新型的甘油单-二酰酯脂肪酶的制作方法
本申请属于酶工程领域,具体地,涉及具有脂肪酶活性的多肽、其编码核酸,以及包含所述编码核酸的表达载体和宿主细胞。本申请还涉及上述多肽的筛选方法及其用途。
发明背景
脂肪酶是酯酶的一种,可以催甘油三酯、甘油二酯、甘油单酯、其它小分子酯、多元醇酯和多元酸酯酯键的水解,脂肪为脂肪酶的天然底物,水解的过程中会产生甘油二酯和甘油单酯,水解最终产物为甘油和脂肪酸。脂肪酶水解条件温和,副产物少,不需要辅酶。脂肪多为疏水物质,因此水解反应发生在油水界面或者有机相中。甘油单-二酰酯脂肪酶(mdgl)是脂肪酶的一种,mdgl具有底物特异性,仅作用于甘油单酰酯(mag)和甘油二酰酯(dag),对甘油三酰酯不起催化作用,可以利用酯化或转酯化反应来生产具有较高工业价值的甘油单酰酯。
mag是一种优良的乳化剂,在食品、医药和化妆品工业中有广泛的应用。mag的传统合成工艺是在高温下,以无机碱为催化剂,在氮气条件下通过油脂/甘油三酯(tag)与甘油连续酯化进行生产,产物为mag、dag和tag的混合物,通过蒸馏获得mag,mag的产率为40-50%。与传统合成工艺不同,酶法合成mag是以脂肪酸和甘油为底物,在温和条件下催化合成mag,酶法催化中脂肪酸的转化率超过97%,mag在产物中的占比超过74%。目前限制酶法应用的主要问题是酶的活力较低和酶的成本较高。
发明概述
第一方面,提供了具有甘油单-二酰酯脂肪酶活性的多肽,其包含选自以下的序列或由选自以下的序列组成:
(a)如seqidno:1所示的氨基酸序列,以及
(b)由(a)所述的序列经过取代、缺失或添加至少一个氨基酸后得到的序列,其中由(b)获得的多肽变体仍保持甘油单-二酰酯脂肪酶活性。
在一实施方案中,本申请的多肽包含seqidno:1所示的氨基酸序列。在优选的实施方案中,上述多肽由seqidno:1所示的氨基酸序列组成。在本文中,由seqidno:1所示的氨基酸序列组成的多肽被命名为mdgl-new。
第二方面,提供了编码第一方面的多肽的多核苷酸,其包含选自以下的序列或由选自以下的序列组成:
(a)核苷酸序列,其编码seqidno:1所示的氨基酸序列或在上述序列中包含至少一个氨基酸取代、缺失或添加的序列;以及
(b)在严格条件下与a)中的核苷酸序列杂交的核苷酸序列。
在一实施方案中,本申请的多核苷酸其包含seqidno:2所示的核苷酸序列。在优选的实施方案中,上述多核苷酸由seqidno:2所示的核苷酸序列组成。
第三方面,提供了表达载体,其包含至少一种第二方面的多核苷酸。
在某些实施方案中,本申请的表达载体还包含调节多核苷酸表达的调控序列,其中多核苷酸与调控序列可操作地连接。在优选的实施方案中,所述表达载体为质粒载体,例如p0586-g50。
第四方面,提供了包含第二方面的多核苷酸或第三方面的表达载体的宿主细胞。在具体的实施方案中,宿主细胞为酵母例如毕赤酵母、或者大肠杆菌。
第五方面,提供了第一方面的多肽在制备甘油单酰酯中的用途。
第六方面,提供了合成甘油单酰酯的方法,其包括将第一方面的多肽与脂肪酸和甘油进行接触。
第七方面,提供了筛选本申请的多肽的方法,其包括:
1)将seqidno:3所示的核苷酸序列进行随机突变,得到突变序列集合,
2)将步骤1)中获得的突变序列克隆在表达载体上,然后转化或转导至合适的宿主细胞中,得到突变体库,
3)培养步骤2)中的宿主细胞,回收重组表达载体,然后将线性化产物转化至酵母菌株中培养,以及
4)筛选酶活力高于seqidno:4所示的多肽的活力的突变多肽。
另外,本申请还提供了seqidno:3所示的核酸序列用于筛选本文公开的多肽的用途。
通过本文公开的筛选方法得到的多肽具有高脂肪酶活性,特别是甘油单-二酰酯脂肪酶活性。
附图简要说明
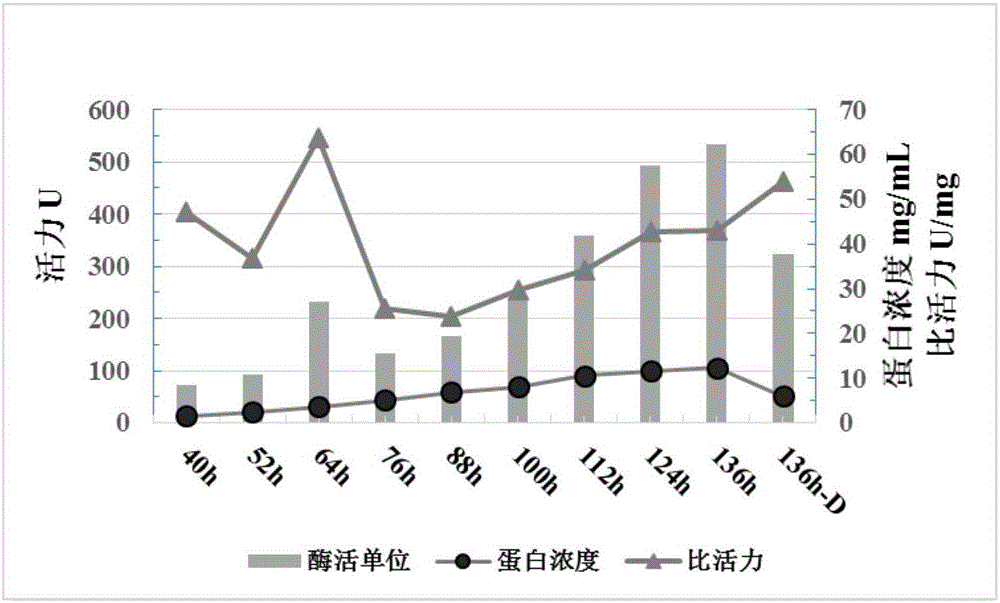
图1显示了毕赤酵母gs1157.5l发酵罐中表达的mdgl的蛋白浓度和酶活力,其中基于pnpp法测定了不同发酵时间的mdgl酶活力。
图2显示了商品化酶mdgl和mdgl-new的sds-page结果,其中“m”代表分子标志物,“a”代表商品化酶amanog50,以及“w1”、“w2”和“w3”代表mdgl-new。
序列简要说明
seqidno:1:mdgl-new的氨基酸序列;
seqidno:2:mdgl-new的编码核酸序列;
seqidno:3:优化后的mdgl核酸序列;
seqidno:4:优化后的mdgl氨基酸序列;
seqidno:5:优化后的mdgl的正向扩增引物;
seqidno:6:优化后的mdgl的反向扩增引物:
seqidno:7:mdgl-new的正向扩增引物;
seqidno:8:mdgl-new的反向扩增引物;
seqidno:9:mdgl-new的正向扩增引物;
seqidno:10:mdgl-new的反向扩增引物。
具体实施方式
本申请的多肽
本申请提供了具有脂肪酶活性的多肽,特别是甘油单-二酰酯脂肪酶活性的多肽,其包含选自以下的序列或由选自以下的序列组成:
(a)如seqidno:1所示的氨基酸序列,以及
(b)由(a)所述的序列经过取代、缺失或添加至少一个氨基酸后得到的序列,其中由(b)获得的多肽变体仍保持脂肪酶活性。
甘油单-二酰酯脂肪酶(mdgl)是脂肪酶的一种。mdgl有2种形态,分子量分别为37kda和39kda,mdgl有26个氨基酸组成的信号肽,成熟肽包含279个氨基酸。例如可以利用月桂酸乙烯酯作为底物测定mdgl酶活单位。
在某些实施方案中,上述氨基酸取代、缺失或添加的数目为1-30个,优选为1-20个,更优选为1-10个,其中获得的多肽变体基本上保持未改变的蛋白的脂肪酶活性。在优选的实施方案中,上述多肽变体与seqidno:1所示的氨基酸序列相差约1、2、3、4、5、6、7、8、9、或10个氨基酸的取代、缺失和/或添加。在更优选的实施方案中,上述多肽变体与seqidno:1所示的氨基酸序列相差约1、2、3、4或5个氨基酸的取代、缺失或添加。
在一实施方案中,本申请的多肽包含seqidno:1所示的氨基酸序列。在优选的实施方案中,上述多肽由seqidno:1所示的氨基酸序列组成。在本文中,由seqidno:1所示的氨基酸序列组成的多肽被命名为mdgl-new。
本申请seqidno:1的序列如下所示:
dvstseldqfefwvqyaaasyyeadytaqvgdklscskgncpeveatgatvsydfsdstitdtagyiavdhtnsavvlafrgshsvrnwvadatfvhtnpglcdgclaelgfwsswklvrddiikelkevvaqnpdyelvvvghslgaavatlaatdlrgkgypsaklyayasprvgnaalakyitaqgnnfrfthtndpvpklpllsmgyvhvspeywitspnnatvstsdikvidgdvsfdgntgtglplltdfeahiwyfvqvdagkgpglpfkrv
如本文所用的,术语“氨基酸”表示天然存在的和非天然存在的氨基酸以及氨基酸类似物和模拟物。天然存在的氨基酸包括蛋白生物合成中使用的20种(l)-氨基酸以及其他氨基酸,例如4-羟脯氨酸、羟赖氨酸、锁链素、异锁链素、高半胱氨酸、瓜氨酸和鸟氨酸。非天然存在的氨基酸包括例如(d)-氨基酸、正亮氨酸、正缬氨酸、p-氟苯丙氨酸、乙基硫氨酸等,这些是本领域技术人员已知的。氨基酸类似物包括天然和非天然存在的氨基酸的修饰形式。这种修饰可以包括例如取代氨基酸上的化学基团和部分,或者氨基酸的衍生化。氨基酸模拟物包括例如表现出功能上类似性质的有机结构,所述性质例如氨基酸的电荷和电荷空间特性。例如,模拟精氨酸(arg或r)的有机结构具有位于类似分子空间并且具有与天然存在的arg氨基酸的侧链的e-氨基相同程度的移动性的正电荷部分。模拟物还包括约束结构以维持氨基酸或氨基酸官能团的最佳空间和电荷相互作用。本领域技术人员可以确定什么结构构成功能上等效的氨基酸类似物和氨基酸模拟物。
在一些实施方案中,seqidno:1所示的氨基酸序列的变体与seqidno:1具有至少80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%以上的同源性。在优选的实施方案中,多肽变体与seqidno:1所示序列具有99%以上的同源性。
本文所述的“同源性”被定义为经过序列比对和引入空位后,氨基酸或核苷酸序列变体中相同的残基的百分比,如果需要,达到最大百分比的同源性。用于比对的方法和计算机程序在本领域内是公知的。
本申请的“多肽”和“蛋白”在本文可互换使用,指氨基酸残基的聚合物及其变体和合成的和天然存在的类似物。因此,这些术语适用于天然存在的氨基酸聚合物及其天然存在的化学衍生物,以及其中一个或多个氨基酸残基是合成的非天然存在的氨基酸(诸如相应的天然存在的氨基酸的化学类似物)的氨基酸聚合物。此类衍生物包括例如翻译后修饰和降解产物,包括seqidno:1所示的多肽片段的磷酸化的、糖基化的、氧化的、异构化的和脱氨基化的变体。
在优选的实施方案中,多肽变体的序列是在seqidno:1所示的氨基酸序列中包含一个或几个保守性氨基酸取代的序列,其中经取代后的序列仍保持类似的脂肪酶催化活性,特别是甘油单-二酰酯脂肪酶活性。
被称为“保守氨基酸取代”的某些氨基酸取代能够在蛋白质中频繁出现,但不改变该蛋白质的构象或功能,这是蛋白质化学中已建立的法则。
本申请中的保守氨基酸取代包括但不限于用甘氨酸(g)、丙氨酸(a)、异亮氨酸(i)、缬氨酸(v)和亮氨酸(l)中的任一个取代这些脂肪族氨基酸的任何另外一个;用丝氨酸(s)取代苏氨酸(t),反之亦然;用天冬氨酸(d)取代谷氨酸(e),反之亦然;用谷氨酰胺(q)取代天冬酰胺(n),反之亦然;用赖氨酸(k)取代精氨酸(r),反之亦然;用苯丙氨酸(f)、酪氨酸(y)和色氨酸(w)取代这些芳香族氨基酸中的任何另外一个;以及用甲硫氨酸(m)取代半胱氨酸(c),反之亦然。其他的取代也可以被视为是保守性的,这取决于特定氨基酸环境和它在蛋白三维结构中的作用。例如,甘氨酸(g)和丙氨酸(a)经常可以互换,如同丙氨酸(a)和缬氨酸(v)可以互换。相对疏水的甲硫氨酸(m)可以经常与亮氨酸和异亮氨酸互换,以及有时与缬氨酸互换。赖氨酸(k)和精氨酸(r)经常在以下位置互换:其中氨基酸残基的重要特征是其电荷,以及这两种氨基酸残基的不同pk并不明显。在特定的环境下,仍有其他一些变化可以视为“保守性”的(参见,例如,biochemistryatpp.13-15,2nded.lubertstryered.(stanforduniversity);henikoffetal.,proc.nat’lacad.sci.usa(1992)89:10915-10919;leietal.,j.biol.chem.(1995)270(20):11882-11886)。
以下,将氨基酸残基按可取代的残基分类举例,但可取代的氨基酸残基不限于以下记载的残基:
a组:亮氨酸、异亮氨酸、正亮氨酸、缬氨酸、正缬氨酸、丙氨酸、2-氨基丁酸、蛋氨酸、o-甲基丝氨酸、叔丁基甘氨酸、叔丁基甘氨酸及环己基丙氨酸;
b组:天冬氨酸、谷氨酸、异天冬氨酸、异谷氨酸、2-氨基己二酸及2-氨基辛二酸;
c组:天冬酰胺及谷氨酰胺;
d组:赖氨酸、精氨酸、鸟氨酸、2,4-二氨基丁酸即2,3-二氨基丙酸;
e组:脯氨酸、3-羟基脯氨酸及4-羟基脯氨酸;
f组:丝氨酸、苏氨酸及高丝氨酸;
g组:苯丙氨酸及酪氨酸。
在某些实施方案中,本申请的多肽,例如seqidno:1所示多肽或其变体与异源多肽融合。在一些实施方案中,所述融合蛋白基本上保持seqidno:1所示多肽的脂肪酶活性。在某些实施方案中,异源多肽与seqidno:1所示多肽的n端连接。在某些实施方案中,异源多肽与seqidno:1所示多肽的c端连接。在这些实施方案中,异源多肽可以选自纯化标签(例如可以包括但不限于:gst、mbp)、表位标签(例如可以包括但不限于:myc、flag)、靶向序列、信号肽等。
在具体实施方案中,融合蛋白包含seqidno:1所示多肽和标签,所述标签与seqidno:1所示多肽的c-末端或n-末端结合,通常为肽标签。所述标签通常是能够用于分离和纯化所述融合蛋白的肽或氨基酸序列。
多核苷酸
本申请提供了编码本文公开的多肽的多核苷酸,其包含选自以下的序列或由选自以下的序列组成:
(a)核苷酸序列,其编码seqidno:1所示的氨基酸序列或在上述序列中包含至少一个氨基酸取代、缺失或添加的序列;以及
(b)在严格条件下与a)中的核苷酸序列杂交的核苷酸序列。
在某些具体的实施方案中,本申请的多核苷酸编码seqidno:1所示多肽及其功能等同变体。在一实施方案中,本申请的多核苷酸与编码seqidno:1所示多肽及其功能等同变体的多核苷酸具有至少80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%同源性。
在某些实施方案中,本申请的多核苷酸包含与seqidno:2所示的核苷酸序列具有至少80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%同源性的核苷酸序列。在优选的实施方案中,本申请的多核苷酸包含seqidno:2所示的核苷酸序列。
seqidno:2的序列如下所示:
gatgtctccacttccgaactggaccagttcgagttctgggtacaatacgcagccgcctcttactacgaggctgattacaccgcacaggttggtgataagctgtcctgctctaagggtaactgcccagaagttgaagcaaccggtgcaactgtgtcttacgacttctccgattccacgatcactgacaccgcaggttacatcgcagttgatcacaccaactccgcagtggtactggcattccgtggttctcactccgtacgtaactgggttgctgatgctactttcgtccataccaacccaggtctgtgtgatggttgcctggctgagctgggtttctggtcttcctggaagctggttcgtgatgatattatcaaagaactgaaagaagtggtggcacagaacccagactatgaactggtggtcgtgggccactccctgggtgctgctgtggctactctggctgctaccgacctgcgtggtaaaggttatccatctgctaaactgtacgcctacgcttcccctcgtgttggcaacgcagccctggccaaatatatcaccgcccagggcaacaacttccgtttcacccacaccaatgacccagtacctaaactgccactgctgtctatgggctatgtacatgtttctcctgaatattggatcacctctcctaacaacgccactgtttctacctctgacatcaaagtcattgacggcgacgtatcttttgacggcaataccggcacgggcctgcctctgctgacggactttgaagcccacatttggtactttgtacaggttgacgccggcaaaggtcctggcctgccattcaaacgtgtttaa
在优选的实施方案中,本申请的多核苷酸由与seqidno:2所示的核苷酸序列具有90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%同源性的核苷酸序列组成。在更优选的实施方案中,本申请的多核苷酸由seqidno:2所示的核苷酸序列组成。
本文使用的术语“多核苷酸”或“核酸”指mrna、rna、crna、cdna或dna,包括单链和双链形式的dna。该术语通常指至少10个碱基长度的核苷酸多聚形式,所述核苷酸是核糖核苷酸或脱氧核苷酸或任一类型的核苷酸的修饰形式。
在某些实施方案中,本申请的多核苷酸包含与编码seqidno:1所示多肽及其功能等同变体的核苷酸序列在严格条件下杂交的核苷酸序列,或者由与编码seqidno:1所示多肽及其功能等同变体的核苷酸序列特异性杂交且编码与seqidno:1所示多肽在功能上等同的多肽的核苷酸序列组成。
本领域技术人员可以常规选择dna杂交的严格条件。通常较长的探针需要较高的温度,以便进行适当的退火,而较短的探针需要较低的温度。杂交通常取决于当互补链处于低于其解链温度的环境时变性dna的重退火能力。探针与可杂交序列之间同源性程度越高,所能采用的相对温度越高。于是,较高的相对温度往往使反应条件更严格,而在较低的温度下,则严格度较低。关于杂交反应严格条件的详细描述,可参阅ausubel等,currentprotocolsinmolecularbiology,wileyintersciencepublishers,(1995)。
在某些实施方案中,dna杂交采用的严格条件包括:1)洗涤时采用低离子强度和高温,例如50℃下的0.015m氯化钠/0.0015m柠檬酸钠/0.1%十二烷基硫酸钠;2)杂交时采用甲酰胺等变性剂,例如42℃下50%(v/v)甲酰胺加0.1%牛血清白蛋白/0.1%ficoll/0.1%聚二烯吡咯烷酮/ph6.5的50mm磷酸钠缓冲液以及750mm氯化钠、75mm柠檬酸钠;或(3)在42℃下过夜杂交,杂交溶液含50%甲酰胺,5xssc(0.75m氯化钠,0.075m朽1檬酸钠)、50mm磷酸钠(ph6.8)、0.1%焦磷酸钠、5xdenhardt’s溶液、超声波处理的鲑鱼精子dna(50.mu.g/ml)、0.1%sds和10%硫酸葡聚糖,然后在0.2xssc(氯化钠/柠檬酸钠)中于42℃洗涤10分钟,再以含有edta的0.1xssc于55℃进行高严格度洗涤。中等严格条件可按sambrook等,molecularcloning:alaboratorymanual,newyork:coldspringharborpress,1989中的描述加以确定。中等严格条件包括采用严格度低于以上描述的洗涤溶液和杂交条件(如温度、离子强度和sds百分比)。例如,中等严格条件包括用至少约16%v/v到至少约30%v/v的甲酰胺和至少约0.5m到至少约0.9m的盐在42℃杂交,以及用至少约0.1m到至少约0.2m盐在55℃洗涤。中等严格条件还可以包括用1%牛血清白蛋白(bsa)、1mmedta、0.5mnahpo4(ph7.2)、7%sds在65℃杂交,以及用(i)2×ssc、0.1%sds;或(ii)0.5%bsa、1mmedta、40mmnahpo4(ph47.2)、5%sds在60-65℃洗涤。专业人员将会根据探针长度等因素调节温度、离子强度等。杂交核酸时的严格度取决于核酸分子长度和互补程度,以及其它本领域内众所周知的变量。两个核苷酸序列之间的相似性或同源性越大,则含有这些序列的核酸杂合体的tm越大。核酸杂交的相对稳定性(对应于较高的tm)以下列顺序递减:rna:rna、dna:rna,dna:dna。优选地,可杂交核酸的最低长度至少约为12个核苷酸,优选至少约为16个、更优选至少约为24个、最优选至少约为36个核苷酸。
在一些实施方案中,本申请发明人以来源于penicilliurncamembertiiu-150的mdla基因为基础,根据巴斯德毕赤酵母的密码子偏好性,对编码成熟蛋白的序列进行密码子优化,合成的基因以巴斯德毕赤酵母gs115为表达宿主进行表达。
在具体的实施方案中,本申请提供了经过对密码子进行优化后得到的核苷酸序列(seqidno:3),其编码甘油单-二酰酯脂肪酶成熟肽(seqidno:4)。
seqidno:3的序列如下所示:
gatgtctccacttccgaactggaccagttcgagttctgggttcaatacgcagccgcctcttactacgaggctgattacaccgcacaggttggtgataagctgtcctgctctaagggtaactgcccagaagttgaagcaaccggtgcaactgtgtcttacgacttctccgattccacgatcactgacaccgcaggttacatcgcagttgatcacaccaactccgcagtggtactggcattccgtggttcttactccgtacgtaactgggttgctgatgctactttcgtccataccaacccaggtctgtgtgatggttgtctggctgagctgggtttctggtcttcctggaagctggttcgtgatgatattatcaaagaactgaaagaagtggtggcacagaacccaaactatgaactggtggtcgtgggccactccctgggtgctgctgtggctactctggctgctaccgacctgcgtggtaaaggttatccatctgctaaactgtacgcttacgcttcccctcgtgttggcaacgcagccctggccaaatatatcaccgcccagggcaacaacttccgtttcacccacaccaatgacccagtacctaaactgccactgctgtctatgggctatgtacatgtttctcctgaatattggatcacctctcctaacaacgccactgtttctacctctgacatcaaagtcattgacggcgacgtatcttttgacggcaataccggcacgggcctgcctctgctgacggactttgaagcccacatttggtactttgtacaggttgacgccggcaaaggtcctggcctgccattcaaacgtgtttaa
seqidno:4的序列如下所示:
dvstseldqfefwvqyaaasyyeadytaqvgdklscskgncpeveatgatvsydfsdstitdtagyiavdhtnsavvlafrgsysvrnwvadatfvhtnpglcdgclaelgfwsswklvrddiikelkevvaqnpnyelvvvghslgaavatlaatdlrgkgypsaklyayasprvgnaalakyitaqgnnfrfthtndpvpklpllsmgyvhvspeywitspnnatvstsdikvidgdvsfdgntgtglplltdfeahiwyfvqvdagkgpglpfkrv
本申请公开的多核苷酸可以与其他dna序列组合,所述其他dna序列例如启动子、聚腺苷化信号、其他限制性酶切位点、多克隆位点、其他编码节段等,使得它们的总长度可以显著不同。因此考虑可以利用几乎任意长度的多核苷酸片段;总长度优选地受预期重组dna方案中制备和使用的便利性的限制。
可以利用本领域内已知的和可获得的多种成熟技术中的任何一种来制备、操控和/或表达多核苷酸及其融合物。例如,编码本申请的多肽或其变体的多核苷酸序列可以用于重组dna分子中以指导多肽在适当的宿主细胞中表达。由于遗传密码子固有的简并性,编码基本上相同或在功能上等同的氨基酸序列的其他dna序列也可以用于本申请中,并且这些序列可以用于克隆和表达给定的多肽。
此外,可以使用本领域内公知的方法改造本申请的多核苷酸序列,包括但不限于基因产物的克隆、加工、表达和/或活性的改变。
在某些实施方案中,本申请的多核苷酸通过人工合成产生,例如直接的化学合成或酶合成。在可选的实施方案中,上述多核苷酸通过重组技术产生。
在具体的实施方案中,本申请使用的mdgl编码基因mdla来源于penicilliurncamembertiiu-150(genebank号:baa14345.1),将密码子根据巴斯德毕赤酵母的密码子偏好性进行优化,优化后的基因由生工生物工程有限公司合成,将合成好的基因连接到puc57中。
在某些实施方案中,可以通过常规方法优选如双脱氧链终止法(sangeretal.pnas,1977,74:5463-5467)测定所获得的多核苷酸的序列。这类多核苷酸序列测定也可用购买的测序试剂盒来完成。
表达载体
本申请提供了包含本申请的多核苷酸的表达载体。
本申请所述的“表达载体”是重组或合成产生的核酸构建体,其具有一系列允许特定的核酸在宿主细胞中转录的特异性核酸元件。本申请使用的表达载体可以是诸如p0586-g50、puc57、pet-24a(+)、pires2-egfp、pcdna3.1、pci-neo、pdc516、pvac、pcdna4.0、pgem-t、pdc315的质粒载体,或者是诸如腺病毒、腺相关病毒、逆转录病毒、semliki森林病毒(sfv)载体的病毒载体,或者是本领域熟知的其它载体。
在某些实施方案中,编码seqidno:1所示多肽及其变体的多核苷酸序列被克隆到载体中,以构成含有本申请所述多核苷酸的重组载体。
在优选的实施方案中,用于克隆多核苷酸的表达载体为质粒载体。在更优选的实施方案中,所述质粒载体为p0586-g50或puc57。
在具体的实施方案中,上述表达载体还包含调节多核苷酸表达的调控序列,其中所述多核苷酸与所述调控序列可操作地连接。
本文所用的术语“调控序列”是指实现与其连接的编码序列表达所需的多核苷酸序列。这类调控序列的性质随宿主生物而改变。在原核生物中,这类调控序列一般包括启动子、核糖体结合位点和终止子;在真核生物中,这类调控序列一般包括启动子、终止子以及在某些情况下的增强子。因此,术语“调控序列”包括其存在对目的基因的表达是必需的最低限度的所有序列,也可以包括其存在对目的基因表达是有利的其它序列,例如前导序列。
本文所用的术语“可操作地连接”是指如下情形:所涉及到的序列处于允许它们以希望的方式起作用的关系之中。因此,例如“可操作地连接”到一编码序列的调控序列使得在与所述调控序列相容的条件下实现该编码序列的表达。
在某些实施方案中,利用本领域的技术人员熟知的方法构建包含编码seqidno:1所示多肽及其变体的核苷酸序列和合适的转录/翻译调控元件的表达载体。这些方法包括体外重组dna技术、dna合成技术、体内重组技术等(sambroook,etal.molecularcloning,alaboratorymanual,coldspringharborlaboratory.newyork,1989)。核苷酸序列可操作地连接到表达载体中的适当启动子上,以指导mrna合成。这些启动子的代表性实例包括:大肠杆菌的lac或trp启动子;λ噬菌体的pl启动子;真核启动子包括cmv立即早期启动子、hsv胸苷激酶启动子、早期和晚期sv40启动子、反转录病毒的ltrs和其它一些已知的可控制基因在原核细胞或真核细胞或其病毒中表达的启动子。表达载体还包括翻译起始用的核糖体结合位点和转录终止子等。在载体中插入增强子序列将会使其在高等真核细胞中的转录得到增强。增强子是dna表达的顺式作用因子,通常大约有10到300个碱基对,作用于启动子以增强基因的转录。实例包括在复制起始点晚期一侧的100到270个碱基对的sv40增强子、在复制起始点晚期一侧的多瘤增强子以及腺病毒增强子等。
此外,表达载体优选地包含一个或多个选择性标记基因,以提供用于选择转化的宿主细胞的表型性状,如真核细胞培养用的二氢叶酸还原酶、新霉素抗性以及绿色荧光蛋白(gfp),或用于大肠杆菌的四环素或氨苄青霉素抗性等。
宿主细胞
本申请提供了包含本文公开的多核苷酸或表达载体的宿主细胞。
在某些实施方案中,将编码seqidno:1所示多肽及其变体的多核苷酸或含有该多核苷酸的表达载体转化或转导入宿主细胞,获得含有该多核苷酸或表达载体的基因工程化宿主细胞。
本文所用的宿主细胞可以是本领域技术人员熟知的任一种宿主细胞,包括原核细胞、真核细胞,例如细菌细胞、真菌细胞、酵母细胞、哺乳动物细胞、昆虫细胞或植物细胞等。示例性的细菌细胞包括埃希氏菌属、杆菌属、链霉菌属、沙门氏菌属、假单胞菌属和葡萄球菌属中的任何种,包括例如大肠杆菌、乳酸球菌、枯草芽孢杆菌、蜡状芽胞杆菌、鼠伤寒沙门氏菌、荧光假单胞菌。示例性的真菌细胞包括曲霉属的任何种。示例性的酵母细胞包括毕赤酵母属、啤酒酵母菌属、裂殖酵母属或酵母菌属中的任何种,包括毕赤酵母、啤酒酵母或裂殖酵母。示例性的昆虫细胞包括斜纹夜蛾或果蝇中的任何种,包括果蝇s2和斜纹夜蛾sf9。示例性的动物细胞包括cho、cos或黑色素瘤或任何小鼠或人细胞系。选择合适的宿主在本领域技术人员的能力范围内。
在具体的实施方案中,本申请所用的宿主细胞为大肠杆菌。在优选的实施方案中,将携带本申请多核苷酸序列的表达载体转化至大肠杆菌dh5α菌株进行诱导表达。在另一具体的实施方案中,将携带本申请多核苷酸序列的表达载体转化至毕赤酵母细胞中进行表达。可用于本申请的毕赤酵母包括gs115和km71两种,其都具有his4营养缺陷标记。gs115菌株具有aox1基因,是mut+,即甲醇利用正常型;而km71菌株的aox1位点被arg4基因插入,表型为muts,即甲醇利用缓慢型,两种菌株都适用于一般的酵母转化方法。
可以利用本领域已知的任何技术将表达载体导入宿主细胞中,包括转化、转导、转染、病毒感染、基因枪或ti-介导的基因转移。具体的方法包括磷酸钙转染、deae-葡聚糖介导的转染、脂转染或电穿孔等(davis,l.,dibner,m.,battey,i.,basicmethodsinmolecularbiology,(1986))。作为示例,当宿主为原核生物如大肠杆菌时,可在指数生长期后收获感受态细胞,用本领域熟知的cacl2法进行转化。
在具体的实施方案中,将与质粒puc57连接的本申请编码mdgl的序列用avrii和ecori酶切,连接到ppic9k(avrii和ecori酶切)载体上,连接好的载体转入大肠杆菌,挑选单克隆进行菌落pcr验证,阳性菌株测序验证,测序结果正确的菌株用于提取质粒,质粒经bglii线性化后通过电击法转化毕赤酵母,转化物在不含组氨酸的筛选培养基上筛选,只有转化有外源基因片段的重组毕赤酵母才能在筛选培养基上生长。将筛选的培养基上的菌落转接到bmgy-甘油单-二酰酯筛选培养基平板上,根据水解圈大小挑选克隆,进行摇瓶发酵及活力检测,得到重组毕赤酵母-mdgl,使用发酵罐发酵检测蛋白表达能力和酶活力。
本申请的多肽的筛选和制备方法
可以通过本领域技术人员已知的任何合适方法来筛选和制备本申请的多肽。
在一些实施方案中,本文公开的多肽通过易错pcr和大批量筛选得到。本申请的mdgl多肽可以通过随机筛选获得,结果可验证,也可以用于指导mdgl的定向改造。
在一些实施方案中,本申请的多肽还可以通过重组技术产生,或者化学合成。产生重组肽的方法是本领域已知的。肽的化学合成方法也为本领域技术人员所熟知,例如,可以通过使用固相技术的定向肽合成来产生本申请的多肽及其变体(merrifield,j.am.chem.soc.85:2149-2154(1963))。可以用手动或通过自动化来进行蛋白合成。例如,可以用appliedbiosystems的431a肽合成仪(perkinelmer)实现自动化合成。可选择地,不同的片度可以分别通过化学方式合成并利用化学方法进行组合以制备所需的分子。
在具体的实施方案中,使用易错pcr方法对mdla基因进行随机突变,使用takarataq酶和引物进行易错pcr,得到突变扩增子片段集合,例如大小为约1000bp的片段。通过sac-ii和ecori酶切位点将得到的片段克隆至质粒载体例如p0586-g50中,并将得到的载体转化入宿主细胞例如大肠杆菌中,得到突变体库。将突变体在例如含氨苄青霉素的培养基中培养后,抽提质粒,用sali进行线性化,回收扩增的重组载体(例如约8.5kb的片段),然后将其导入酵母细胞中。将导入了重组载体的酵母细胞在筛选培养基平板进行培养,通过测定上清培养基的酶活力,筛选高比酶活的突变体。
在一些实施方案中,还可以对筛选的突变体进行验证,例如进行发酵验证。在一些实施方案中,对验证后的突变体进行测序,确定突变后的序列。
在一些实施方案中,将筛选得到的突变后的序列克隆到载体,例如质粒载体中,然后导入酵母细胞中,例如用电转化法将载体转化至毕赤酵母gs115菌株的感受态细胞中,发酵验证多肽的比酶活。
在一些实施方案中,本文公开的多肽的筛选方法包括:
1)将seqidno:3所示的核苷酸序列进行随机突变,得到突变序列集合,
2)将步骤1)中获得的突变序列克隆在表达载体上,然后转化或转导至合适的宿主细胞中,得到突变体库,
3)在合适的培养基中,培养步骤2)中的宿主细胞,回收重组表达载体,然后将线性化产物转化至酵母菌株中培养,以及
4)筛选酶活力高于seqidno:4所示的多肽的活力的突变多肽。
合适的宿主细胞是指适于表达载体或目的多核苷酸表达的宿主细胞。合适的培养基指适于宿主细胞生长或对其进行诱导表达的培养基。
在某些实施方案中,根据所用的宿主细胞,可以选择各种常规培养基。在适于宿主细胞生长的条件下进行培养。优选地,工程化的宿主细胞可以在被修饰适于激活启动子的常规营养培养基中进行培养,以筛选转化子或扩增本申请的多核苷酸。转化合适的宿主细胞并当宿主细胞生长到适当的细胞密度后,用合适的方法(如温度转换或化学诱导)诱导选择的启动子,将细胞再培养一段时间,以允许其生产目的多肽或其片段。
在某些实施方案中,宿主细胞生产的多肽可包被于细胞内、或在细胞膜上表达、或分泌到细胞外。如果需要,可利用其物理的、化学的和其它特性通过各种分离方法分离和纯化重组的蛋白。例如,表达的多肽或其片段可以通过本领域熟知的以下方法从重组细胞培养物中回收并纯化:常规的复性处理、蛋白沉淀剂处理(盐析方法)、离心、渗透破菌、超声波处理、超离心、分子筛层析(凝胶过滤)、吸附层析、离子交换层析、高效液相层析(hplc)和其它各种液相层析技术及这些方法的结合。
在具体的实施方案中,本文公开的多肽被分泌到宿主细胞外,例如酵母细胞外的培养基中。在一些实施方案中,将培养后的菌液离心,取上清,用于测定多肽的活性,例如水解pnpp的能力。
具有甘油单-二酰酯脂肪酶活性的多肽的应用
本申请的多肽是具有脂肪酶活性的多肽,特别是具有甘油单-二酰酯脂肪酶(mdgl)活性的多肽,能够利用酯化或转酯化反应来生产具有较高工业价值的甘油单酰酯(mag)。
本文公开的多肽具有较高的酶活力。在一些实施方案中,本文公开的多肽比seqidno:4所示的对照多肽的活力高至少约10%,例如高约40%。在一些实施方案中,本文公开的多肽比商品化酶例如amanog50-k的活力高至少约10%,例如高约30%。
本文公开的多肽可以用于mag的合成和tag的水解。因此,本申请提供了本文公开的多肽在制备甘油单酰酯中的用途。在一些实施方案中,使用本文公开的酶可明显降低酶的添加量和生产成本。
本说明书和权利要求书中,词语“包括”、“包含”和“含有”意指“包括但不限于”,且并非意图排除其他部分、添加物、组分、或步骤。
应该理解,在本申请的特定方面、实施方案或实施例中描述的特征、特性、组分或步骤,可适用于本文所描述的任何其他的方面、实施方案或实施例,除非与之矛盾。
上述公开内容总体上描述了本申请,通过下面的实施例进一步示例本申请。描述这些实施例仅为说明本申请,而不是限制本申请的范围。尽管本文中使用了特殊的术语和值,这些术语和值同样被理解为示例性的,并不限定本申请的范围。
实施例
实施例1:mdgl序列的合成和克隆
seqidno:3所示的核苷酸序列(其编码序列如seqidno:4所示的多肽)由生工生物工程(上海)股份有限公司合成。
将合成的mdgl序列克隆在质粒puc57中,保存于大肠杆菌dh5α中,使用fermentas公司的avrii和ecori酶切质粒,同时用avrii和ecori酶切质粒酶切带有组成型启动子spi和酵母α-交配因子的质粒pao815,然后使用axygen公司的凝胶回收试剂盒纯化。使用fermentas公司t4dna连接酶,按照产品说明,将mdgl序列酶切片段和质粒酶切片段进行连接,连接物通过热激法转入大肠杆菌dh5α中,在含100μg/ml氨苄青霉素的lb培养基平板上过夜培养。次日挑取单克隆在lb液体培养基中培养,使用axygen公司质粒提取试剂盒提取质粒并送交上海生工测序。
将测序正确的重组表达载体用bglii限制性内切酶酶切线性化后,通过电击法转化巴斯德毕赤酵母gs115感受态细胞,涂布到选择培养基mgys筛选平板,于30℃培养3天。挑取转化子转移至甘油单-二酯平板(1%ynb,2%甘油单-二酰酯,2%琼脂糖,0.0001%罗丹明b)上,30℃下培养3天,挑取水解圈最大的转化子。
实施例2:产甘油单-二酰酯脂肪酶菌株的发酵验证
挑取甘油单-二酰酯平板上透明圈较大的单克隆转移到含50mlbmgy培养基(1%酵母提取物,2%蛋白胨,1.34%酵母氮源碱(ynb)含硫酸铵不含氨基酸,1%甘油,4×10-5%d-生物素,100mm柠檬酸-柠檬酸钠缓冲液,ph6.6)的250ml三角瓶中,30℃下以200rpm摇动培养3天。培养结束后收集所有菌液,以8000rpm离心5分钟,取全部上清,使用10k的滤膜(millipore)超滤,超滤后蛋白浓缩至原发酵液的20-30倍,使用bradford试剂(生工生物工程(上海)股份有限公司)测定蛋白浓度,蛋白浓度为1-3mg/ml。将三角瓶活化的菌液接种到7.5l发酵罐中,发酵136小时,测定不同时间点的蛋白浓度和酶活力,结果如图1所示。
实施例3:通过pnpp法检测菌株gs115-mdgl产mdgl的比酶活
在400μlpnpp反应液(3mg/ml,溶于异丙醇,使用前取1ml与9ml0.2m乙酸钠-乙酸溶液混匀)中加入5μl酶液,35℃下反应30min,加入400ul终止液(200mmtris-hcl,5%triton-100,ph8.5)终止反应,以12000rpm离心5min,取上清,测定405nm处吸光值(od)。
酶活单位=0.1935*od*v1*稀释倍数/t/v2,其中v1为反应液体积(ml),v2为酶体积(ml),t为反应时间(min),稀释倍数为酶液的稀释倍数。比酶活为酶活单位(u)与酶蛋白量(mg)的比值。
测定三角瓶发酵获得的mdgl的比酶活为约20u/mg。
实施例4:mdgl随机pcr突变和高比酶活突变子筛选
使用引物epg50-1(seqidno.5:gcgcctaggccgcggcgaaacgatgagatttccttcaatttt)和epg50-2(seqidno.6:ccggaattcttaaacacgtttgaatg)扩增含mdgl质粒中的mdgl部分,pcr使用takara公司的taq酶进行,反应体系为:10×buffer5μl,dntpmixture(每者2.5mm)4μl,引物各1μl,质粒模板0.5μl,taq酶0.5μl,额外添加0.3mm的mncl2,加双蒸水至50ul。pcr反应程序为98℃10s,94℃20s,56℃20s,72℃1min,72℃5min,30个循环。pcr产物使用axygen公司的pcr纯化试剂盒纯化。纯化后的pcr产物通过sac-ii和ecori酶切位点酶切并克隆至p0586-g50的相应酶切位点,将得到的载体转化入大肠杆菌dh5α菌株。将每1×103个mdgl突变体用2ml的无菌水洗至8ml的lb液体培养基中(含100μg/ml氨苄青霉素),37℃培养4h。使用axygenminipre质粒提取试剂盒抽提质粒,用sali进行线性化,回收约8.5kb的片段,通过电击法转化巴斯德毕赤酵母gs115感受态细胞,涂布到mgys筛选平板,于30℃培养三天。挑取转化子转移至甘油单-二酰酯平板上,30℃下培养2天,挑取水解圈最大的转化子接种至500μlbmgy培养基中,30℃下以200rpm摇动培养2天。将培养后的菌液以12000rpm离心5min,吸取上清于4℃保藏,用于测定pnpp水解能力。
使用96孔板筛选高比酶活的mdgl。96孔板反应体系为:在200μlpnpp反应液(6mg/mlpnpp异丙醇溶液,使用前取1ml与9ml反应液(200mm乙酸钠-乙酸,ph4.84)混匀)中加入5μl酶液,35℃下反应30min,加入100μl终止液(200mmtris-hcl,5%triton-100,ph8.5)终止反应,4000rpm下离心5min,取上清,测定405nm处吸光值。挑选出比酶活最大的突变子于1.5ml离心管中再次验证,反应体系:400μlpnpp反应液,加入10μl酶液,35℃下反应30min,加入400μl终止液,4000rpm下离心5min,取上清,测定405nm处吸光值,计算比酶活。计算比酶活的方法与实施例3中的方法相同。
实施例5:高比酶活突变子三角瓶发酵验证
在本实施例中,将实施例4中初步筛选得到的突变子进行三角瓶发酵验证。具体操作步骤为:将筛选出的突变子接种至50ml的bmgy培养基中,30℃下以200rpm摇动培养2天,每隔12h向50ml培养基中补加0.5ml甘油。培养3天后,4℃下以8000rpm离心发酵液,使用0.22μm滤膜过滤处理上清液,将等量上清液使用milipore10kda超滤浓缩罐浓缩到相同体积后,使用bradford试剂测定蛋白浓度,使用pnpp法测定各突变子发酵液中mdgl的比酶活,筛选比酶活最高的突变子,取等蛋白量和等酶活单位的酶液进行聚丙烯酰胺凝胶电泳分析,结果如图2所示。
实施例6:高比酶活突变子序列测定
在本实施例中,将实施例4和5中筛选并验证的高比酶活突变子即mdgl-new的序列进行测定。
使用引物spi-f(seqidno.7:ggcgaaacgatgagatttcct)和plc-r(seqidno.8:gtgccgaggatgacgatgag)扩增mdgl-new的序列,pcr使用takara公司的taq酶进行,pcr产物送生工生物工程有限公司测序。mdgl-new的核苷酸序列如seqidno:2所示,mdgl-new的氨基酸序列如seqidno:1所示。
实施例7:mdgl-new编码基因的纯化和验证
使用引物plc-fa(seqidno.9:ccctaggtggtcagctgaggacaagcataa)和plc-rb(seqidno.10:cgggatccgtgccgaggatgacgatgag)扩增实施例6中测序的mdgl-new核苷酸序列,通过sac-ii和ecori酶切并克隆至p0586-g50,将得到的载体转化入大肠杆菌dh5α菌株,挑取单克隆进行测序验证,与mdgl-new核苷酸序列完全一致则认为是阳性克隆。将阳性克隆抽提质粒,用sali进行线性化,回收约8.5kb的片段,转化至毕赤酵母gs115中。挑取转化子至甘油单-二酰酯平板上,30℃培养3天,挑取水解圈最大的转化子进行三角瓶发酵。然后利用与实施例5相同的方法,通过pnpp法测定发酵液中mdgl的比酶活,其中测定的比酶活为58.4u/mg。
实施例8:mdgl-new活力单位测定
在本实施例中,以月桂酸乙烯酯为底物测定商品化酶amanog50-k(购自天野酶制剂(江苏)有限公司)、seqidno:4所示多肽和mdgl-new的酶活单位,反应体系为:500μl底物(3%月桂酸乙烯酯,2%pva),400μl0.1m乙酸钠(ph5.6),100μl稀释后酶液(6mg/ml蛋白,稀释20000倍),37℃静止反应30min,加入4ml终止液(乙醇:丙酮=1:1)。使用0.01m乙醇氢氧化钾滴定反应液,酚酞为指示剂,
酶活力单位定义为:每分钟释放1μm月桂酸所需的蛋白量为1u。计算公式:酶活单位=(v1-v2)*0.01*106*d/30,v1:样品消耗氢氧化钾量,v2:空白对照消耗氢氧化钾量,d:稀释倍数。
测定结果为:amanog50-k比酶活为6256.41u/mg;seqidno:4所示的对照mdgl比酶活为5687.83u/mg,为amano商品化酶的90.9%;mdgl-new的比酶活为8045.98u/mg,比商品化酶的活力提高28.6%,比对照mdgl的活力提高41.5%。
可以理解,尽管本申请以某种形式被说明,但本申请并不局限于本说明书中所显示和描述的内容。对本领域的技术人员显而易见的是,在不偏离本申请的范围的前提下还可做出各种变化。这些变化都在本申请要求保护的范围内。
序列表
<110>丰益(上海)生物技术研发中心有限公司
<120>新型的甘油单-二酰酯脂肪酶
<130>17c13550cn
<160>10
<170>siposequencelisting1.0
<210>1
<211>279
<212>prt
<213>人工序列(artificialsequence)
<400>1
aspvalserthrsergluleuaspglnphegluphetrpvalglntyr
151015
alaalaalasertyrtyrglualaasptyrthralaglnvalglyasp
202530
lysleusercysserlysglyasncysprogluvalglualathrgly
354045
alathrvalsertyrasppheseraspserthrilethraspthrala
505560
glytyrilealavalasphisthrasnseralavalvalleualaphe
65707580
argglyserhisservalargasntrpvalalaaspalathrpheval
859095
histhrasnproglyleucysaspglycysleualagluleuglyphe
100105110
trpsersertrplysleuvalargaspaspileilelysgluleulys
115120125
gluvalvalalaglnasnproasptyrgluleuvalvalvalglyhis
130135140
serleuglyalaalavalalathrleualaalathraspleuarggly
145150155160
lysglytyrproseralalysleutyralatyralaserproargval
165170175
glyasnalaalaleualalystyrilethralaglnglyasnasnphe
180185190
argphethrhisthrasnaspprovalprolysleuproleuleuser
195200205
metglytyrvalhisvalserproglutyrtrpilethrserproasn
210215220
asnalathrvalserthrseraspilelysvalileaspglyaspval
225230235240
serpheaspglyasnthrglythrglyleuproleuleuthraspphe
245250255
glualahisiletrptyrphevalglnvalaspalaglylysglypro
260265270
glyleuprophelysargval
275
<210>2
<211>840
<212>dna
<213>人工序列(artificialsequence)
<400>2
gatgtctccacttccgaactggaccagttcgagttctgggtacaatacgcagccgcctct60
tactacgaggctgattacaccgcacaggttggtgataagctgtcctgctctaagggtaac120
tgcccagaagttgaagcaaccggtgcaactgtgtcttacgacttctccgattccacgatc180
actgacaccgcaggttacatcgcagttgatcacaccaactccgcagtggtactggcattc240
cgtggttctcactccgtacgtaactgggttgctgatgctactttcgtccataccaaccca300
ggtctgtgtgatggttgcctggctgagctgggtttctggtcttcctggaagctggttcgt360
gatgatattatcaaagaactgaaagaagtggtggcacagaacccagactatgaactggtg420
gtcgtgggccactccctgggtgctgctgtggctactctggctgctaccgacctgcgtggt480
aaaggttatccatctgctaaactgtacgcctacgcttcccctcgtgttggcaacgcagcc540
ctggccaaatatatcaccgcccagggcaacaacttccgtttcacccacaccaatgaccca600
gtacctaaactgccactgctgtctatgggctatgtacatgtttctcctgaatattggatc660
acctctcctaacaacgccactgtttctacctctgacatcaaagtcattgacggcgacgta720
tcttttgacggcaataccggcacgggcctgcctctgctgacggactttgaagcccacatt780
tggtactttgtacaggttgacgccggcaaaggtcctggcctgccattcaaacgtgtttaa840
<210>3
<211>840
<212>dna
<213>人工序列(artificialsequence)
<400>3
gatgtctccacttccgaactggaccagttcgagttctgggttcaatacgcagccgcctct60
tactacgaggctgattacaccgcacaggttggtgataagctgtcctgctctaagggtaac120
tgcccagaagttgaagcaaccggtgcaactgtgtcttacgacttctccgattccacgatc180
actgacaccgcaggttacatcgcagttgatcacaccaactccgcagtggtactggcattc240
cgtggttcttactccgtacgtaactgggttgctgatgctactttcgtccataccaaccca300
ggtctgtgtgatggttgtctggctgagctgggtttctggtcttcctggaagctggttcgt360
gatgatattatcaaagaactgaaagaagtggtggcacagaacccaaactatgaactggtg420
gtcgtgggccactccctgggtgctgctgtggctactctggctgctaccgacctgcgtggt480
aaaggttatccatctgctaaactgtacgcttacgcttcccctcgtgttggcaacgcagcc540
ctggccaaatatatcaccgcccagggcaacaacttccgtttcacccacaccaatgaccca600
gtacctaaactgccactgctgtctatgggctatgtacatgtttctcctgaatattggatc660
acctctcctaacaacgccactgtttctacctctgacatcaaagtcattgacggcgacgta720
tcttttgacggcaataccggcacgggcctgcctctgctgacggactttgaagcccacatt780
tggtactttgtacaggttgacgccggcaaaggtcctggcctgccattcaaacgtgtttaa840
<210>4
<211>279
<212>prt
<213>人工序列(artificialsequence)
<400>4
aspvalserthrsergluleuaspglnphegluphetrpvalglntyr
151015
alaalaalasertyrtyrglualaasptyrthralaglnvalglyasp
202530
lysleusercysserlysglyasncysprogluvalglualathrgly
354045
alathrvalsertyrasppheseraspserthrilethraspthrala
505560
glytyrilealavalasphisthrasnseralavalvalleualaphe
65707580
argglysertyrservalargasntrpvalalaaspalathrpheval
859095
histhrasnproglyleucysaspglycysleualagluleuglyphe
100105110
trpsersertrplysleuvalargaspaspileilelysgluleulys
115120125
gluvalvalalaglnasnproasntyrgluleuvalvalvalglyhis
130135140
serleuglyalaalavalalathrleualaalathraspleuarggly
145150155160
lysglytyrproseralalysleutyralatyralaserproargval
165170175
glyasnalaalaleualalystyrilethralaglnglyasnasnphe
180185190
argphethrhisthrasnaspprovalprolysleuproleuleuser
195200205
metglytyrvalhisvalserproglutyrtrpilethrserproasn
210215220
asnalathrvalserthrseraspilelysvalileaspglyaspval
225230235240
serpheaspglyasnthrglythrglyleuproleuleuthraspphe
245250255
glualahisiletrptyrphevalglnvalaspalaglylysglypro
260265270
glyleuprophelysargval
275
<210>5
<211>42
<212>dna
<213>人工序列(artificialsequence)
<400>5
gcgcctaggccgcggcgaaacgatgagatttccttcaatttt42
<210>6
<211>26
<212>dna
<213>人工序列(artificialsequence)
<400>6
ccggaattcttaaacacgtttgaatg26
<210>7
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>7
ggcgaaacgatgagatttcct21
<210>8
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>8
gtgccgaggatgacgatgag20
<210>9
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>9
ccctaggtggtcagctgaggacaagcataa30
<210>10
<211>28
<212>dna
<213>人工序列(artificialsequence)
<400>10
cgggatccgtgccgaggatgacgatgag28
- 还没有人留言评论。精彩留言会获得点赞!