糖基转移酶CtGT-I、其编码基因和衍生物及用途的制作方法
本发明涉及一种糖基转移酶,具体地涉及来源于管花肉苁蓉的糖基转移酶ctgt-i、其编码基因和衍生物及用途。
背景技术:
糖基转移酶是通过合成糖苷键将糖基连接到特定受体的一类酶。根据底物识别、序列相似性和系统进化分析,糖基转移酶可以被分为91个基因家族。其中,与植物次生代谢相关的基因大部分都属于familyi。该家族中的糖基转移酶的底物都是小分子亲脂性化合物,糖基化反应多发生在其-oh、-cooh、-nh2、-sh或c-c基团上。
近年来,植物小分子化合物糖基转移酶的研究逐渐受到学者的关注,其中第一个被鉴定的植物来源糖基转移酶基因是由mcclintock发现的控制玉米种子黑色素沉积的bronze1基因,该基因编码产生黄酮糖苷的udp-糖基转移酶。随着生物技术的发展,生物化学、生物信息学、分子生物学和遗传学等方法都已经成功的运用于糖基转移酶基因的克隆、鉴定与分析。通过序列分析的方法,近十几年来,一些新型的参与不同结构类型化合物糖基化反应的糖基转移酶被陆续从不同植物中克隆出来,如生长素、细胞分离素生物合成相关糖基转移酶,甜叶菊苷生物合成相关糖基转移酶,萜类化合物(藏红花藏花酸)糖基转移酶等。
2005年,shao等人通过x-ray单晶衍射分析了蒺藜苜蓿(medicagotruncatula)糖基转移酶ugt71g1与供体udp-葡萄糖共结晶结构。结果表明,植物糖基转移酶有2个罗斯曼折叠(rossmannfold,βαβ结构),受体结合区主要在n末端,活化供体结合区主要在c末端,n-和c-端结构域有连接臂连接,酶活性位点位于二者之间。目前已发现的植物糖基转移酶均以udp-葡萄糖作为糖基供体,有些酶则以udp-鼠李糖、udp-半乳糖、udp-木糖以及udp-葡萄糖醛酸作为专一性的糖供体。
目前为止,尽管植物来源糖基转移酶的研究已取得了一定进展,但迄今鉴定的酶都只针对某一个或某一类特定的化合物的糖苷化,且目前报道的糖基转移酶所接受的供体大部分为udp-葡萄糖,催化的糖苷化取代形式也多为o-糖苷化,无普适性的能接受不同结构类型底物同时以不同取代形式进行多样性糖基化取代的糖基转移酶的报道。因此,当外源化合物需要进行糖基化修饰时,其结构类型如果与已报道的糖基转移酶底物结构差别较大,则无法通过酶催化的方法进行结构修饰。
另外,目前报道的糖基转移酶多催化芳香类化合物苷元,对于既能催化苷元,同时又能催化已含有糖链的化合物进行进一步糖基化取代,从而生成双糖苷或多糖苷在的糖基转移酶少有报道,而双糖苷及多糖苷又都是活性糖苷类化合物中重要的组成部分。因此,上述问题的存在极大程度上限制了酶催化糖苷化的应用。
技术实现要素:
本发明在中药管花肉苁蓉中发现了一种糖基转移酶,广泛而深入的酶催化反应发现其可作为一种普适性的糖基转移酶,其可应用于不同结构类型糖苷类化合物的酶法合成。基于此完成了本发明。具体地,本发明包括以下内容。
本发明的第一方面,提供一种糖基转移酶ctgt-i,其能够催化糖基供体与受体反应生成糖基化产物;其中所述糖基转移酶ctgt-i具有(1)~(4)所述特性中的至少一种:
(1)所述糖基供体包括udp-葡萄糖和udp-n-乙酰葡萄糖胺;
(2)所述受体包括芳香苷元化合物和芳香糖苷化合物;
(3)催化形式包括o-糖苷化、s-糖苷化和n-糖苷化;
(4)在每种受体上具有至少一个糖基化反应位点。
在某些实施方案中,所述糖基转移酶ctgt-i来源于管花肉苁蓉。
在某些实施方案中,糖基转移酶ctgt-i的氨基酸序列如seqidno:1所示,或者来源于管花肉苁蓉且与seqidno:1所示序列具有90%以上的同源性。
本发明的第二方面,提供一种编码所述的糖基转移酶ctgt-i的基因。优选地,其来源于管花肉苁蓉且序列如seqidno:2所示,或者来源于管花肉苁蓉且与seqidno:2所示序列具有90%以上的同源性。在某些实施方案中,本发明的基因的序列如seqidno:3所示。
本发明的第三方面,提供一种载体,其包含本发明所述的基因以及与其可操作连接的调控元件。
本发明的第四方面,提供一种宿主,其包含本发明所述的基因,或本发明所述的载体。
本发明的第五方面,提供糖基转移酶ctgt-i的用途。优选地,糖基转移酶ctgt-i用于制备糖基化产物,和/或用于制备转基因植物。
本发明所述的糖基转移酶ctgt-i可以接受不同结构类型的苷元或糖苷类底物作为糖基化反应的受体,且既能接受udp-葡萄糖为供体,又能接受udp-n-乙酰葡糖胺为供体。此外,糖基转移酶ctgt-i还可催化多样性糖苷化形式如o-糖苷化,s-糖苷化和n-糖苷化。ctgt-i的催化产物多样性丰富,其能催化单一底物生成一个或多个糖基化产物。因此兼具供体、受体及催化形式杂泛性的特点。
本发明的基因能够高效表达糖基转移酶ctgt-i。优选地,密码子优化后的新基因序列ctgt-iopt编码与ctgt-i蛋白相同的氨基酸序列,其在保持与ctgt-i相同的催化活性及催化反应类型的基础上,蛋白表达量及催化效率较ctgt-i相比有了显著提高,为所述糖基转移酶ctgt-i的进一步学术/工业化应用提供了可能。
本发明的用途中,作为一种普适性的糖基转移酶工具酶,可应用于不同结构类型单糖/多糖苷类化合物的酶法合成,弥补了化学法修饰和单一底物酶法修饰的不足。另外,由于催化反应位点多样性,本发明的糖基转移酶还可应用于不同类型糖苷类化合物的酶法制备中。
附图说明
图1为糖基转移酶ctgt-i基因编码区琼脂糖凝胶电泳图;
图2为异源表达得到的糖基转移酶ctgt-i的sds-page电泳图;
图3为序列优化后的糖基转移酶ctgt-iopt的sds-page电泳图;
图4为糖基转移酶ctgt-i所催化阳性底物的结构示意图(涉及不同结构类型的阳性底物共37个);
图5为糖基转移酶ctgt-i与序列优化后蛋白ctgt-iopt催化效率对比图;
图6为糖基转移酶ctgt-i催化底物毛蕊花糖苷葡萄糖苷化的反应式。
具体实施方式
下面结合具体实施例对本发明作进一步的说明,但本发明的保护范围并不限于此。
本发明在中药管花肉苁蓉中克隆获得了一个序列新颖的糖基转移酶,通过大范围的底物筛选及体外酶促催化反应,结合hplc-hr-ms分析,发现其可作为一种普适性糖基转移酶应用于不同结构类型糖苷类化合物的酶法合成。基于此完成了本发明。具体地,本发明包括以下内容。
本发明的第一方面,提供一种糖基转移酶ctgt-i。本发明中,“糖基转移酶ctgt-i”有时也简称作“本发明的糖基转移酶”或“ctgt-i”,其是一种能够催化糖基供体与受体发生糖基化反应生成糖基化产物的蛋白酶。本发明的糖基转移酶兼具显著的糖基供体与糖基受体选择及催化形式杂泛性。具体地,本发明的糖基转移酶具有(1)~(4)所述特性中的至少一种:
(1)所述糖基供体包括udp-葡萄糖和udp-n-乙酰葡萄糖胺;
(2)所述受体包括芳香苷元化合物和芳香糖苷化合物;
(3)催化形式包括o-糖苷化、s-糖苷化和n-糖苷化;
(4)在每种受体上具有至少一个糖基化反应位点。
关于特性(1)
本发明中,糖基供体是指为糖基化反应提供糖基的化合物。糖基供体的类型包括但不限于葡萄糖类、半乳糖类、鼠李糖类和木糖类等。以目前最常见的葡萄糖苷化为例,本发明的糖基转移酶既能接受udp-葡萄糖(即尿苷二磷酸葡萄糖,简称udpg)为供体,催化葡萄糖苷化取代,也能接受udp-n-乙酰葡糖胺(即尿苷二磷酸-n-乙酰葡糖胺,简称udpag)作为糖基供体催化n-乙酰葡萄糖苷化。需要说明的是,葡萄糖类糖基供体可以是上述两种化合物中的一种或两种,但本发明的糖基供体并不排除其他含葡萄糖类化合物的已知化合物或能够提供此种葡萄糖类化合物的合成体系。
关于特性(2)
本发明中,受体是指在糖基化反应中接受糖基的化合物,有时也称作“阳性底物”。本发明的糖基转移酶具有广泛的底物选择性,即普适性。本发明的受体在结构方面可以差别很大。优选地,受体包括芳香苷元化合物和芳香糖苷化合物(本文中将此处的芳香糖苷化合物称作“作为受体的糖苷化合物”),但并不排除可以其他类型的化合物作为其阳性底物。
关于芳香苷元化合物,是指含有芳香环,但不包括糖基的化合物,只要可以作为糖基化合物的苷元部分,则不特别限定其具体结构类型。优选地,本发明的芳族化合物包括但不限于黄酮类化合物、二苯乙基色酮类化合物、蒽醌类化合物、香豆素类化合物、二苯乙烯类化合物、木脂素类化合物和酚酸类化合物。对于黄酮类化合物,其实例包括含羟基取代的黄酮类化合物,例如黄酮、二氢黄酮、异黄酮、二氢异黄酮、黄酮醇、查尔酮化合物。对于二苯乙基色酮类化合物,其实例包括含羟基取代的二苯乙基色酮类化合物。对于蒽醌类化合物,其实例包括大黄素等。对于香豆素类化合物,其实例包括秦皮乙素等。对于二苯乙烯类化合物,其实例包括白藜芦醇等。对于木脂素类化合物,其实例包括厚朴酚等。对于酚酸类化合物,其实例包括对羟基苯甲醛、姜酮等。在糖基化反应中可以使用上述化合物中的一种或多种作为受体。
作为受体的糖苷化合物可以是不同结构类型的糖苷化合物。目前常见的糖基转移酶大部分只催化苷元的糖苷化,而对于已含有糖基取代的糖苷化合物进行进一步的糖苷化,从而生成双糖苷和/或多糖苷的糖基转移酶少有报道。对于既能接受苷元又能接受糖苷类底物的糖基转移酶更鲜有研究。本发明的糖基转移酶ctgt-i除催化芳族化合物作为苷元的糖苷化的功能性以外,还表现出对糖苷化合物进行进一步糖苷化的高效催化活性。
作为受体的糖苷化合物可以是单糖苷或双糖苷,或者含有更多个糖基的糖苷。具体包括但不限于苯乙醇苷类化合物、黄酮苷类化合物、香豆素苷类化合物、二苯乙烯苷类化合物。对于苯乙醇苷类化合物,其实例包括但不限于毛蕊花糖苷、肉苁蓉苷d、异肉苁蓉苷c、松果菊苷、管花苷b等。对于黄酮苷类化合物,其实例包括但不限于黄酮单糖苷日当药黄素、黄酮二糖苷地奥司明、黄酮醇苷白前苷b、二氢黄酮苷黄杞苷、异黄酮苷毛蕊异黄酮苷、二氢查耳酮苷类化合物根皮苷等。对于香豆素苷类化合物,其实例包括但不限于秦皮甲素等。对于二苯乙烯苷类化合物,其实例包括但不限于虎杖苷和何首乌苷等。作为受体的糖苷化合物的范围不受糖基取代类型、位置、数目以及苷键类型的限制。
关于特性(3)
本发明中,本发明的糖基转移酶具有多种催化形式。即,本发明的糖基转移酶的催化形式包括o-糖苷化、s-糖苷化和n-糖苷化。这不同于目前糖基转移酶大多只能催化o-糖苷化的情形。例如,本发明的糖基转移酶既能以3,4-二氯苯酚为底物催化o-糖苷化,又能分别以3,4-二氯苯硫酚和3,4-二氯苯胺为底物催化s-糖苷化和n-糖苷化。
关于特性(4)
与目前大部分糖基转移酶催化底物糖基化主要生成1种糖苷化产物明显不同,本发明的糖基转移酶可在每种受体上具有至少一个糖基化反应位点。即,本发明的糖基转移酶具有催化产物多样性的特点,其催化受体糖苷化的反应往往生成多个糖基化产物。本发明的糖基转移酶可应用于不同类型糖苷类化合物的酶法制备中。
本发明的糖基转移酶只要具有上述特性(1)~(4)中的至少一种,则不特别限定其结构组成和来源。例如,本发明的糖基转移酶可来源于管花肉苁蓉(学名:cistanchetubulosa(schenk)wight)。本发明的糖基转移酶的氨基酸序列可选自下述之一:
(a)seqidno:1所示的氨基酸序列;
(b)由seqidno:1所示序列衍生的氨基酸序列。例如,在seqidno:1所示氨基酸序列中经过取代和/或缺失和/或添加一个或多个氨基酸的衍生氨基酸序列。
再例如,来源于管花肉苁蓉且与seqidno:1所示序列具有90%以上,优选95%以上,更优选98%以上,进一步优选99%同源性的氨基酸序列。本申请中“同源性”是指两个序列之间的相似性,可通过本领域已知的任何算法来确定。例如,两个序列之间的同一性程度可使用needleman-wunsch算法确定。
本发明的第二方面,提供编码糖基转移酶ctgt-i的基因(本文有时简称为“本发明的基因”)。对于基因序列及来源并不特别限定,只要其能够编码具有催化活性的糖基转移酶ctgt-i即可。在某些实施方案中,本发明的基因来源于管花肉苁蓉。在某些实施方案中,本发明的基因的序列选自下述之一:
(a)seqidno:2所示的序列;
(b)由seqidno:2所示序列衍生的序列。
例如,在seqidno:2所示序列的基础上进行简并密码子改造的衍生序列。
又例如,来源于管花肉苁蓉且与seqidno:2所示序列具有90%以上,优选95%以上,更优选98%以上,进一步优选99%同源性的序列。本申请中“同源性”是指两个序列之间的相似性,可通过本领域已知的任何算法来确定。例如,两个序列之间的同一性程度可使用needleman-wunsch算法确定。
再例如,在seqidno:2所示序列的基础上,经密码子优化后得到的序列。优选通过大肠杆菌密码子偏爱性优化后具有有益技术效果的序列。进一步优选优化后编码具有与ctgt-i蛋白相同的氨基酸序列,且催化活性及催化反应类型与ctgt-i相同的序列。更优选地,经优化后蛋白表达量和/或催化效率提高的序列。在某一实施方案中,经密码子优化后得到的序列如seqidno:8所示。
还例如,在seqidno:2所示序列的基础上,上游或下游加入一些调控元件或修饰序列,这些序列的共表达蛋白具有与本发明的基因编码蛋白相同的活性,同时对蛋白的表达量无影响或有促进作用。
本发明的第三方面,提供一种载体(本文有时称作“本发明的载体”),其包含本发明的基因以及与其可操作连接的调控元件。作为载体既可以是复制载体也可以是表达载体。其实例包括但不限于质粒、粘粒、病毒、自主复制序列、噬菌体。优选地,所述载体为表达载体,例如pet-28a等。本发明中,示例性的调控元件包括启动子、终止子、增强子等。例如,可在载体引入5’调控序列和启动子。
本发明的第四方面,提供一种宿主(本文有时称作“本发明的宿主”),其包含本发明的基因或者本发明的载体。作为宿主的实例包括各类细胞、组织、器官或个体。作为细胞的实例包括原核细胞、真核细胞。作为原核细胞优选大肠杆菌。作为真核细胞优选酵母。作为组织、器官或个体的实例优选植物组织、器官或个体。
本发明的第五方面,提供本发明的糖基转移酶的用途。优选地用于制备糖基化产物,和/或用于制备转基因植物。
作为制备糖基化产物的用途,包括在包含本发明的糖基转移酶、受体和糖基供体的反应体系中,在适于反应的条件下进行反应的步骤。反应体系中的受体和糖基供体如本文第一方面中所述,在此不再赘述。
本发明的反应体系中,本发明的糖基转移酶的浓度在50~95μg/100μl之间,优选60~90μg/100μl之间,进一步优选75~88μg/100μl之间。糖基供体的浓度在0.01~2mm范围内,优选0.1~1mm范围内,更优选0.2~0.8mm范围内。受体的浓度为0.01~1mm,优选为0.04~0.6mm范围内,更优选0.1~0.4mm范围内。优选地,本发明的反应体系进一步包含缓冲液。优选地,缓冲液可为包含tris-hcl、dtt和nacl的缓冲液。优选地,nacl的浓度为50~150mm,优选100mm。本发明中,优选所述反应体系为体外反应体系。
本发明所述的“适于反应的条件”是指能够保证糖基转移酶、受体和糖基供体进行反应的条件。所述条件包括20~40℃,优选25~35℃,例如30℃的反应温度,和3~24小时,优选6~18小时,更优选10小时的反应时间。
作为制备转基因植物的用途,包括以本发明的基因、载体或宿主作为材料进行生物技术操作的步骤。本发明所述的生物技术操作为本领域内通常已知的操作。具体可参考例如《分子克隆实验指南(第4版)》(美国冷泉港实验室出版,科学出版社原版引进)等工具书或现有技术文献等。在此不再赘述。
实施例1-糖基转移酶ctgt-i编码基因的获得
选取管花肉苁蓉植株上新鲜且幼嫩的组织,用清水洁净表面,吸水纸吸去残余水分,采用液氮速冻研磨法,利用rna提取试剂盒rnaplantkit(omega)进行总rna的提取。对总rna进行凝胶电泳分析,并利用nanodrop测定浓度,利用smarterrace5′/3′kit(clontech)分别反转录获得5′-race-cdna,3′-race-cdna及总cdna。
5′-race-cdna的获得:取0.2-2.0μgrna,与1.0μl5′-cds-primera,ddh2o补足至3.75μl,进行pcrstep1(72℃,3min;42℃,2min),反应结束后取出立即放冰上,加入1.0μlsmarteriiaoligo以及4.25μlmix(包含有5×first-strandbuffer2.0μl,20mmdtt1.0μl,10mmdntp1.0μl,rnaseinhibitor0.25μl),混匀并瞬离后加入smartscribereversetransciptase1.0μl,进行pcrstep2(42℃,90min;72℃,10min),反应结束后,用100μlrnasewater稀释产物。
3′-race-cdna的获得:取0.2-2.0μgrna,与1.0μl3′-cds-primera,ddh2o补足至4.75μl,进行pcrstep1(72℃,3min;42℃,2min),结束后取出立即放冰上,加入4.25μlmix(5×first-strandbuffer2.0μl,20mmdtt1.0μl,10mmdntp1.0μl,rnaseinhibitor0.25μl),混匀并瞬离后加入smartscribereversetransciptase1.0μl,进行pcr-step2(42℃,90min;72℃,10min),反应结束后,用100μlrnase-freewater稀释产物。
rt-cdna的获得:取0.2-2.0μgrna,与10μmoligodt202.0μl,ddh2o补足至5.0μl,进行pcrstep1(72℃,3min),反应产物中加入4.0μlmix(5×first-strandbuffer2.0μl,20mmdtt1.0μl,10mmdntp1.0μl),混匀并瞬离后加入smartscribereversetransciptase1.0μl,进行pcrstep2(42℃,90min;70℃,15min),反应结束后,用10μlrnasewater稀释产物。
race法快速扩增cdna末端
目的基因5′端和3′端序列的克隆参照smartertmracecdnaamplificationkit(clontech)的要求,以race反转录所得到的5′/3′-race-cdna(约40ng)为模板,在对前期获得的管花肉苁蓉转录组数据分析的基础上,设计ctgt-i序列的5′/3′-race特异引物,同时结合试剂盒通用引物upm,以高保真dna扩增酶kod-plus-neodnapolymerase扩增得到相应的5′/3′端序列。race扩增的反应体系为:5′/3′-race-cdna:40ng,upm(10μm):1.0μl,5′/3′-race特异引物(10μm):0.5μl,10×kodbuffer:1.0μl,mgso4(25mm):0.6μl,dntps(2mm):1.2μl,koddnapolymerase(1u/μl):0.2μl。pcr反应程序为:94℃预变性2min;之后94℃变性15s,起始65℃退火,30s,每个循环降低0.5℃,68℃延伸,50s,共30个循环;紧接着94℃变性15s,54℃退火,30s,68℃延伸,50s,共25个循环;最后72℃延伸1min。
5′端race特异引物序列如seqidno:4所示;5′端racepcr产物1087bp。
3′端race特异引物序列如seqidno:5所示;3′端racepcr产物1312bp。
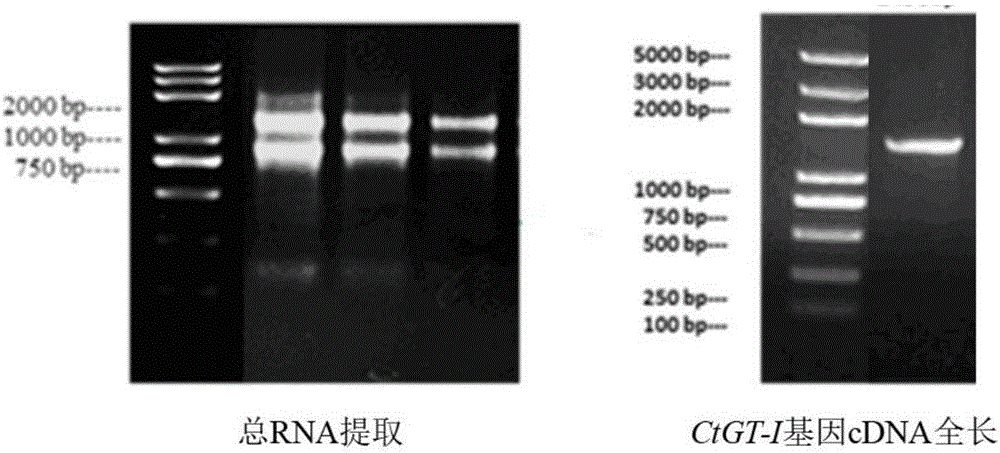
将测序所得的5′race和3′race序列进行拼接,得到全长cdna序列如seqidno:3所示。分析5′-race和3′-race所得到的cdna片段序列,设计一对带有酶切位点的特异性引物,序列如seqidno:6,7所示,其中seqidno:6通过引物设计引入bamhi酶切位点,seqidno:7通过引物设计引入noti酶切位点。利用一对特异性引物扩增得到约1458bp的编码区序列全长,序列如seqidno:2所示,编码氨基酸序列如seqidno:1所示,琼脂糖凝胶电泳如图1所示。
实施例2-糖基转移酶ctgt-i基因原核表达载体的构建和原核表达
将实施例1中扩增获得的含酶切位点基因全长胶回收,与表达载体pet-28a用相应的限制性内切酶进行双酶切,根据限制性内切酶的相对位置,保留载体pet-28a上c、n两端的his标签。37℃酶切2~3h,加入10%10×loadingbuffer终止反应。凝胶电泳检测回收产物,利用nebt4dnaligase0.5μl将目的基因(53ng/1.4kb)连接于pet-28a(66ng/5.3kb)上,加入10×t4buffer1.0μl,25℃连接10min。连接产物转化感受态细胞,选择e.colibl21(de3)作为表达菌株。通过菌落pcr筛选阳性克隆,取测序正确的菌株接种于含有kana50μg/ml,chl50μg/ml的lb液体培养基中,在37℃,200rpm的恒温摇床中振荡培养至菌液od600在0.4-0.6之间,加入诱导剂iptg至终浓度为0.5mm,23℃,180rpm条件下培养16h低温诱导目的蛋白的表达。利用镍离子亲和层析柱(nisepharose6fastflow,gehealthcare)纯化ctgt-i蛋白。蛋白表达纯化结果如图2所示,目的蛋白大小在50~60kda,与其理论大小53.5kda相一致,200mm咪唑浓度下目的蛋白大量洗脱获得单一条带蛋白。合并目的蛋白流份于pd-10column中进行蛋白浓缩。利用easyproteinquantitativekit进行。蛋白表达量约为9.7mg/l菌体。
实施例3-糖基转移酶ctgt-i以udp-葡萄糖或udp-n-乙酰葡糖胺为糖基供体进行体外酶促反应的hplc-hr-ms检测
利用his标签ni+亲和柱色谱纯化后的ctgt-i蛋白进行酶反应实验。酶反应150μl体系包括:50μgctgt-i蛋白,0.5mmudp-葡萄糖或0.5mmudp-n-乙酰葡糖胺供体,0.4mm受体底物,轻弹混匀,30℃水浴反应12h,400μl乙酸乙酯/正丁醇萃取回收反应产物,减压蒸干溶剂,残渣溶于200μl甲醇中,0.2μm滤膜过滤后用于hplc-ms分析。酶反应产物用agilent1260液相进行检测,检测条件为:色谱柱sheshidoc18column(4.6mml.d.×250mm,5μm),流速1.0ml/min,检测波长为dad检测器全波长扫描,对苯乙醇苷类化合物洗脱系统采用乙腈-0.1%甲酸水梯度洗脱:0~10min,5%~20%乙腈;10~15min,20%~25%乙腈;15~25min,25%~35%乙腈;25~30min,35%~95%乙腈;30~35min,100%乙腈。对黄酮类及黄酮苷类和2-(2-苯乙基)色酮类,以及其他类化合物洗脱系统采用甲醇-0.1%甲酸水梯度洗脱:0~25min,30%~90%甲醇;25~27min,90%~100%甲醇;27~33min,100%甲醇。质谱条件为:lcms-it-tof(shimadzu,japan),正、负离子模式检测;雾化气体(nebulizinggas)为n2,流速为1.5ml/min;干燥气体(dryinggas)为n2,压力为100mpa;检测器(detector)电压1.40kv;曲线脱溶剂管(cdl)压力为正常模式;cdl温度为200℃;加热器(blockheater)温度为200℃;接口电压(interfacevoltage)1.40kv;离子阱真空度(itvacuum,1.9×10-2pa);高纯氩气作为冷却气体(coolinggas)和碰撞诱导解离(collision-induceddissociation,cid)的碰撞气体(collisiongas)。质谱设为自动多级ms1、ms2、ms3全扫描模式;离子积累时间(ionaccumulationtime)为100ms;cid碰撞能量(collisionenergy)设为50%;数据处理用lcsolutionversion1.1软件(shimadzu)。hplc-hr-ms检测数据如表1所示。
表1ctgt-i催化不同底物糖基化反应的hplc和hr-esi-ms数据表
实施例4-糖基转移酶ctgt-iopt基因原核表达载体的构建和原核表达
ctgt-iopt基因序列是基于ctgt-i核苷酸序列的基础上,通过大肠杆菌密码子偏爱性优化后的序列,其编码氨基酸具有与ctgt-i蛋白相同的序列,ctgt-iopt基因载体的构建和原核表达流程同实施例2,蛋白表达纯化结果如图3所示,其蛋白大小在50~60kda,与ctgt-i蛋白大小一样,且蛋白表达量约为15.5mg/l菌体,高于ctgt-i的蛋白表达量。
实施例5-糖基转移酶ctgt-iopt与ctgt-i催化效率的比较
利用his标签ni+亲和柱色谱纯化后的ctgt-i蛋白和ctgt-iopt蛋白分别进行酶反应实验。酶反应150μl体系包括:50μgctgt-i或ctgt-iopt蛋白,0.08μmudp-葡萄糖供体,0.06μm受体底物,轻弹混匀,30℃水浴反应12h,400μl乙酸乙酯/正丁醇萃取回收反应产物,减压蒸干溶剂,残渣溶于200μl甲醇中。0.2μm滤膜过滤后进行hplc-hr-ms分析。结果表明ctgt-iopt催化活性及催化反应类型与ctgt-i相同,催化效率较ctgt-i相比有了显著提高。以根皮苷为反应底物进行说明,如图5所示。
实施例6-糖基转移酶ctgt-i/ctgt-iopt催化阳性底物毛蕊花糖苷葡萄糖苷化产物的制备
重组蛋白放大酶促反应:75ml反应体系,0.06mmol毛蕊花糖苷(溶于dmso),0.08mmoludp-葡萄糖基供体,65mg重组ctgt-i蛋白,反应缓冲液(50mmtris-hcl,1mmdtt,1.5%甘油,100mmnacl),30℃反应12~24小时,反应液过0.45μm滤膜,用于后续色谱分离。上述反应液以<1ml/min的流速上样于mcigelchp系列树脂(1cm×15cm),20倍柱体积水洗脱杂质,依次以10倍体积10%、30%、50%、70%、90%甲醇-水溶液梯度洗脱,最后以100%甲醇冲柱。各流份取样进行hplc检测,合并目标产物流份,减压蒸干溶剂,残渣溶于甲醇,过0.45μm滤膜。采用岛津半制备液相进一步纯化富集产物,制备柱ymc-packods-ahplccolumn(10mml.d.×250mm,s-5μm,12nm),洗脱系统采用乙腈-水梯度洗脱:0~5min,5%~15%乙腈;5~10min,15%乙腈;10~15min,15%~18%乙腈;15~30min,18%~20%乙腈;30~35min,20%~75%乙腈;35~40min90%~100%乙腈,手动进样,流速3ml/min。制备产物采用varian500核磁共振仪进行结构鉴定。结果分析表明,ctgt-i催化毛蕊花糖苷糖基化反应的取代位置在咖啡酰基3-oh上,如图6所示。
本发明并不限于上述实施方式,在不背离本发明的实质内容的情况下,本领域技术人员可以想到的任何变形、改进、替换均落入本发明的范围。
sequencelisting
<110>北京中医药大学
<120>糖基转移酶ctgt-i、其编码基因和衍生物及用途
<130>yc12017120005-a
<160>8
<170>patentinversion3.3
<210>1
<211>485
<212>prt
<213>cistanchetubulosa
<400>1
metgluglylysvallysalagluleuvalphepheproserprogly
151015
argglyhisleuleuserthrleuglumetalalysleuleuilehis
202530
argaspaspargleuserilethrvalleuvalilelysprosertyr
354045
aspprolysserthrserhisalatyrphehishispheproileser
505560
aspproargileargphevalaspileproproprovalgluserval
65707580
prothrglyserproalaserphehisilealaglnpheilegluala
859095
hislysasphisvalargasngluvalserlysilevalleuaspser
100105110
glyprogluserlysleualaglyphevalvalaspilephecysthr
115120125
alametileaspvalalaaspgluleuglyvalproalatyrvalphe
130135140
tyrthrserglyalaalathrleuglyleumetphehispheglngly
145150155160
leuvalaspasphisargargargaspleuleuthrglutyralaasp
165170175
seraspaspglyileleuileprosertyrgluphepropheproala
180185190
lysleuleuproasnpheleuileasplysaspileasnglnmetphe
195200205
metasnleualaargargmetargglnthrlysglyileilevalasn
210215220
thrpheleugluleuglusertrpalametasnserleuserglyasp
225230235240
gluargthrproprovaltyrservalglyprovalleuhisvalglu
245250255
gluglyasnaspleulysproglutyraspgluilevallystrpleu
260265270
aspgluglnproaspserservalvalpheleucyspheglyserlys
275280285
glycyspheaspgluileglnvalarggluilealaleualaleuglu
290295300
asnserglyhisargpheleutrpserleuarglysproproalaglu
305310315320
gluasnlysleugluthrproglyglutyrgluasnproglygluile
325330335
leuprogluglypheileargargthrserglyileglylysvalile
340345350
glytrpalaproglnvalthrileleuserhisargalavalglygly
355360365
phevalserhiscysglytrpasnserthrleugluserleutrptyr
370375380
glyvalprometalaalatrpproleutyralagluglnseralaasn
385390395400
alapheglnleuvallysaspleuglyvalalavalgluilelysmet
405410415
glutyrlyslysserpheserglyalaasnmetilevalthralaasp
420425430
gluilegluserglyileargargleumetalaarggluthraspval
435440445
argvallysileglugluleulysvallysserargmetthrvalval
450455460
gluasnglyserserphegluphevalglyargpheileasnaspval
465470475480
metvalasnileglu
485
<210>2
<211>1458
<212>dna
<213>cistanchetubulosa
<400>2
atggaaggaaaagtgaaagccgagcttgtgttctttccttctccaggaaggggacaccta60
ttatcaacactcgagatggcaaagctactaatccaccgagacgaccgcctctccatcacc120
gtcctcgtcatcaagccctcctacgaccccaagagcacctcccacgcctatttccatcac180
ttccccatatccgaccccaggattcgttttgtcgacattccaccgccagtcgagtccgtt240
ccgaccggctcccccgcttctttccacatcgcccagttcatcgaggcccataaagatcac300
gtgaggaacgaggtgtccaagatagtcctcgattctggcccggagtccaagctcgcgggg360
tttgtggtcgacatcttctgcaccgccatgatcgacgtggcggacgagctcggcgtcccc420
gcgtacgttttctacacgtcgggggccgctacgttggggctcatgtttcatttccagggc480
ctggtggatgatcatcgccgacgggatctgctgacggagtatgcggattcagatgacggg540
attctgatcccgtcgtacgaattcccgttccctgccaagttattacctaattttctgatt600
gataaagatattaaccaaatgttcatgaatctggcaaggagaatgaggcaaactaagggt660
ataattgtcaatactttcctggaattagaatcctgggcgatgaactcactctccggggat720
gagagaactccaccggtttactcggtcggaccggttcttcatgtggaagaaggaaacgat780
cttaaaccggaatacgacgagattgtgaagtggctcgacgaacagcccgattcgtctgtc840
gtgttcctatgtttcggaagcaaaggttgtttcgatgagatccaggtgagggagatagct900
ctggcgctggagaatagtggacaccggtttttatggtccctgagaaagcctccggccgag960
gagaacaaactggagaccccaggggaatacgagaatcctggagaaatcttacctgaaggg1020
tttatccggcgcacgtccggcatcggaaaggtgatcgggtgggccccgcaggtgacgatc1080
ctatcgcaccgggcggtcggtgggttcgtgtcgcactgtggatggaattcgacgctggag1140
agtttgtggtacggggtgccaatggcggcttggccgttgtatgcggagcagtcggcgaat1200
gctttccagctggtgaaggatttgggagtggcggtggagataaagatggagtacaagaag1260
agtttcagtggtgctaatatgatagtgacggcagatgagatagagagtgggatcaggcgc1320
ctgatggcgcgtgagactgacgtcagggtcaaaatcgaggagctgaaagtcaagagtagg1380
atgacggttgtggaaaatggatcgtcatttgagttcgtggggcgatttattaatgacgtc1440
atggttaatattgagtga1458
<210>3
<211>1780
<212>dna
<213>cistanchetubulosa
<400>3
tagcttagtgtggatgtgagcggataacaatttcacacaggaaacagctatgaccatgat60
tacgccaagctgcccttctaatacgactcactatagggcaagcagtggtatcaacgcaga120
gtacatggggacaaaaaaaaaaaaaagtgaatcgtttgtggtgggaagaaatggaaggaa180
aagtgaaagccgagcttgtgttctttccttctccaggaaggggacacctattatcaacac240
tcgagatggcaaagctactaatccaccgagacgaccgcctctccatcaccgtcctcgtca300
tcaagccctcctacgaccccaagagcacctcccacgcctatttccatcacttccccatat360
ccgaccccaggattcgttttgtcgacattccaccgccagtcgagtccgttccgaccggct420
cccccgcttctttccacatcgcccagttcatcgaggcccataaagatcacgtgaggaacg480
aggtgtccaagatagtcctcgattctggcccggagtccaagctcgcggggtttgtggtcg540
acatcttctgcaccgccatgatcgacgtggcggacgagctcggcgtccccgcgtacgttt600
tctacacgtcgggggccgctacgttggggctcatgtttcatttccagggcctggtggatg660
atcatcgccgacgggatctgctgacggagtatgcggattcagatgacgggattctgatcc720
cgtcgtacgaattcccgttccctgccaagttattacctaattttctgattgataaagata780
ttaaccaaatgttcatgaatctggcaaggagaatgaggcaaactaagggtataattgtca840
atactttcctggaattagaatcctgggcgatgaactcactctccggggatgagagaactc900
caccggtttactcggtcggaccggttcttcatgtggaagaaggaaacgatcttaaaccgg960
aatacgacgagattgtgaagtggctcgacgaacagcccgattcgtctgtcgtgttcctat1020
gtttcggaagcaaaggttgtttcgatgagatccaggtgagggagatagctctggcgctgg1080
agaatagtggacaccggtttttatggtccctgagaaagcctccggccgaggagaacaaac1140
tggagaccccaggggaatacgagaatcctggagaaatcttacctgaagggtttatccggc1200
gcacgtccggcatcggaaaggtgatcgggtgggccccgcaggtgacgatcctatcgcacc1260
gggcggtcggtgggttcgtgtcgcactgtggatggaattcgacgctggagagtttgtggt1320
acggggtgccaatggcggcttggccgttgtatgcggagcagtcggcgaatgctttccagc1380
tggtgaaggatttgggagtggcggtggagataaagatggagtacaagaagagtttcagtg1440
gtgctaatatgatagtgacggcagatgagatagagagtgggatcaggcgcctgatggcgc1500
gtgagactgacgtcagggtcaaaatcgaggagctgaaagtcaagagtaggatgacggttg1560
tggaaaatggatcgtcatttgagttcgtggggcgatttattaatgacgtcatggttaata1620
ttgagtgatttttcttttttcttttgttctctctctgtctctctctctctctctcatttt1680
ttttttcttttttttttttattcttaccgttgtttgagaatcaattgatcaaaacatgtg1740
ttattaaaaaagaaaaaaaaaaaaaaaaaaaaaaaaaaaa1780
<210>4
<211>27
<212>dna
<213>人工序列
<400>4
ctattctccagcgccagagctatctcc27
<210>5
<211>28
<212>dna
<213>人工序列
<400>5
acgtgaggaacgaggtgtccaagatagt28
<210>6
<211>28
<212>dna
<213>人工序列
<400>6
ggatccatggaaggaaaagtgaaagccg28
<210>7
<211>29
<212>dna
<213>人工序列
<400>7
gcggccgcctcaatattaaccatgacgtc29
<210>8
<211>1455
<212>dna
<213>cistanchetubulosa
<400>8
atggaaggtaaagttaaagccgaactggtgtttttcccgagtccgggtcgcggtcacctc60
ctgtctaccttagaaatggccaaactgctgatccatcgcgatgatcgcctgtctattacc120
gtgctggttatcaaacctagctatgatcctaaatctacatcacatgcgtattttcatcat180
tttcctatctcagatcctcgtattcgctttgttgacattcctccaccagttgaatcagtt240
ccgacgggtagtcctgcctcatttcatattgcacagtttatcgaagcacataaagatcat300
gtgcgcaatgaggtgagcaaaatcgtgctggattcaggcccggaaagtaaactggcgggc360
tttgtggtggatattttctgtaccgccatgatcgatgttgccgatgaactgggcgttcca420
gcctatgtgttttatacgtcaggtgcagctaccttaggcttaatgtttcattttcagggt480
ctggtggatgatcatcgtcgccgcgacttactgacggaatatgccgatagcgatgatggc540
atcctgatcccgagctatgaatttccgtttccggccaaactgctgcctaattttctgatc600
gataaagatattaatcagatgtttatgaatctggcacgccggatgcgccagaccaaaggc660
attattgttaatacgtttctggaattagaatcttgggccatgaactctctgagcggcgat720
gaacgcaccccaccagtgtatagcgtgggtccagtgttacatgtggaagaaggtaatgac780
ctgaaaccggaatatgatgaaattgttaaatggttagatgaacagccggatagtagcgtt840
gtgtttctgtgctttggtagcaaaggctgctttgatgaaattcaggtgcgcgaaattgca900
ttagccttagaaaatagcggccatcgctttctgtggagtctgcgcaaacctcccgcagaa960
gaaaacaaattagaaacaccaggcgaatatgaaaatccgggcgaaatcttaccggaaggc1020
tttattcgtcgtacaagcggcatcggcaaagtgattggttgggctccacaggtgaccatc1080
ctgagtcatcgtgccgtgggcggttttgtgtcacattgcggttggaatagtacattagaa1140
tctctgtggtatggcgttccaatggcagcttggccactgtatgcagaacagagcgctaat1200
gcctttcagctggttaaagaccttggcgttgcagttgaaatcaagatggaatacaagaaa1260
tcttttagtggcgctaatatgattgtgacagcagatgaaatcgaaagcggtattcgtcgc1320
ttaatggcccgcgaaacggatgttcgcgttaaaatcgaagaactgaaagttaaatcacgc1380
atgaccgtggttgaaaacggcagtagctttgaatttgtgggtcgctttatcaatgatgtt1440
atggttaatatcgaa1455
- 还没有人留言评论。精彩留言会获得点赞!