人类X染色体18个基因座复合扩增体系的制作方法
本发明涉及生物技术领域中,人类x染色体18个基因座复合扩增体系。
背景技术:
短串联重复序列(shorttendemrepreat,str)属于第二代遗传标记,由于其重复单元小、突变速率高、在基因组中分布广等特点,现已广泛应用于群体遗传学及法医学领域。在人类基因组中,大约每15-20kb就有一个str位点,它们占人类基因组总量的10%。这些str通常由2-6个碱基组成串联重复单元,由于重复单元及重复次数的不同,它们在不同种族、地域的人群中显示出较大的差异性,表现为遗传多态性。
最早应用于法医遗传学领域的是人类常染色体str,至今国内外已有比较成型的扩增、检测试剂盒及相关技术路线,扩增位点数目不断增加。同时,常染色体str数据库的建成,为案件侦破及罪犯特征刻画提供了条件。目前已有至少39个x染色体str基因座(记为x-str基因座)应用于法医学实践。父亲的x染色体单倍型遗传给女儿,母亲的x染色体单倍型随机遗传给子女,根据x-str基因座的遗传特点,x-str基因座可以应用于父女鉴定、母子鉴定、同胞、半同胞、隔代亲缘关系、乱伦等特殊亲缘关系鉴定案件中,x-str基因座的密度与常染色体相当,x-str基因座的突变率也与常染色体str相近,约为2.09×10-3。x-str基因座均位于同一染色体上,当两个x-str基因座的物理或遗传距离很近时,必须考虑两个基因座连锁遗传的可能性。由于存在连锁和连锁不平衡,在实际应用中,必须考虑其带来的影响,有学者研究了8个x-str的连锁和连锁不平衡现象,进一步证实了连锁遗传较常见,并且会影响似然比的计算。目前应用最广的基因座复合体系是凯杰的argusx-12试剂盒,但由于我国还未确定x-str核心基因座位点,因此不同复合体系间x-str基因座位点差异较大,以凯杰的argusx-12,中德美联的agcux19,阅微的microreader19x三个试剂盒为例,发现共同的基因座共有四个,分别为:hprtb、dxs10079、dxs10135、dxs7423,故不同复合体系间的兼容性较差。x-str的应用建立在人群等位基因分型和基因频率研究之上,目前可以在x-str数据库(http://www.chrx-str.org/)进行人群遗传学参数的计算,但不同等位基因的基因频率需要根据不同地区和人种进行计算和统计,因此目前有大量的研究是针对x-str不同复合体系的遗传多态性研究,在国内研究的种族人群覆盖了浙江汉族、广东汉族、河南汉族、桂林汉族、新疆维族等。
自hprtb和ara两个x-str基因座用于法医学检验以来,越来越多的x-str基因座被开发应用于亲权鉴定的特殊案件中。x-str基因座在实际应用中已经发挥着越来越重要的作用,特别是在一些亲缘关系鉴定中,通过增加x-str基因座的检验,其检验效能显著提高。有研究人员证实,在仅有母亲残骸的母子关系鉴定、缺乏父亲的同胞姐妹亲缘关系鉴定、同父异母姐妹亲缘关系鉴定中,x-str基因座作为其他遗传标记的重要补充,显示在此类案件中x-str基因座与常染色体str具有同等价值。在一些重大的灾难事故现场,需要做亲缘关系鉴定,传统的方法是通过父母子的三联体进行鉴定,在只具备单亲进行亲缘关系鉴定的条件下,可以通过联合检验常染色体str和x-str进行亲缘关系鉴定。
x染色体特殊的遗传方式,决定了x-str重要的意义在于对其他遗传标记的重要补充。目前国内对x-str的研究主要包括遗传多态性研究和复杂亲缘关系鉴定,但研究成果带有明显的地域性,中国x-str的群体数据相对欠缺。在x-str的研究中各地采用的统计学分析方法不尽相同,一定程度降低了x-str数据的通用性。国内还未确定x-str核心基因座,因此不同复合体系间x-str基因座位点差异较大。国内对于x-str连锁遗传、突变率的研究偏少,在案件中的报道较少。
技术实现要素:
本发明所要解决的技术问题是如何鉴定人类个体间是否具有共同来源x染色体。
为解决上述技术问题,本发明首先提供了一种可以用于鉴定人类个体间是否具有共同来源x染色体关系的成套试剂,所述成套试剂包括:名称依次为dxsgata31e08-p、dxs10079-p、dxs10103-p、dxs7132-p、dxs9895-p、dxs7133-p、dxs7424-p、dxs7423-p、dxs6789-p、dxs9902-p、dxs6810-p、dxs8377-p、dxs101-p、hprtb-p、dxs8378-p、dxs6797-p、dxs6804和gata165b12-p的引物对;
所述dxsgata31e08-p由序列表中序列1和2所示的两条单链dna组成;
所述dxs10079-p由序列表中序列3和4所示的两条单链dna组成;
所述dxs10103-p由序列表中序列5和6所示的两条单链dna组成;
所述dxs7132-p由序列表中序列7和8所示的两条单链dna组成;
所述dxs9895-p由序列表中序列9和10所示的两条单链dna组成;
所述dxs7133-p由序列表中序列11和12所示的两条单链dna组成;
所述dxs7424-p由序列表中序列13和14所示的两条单链dna组成;
所述dxs7423-p由序列表中序列15和16所示的两条单链dna组成;
所述dxs6789-p由序列表中序列17和18所示的两条单链dna组成;
所述dxs9902-p由序列表中序列19和20所示的两条单链dna组成;
所述dxs6810-p由序列表中序列21和22所示的两条单链dna组成;
所述dxs8377-p由序列表中序列23和24所示的两条单链dna组成;
所述dxs101-p由序列表中序列25和26所示的两条单链dna组成;
所述hprtb-p由序列表中序列27和28所示的两条单链dna组成;
所述dxs8378-p由序列表中序列29和30所示的两条单链dna组成;
所述dxs6797-p由序列表中序列31和32所示的两条单链dna组成;
所述dxs6804由序列表中序列33和34所示的两条单链dna组成;
所述gata165b12-p由序列表中序列35和36所示的两条单链dna组成。
所述成套试剂可由所述dxsgata31e08-p、所述dxs10079-p、所述dxs10103-p、所述dxs7132-p、所述dxs9895-p、所述dxs7133-p、所述dxs7424-p、所述dxs7423-p、所述dxs6789-p、所述dxs9902-p、所述dxs6810-p、所述dxs8377-p、所述dxs101-p、所述hprtb-p、所述dxs8378-p、所述dxs6797-p、所述dxs6804、所述gata165b12-p以及名称为amelogenin-p的引物对组成;
所述amelogenin-p由序列表中序列37和38所示的两条单链dna组成。
所述成套试剂还可用于扩增各引物对所对应的基因座位点进行扩增。
上述成套试剂中,每个引物对中均可由荧光物质标记。
所述荧光物质标记引物对是为了更好的区分观察所述成套试剂的pcr扩增结果,所以,各引物对标记的荧光物质的种类只要能实现上述目的即可。所述荧光物质可为fam、hex、tamn和/或roxn。
在本发明的一个实施例中,所述amelogenin-p、所述dxsgata31e08-p、所述dxs10079-p、所述dxs10103-p、所述dxs7132-p和所述dxs9895-p标记有fam;所述dxs7133-p、所述dxs7424-p、所述dxs7423-p和所述dxs6789-p标记有hex;所述dxs9902-p、所述dxs6810-p、所述dxs8377-p和所述dxs101-p标记有tamn;所述hprtb-p、所述dxs8378-p、所述dxs6797-p、所述dxs6804和所述gata165b12-p标记有roxn。
上述成套试剂中,该成套试剂中各引物对的两条单链dna的摩尔比均为1:1。
所述成套试剂中,所述dxsgata31e08-p、所述dxs10079-p、所述dxs10103-p、所述dxs7132-p、所述dxs9895-p、所述dxs7133-p、所述dxs7424-p、所述dxs7423-p、所述dxs6789-p、所述dxs9902-p、所述dxs6810-p、所述dxs8377-p、所述dxs101-p、所述hprtb-p、所述dxs8378-p、所述dxs6797-p、所述dxs6804-p、所述gata165b12-p和所述amelogenin-p的两条引物的摩尔比可为1.5:1.5:3:3:3:3:3.2:3.2:1:1:1.9:1.9:3:3:1.5:1.5:1.5:1.5:2.5:2.5:2.5:2.5:3:3:3.5:3.5:2:2:3:3:2.5:2.5:2.5:2.5:2:2:0.8:0.8。
所述成套试剂的各单链dna可独立包装,也可将各引物对独立包装,也可将所有引物包装在一起。
为解决上述技术问题,本发明还提供了用于鉴定人类个体间是否具有共同来源x染色体关系的系统,所述系统包括所述成套试剂。
所述系统可由所述成套试剂与确定基因座位点dna序列或对基因座位点进行分型所需的试剂组成。
为解决上述技术问题,本发明还提供了下述ⅰ或ⅱ的应用:
ⅰ、所述成套试剂的下述任一应用:
x1、在制备鉴定人类个体间是否具有共同来源x染色体关系的试剂盒中的应用;
x2、在鉴定人类个体间是否具有共同来源x染色体关系中的应用;
x3、在制备扩增人类基因座位点试剂盒中的应用;
x4、在扩增所述人类基因座位点中的应用;
ⅱ、检测人类基因座位点的物质在鉴定是否具有共同来源x染色体关系中的应用;
所述人类基因座位点包括x染色体上的dxsgata31e08、dxs10079、dxs10103、dxs7132、dxs9895、dxs7133、dxs7424、dxs7423、dxs6789、dxs9902、dxs6810、dxs8377、dxs101、hprtb、dxs8378、dxs6797、dxs6804和gata165b12。
上述应用中,所述人类基因座位点为x染色体上的dxsgata31e08、dxs10079、dxs10103、dxs7132、dxs9895、dxs7133、dxs7424、dxs7423、dxs6789、dxs9902、dxs6810、dxs8377、dxs101、hprtb、dxs8378、dxs6797、dxs6804和gata165b12以及amelogenin。
为解决上述技术问题,本发明还提供了鉴定人类个体间是否具有共同来源x染色体关系的方法,所述方法包括:检测待测样本a和待测样本b的人类基因座位点是否具有单亲遗传关系,如具有单亲遗传关系,所述待测样本a和所述待测样本b具有或候选具有共同来源x染色体;如不具有单亲遗传关系,所述待测样本a和所述待测样本b不具有或候选不具有共同来源x染色体;
所述人类基因座位点包括x染色体上的dxsgata31e08、dxs10079、dxs10103、dxs7132、dxs9895、dxs7133、dxs7424、dxs7423、dxs6789、dxs9902、dxs6810、dxs8377、dxs101、hprtb、dxs8378、dxs6797、dxs6804和gata165b12。
所述具有单亲遗传关系是指所述待测样本a和所述待测样本b中,所述人类基因座位点中的任何一个位点均至少有一个位点相同。所述位点相同可通过测序或对位点分型确定,可表现为序列相同或分型相同。
上述方法中,所述检测待测样本a和待测样本b的人类基因座位点是否具有单亲遗传关系采用所述成套试剂进行。
上述方法中,所述人类基因座位点为x染色体上的dxsgata31e08、dxs10079、dxs10103、dxs7132、dxs9895、dxs7133、dxs7424、dxs7423、dxs6789、dxs9902、dxs6810、dxs8377、dxs101、hprtb、dxs8378、dxs6797、dxs6804和gata165b12以及amelogenin。
本发明中,所述人类可为下述a1)或a2):
a1)中国人;
a2)中国汉族。
本发明中,所述具有共同来源x染色体关系可为以下关系:父女关系、母子关系、母女关系、同父姐妹关系、同母同父姐弟关系、同母同父兄妹关系或祖母与孙女关系。
实验证明,本发明的成套试剂可以用于检测个体间是否具有共同来源x染色体,个体识别率高,非父排除率高,灵敏度高。
附图说明
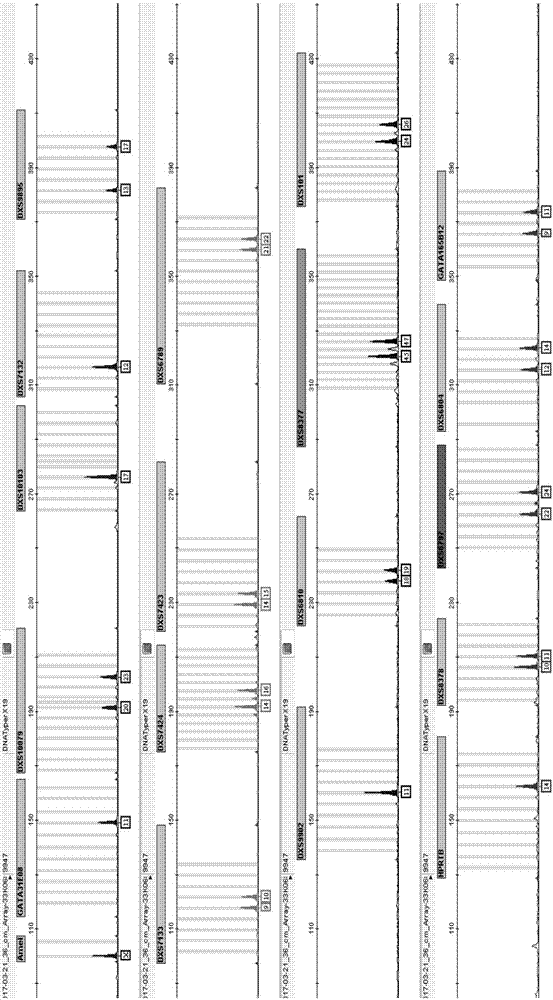
图1为ladder分型图谱。
图2为9947a的分型结果。
图3为男子甲的分型结果图。
图4为男子甲的候选母亲的分型结果图。
图5为女子甲的分型结果图。
图6为女子甲的候选父亲的分型结果图。
图7为女子乙的分型结果图。
图8为女子乙的候选妹妹女子丙的分型结果图。
图9-11为对比例1的结果,图中方框中的ol表示杂峰。
图1-11中,下面标注有方框的峰为有效峰,方框中的数字代表分型,峰的高度代表产物的丰度,峰的颜色为荧光经激发后产生的颜色,其中,蓝色的峰代表经fam标记的扩增产物,绿色的峰代表经hex标记的扩增产物,黑色的峰代表经tamn标记的扩增产物,红色的峰代表经roxn标记的扩增产物,每幅图从上到下四行峰的颜色分别为蓝色、绿色、黑色和红色。amel表示amelogenin,gata31e08表示dxsgata31e08。
具体实施方式
下面结合具体实施方式对本发明进行进一步的详细描述,给出的实施例仅为了阐明本发明,而不是为了限制本发明的范围。下述实施例中的实验方法,如无特殊说明,均为常规方法。下述实施例中所用的材料、试剂、仪器等,如无特殊说明,均可从商业途径得到。以下实施例中的定量试验,均设置三次重复实验,结果取平均值。下述实施例中,如无特殊说明,序列表中各核苷酸序列的第1位均为相应dna的5′末端核苷酸,末位均为相应dna的3′末端核苷酸。
实施例1、人类亲权鉴定成套试剂的制备
本实施例提供的人类亲权鉴定成套试剂基于18个x染色体基因座位点(记为x-str基因座位点)dxsgata31e08、dxs10079、dxs10103、dxs7132、dxs9895、dxs7133、dxs7424、dxs7423、dxs6789、dxs9902、dxs6810、dxs8377、dxs101、hprtb、dxs8378、dxs6797、dxs6804、gata165b12和1个用于鉴定性别的基因座位点amelogenin,由依次对应于这19个基因座的名称分别为dxsgata31e08-p、dxs10079-p、dxs10103-p、dxs7132-p、dxs9895-p、dxs7133-p、dxs7424-p、dxs7423-p、dxs6789-p、dxs9902-p、dxs6810-p、dxs8377-p、dxs101-p、hprtb-p、dxs8378-p、dxs6797-p、dxs6804-p、gata165b12-p、amelogenin-p的引物对组成;
dxsgata31e08-p由序列表中序列1和2所示的两条单链dna组成;
dxs10079-p由序列表中序列3和4所示的两条单链dna组成;
dxs10103-p由序列表中序列5和6所示的两条单链dna组成;
dxs7132-p由序列表中序列7和8所示的两条单链dna组成;
dxs9895-p由序列表中序列9和10所示的两条单链dna组成;
dxs7133-p由序列表中序列11和12所示的两条单链dna组成;
dxs7424-p由序列表中序列13和14所示的两条单链dna组成;
dxs7423-p由序列表中序列15和16所示的两条单链dna组成;
dxs6789-p由序列表中序列17和18所示的两条单链dna组成;
dxs9902-p由序列表中序列19和20所示的两条单链dna组成;
dxs6810-p由序列表中序列21和22所示的两条单链dna组成;
dxs8377-p由序列表中序列23和24所示的两条单链dna组成;
dxs101-p由序列表中序列25和26所示的两条单链dna组成;
hprtb-p由序列表中序列27和28所示的两条单链dna组成;
dxs8378-p由序列表中序列29和30所示的两条单链dna组成;
dxs6797-p由序列表中序列31和32所示的两条单链dna组成;
dxs6804由序列表中序列33和34所示的两条单链dna组成;
gata165b12-p由序列表中序列35和36所示的两条单链dna组成,
amelogenin-p由序列表中序列37和38所示的两条单链dna组成。
该成套试剂中的各引物对均能扩增得到相应的基因座。
该成套试剂中各引物对的两条单链dna的摩尔比均为1:1,dxsgata31e08-p、dxs10079-p、dxs10103-p、dxs7132-p、dxs9895-p、dxs7133-p、dxs7424-p、dxs7423-p、dxs6789-p、dxs9902-p、dxs6810-p、dxs8377-p、dxs101-p、hprtb-p、dxs8378-p、dxs6797-p、dxs6804-p、gata165b12-p和amelogenin-p的摩尔比依次为1.5:3:3:3.2:1:1.9:3:1.5:1.5:2.5:2.5:3:3.5:2:3:2.5:2.5:2:0.8(每个引物对均以正向引物计,序列表中奇数序列均为相应引物对的正向引物)。
该成套试剂中,每个引物对的正向引物的5’端具有荧光物质标记,amelogenin-p、dxsgata31e08-p、dxs10079-p、dxs10103-p、dxs7132-p、dxs9895-p的正向引物5’端标记fam;dxs7133-p、dxs7424-p、dxs7423-p、dxs6789-p的正向引物5’端标记hex;dxs9902-p、dxs6810-p、dxs8377-p、dxs101-p的正向引物5’端标记tamn;hprtb-p、dxs8378-p、dxs6797-p、dxs6804、gata165b12-p的正向引物5’端标记roxn。
实施例2、人类亲权鉴定成套试剂的鉴定人类亲缘关系
一、待测样本
代表人类样本的细胞标准品9947a(女性)(苏州新海生物科技股份有限公司);
中国汉族血液样本:男子甲与作为其候选母亲的亲生母亲的血液样本;女子甲与作为其候选父亲的亲生父亲的血液样本;女子乙以及与作为其候选妹妹的非同一父亲的女子丙的血液样本。
二、鉴定过程
提取各样本的基因组dna,利用实施例1的成套试剂进行pcr扩增。pcr反应体系如下:实施例1的成套试剂4μl、pcr反应液(克劳宁(北京)生物科技有限公司)5μl、样本基因组dna1μl。该反应体系中dxsgata31e08-p的两条引物的浓度均为0.15μm,其余引物对的浓度与dxsgata31e08-p均满足实施例1中各引物间的摩尔比关系。利用无菌水作为阴性对照。
pcr反应条件如下:72℃20min,95℃15min,94℃30s,59℃45s,72℃1min,28cycles,72℃60min。
将得到的pcr产物加入电泳上样液(ab公司),离心后用3130遗传分析仪进行毛细管电泳并进行分型。
毛细管电泳后,对电泳结果进行判读,确定具有共同x染色体来源的两个待测样本间是否具有血缘关系,该血缘关系包括父女关系、母子关系、母女关系、同父姐妹关系、同母同父姐弟及兄妹关系、祖母与孙女等:
如两个待测样本间的18个x-str基因座位点dxsgata31e08、dxs10079、dxs10103、dxs7132、dxs9895、dxs7133、dxs7424、dxs7423、dxs6789、dxs9902、dxs6810、dxs8377、dxs101、hprtb、dxs8378、dxs6797、dxs6804、gata165b12的分型均符合单亲遗传关系,则二者具有上述一种血缘关系,如两个待测样本间的分型至少有一个不符合单亲遗传关系,则二者不具有上述任一种血缘关系。
三、鉴定结果
检测过程中采用包含基因座位点dxsgata31e08、dxs10079、dxs10103、dxs7132、dxs9895、dxs7133、dxs7424、dxs7423、dxs6789、dxs9902、dxs6810、dxs8377、dxs101、hprtb、dxs8378、dxs6797、dxs6804、gata165b12和amelogenin在中国人群中常见分型的ladder确定各扩增产物大小。该ladder的分型图见图1。
9947a的分型结果如图2所示,结果与预期一致。
男子甲与其候选母亲的结果如图3和图4所示,比较二者的分型结果,男子甲与其候选母亲的18个x-str基因座位点的分型均符合单亲遗传关系,这与已知的二者的关系一致。
女子甲与其候选父亲的结果如图5和图6所示,比较二者的分型结果,女子甲与其候选父亲的18个x-str基因座位点的分型均符合单亲遗传关系,这与已知的二者的关系一致。
女子乙与其候选妹妹的结果如图7和图8所示,比较二者的分型结果,18个x-str基因座位点中,女子乙与其候选妹妹的分型dxsgata31e08、dxs7424、dxs7423、dxs8377、dxs101、hprtb和dxs8378的分型结果不同,排除其为同一父亲所生,这与已知的二者的关系一致。
四、累积个人识别率与累计非父排除率
分析18个x-str基因座位点在随机选取的384个中国汉族女性组成的女性群体以及在随机选取的384个中国汉族男性组成的男性群体中的累计个人识别率,在女性群体中的累积个人识别率为0.99999999,在男性群体的累积个人识别率为0.99999993,表明,实施例1的18个x-str基因座位点和成套试剂具有很高的个体识别率。
分析18个x-str基因座位点的累计非父排除率,其在三联体的累积非父排除率为0.99999999,在二联体中的累积非父排除率为0.999999326,表明,实施例1的18个x-str基因座位点和成套试剂具有很高的累计非父排除率。其中,三联体特指父亲-母亲-子女三个个体进行亲缘关系鉴定,二联体特指父亲-女儿或母亲-儿子两个个体进行亲缘关系鉴定。
实施例3、实施例1的成套试剂的灵敏度
以标准品9947a的基因组dna(1ng/μl)为模板,利用实施例1的成套试剂与实施例2的pcr反应体系进行pcr扩增,模板在反应体系中的含量设置为如下梯度:50pg,75pg,100pg,200pg,500pg,1ng,其他试剂与用量以及反应条件均同实施例2,确定dna最低检出量。
结果显示,在反应体系中模板的含量为100pg-1ng时,19个基因座位点均能得到正确的分型,在反应体系中模板的含量为50pg-75pg时,实施例1的19个基因座位点不能完全得到正确分型,表明,实施例1的成套试剂检测dna的最低检出量为0.1ng,即实施例1的成套试剂的灵敏度为0.01ng/μl;实施例1的成套试剂检测dna时的最佳模板含量为0.1ng-1ng。
实施例4、检测条件的优化
一、扩增体系的优化
1、mg2+浓度的优化:
以标准品9947a的基因组dna(1ng/μl)为模板,利用实施例1的成套试剂进行pcr扩增,mg2+在反应体系中的浓度设置为如下梯度:1.5,2.0,2.5,3,3.5,4.0mmol/l,反应体系具体如下:5μlpcr反应液,4μl实施例1中的成套试剂,1μl9947a基因组dna,mg2+的原始浓度为1.5mmol/l,根据不同的mg2+浓度在反应体系中添加mg2+。反应体系中dxsgata31e08-p的两条引物的浓度均为0.15μm,其余引物对的浓度与dxsgata31e08-p均满足实施例1中各引物间的摩尔比关系。
反应条件同实施例2,确定最适合扩增体系的mg2+浓度。
结果显示,在反应体系中mg2+的浓度为2.0mmol/l时,19个基因座位点均能得到正确的分型,在反应体系中mg2+的浓度为1.5mmol/l时,实施例1的19个基因座位点不能完全得到正确分型,在反应体系中mg2+的浓度为2.5-4.0mmol/l时,部分基因座位点扩增不完全,主峰丢失。表明,利用实施例1的成套试剂检测dna的最适mg2+浓度为2.0mmol/l。
2、引物浓度优化:
以标准品9947a的基因组dna(1ng/μl)为模板,利用实施例1的成套试剂进行pcr扩增,dxsgata31e08-p的两条引物在反应体系中的浓度设置为如下梯度:0.1,0.15,0.20,0.25,0.30,0.35μmol/l,其余引物对的浓度与dxsgata31e08-p均满足实施例1中各引物间的摩尔比关系。反应体系具体如下:5μlpcr反应液,2.5μl成套试剂,1μl9947a基因组dna,1.5μl超纯水。
反应条件同实施例2,确定最适合扩增体系的引物浓度。
结果显示,在实施例1的各引物配比下,dxsgata31e08-p的两条引物在反应体系中的浓度为0.25μmol/l时,19个基因座位点均能得到正确的分型,在反应体系中的浓度为0.2μmol/l时,实施例1的19个基因座位点不能完全得到正确分型,在反应体系中的浓度为0.1-0.2μmol/l时,各个基因座的峰很低,无法获得分型结果,在反应体系中的浓度为0.3-0.35μmol/l时,部分基因座位点的扩增受到抑制,出现杂峰或主峰丢失。表明,在实施例1的各引物配比下,利用实施例1的成套试剂检测dna的dxsgata31e08-p的两条引物最适浓度为0.25μmol/l。
3、引物对间比例优化:
以标准品9947a的基因组dna(1ng/μl)为模板,利用实施例1的成套试剂进行pcr扩增,反应体系具体如下:5μlpcr反应液,4μl成套试剂,1μl9947a基因组dna。dxsgata31e08-p、dxs10079-p、dxs10103-p、dxs7132-p、dxs9895-p、dxs7133-p、dxs7424-p、dxs7423-p、dxs6789-p、dxs9902-p、dxs6810-p、dxs8377-p、dxs101-p、hprtb-p、dxs8378-p、dxs6797-p、dxs6804-p、gata165b12-p和amelogenin-p的摩尔比为的摩尔比设置为如下①、②、③、④、⑤、⑥、⑦,每个引物对的两条引物的摩尔比均为1:1,引物对间的摩尔比均以正向引物计:
①0.8:0.8:0.8:0.8:0.8:0.8:0.8:0.8:0.8:0.8:0.8:0.8:0.8:0.8:0.8:0.8:0.8:0.8:0.8;dxsgata31e08-p的两条引物在反应体系中的浓度均为0.8μmol/l;
②0.8:1.5:1.7:2.0:0.8:1.0:2:0.9:0.9:1.6:1.5:2:2.4:1:1.6:1.7:1.5:1:0.8;dxsgata31e08-p的两条引物在反应体系中的浓度均为0.8μmol/l;
③0.8:2.2:2.2:2.4:0.8:1.0:2.2:0.9:0.9:1.8:1.7:2:2.7:1.2:2:1.8:1.8:1.2:0.8;dxsgata31e08-p的两条引物在反应体系中的浓度均为0.8μmol/l;
④0.9:2.4:2.4:2.6:0.8:1.3:2.4:0.9:1.0:2:2:2.4:2.9:1.4:2.4:2:2:1.4:0.8;dxsgata31e08-p的两条引物在反应体系中的浓度均为0.9μmol/l;
⑤1.1:2.6:2.6:2.8:0.8:1.5:2.6:1.1:1.1:2.1:2.1:2.6:3.1:1.6:2.6:2.1:2.1:1.6:0.8;dxsgata31e08-p的两条引物在反应体系中的浓度均为1.1μmol/l;
⑥1.3:2.8:2.8:3:0.8:1.7:2.8:1.3:1.3:2.3:2.3:2.8:3.3:1.8:2.8:2.3:2.3:1.8:0.8;dxsgata31e08-p的两条引物在反应体系中的浓度均为1.3μmol/l;
⑦1.5:3:3:3.2:1:1.9:3:1.5:1.5:2.5:2.5:3:3.5:2:3:2.5:2.5:2:0.8;dxsgata31e08-p的两条引物在反应体系中的浓度均为1.5μmol/l。
结果显示,在各引物对的摩尔比为⑦时,19个基因座位点均能得到正确的分型,在各引物对的摩尔比为①时,实施例1的19个基因座位点不能完全得到正确分型,在各引物对的摩尔比为②、③、④、⑤、⑥时,会出现部分位点扩增不完全,非特异性扩增、主峰丢失等结果。表明,利用实施例1的成套试剂中dxsgata31e08-p、dxs10079-p、dxs10103-p、dxs7132-p、dxs9895-p、dxs7133-p、dxs7424-p、dxs7423-p、dxs6789-p、dxs9902-p、dxs6810-p、dxs8377-p、dxs101-p、hprtb-p、dxs8378-p、dxs6797-p、dxs6804-p、gata165b12-p和amelogenin-p的摩尔比为1.5:3:3:3.2:1:1.9:3:1.5:1.5:2.5:2.5:3:3.5:2:3:2.5:2.5:2:0.8时,为检测dna的最适引物对配比。
二、扩增条件的优化
1、退火温度
以标准品9947a的基因组dna(0.1ng/μl)为模板,利用实施例1的成套试剂进行pcr扩增,pcr扩增的反应体系均同实施例2。
pcr扩增的反应条件为72℃20min;95℃15min;94℃30s,退火温度45s,72℃1min,28个循环;72℃60min。退火温度设置为55,56,57,58,59,60,61,62℃。
结果显示,在退火温度为59℃时,19个基因座位点均能得到正确的分型,在退火温度为55、56、57、58、60、61、62℃时,实施例1的19个基因座位点不能完全得到正确分型,表明,利用实施例1的成套试剂检测dna的最佳退火温度为59℃。
2、pcr循环数
以标准品9947a的基因组dna(0.1ng/μl)为模板,利用实施例1的成套试剂进行pcr扩增,pcr扩增的反应体系均同实施例2。
pcr扩增的反应条件为72℃20min;95℃15min;94℃30s,59℃45s,72℃1min,循环数;72℃60min。循环数设置为28,29,30,31,32。
结果显示,在循环数为28时,19个基因座位点均能得到正确的分型,在循环数为29,30,31,32时,实施例1的19个基因座位点不能完全得到正确分型,表明,利用实施例1的成套试剂检测dna的最佳循环数为28。
最终确定最佳扩增条件为72℃20min;95℃15min;94℃30s,59℃45s,72℃1min,28个循环;72℃60min。
对比例1、其他引物的实验
将实施例1中的成套试剂中的引物进行如下替换,并对标准品9947a的基因组dna进行pcr扩增:
替换1:将dxs10103位点的引物替换为:正向引物-acttctcagccttcataatcacata,反向引物-gcctttgcaacaaattgt;
替换2:将dxs9895位点的引物替换为:正向引物-ggcggaagtggaacaaaac,反向引物-ccaggtccctctcacaac;
替换3:将dxs6810位点的引物替换为:正向引物-ctacctaacagaaaaccttttggg,反向引物-ccaccatacccagccctgaatat。
实施例1中的成套试剂进行替换1后无论pcr反应体系与扩增条件进行如何优化结果中总会出现基因座位点扩增不全(图9);实施例1中的成套试剂进行替换2后无论pcr反应体系与扩增条件进行如何优化结果中总会出现杂峰(ol)(图10);实施例1中的成套试剂进行替换3后无论pcr反应体系与扩增条件进行如何优化结果中总会出现非特异性扩增(部分位点出现3个峰)(图11)。
<110>公安部物证鉴定中心
<120>人类x染色体18个基因座复合扩增体系
<160>38
<170>patentinversion3.5
<210>1
<211>21
<212>dna
<213>人工序列
<400>1
agagctggtgatgatagatga21
<210>2
<211>19
<212>dna
<213>人工序列
<400>2
cagctgacagagcacagag19
<210>3
<211>24
<212>dna
<213>人工序列
<400>3
caagtgagaccaaaaaaagagaga24
<210>4
<211>23
<212>dna
<213>人工序列
<400>4
atgtgttgttgagttcagtttgc23
<210>5
<211>25
<212>dna
<213>人工序列
<400>5
acttctcagccttcataatcacata25
<210>6
<211>18
<212>dna
<213>人工序列
<400>6
gcctttgcaacaaattgt18
<210>7
<211>27
<212>dna
<213>人工序列
<400>7
tacagttcatacaatggacaatcagtg27
<210>8
<211>23
<212>dna
<213>人工序列
<400>8
agcctccttaatagtgtgagccc23
<210>9
<211>19
<212>dna
<213>人工序列
<400>9
ggcggaagtggaacaaaac19
<210>10
<211>18
<212>dna
<213>人工序列
<400>10
ccaggtccctctcacaac18
<210>11
<211>21
<212>dna
<213>人工序列
<400>11
agcttccttagatggcattca21
<210>12
<211>24
<212>dna
<213>人工序列
<400>12
catcttccaagaatcagaagtctc24
<210>13
<211>20
<212>dna
<213>人工序列
<400>13
agcagcaaacactagagcaa20
<210>14
<211>19
<212>dna
<213>人工序列
<400>14
caggaattcaaggcctgcc19
<210>15
<211>20
<212>dna
<213>人工序列
<400>15
tggcctttgtctccagtacc20
<210>16
<211>19
<212>dna
<213>人工序列
<400>16
tgcgagcccactctttcta19
<210>17
<211>19
<212>dna
<213>人工序列
<400>17
ccatctgtttcaaggtggt19
<210>18
<211>19
<212>dna
<213>人工序列
<400>18
ttgcagacagcctattgtg19
<210>19
<211>22
<212>dna
<213>人工序列
<400>19
ctgttcttgtaacttttctgtc22
<210>20
<211>22
<212>dna
<213>人工序列
<400>20
agcaatacacattcatatcagg22
<210>21
<211>24
<212>dna
<213>人工序列
<400>21
ctacctaacagaaaaccttttggg24
<210>22
<211>23
<212>dna
<213>人工序列
<400>22
ccaccatacccagccctgaatat23
<210>23
<211>23
<212>dna
<213>人工序列
<400>23
ccacagtgacccttctgcaacag23
<210>24
<211>25
<212>dna
<213>人工序列
<400>24
tatttttgctccttcgttccctgtc25
<210>25
<211>21
<212>dna
<213>人工序列
<400>25
tacacctgggctgagcaagtt21
<210>26
<211>17
<212>dna
<213>人工序列
<400>26
ggcaagggaagggatag17
<210>27
<211>20
<212>dna
<213>人工序列
<400>27
ccatctctgtctccatcttt20
<210>28
<211>19
<212>dna
<213>人工序列
<400>28
acccctgtctatggtctcg19
<210>29
<211>18
<212>dna
<213>人工序列
<400>29
caggaggtttgacctgtt18
<210>30
<211>19
<212>dna
<213>人工序列
<400>30
actgagatggtgccactga19
<210>31
<211>25
<212>dna
<213>人工序列
<400>31
ctctttccctctctccctctgtctc25
<210>32
<211>19
<212>dna
<213>人工序列
<400>32
cacacacccaaaaccagat19
<210>33
<211>26
<212>dna
<213>人工序列
<400>33
aaatggggtctcactatattgcctaa26
<210>34
<211>26
<212>dna
<213>人工序列
<400>34
taaccaagccaagacgctacctacac26
<210>35
<211>20
<212>dna
<213>人工序列
<400>35
tctccctctgaattgcgtct20
<210>36
<211>19
<212>dna
<213>人工序列
<400>36
gggcatctattagccaagc19
<210>37
<211>21
<212>dna
<213>人工序列
<400>37
gacagagcacatccatctgat21
<210>38
<211>18
<212>dna
<213>人工序列
<400>38
acagaaaaccctctcacg18
- 还没有人留言评论。精彩留言会获得点赞!