体外重编程制备视网膜节细胞的方法与流程
本发明属于生物医药领域,特别是涉及一种体外重编程制备视网膜节细胞的方法。
背景技术:
自诺贝尔奖得主山中伸弥发现通过过表达oct4,sox2,klf4和c-myc四个转录因子可以将体细胞重编程为多能干细胞(ips)以来,人们陆续发现通过过表达组织特异性转录因子可以将体细胞直接重编程为其它谱系的体细胞,而无需经过多能干细胞阶段(体细胞直接重编程)。2010年,美国的mariuswernig实验室发现同时过表达ascl1,brn2和myt1l,可以将小鼠成纤维细胞高效地直接重编程为tuj1阳性的神经元(nature2010,463:1035-41)。这一发现为再生治疗神经退行性疾病开辟了崭新,方便而快捷的供体细胞制备途径。但是这一方法得到的神经元仅仅是普通的泛神经元,而治疗各种神经退行性疾病需要针对此疾病的特定神经元亚型。为此,人们通过筛查不同的因子组合实现了体细胞直接重编程制备多巴胺神经元,运动神经元等神经元亚型的有效方法。但是当前尚缺乏体细胞直接重编程制备视网膜神经元的有效方法。
在发病率最广泛的视网膜退行性疾病-青光眼中视网膜节细胞受到损害而永久丢失,导致视力不可逆丧失。视网膜节细胞移植治疗有望解决青光眼不治之难题。因此建立体细胞直接重编程制备视网膜节细胞的方法具有巨大的临床应用价值,但当前在此领域进展有限。虽然有报道,过表达ascl1,brn3b和ngn2可以将小鼠成纤维细胞重编程为brn3a阳性的视网膜节细胞样细胞(neuroscience2013,250:381-93),但是此报道中的方法获得视网膜节细胞样神经元的效率不够高。
申请号为2018104904910的在先申请,通过将外源ascl1基因、islet1基因、brn3b基因整合到体细胞,重编程直接获得视网膜节细胞,但是重编程效率较低,仅能达到10%。
因此,亟待探索一种效率高的体细胞直接重编程制备视网膜节细胞的方法。
技术实现要素:
基于此,本发明的主要目的是提供一种提高体外重编程制备视网膜节细胞效率的方法。
本发明的主要目的是通过以下技术方案实现的:
一种体外重编程制备视网膜节细胞的方法,所述的方法包括:
(1)获取染色体上整合有ascl1基因、islet1基因、brn3b基因的体细胞;
(2)诱导培养,获得视网膜节细胞;
所述诱导培养包括:
先将所述体细胞接种于添加有fgf2、强力霉素的mef培养基中培养1~3天;
再更换为添加有fgf2、强力霉素的dmem/f12与神经细胞培养基的混合培养基中培养至第5天;
然后更换为添加强力霉素的dmem/f12与神经细胞培养基的混合培养基中培养6~8天。
在其中一个实施例中,所述的培养基中添加有5~40ng/ml的fgf2。
在其中一个实施例中,所述的培养基中添加有10~40ng/ml的fgf2。
在其中一个实施例中,所述诱导培养包括:
先将所述体细胞接种于添加有fgf2、强力霉素的mef培养基中培养2天;
再更换为添加有fgf2、强力霉素的dmem/f12与神经细胞培养基的混合培养基中培养至第5天;
然后更换为添加强力霉素的dmem/f12与神经细胞培养基的混合培养基中培养7天。
在其中一个实施例中,所述强力霉素的浓度为1~3μg/ml;所述dmem/f12与神经细胞培养基的体积比为1:1。
在其中一个实施例中,获取染色体上整合有ascl1基因、islet1基因、brn3b基因的体细胞,包括如下步骤:
获取体细胞;
构建慢病毒颗粒,用所述慢病毒颗粒转染所述体细胞,从而将ascl1基因、islet1基因、brn3b基因整合到体细胞染色体上。
在其中一个实施例中,所述慢病毒颗粒的构建包括如下步骤:
1)获取ascl1基因的全长cdna、islet1基因的全长cdna、brn3b基因的全长cdna;
2)将所述ascl1基因的全长cdna、islet1基因的全长cdna、brn3b基因的全长cdna克隆到同一慢病毒载体上,获得慢病毒表达质粒;
3)用慢病毒表达质粒、诱导因子表达质粒、包装质粒转染包装细胞,然后于包装细胞的上清液中收集慢病毒颗粒。
在其中一个实施例中,获取所述brn3b基因的全长cdna的步骤包括:
提取小鼠胚胎头部组织总rna,用反转录酶反转录为cdna库;以所述cdna库为模板,以seqidno.1、seqidno.2为引物,进行pcr扩增;或/和,
获取islet1基因的全长cdna的步骤包括:
提取小鼠胚胎头部组织总rna,用反转录酶反转录为cdna库;以所述cdna库为模板,以seqidno.3、seqidno.4为引物,进行pcr扩增;或/和,
获取所述ascl1基因的全长cdna的步骤包括:
以teto-fuw-ascl1为模板,以seqidno.5、seqidno.6为引物,进行pcr扩增。
在其中一个实施例中,所述brn3b基因的全长cdna如seqidno.9所示;所述islet1基因的全长cdna如seqidno.8所示;所述ascl1基因的全长cdna如seqidno.7所示。
在其中一个实施例中,所述的慢病毒载体为psicor-teto;所述诱导因子表达质粒为诱导因子rtta表达质粒;所述包装细胞为hek293细胞;所述包装质粒为pspax2、pmd2.g。
与现有技术相比,本发明具有如下有益效果:
发明人经过长期研究发现,同时过表达ascl1、brn3b和islet1三个转录因子能够将体细胞重编程为brn3a+;tuj1+的视网膜节细胞样细胞。但是,此技术方案能达到的重编程效率仅有10%左右。为提高重编程的效率,发明人在重编程过程中选择细胞生长因子fgf2于合适的时机添加至诱导培养基中,可以将重编程的效率显著提高到30%以上。
附图说明
图1为不添加fgf2与添加fgf2两种情况下重编程结果比较图;
图2为不添加fgf2、添加fgf2、添加其他细胞生长因子几种情况下重编程效率比较图。
具体实施方式
下列实施例中未注明具体条件的实验方法,通常按照常规条件,例如sambrook等人,分子克隆:实验室手册(newyork:coldspringharborlaboratorypress,1989)中所述的条件,或按照制造厂商所建议的条件。实施例中所用到的各种常用化学试剂,均为市售产品。
除非另有定义,本发明所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不用于限制本发明。本发明所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
实施例1
本实施例提供一种视网膜节细胞的制备方法,具体步骤包括:
步骤1、制备慢病毒表达质粒psicor-teto-ascl1-p2a-islet1-t2a-brn3b(psicor-teto-abi)
(1)获取ascl1基因、brn3b基因、islet1基因的全长cdna
1)提取小鼠胚胎第13.5天头部组织的总rna,用反转录酶superscriptⅲ(thermofisher,scientific)反转录为cdna库。
2)以cdna库为模板,以如下seqidno.1、seqidno.2为引物,进行pcr扩增,获得小鼠brn3b基因全长cdna;
seqidno.1:5’-gaactgtacaatgatgatgatgtccctgaac-3’,
seqidno.2:5’-ggttgaattcctaaatgccggcagagtatttc-3’;
pcr扩增的体系为:1μlcdna库,1×phusion反应缓冲液,200μmdntp,1μm正向引物seqidno.1,1μm反向引物seqidno.2,1unitsphusiondna聚合酶,加水至反应体系为50μl;
pcr扩增的程序为:步骤一:98℃,30s;步骤二:98℃,10s;60℃,20s;72℃,1min;35个循环;步骤三:72℃,10min。
所基因brn3b基因全长cdna的序列(brn3b-cdna)如下seqidno.9所示:
atgatgatgatgtccctgaacagcaagcaggcgttcagcatgcctcacgcaggcagcctgcacgtggagcccaagtactcggcgctacacagtgcctccccgggctcctctgcgcccgcggcgccctcggccagttcccctagcagctccagcaacgctggcggcggcggcggtggcggcggaggcggaggcggcggcggccggagcagcagttccagcagcagtggcagcggcggcagcggcggcggcgggggctcggaggcgatgcggagagcttgtcttccaaccccaccgagcaatatattcggcgggctggatgagagtctgctggcccgtgccgaggctctggccgccgtggacatcgtctcccagagtaagagccaccaccaccatccgccccaccacagccccttcaagccggacgccacttaccacaccatgaacaccatcccgtgcacgtcggcagcctcctcttcttctgtgcccatctcgcacccgtccgctctggctggcacccatcaccaccaccaccaccaccatcaccaccatcaccagccgcaccaggcgctggagggcgagctgcttgagcacctaagccccgggctggccctgggagctatggcgggccccgacggcacggtggtgtccactccggctcacgcaccacacatggccaccatgaaccccatgcaccaagcagccctgagcatggcccacgcacatgggctgccctcgcacatgggctgcatgagcgacgtggatgcagacccgcgggacctggaggcgttcgccgagcgtttcaagcagcgacgcatcaagctgggagtgacccaggcagatgtgggctcggcgctggccaacctcaagatcccgggcgtgggctcgctcagccagagcaccatctgcaggtttgagtctctcacgctgtcacacaacaacatgatcgcgctcaagcccatcctgcaggcgtggctggaggaagctgagaaatcccaccgcgagaagctcactaagccggagctcttcaatggcgcggagaagaagcgcaagcgcacgtccatcgcggcgccggagaagcgctctctggaagcctacttcgccatccagccaaggccctcctcggagaagatcgcggccatcgccgaaaagctggatctcaagaaaaatgtggtgcgcgtctggttctgcaaccagaggcagaaacagaagagaatgaaatactctgccggcatttag。
3)以cdna库为模板,以如下seqidno.3、seqidno.4为引物,进行pcr扩增,扩增小鼠islet1基因全长cdna,并在5’端添加p2a序列,在3’端添加t2a序列;
seqidno.3:
5’-actcaccggtggcagcggcgccacaaacttctctctgctaaagcaagcaggtgatgttgaagaaaaccccgggcctgcatgcatgggagacatgggcgatccacc-3’,
seqidno.4:
5’-gaactgtacactcgagtgggccgggattttcctccacgtccccgcatgttagaagacttcccctgccctcgccggagccgcatgctgcctcaataggactggctaccatgctg-3’;
pcr扩增的体系为:1μlcdna库,1×phusion反应缓冲液,200μmdntp,1μm正向引物seqidno.3,1μm反向引物seqidno.4,1unitsphusiondna聚合酶,加水至反应体系为50μl;
pcr扩增的程序为:步骤一:98℃,30s;步骤二:98℃,10s,60℃,20s,72℃,1min,35个循环;步骤三:72℃,10min。
所得小鼠islet1基因全长cdna的序列(islet1-cdna)如seqidno.8所示:
atgggagacatgggcgatccaccaaaaaaaaaacgtctgatttccctgtgtgttggttgcggcaatcaaattcacgaccagtatattctgagggtttctccggatttggagtggcatgcagcatgtttgaaatgtgcggagtgtaatcagtatttggacgaaagctgtacgtgctttgttagggatgggaaaacctactgtaaaagagattatatcaggttgtacgggatcaaatgcgccaagtgcagcataggcttcagcaagaacgacttcgtgatgcgtgcccgctctaaggtgtaccacatcgagtgtttccgctgtgtagcctgcagccgacagctcatcccgggagacgaattcgccctgcgggaggatgggcttttctgccgtgcagaccacgatgtggtggagagagccagcctgggagctggagaccctctcagtcccttgcatccagcgcggcctctgcaaatggcagccgaacccatctcggctaggcagccagctctgcggccgcacgtccacaagcagccggagaagaccacccgagtgcggactgtgctcaacgagaagcagctgcacaccttgcggacctgctatgccgccaaccctcggccagatgcgctcatgaaggagcaactagtggagatgacgggcctcagtcccagagtcatccgagtgtggtttcaaaacaagcggtgcaaggacaagaaacgcagcatcatgatgaagcagctccagcagcagcaacccaacgacaaaactaatatccaggggatgacaggaactcccatggtggctgctagtccggagagacatgatggtggtttacaggctaacccagtagaggtgcaaagttaccagccgccctggaaagtactgagtgacttcgccttgcaaagcgacatagatcagcctgcttttcagcaactggtcaatttttcagaaggaggaccaggctctaattctactggcagtgaagtagcatcgatgtcctcgcagctcccagatacacccaacagcatggtagccagtcctattgaggcatga。
4)通过pcr方法从teto-fuw-ascl1质粒中扩增出ascl1基因全长cdna
以teto-fuw-ascl1(从addgeng购入,货号27150)为模板,以seqidno.5、seqidno.6为引物对,pcr扩增,获得小鼠ascl1基因全长cdna。
seqidno.5:5’-actcgctagccaccatggagagctctggcaag-3’,
seqidno.6:5’-actcaccggtgaaccagttggtaaagtccagcagctc-3’;
pcr扩增的体系为:1μlcdna库,1×phusion反应缓冲液,200μmdntp,1μm正向引物seqidno.5,1μm反向引物seqidno.6,1unitsphusiondna聚合酶,加水至反应体系为50μl;
pcr扩增的程序为:步骤一:98℃,30s;步骤二:98℃,10s,60℃,20s,72℃,1min,35个循环;步骤三:72℃,10min。
所得小鼠ascl1基因全长cdna的序列(ascl1-cdna)如下seqidno.7所示:
atggagagctctggcaagatggagagtggagccggccagcagccgcagcccccgcagcccttcctgcctcccgcagcctgcttctttgcgaccgcggcggcggcggcagcggcggcggccgcggcagctcagagcgcgcagcagcaacagccgcaggcgccgccgcagcaggcgccgcagctgagcccggtggccgacagccagccctcagggggcggtcacaagtcagcggccaagcaggtcaagcgccagcgctcgtcctctccggaactgatgcgctgcaaacgccggctcaacttcagcggcttcggctacagcctgccacagcagcagccggccgccgtggcgcgccgcaacgagcgcgagcgcaaccgggtcaagttggtcaacctgggttttgccaccctccgggagcatgtccccaacggcgcggccaacaagaagatgagcaaggtggagacgctgcgctcggcggtcgagtacatccgcgcgctgcagcagctgctggacgagcacgacgcggtgagcgctgcctttcaggcgggcgtcctgtcgcccaccatctcccccaactactccaacgacttgaactctatggcgggttctccggtctcgtcctactcctccgacgagggatcctacgaccctcttagcccagaggaacaagagctgctggactttaccaactggttctga。
(2)通过分子克隆方法将步骤(1)所得三个cdna克隆入同一个诱导表达慢病毒载体psicor-teto中,得到psicor-teto-abi质粒
本步骤采用的psicor-teto质粒,可通过常规分子生物学手段改造psicor(addgene,11579)获得,包括:以含有teto序列的质粒为模板,pcr扩增teto序列,用限制性内切酶noti-nhei分别酶切pcr产物和psicor质粒,连接合成psicor-teto载体质粒。
构建psicor-teto-abi质粒的步骤包括:
首先,用限制性内切酶nhei和agei分别酶切psicor-teto和ascl1-cdna,然后将ascl1-cdna连接入pscor-teto载体中,转化感受态细菌,挑单克隆菌株,扩增培养,提取质粒,送测序公司测序,核实正确psicor-teto-ascl1菌株。
然后,用限制性内切酶bsrgi和ecori分别酶切psicor-teto-ascl1和brn3b-cdna,连接,转化感受态细菌,挑单克隆,扩增培养,提取质粒,送测序公司测序,核实正确psicor-teto-ascl1-brn3b菌株。
最后,用限制性内切酶agei和bsrgi分别酶切psicor-teto-ascl1-brn3b和isleti-cdna,连接,转化感受态细菌,挑单克隆,扩增培养,提取质粒,送测序公司测序,核实正确psicor-teto-ascl1-p2a-islet1-t2a-brn3b(简称psicor-teto-abi)菌株。
扩增培养psicor-teto-abi菌株,利用qiagen质粒提取试剂盒qiagenplasmidmidikit(货号12145)提取纯化质粒,以备转染293细胞制作病毒使用。
步骤2、将psicor-teto-abi质粒,以及诱导因子rtta表达质粒分别和包装质粒pspax2和pmd2.g通过钙转染方法转染hek293细胞。
转染36小时后,收集含病毒上清液,通过peg沉降的方法富集慢病毒,最后重悬慢病毒于dmem培养基中(25ml起始病毒上清液最后重悬于100μldmem培养基中),分装冻存于-80℃冰箱待用。
步骤3、准备传代第3代的小鼠成纤维细胞(mef),培养于mef培养基中(dmem+10%fbs),置于37℃,5%co2培养箱中孵育过夜。该步骤的“%”为体积比。
步骤4、第0天:用mef培养基稀释慢病毒(按每毫升培养基添加50μlpsicor-teto-abi,15μlrtta慢病毒的比例加入),吸去mef培养基,换成添加了慢病毒的培养基,继续置于37℃,5%co2培养箱中培养。
步骤5、第1天(即重编程诱导培养的第一天):加入病毒24小时后,吸去含慢病毒培养基,更换入新鲜mef培养基,同时加入doxycycline(2μg/ml);同时添加fgf2(20ng/ml);持续培养2天。
步骤6、第3天:更换培养基为dmem/f12:neurobasal(1:1)+n2(1%)+b27(2%),仍然保持添加2μg/mldoxycycline、20ng/mlfgf2。该步骤的“%”为体积比。neurobasal即基础培养基。
步骤7、半量更换添加有2μg/mldoxycycline、20ng/mlfgf2的dmem/f12:neurobasal(1:1)+n2(1%)+b27(2%)的培养基。保证添加fgf2培养的时间为5天。
步骤8、第6天撤掉fgf2,即更换为添加有2μg/mldoxycycline的dmem/f12:neurobasal(1:1)+n2(1%)+b27(2%)的培养基。
步骤9、第7天:培养基中添加4.2μg/mlforskolin,继续培养;该步骤的培养基为dmem/f12:neurobasal(1:1)+n2(1%)+b27(2%)的培养基。
步骤10、第8天至第12天,每两天更换半量培养基,获得视网膜节细胞。该步骤的培养基为dmem/f12:neurobasal(1:1)+n2(1%)+b27(2%)的培养基。
步骤11、第12天:取细胞进行免疫荧光染色(检测brn3a,tuj1等表达情况)。
实施例2
本实施例是实施例1的变化例,变化之处主要在于步骤5至步骤7中,添加终浓度为40ng/ml的fgf2,持续培养5天。
实施例3
本实施例是实施例1的变化例,变化之处主要在于步骤5中,添加终浓度为10ng/ml的fgf2,持续培养5天。
实施例4
本实施例是实施例1的变化例,变化之处主要在于步骤5中,添加终浓度为5ng/ml的fgf2,持续培养5天。
对比例1~2
本对比例是实施例1的对比例,相对于实施例1的差别之处主要是步骤5采用的细胞生长因子种类不同:
对比例1的步骤5添加egf(20ng/ml)代替fgf2;
对比例2的步骤5添加bmp4(20ng/ml)代替fgf2。
对比例3
本对比例是实施例1的对比例,相对于实施例1的差别之处主要是步骤5不加入细胞生长因子fgf2。
对比例4
本对比例是实施例1的对比例,相对于实施例1的差别之处主要是加入fgf2的时机不同:本对比例是在步骤6开始加入fgf2,而非是从步骤5开始加入。
对以上各例制备视网膜节细胞的结果进行检测:
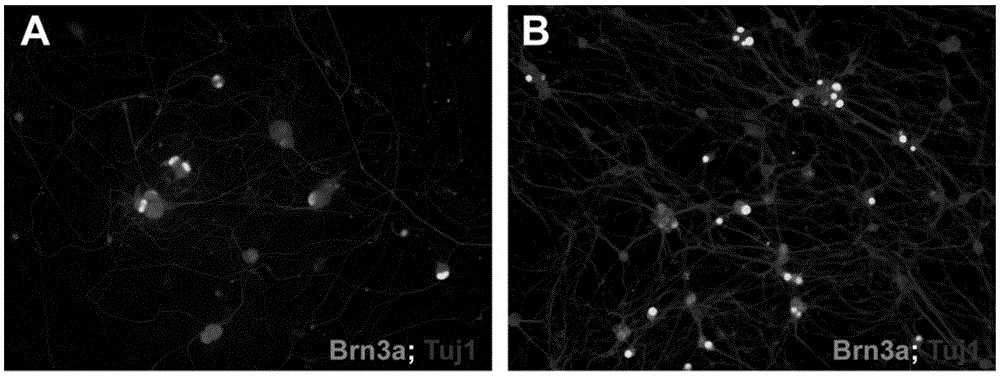
(1)实施例1在诱导培养开始起第1至5天采用的培养基中加入fgf2,而对比例3则没有加入fgf2。根据图1可知:对比例3不加入任何细胞生长因子时,同时过表达ascl1、islet1、brn3b可将小鼠成纤维细胞(mef)重编程为brn3a+;tuj1+的视网膜节细胞样细胞,但是重编程视网膜节细胞数量少。而实施例1,在重编程过程中添加fgf2显著提高形成brn3a+;tuj1+的视网膜节细胞样细胞的比率。
(2)在不添加fgf2的条件下同时过表达ascl1、islet1、brn3b仅可将9.5%小鼠成纤维细胞(mef)重编程为brn3a+;tuj1+的视网膜节细胞样细胞,参见对比例3及表1。而在重编程第一天开始持续添加4天的fgf2时,可将重编程的效率提高到30.9%,参见实施例1至实施例4。其他的细胞生长因子无此效果,请参见对比例1、2以及表1。如果加入fgf2的时机不对,那么也无法实现重编程效率提升问题,参见对比例4及表1。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
序列表
<110>中山大学中山眼科中心
<120>体外重编程制备视网膜节细胞的方法
<160>13
<170>siposequencelisting1.0
<210>1
<211>31
<212>dna
<213>人工序列(artificialsequence)
<400>1
gaactgtacaatgatgatgatgtccctgaac31
<210>2
<211>32
<212>dna
<213>人工序列(artificialsequence)
<400>2
ggttgaattcctaaatgccggcagagtatttc32
<210>3
<211>105
<212>dna
<213>人工序列(artificialsequence)
<400>3
actcaccggtggcagcggcgccacaaacttctctctgctaaagcaagcaggtgatgttga60
agaaaaccccgggcctgcatgcatgggagacatgggcgatccacc105
<210>4
<211>113
<212>dna
<213>人工序列(artificialsequence)
<400>4
gaactgtacactcgagtgggccgggattttcctccacgtccccgcatgttagaagacttc60
ccctgccctcgccggagccgcatgctgcctcaataggactggctaccatgctg113
<210>5
<211>32
<212>dna
<213>人工序列(artificialsequence)
<400>5
actcgctagccaccatggagagctctggcaag32
<210>6
<211>37
<212>dna
<213>人工序列(artificialsequence)
<400>6
actcaccggtgaaccagttggtaaagtccagcagctc37
<210>7
<211>696
<212>dna
<213>小鼠(musmusculus)
<400>7
atggagagctctggcaagatggagagtggagccggccagcagccgcagcccccgcagccc60
ttcctgcctcccgcagcctgcttctttgcgaccgcggcggcggcggcagcggcggcggcc120
gcggcagctcagagcgcgcagcagcaacagccgcaggcgccgccgcagcaggcgccgcag180
ctgagcccggtggccgacagccagccctcagggggcggtcacaagtcagcggccaagcag240
gtcaagcgccagcgctcgtcctctccggaactgatgcgctgcaaacgccggctcaacttc300
agcggcttcggctacagcctgccacagcagcagccggccgccgtggcgcgccgcaacgag360
cgcgagcgcaaccgggtcaagttggtcaacctgggttttgccaccctccgggagcatgtc420
cccaacggcgcggccaacaagaagatgagcaaggtggagacgctgcgctcggcggtcgag480
tacatccgcgcgctgcagcagctgctggacgagcacgacgcggtgagcgctgcctttcag540
gcgggcgtcctgtcgcccaccatctcccccaactactccaacgacttgaactctatggcg600
ggttctccggtctcgtcctactcctccgacgagggatcctacgaccctcttagcccagag660
gaacaagagctgctggactttaccaactggttctga696
<210>8
<211>1050
<212>dna
<213>小鼠(musmusculus)
<400>8
atgggagacatgggcgatccaccaaaaaaaaaacgtctgatttccctgtgtgttggttgc60
ggcaatcaaattcacgaccagtatattctgagggtttctccggatttggagtggcatgca120
gcatgtttgaaatgtgcggagtgtaatcagtatttggacgaaagctgtacgtgctttgtt180
agggatgggaaaacctactgtaaaagagattatatcaggttgtacgggatcaaatgcgcc240
aagtgcagcataggcttcagcaagaacgacttcgtgatgcgtgcccgctctaaggtgtac300
cacatcgagtgtttccgctgtgtagcctgcagccgacagctcatcccgggagacgaattc360
gccctgcgggaggatgggcttttctgccgtgcagaccacgatgtggtggagagagccagc420
ctgggagctggagaccctctcagtcccttgcatccagcgcggcctctgcaaatggcagcc480
gaacccatctcggctaggcagccagctctgcggccgcacgtccacaagcagccggagaag540
accacccgagtgcggactgtgctcaacgagaagcagctgcacaccttgcggacctgctat600
gccgccaaccctcggccagatgcgctcatgaaggagcaactagtggagatgacgggcctc660
agtcccagagtcatccgagtgtggtttcaaaacaagcggtgcaaggacaagaaacgcagc720
atcatgatgaagcagctccagcagcagcaacccaacgacaaaactaatatccaggggatg780
acaggaactcccatggtggctgctagtccggagagacatgatggtggtttacaggctaac840
ccagtagaggtgcaaagttaccagccgccctggaaagtactgagtgacttcgccttgcaa900
agcgacatagatcagcctgcttttcagcaactggtcaatttttcagaaggaggaccaggc960
tctaattctactggcagtgaagtagcatcgatgtcctcgcagctcccagatacacccaac1020
agcatggtagccagtcctattgaggcatga1050
<210>9
<211>1236
<212>dna
<213>小鼠(musmusculus)
<400>9
atgatgatgatgtccctgaacagcaagcaggcgttcagcatgcctcacgcaggcagcctg60
cacgtggagcccaagtactcggcgctacacagtgcctccccgggctcctctgcgcccgcg120
gcgccctcggccagttcccctagcagctccagcaacgctggcggcggcggcggtggcggc180
ggaggcggaggcggcggcggccggagcagcagttccagcagcagtggcagcggcggcagc240
ggcggcggcgggggctcggaggcgatgcggagagcttgtcttccaaccccaccgagcaat300
atattcggcgggctggatgagagtctgctggcccgtgccgaggctctggccgccgtggac360
atcgtctcccagagtaagagccaccaccaccatccgccccaccacagccccttcaagccg420
gacgccacttaccacaccatgaacaccatcccgtgcacgtcggcagcctcctcttcttct480
gtgcccatctcgcacccgtccgctctggctggcacccatcaccaccaccaccaccaccat540
caccaccatcaccagccgcaccaggcgctggagggcgagctgcttgagcacctaagcccc600
gggctggccctgggagctatggcgggccccgacggcacggtggtgtccactccggctcac660
gcaccacacatggccaccatgaaccccatgcaccaagcagccctgagcatggcccacgca720
catgggctgccctcgcacatgggctgcatgagcgacgtggatgcagacccgcgggacctg780
gaggcgttcgccgagcgtttcaagcagcgacgcatcaagctgggagtgacccaggcagat840
gtgggctcggcgctggccaacctcaagatcccgggcgtgggctcgctcagccagagcacc900
atctgcaggtttgagtctctcacgctgtcacacaacaacatgatcgcgctcaagcccatc960
ctgcaggcgtggctggaggaagctgagaaatcccaccgcgagaagctcactaagccggag1020
ctcttcaatggcgcggagaagaagcgcaagcgcacgtccatcgcggcgccggagaagcgc1080
tctctggaagcctacttcgccatccagccaaggccctcctcggagaagatcgcggccatc1140
gccgaaaagctggatctcaagaaaaatgtggtgcgcgtctggttctgcaaccagaggcag1200
aaacagaagagaatgaaatactctgccggcatttag1236
<210>10
<211>34
<212>dna
<213>人工序列(artificialsequence)
<400>10
ggttgctagccaccatgggagacatgggcgatcc34
<210>14
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>14
ggtatgtacatcatgcctcaataggactgg30
<210>12
<211>35
<212>dna
<213>人工序列(artificialsequence)
<400>12
ggttgctagccaccatgatgatgatgtccctgaac35
<210>13
<211>32
<212>dna
<213>人工序列(artificialsequence)
<400>13
ggttgaattcctaaatgccggcggaatatttc32
- 还没有人留言评论。精彩留言会获得点赞!