggaagcaccctcgtgacagtgtcttccgcctccaccaagggcccttccgtgttccctctggccccttgctcccgctccacctccgagtccaccgccgccctgggctgcctggtgaaggactacttccctgagcctgtgaccgtgtcctggaactccggcgccctgacctccggcgtgcacaccttccctgccgtgctgcagtcctccggcctgtactccctgtcctccgtggtgaccgtgccttcctcctccctgggcaccaagacctacacctgcaacgtggaccacaagccttccaacaccaaggtggacaagcgcgtggagtccaagtacggccctccttgccctccttgccctgcccctgagttcctgggcggcccttccgtgttcctgttccctcctaagcctaaggacaccctgatgatctcccgcacccctgaggtgacctgcgtggtggtggacgtgtcccaggaggaccctgaggtgcagttcaactggtacgtggacggcgtggaggtgcacaacgccaagaccaagcctcgcgaggagcagttcaactccacctaccgcgtggtgtccgtgctgaccgtgctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtgtccaacaagggcctgccttcctccatcgagaagaccatctccaaggccaagggccagcctcgcgagcctcaggtgtacaccctgcctccttcccaggaggagatgaccaagaaccaggtgtccctgacctgcctggtgaagggcttctacccttccgacatcgccgtggagtgggagtccaacggccagcctgagaacaactacaagaccacccctcctgtgctggactccgacggctccttcttcctgtactcccgcctgaccgtggacaagtcccgctggcaggagggcaacgtgttctcctgctccgtgatgcacgaggccctgcacaaccactacacccagaagtccctgtccctgtccctgggcggcggaggatctggcggcggaggcagtggaggcggcggaagcgcttccgacaccggccgccctttcgtggagatgtactccgagatccctgagatcatccacatgaccgagggccgcgagctggtgatcccttgccgcgtgacctcccctaacatcaccgtgaccctgaagaagttccctctggacaccctgatccctgacggcaagcgcatcatctgggactcccgcaagggcttcatcatctccaacgccacctacaaggagatcggcctgctgacctgcgaggccaccgtgaacggccacctgtacaagaccaactacctgacccaccgccagaccaacaccatcatcgacgtggtgctgtccccttcccacggcatcgagctgtccgtgggcgagaagctggtgctgaactgcaccgcccgcaccgagctgaacgtgggcatcgacttcaactgggagtacccttcctccaagcaccagcacaagaagctggtgaaccgcgacctgaagacccagtccggctccgagatgaagaagttcctgtccaccctgaccatcgacggcgtgacccgctccgaccagggcctgtacacctgcgccgcctcctccggcctgatgaccaagaagaactccaccttcgtgcgcgtgcacgagaagtaagtcgac
融合蛋白by24.14(κ,igg4)的重链-vid融合亚基(by24.14h)氨基酸序列(seqidno:119):
metdtlllwvlllwvpgstgqlqlqesgpglvkpsetltltctvsadsissttyywvwirqppgkglewigsisysgstyynpslksrvtvsvdtsknqfslklnsvaatdtalyycarhlgyngrylpfdywgqgstlvtvssastkgpsvfplapcsrstsestaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtktytcnvdhkpsntkvdkrveskygppcppcpapeflggpsvflfppkpkdtlmisrtpevtcvvvdvsqedpevqfnwyvdgvevhnaktkpreeqfnstyrvvsvltvlhqdwlngkeykckvsnkglpssiektiskakgqprepqvytlppsqeemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflysrltvdksrwqegnvfscsvmhealhnhytqkslslslggggsggggsggggsasdtgrpfvemyseipeiihmtegrelvipcrvtspnitvtlkkfpldtlipdgkriiwdsrkgfiisnatykeiglltceatvnghlyktnylthrqtntiidvvlspshgielsvgeklvlnctartelnvgidfnweypsskhqhkklvnrdlktqsgsemkkflstltidgvtrsdqglytcaassglmtkknstfvrvhek
其中氨基酸序列“metdtlllwvlllwvpgstg”为信号肽。
使用上述实施例1(1)相同的方法,分别通过xhoi-ecori双酶切将by24.3l、by24.4l、lby24.5l、by24.6l、by24.7l、by24.8l、by24.9l、by24.10l、by24.11l、by24.12l、by24.13l和by24.14l编码核苷酸连接至具有双表达盒的谷氨酰胺合成酶高效表达载体(专利授权号:cn104195173b,获自北京比洋生物技术有限公司);再通过xbai-sali双酶切将by24.3h、by24.4h、lby24.5h、by24.6h、by24.7h、by24.8h、by24.9h、by24.10h、by24.11h、by24.12h、by24.13h和by24.14h编码核苷酸分别克隆至已连接了相应的融合蛋白轻链亚基编码核苷酸的具有双表达盒的谷氨酰胺合成酶高效表达载体;或者反之亦然。将重组载体测序验证正确后用于表达。所表达的双靶向融合蛋白分别命名为融合蛋白by24.3、by24.4、by24.5、by24.6、by24.7、by24.8、by24.9、by24.10、by24.11、by24.12、by24.13和by24.14。
实施例2、融合蛋白的表达和纯化
(1)融合蛋白的瞬时表达
将293f(购自invitrogen公司,目录号:11625-019)细胞悬浮培养于无血清cd293培养液(购自invitrogen公司,目录号:11913-019)中。转染前离心细胞培养物,获得细胞沉淀,用新鲜的无血清cd293培养液悬浮细胞,将细胞浓度调整为1×106个细胞/ml。将细胞悬浮液置于摇瓶中。以100ml细胞悬浮液为例,分别将实施例1制备的重组表达载体质粒dna250ug和聚乙烯亚胺(polyethylenimine(pei))(sigma,目录号:408727)500ug加入1ml无血清cd293培养液中混匀,室温静置8分钟后,将pei/dna混悬液逐滴加入放置有100ml细胞悬浮液的摇瓶中。轻轻混匀,置于5%co2、37℃摇床培养(120转/分钟)。5天后收集培养上清。
根据同样的方法,瞬时表达产生作为对照的抗体by18.1和作为对照的蛋白301-8。
(2)表达蛋白的纯化
用ph7.4pbs溶液平衡的hitrapmabselectsure1ml柱(gehealthcarelifesciences产品,目录号:11-0034-93)纯化上述实施例2(1)收集的培养上清中存在的融合蛋白。简而言之,用ph7.4的pbs溶液以10个柱床体积平衡hitrapmabselectsure1ml柱,流速为0.5ml/分钟;将上述实施例2(1)收集的培养上清用0.45μm滤膜过滤后,载样至用ph7.4pbs溶液平衡的hitrapmabselectsure1ml柱;装载上清液后,将该柱首先用ph7.4的pbs溶液以流速0.5ml/分钟洗涤5-10个柱床体积,并随后用100mm柠檬酸缓冲液(ph4.0)以流速0.5ml/分钟洗脱。收集洗脱峰,目的蛋白存在于洗脱峰中。
在还原剂(5mm1,4-二硫苏糖醇)存在下通过sds-page并用考马斯蓝染色,分析融合蛋白的纯度和分子量。结果如图2所示。分子量理论预测值与实际测定值见表5。因真核表达系统中存在对蛋白质的糖基化作用,故分子量实际测定值略高于理论预测值。
表5经纯化的表达蛋白的分子量大小
实施例3、使用elisa方法检测本发明的融合蛋白与人pd-1和重组人vegf-a的结合
将抗原pd-1(北京义翘神州生物技术有限公司产品,目录号:10377-h08h)和抗原vegf165(北京义翘神州生物技术有限公司产品,目录号:11066-hnah)稀释至0.5μg/ml和0.02μg/ml并分别包被96孔elisa板(购自corning公司,货号:42592)。将上述实施例2(2)纯化的双靶向融合蛋白稀释至5μg/ml,然后进行3倍系列稀释,共稀释9个梯度,对每个浓度梯度进行复孔检测。将稀释样品50μl分别加入经抗原pd-1或抗原vegf165包被的96孔板中,37℃孵育2小时。洗涤3次后,加入辣根过氧化物酶标记的山羊抗人二级抗体(北京中衫金桥公司产品,产品号:zdr-5301),37℃孵育1小时。洗涤3次后,加入3,3',5,5'-四甲基联苯胺(tmb)底物显色液(北京康为世纪生物科技有限公司,产品号:cw0050)50μl/孔。10分钟后,加入2n的h2so4终止显色。使用elisa读数仪在450nm处测定每孔的吸光度od值。对作为对照的抗体by18.1、作为对照的蛋白301-8实施同样的elisa操作。
elisa结果显示,与作为对照的抗体by18.1同样地,本发明的融合蛋白by24.3、by24.4、by24.5、by24.6、by24.7、by24.8、by24.9、by24.10、by24.11、by24.12、by24.13、by24.14能特异性地结合pd-1;与作为对照的蛋白301-8同样地,本发明的融合蛋白by24.3、by24.4、lby24.5、by24.6、by24.7、by24.8、by24.9、by24.10、by24.11、by24.12、by24.13、by24.14也能特异性地结合vegf-a。
应用graphpadprism5软件,将各融合蛋白的蛋白质浓度对吸光度od值作图,并且拟合数据以产生融合蛋白介导的特异性结合作用的半数最大有效浓度ec50值。结果如下表6所示。
表6本发明的融合蛋白对pd-1、vegf-a的结合作用
根据表6的结果可见,本发明所构建的新型融合蛋白均能够以高亲和力结合pd-1,其中融合蛋白by24.4、by24.5、by24.7、by24.8、by24.10、by24.11、by24.12、by24.14以比抗体by18.1大的、甚至融合蛋白by24.8以比抗体by18.1大约10倍的亲和力结合pd-1,融合蛋白by24.3与抗体by18.1对pd-1的亲和力基本一致;本发明所构建的新型融合蛋白也均能够以高亲和力结合vegf-a,其中融合蛋白by24.3显示与作为对照的蛋白301-8相似的高亲和力结合vegf-a。
实施例4、使用biacoret100测定本发明的融合蛋白的亲和力
在
首先,通过酰胺偶联将抗igg抗体(gehealthcarelifesciences,目录号:br-1008-39)共价固定在cm5芯片上。使用60μln-乙基-n'-(3-二甲基氨基丙基)碳二亚胺盐酸盐(edc)和60μln-羟基琥珀酰亚胺(nhs)活化cm5芯片,然后将5μl抗igg抗体加95μl稀释缓冲液hbst(0.1mhepes,1.5mnacl,ph7.4,加0.005%吐温20)经0.2um滤膜过滤后,通过酰胺偶联将抗igg抗体共价固定在cm5芯片上,产生约9000-14000共振单位(ru)的捕获系统。使用120μl乙醇胺封闭cm5芯片。
然后,将实施例2制备的本发明的融合蛋白、抗体by18.1和蛋白301-8分别稀释为5μg/ml,以流速10μl/分钟注射该稀释液2分钟,将1600ru的实施例2制备的本发明的融合蛋白、抗体by18.1和蛋白301-8通过各自的fc区非共价地捕获到cm5芯片表面上。通过与edc/nhs交联来稳定所得的复合物,以避免在测量和再生期间的基线漂移。
分别将结合抗原pd-1(北京义翘神州生物技术有限公司产品,目录号:10377-h08h)、vegf165(北京义翘神州生物技术有限公司产品,目录号:11066-hnah)、vegf-b(biovision产品,目录号:4642-20)和plgf-1(biovision产品,目录号:4739-25)配制为如下浓度梯度:7nm、22nm、66nm、200nm、600nm。通过以流速30μl/分钟注射每个浓度180秒,解离时间600秒,测量结合。通过用3mmgcl2溶液以流速10μl/分钟洗涤30秒使表面再生。使用bia评价软件(biaevaluation4.1software,来自gehealthcarebiosciencesab,瑞典)进行数据分析,获得下表7所示的亲和力数据。
表7各蛋白质与vegf家族分子、pd-1的结合
注:nd:未检测
根据表7所示的数据可见,融合蛋白by24.3以高的亲和力与vegf-a、vegf-b和plgf-1结合,亲和力分别达到9.59×10-12m、1.23×10-9m和1.82×10-10m,且对pd-1的亲和力(kd)与作为对照的抗体by18.1基本一致,融合蛋白by24.7以比抗体by18.1大的亲和力(kd)结合pd-1;融合蛋白by24.3显示与作为对照的蛋白301-8相似的高亲和力结合vegf-a;融合蛋白by24.3也以高亲和力结合vegf-b和plgf-1。
由此表明了本发明的双靶向融合蛋白以与抗pd-1抗体类似的、或者更好的亲和力与pd-1结合,并具有极好的与多种vegf结合的能力。
表7的结果也表明了:实施例4的通过表面等离子体共振(spr)技术测定的亲和力结果与实施例3的通过elisa测定的亲和力结果呈现高度一致性。
实施例5、本发明的融合蛋白在人源化b-hpd-1小鼠模型中对肿瘤生长的抑制作用
将0.1mldmem培养基中的5×105个mc38鼠结肠癌细胞(获自atcc,美国)接种于体重约18g,6周龄雌性b-hpd-1人源化小鼠(获自北京百奥赛图基因生物技术有限公司,产品编号:b-cm-001)右侧前胁肋部皮下。肿瘤在所述小鼠体内长大。待肿瘤体积达到约108mm3时将荷瘤小鼠随机分组,每组6只,共4组,分别为:pbs溶剂对照组、蛋白301-8组(3.3mg/kg)、融合蛋白by24.3组(6.4mg/kg)和抗体by18.1组(5mg/kg),各给药组剂量以抗体by18.1组的剂量为标准,对蛋白301-8组、融合蛋白by24.3组和抗体by18.1组而言所施用的剂量在摩尔量上是等同的。将第一次给药的时间设定为第0天。所有组给药途径均为腹腔(i.p.)注射,每三天给药1次,连续给药6次,末次给药3天后结束实验。每周测量肿瘤体积及小鼠体重2次,记录小鼠体重和肿瘤体积。实验结束时,将动物安乐死,剥取肿瘤称重、拍照,计算肿瘤生长抑制率(tumorgrowthinhibition%)和肿瘤重量抑制率(inhibitionrateoftumorweight%)。计算tgi%使用的公式是:[1-(给药组肿瘤体积变化的均值/pbs溶剂对照组肿瘤体积变化的均值)]x100%,计算irtw%使用的公式是:[1-(给药组肿瘤重量/pbs溶剂对照组肿瘤重量)]x100%。该实验在北京百奥赛图基因生物技术有限公司实施。
结果见图3和图4。本实验观察了本发明的融合蛋白by24.3以及作为药物对照的抗体by18.1、蛋白301-8对mc38小鼠结肠癌皮下移植瘤生长的抑制作用。
整个实验过程中,所有动物精神状态良好,无动物死亡。实验结束时(首次给药后的第21天),各组动物体重平均约为19g。将本发明的融合蛋白by24.3组以及作为药物对照的抗体by18.1组、蛋白301-8组的动物与pbs溶剂对照组动物进行体重比较,没有显著性差异(p>0.05),表明动物对本发明的融合蛋白by24.3耐受良好(图3)。
实验结束时,pbs溶剂对照组平均肿瘤体积±标准误为1386±170mm3,而融合蛋白by24.3和蛋白301-8组平均肿瘤体积±标准误分别为452±69、1023±256,tgi%分别为73.3%、28.1%,irtw%分别为74.6%、25.7%。融合蛋白by24.3与pbs溶剂对照组的肿瘤体积相比有明显差异(p<0.05),表明融合蛋白by24.3有显著的肿瘤抑制作用。蛋白301-8有一定的肿瘤抑制作用,但是与pbs溶剂对照组相比,未见显著性差异(p>0.05)。作为对照的抗体by18.1平均肿瘤体积±标准误为739±128,tgi%为50.6%,irtw%为46.0%,与pbs溶剂对照组的肿瘤体积相比有显著差异(p<0.05)。融合蛋白by24.3显示极佳的肿瘤抑制作用,与作为药物对照的抗体by18.1组、蛋白301-8组的肿瘤抑制作用相比较,具有显著性差异。本实验的抗肿瘤药效结果在对小鼠肿瘤称重的比较上也得到进一步证实。
表8在人源化b-hpd-1小鼠模型中对肿瘤生长的抑制作用比较
尽管已经出于说明本发明的目的显示了某些代表性实施方案和细节,但是本领域技术人员显而易见的是可以对它们进行多种变化和修改而不脱离主题发明的范围。在这个方面,本发明范围仅由以下权利要求限定。
- 还没有人留言评论。精彩留言会获得点赞!